 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Two-stage Unsupervised Approach for Low light Image Enhancement
Oct 20, 2020




As vision based perception methods are usually built on the normal light assumption, there will be a serious safety issue when deploying them into low light environments. Recently, deep learning based methods have been proposed to enhance low light images by penalizing the pixel-wise loss of low light and normal light images. However, most of them suffer from the following problems: 1) the need of pairs of low light and normal light images for training, 2) the poor performance for dark images, 3) the amplification of noise. To alleviate these problems, in this paper, we propose a two-stage unsupervised method that decomposes the low light image enhancement into a pre-enhancement and a post-refinement problem. In the first stage, we pre-enhance a low light image with a conventional Retinex based method. In the second stage, we use a refinement network learned with adversarial training for further improvement of the image quality. The experimental results show that our method outperforms previous methods on four benchmark datasets. In addition, we show that our method can significantly improve feature points matching and simultaneous localization and mapping in low light conditions.
Multi-Material Blind Beam Hardening Correction Based on Non-Linearity Adjustment of Projections
Mar 09, 2022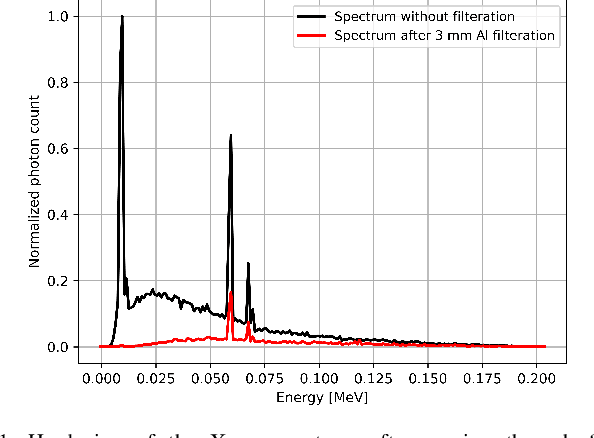
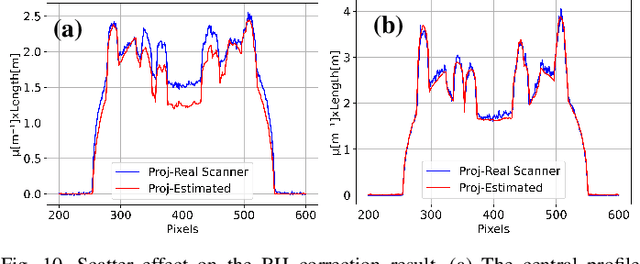
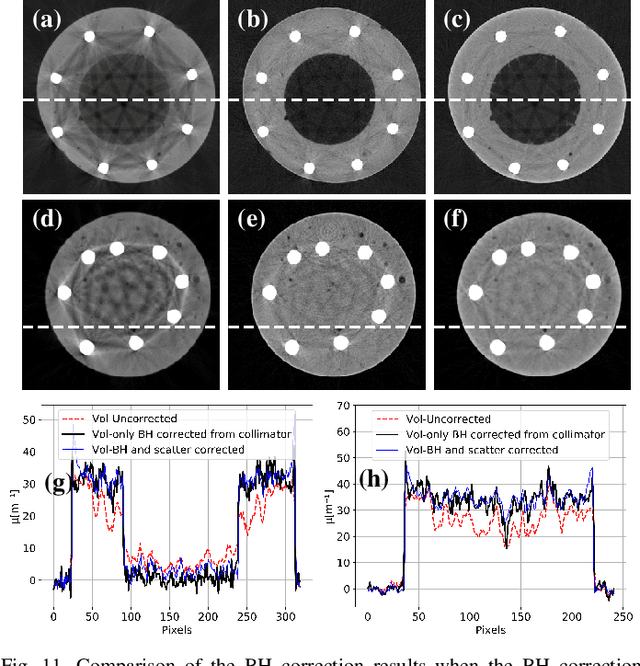
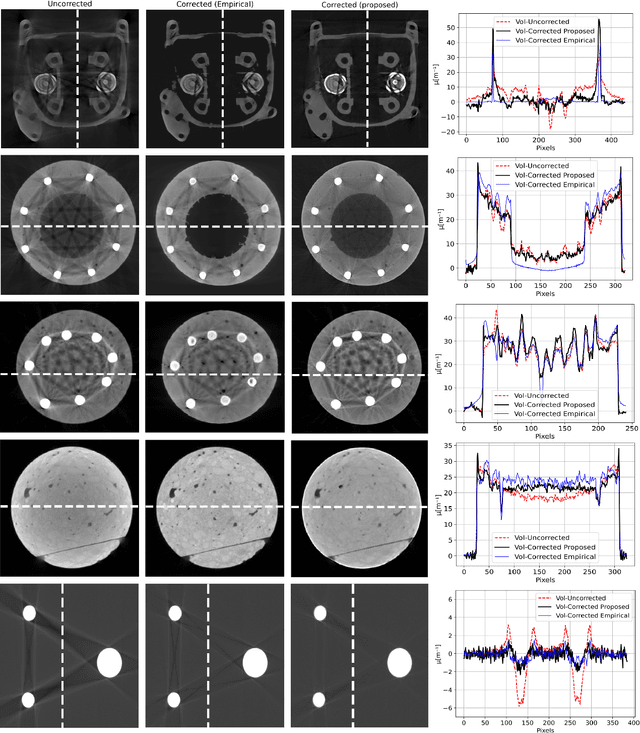
Beam hardening (BH) is one of the major artifacts that severely reduces the quality of Computed Tomography (CT) imaging. In a polychromatic X-ray beam, since low-energy photons are more preferentially absorbed, the attenuation of the beam is no longer a linear function of the absorber thickness. The existing BH correction methods either require a given material, which might be unfeasible in reality, or they require a long computation time. This work aims to propose a fast and accurate BH correction method that requires no prior knowledge of the materials and corrects first and higher-order BH artifacts. In the first step, a wide sweep of the material is performed based on an experimentally measured look-up table to obtain the closest estimate of the material. Then the non-linearity effect of the BH is corrected by adding the difference between the estimated monochromatic and the polychromatic simulated projections of the segmented image. The estimated monochromatic projection is simulated by selecting the energy from the polychromatic spectrum which produces the lowest mean square error (MSE) with the acquired projection from the scanner. The polychromatic projection is estimated by minimizing the difference between the acquired projection and the weighted sum of the simulated polychromatic projections using different spectra of different filtration. To evaluate the proposed BH correction method, we have conducted extensive experiments on the real-world CT data. Compared to the state-of-the-art empirical BH correction method, the experiments show that the proposed method can highly reduce the BH artifacts without prior knowledge of the materials.
One-shot Weakly-Supervised Segmentation in Medical Images
Nov 21, 2021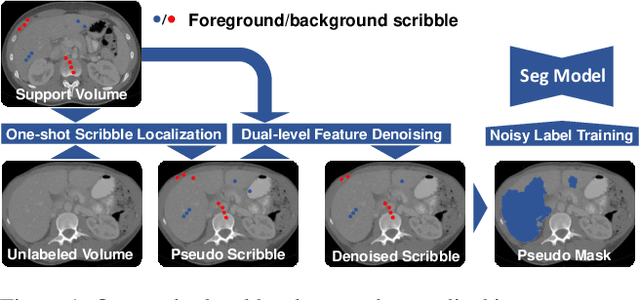

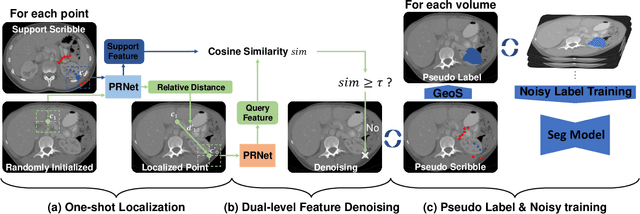

Deep neural networks usually require accurate and a large number of annotations to achieve outstanding performance in medical image segmentation. One-shot segmentation and weakly-supervised learning are promising research directions that lower labeling effort by learning a new class from only one annotated image and utilizing coarse labels instead, respectively. Previous works usually fail to leverage the anatomical structure and suffer from class imbalance and low contrast problems. Hence, we present an innovative framework for 3D medical image segmentation with one-shot and weakly-supervised settings. Firstly a propagation-reconstruction network is proposed to project scribbles from annotated volume to unlabeled 3D images based on the assumption that anatomical patterns in different human bodies are similar. Then a dual-level feature denoising module is designed to refine the scribbles based on anatomical- and pixel-level features. After expanding the scribbles to pseudo masks, we could train a segmentation model for the new class with the noisy label training strategy. Experiments on one abdomen and one head-and-neck CT dataset show the proposed method obtains significant improvement over the state-of-the-art methods and performs robustly even under severe class imbalance and low contrast.
MIINet: An Image Quality Improvement Framework for Supporting Medical Diagnosis
Nov 28, 2020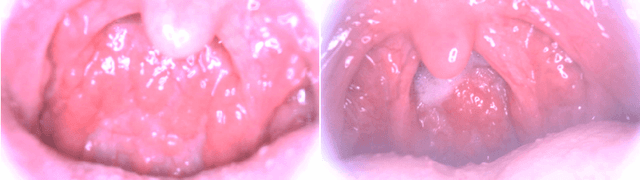
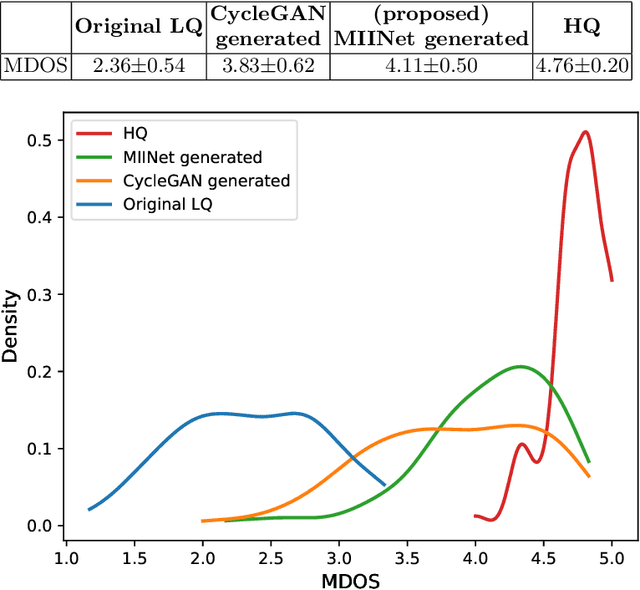

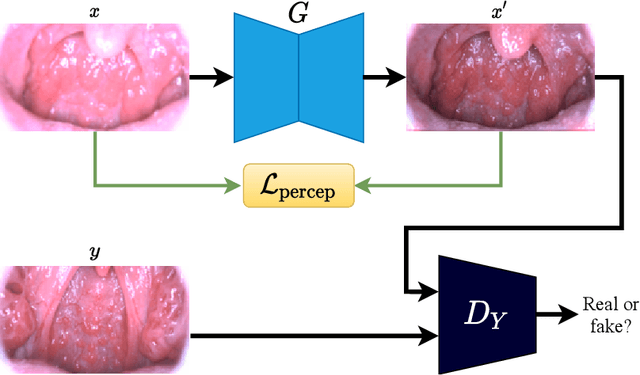
Medical images have been indispensable and useful tools for supporting medical experts in making diagnostic decisions. However, taken medical images especially throat and endoscopy images are normally hazy, lack of focus, or uneven illumination. Thus, these could difficult the diagnosis process for doctors. In this paper, we propose MIINet, a novel image-to-image translation network for improving quality of medical images by unsupervised translating low-quality images to the high-quality clean version. Our MIINet is not only capable of generating high-resolution clean images, but also preserving the attributes of original images, making the diagnostic more favorable for doctors. Experiments on dehazing 100 practical throat images show that our MIINet largely improves the mean doctor opinion score (MDOS), which assesses the quality and the reproducibility of the images from the baseline of 2.36 to 4.11, while dehazed images by CycleGAN got lower score of 3.83. The MIINet is confirmed by three physicians to be satisfying in supporting throat disease diagnostic from original low-quality images.
Large Deformation Diffeomorphic Image Registration with Laplacian Pyramid Networks
Jun 29, 2020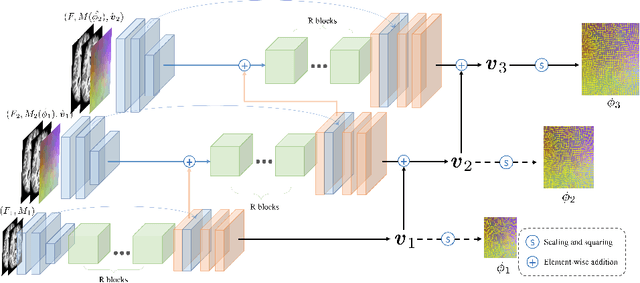
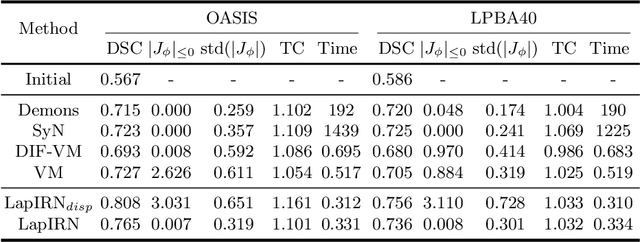
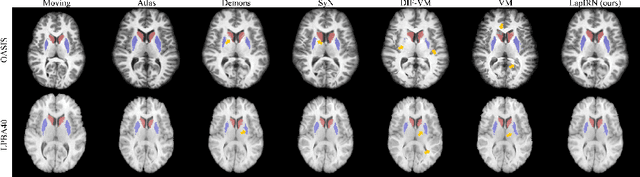
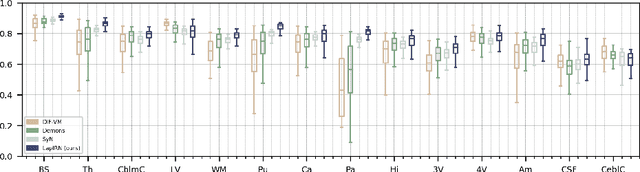
Deep learning-based methods have recently demonstrated promising results in deformable image registration for a wide range of medical image analysis tasks. However, existing deep learning-based methods are usually limited to small deformation settings, and desirable properties of the transformation including bijective mapping and topology preservation are often being ignored by these approaches. In this paper, we propose a deep Laplacian Pyramid Image Registration Network, which can solve the image registration optimization problem in a coarse-to-fine fashion within the space of diffeomorphic maps. Extensive quantitative and qualitative evaluations on two MR brain scan datasets show that our method outperforms the existing methods by a significant margin while maintaining desirable diffeomorphic properties and promising registration speed.
TriGAN: Image-to-Image Translation for Multi-Source Domain Adaptation
Apr 19, 2020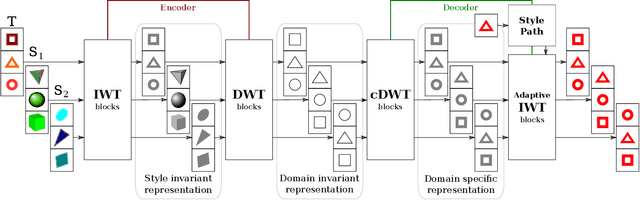
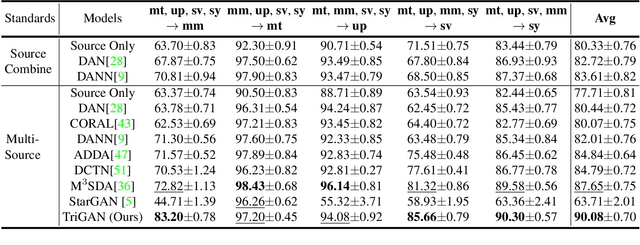
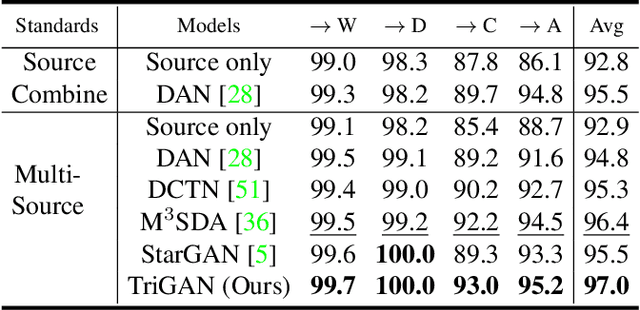

Most domain adaptation methods consider the problem of transferring knowledge to the target domain from a single source dataset. However, in practical applications, we typically have access to multiple sources. In this paper we propose the first approach for Multi-Source Domain Adaptation (MSDA) based on Generative Adversarial Networks. Our method is inspired by the observation that the appearance of a given image depends on three factors: the domain, the style (characterized in terms of low-level features variations) and the content. For this reason we propose to project the image features onto a space where only the dependence from the content is kept, and then re-project this invariant representation onto the pixel space using the target domain and style. In this way, new labeled images can be generated which are used to train a final target classifier. We test our approach using common MSDA benchmarks, showing that it outperforms state-of-the-art methods.
Mushrooms Detection, Localization and 3D Pose Estimation using RGB-D Sensor for Robotic-picking Applications
Jan 08, 2022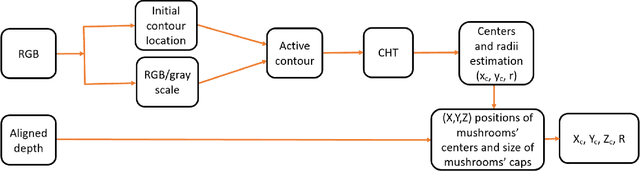
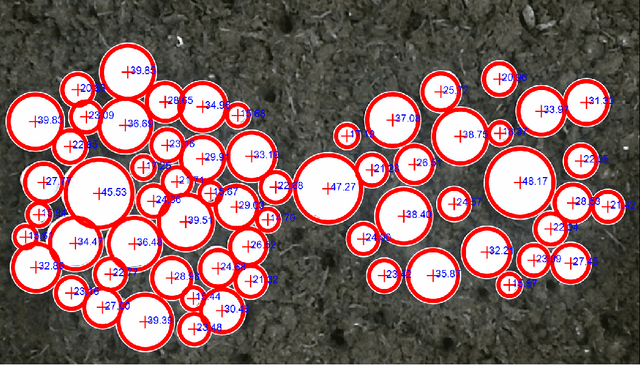
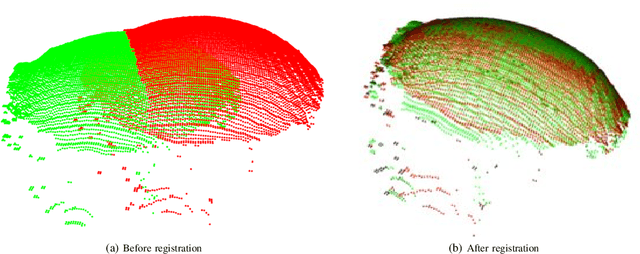

In this paper, we propose mushrooms detection, localization and 3D pose estimation algorithm using RGB-D data acquired from a low-cost consumer RGB-D sensor. We use the RGB and depth information for different purposes. From RGB color, we first extract initial contour locations of the mushrooms and then provide both the initial contour locations and the original image to active contour for mushrooms segmentation. These segmented mushrooms are then used as input to a circular Hough transform for each mushroom detection including its center and radius. Once each mushroom's center position in the RGB image is known, we then use the depth information to locate it in 3D space i.e. in world coordinate system. In case of missing depth information at the detected center of each mushroom, we estimate from the nearest available depth information within the radius of each mushroom. We also estimate the 3D pose of each mushroom using a pre-prepared upright mushroom model. We use a global registration followed by local refine registration approach for this 3D pose estimation. From the estimated 3D pose, we use only the rotation part expressed in quaternion as an orientation of each mushroom. These estimated (X,Y,Z) positions, diameters and orientations of the mushrooms are used for robotic-picking applications. We carry out extensive experiments on both 3D printed and real mushrooms which show that our method has an interesting performance.
SMILE: Semantically-guided Multi-attribute Image and Layout Editing
Oct 05, 2020
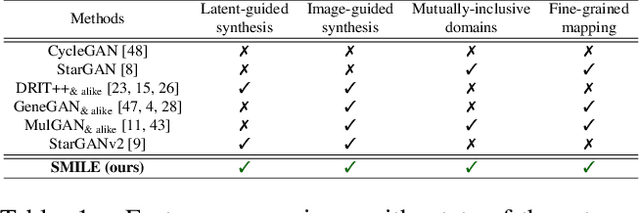
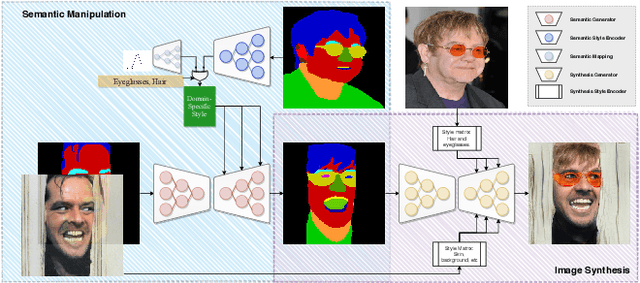

Attribute image manipulation has been a very active topic since the introduction of Generative Adversarial Networks (GANs). Exploring the disentangled attribute space within a transformation is a very challenging task due to the multiple and mutually-inclusive nature of the facial images, where different labels (eyeglasses, hats, hair, identity, etc.) can co-exist at the same time. Several works address this issue either by exploiting the modality of each domain/attribute using a conditional random vector noise, or extracting the modality from an exemplary image. However, existing methods cannot handle both random and reference transformations for multiple attributes, which limits the generality of the solutions. In this paper, we successfully exploit a multimodal representation that handles all attributes, be it guided by random noise or exemplar images, while only using the underlying domain information of the target domain. We present extensive qualitative and quantitative results for facial datasets and several different attributes that show the superiority of our method. Additionally, our method is capable of adding, removing or changing either fine-grained or coarse attributes by using an image as a reference or by exploring the style distribution space, and it can be easily extended to head-swapping and face-reenactment applications without being trained on videos.
High-Performance Large-Scale Image Recognition Without Normalization
Feb 11, 2021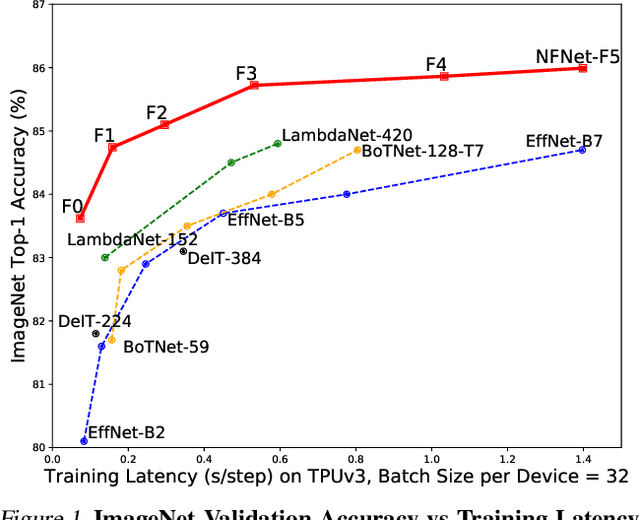
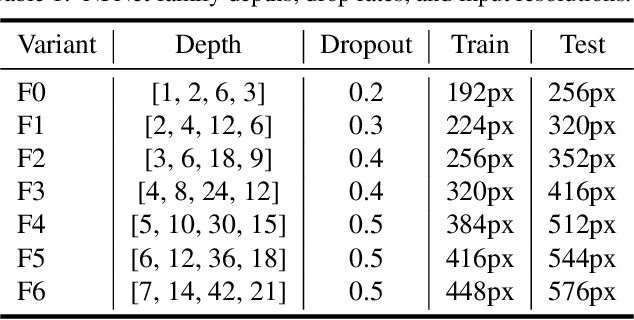
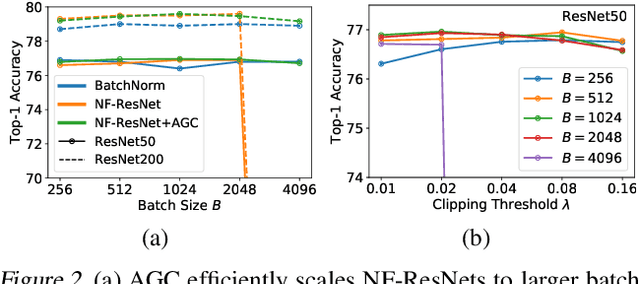
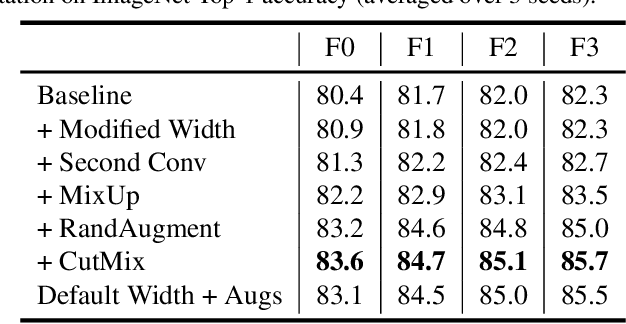
Batch normalization is a key component of most image classification models, but it has many undesirable properties stemming from its dependence on the batch size and interactions between examples. Although recent work has succeeded in training deep ResNets without normalization layers, these models do not match the test accuracies of the best batch-normalized networks, and are often unstable for large learning rates or strong data augmentations. In this work, we develop an adaptive gradient clipping technique which overcomes these instabilities, and design a significantly improved class of Normalizer-Free ResNets. Our smaller models match the test accuracy of an EfficientNet-B7 on ImageNet while being up to 8.7x faster to train, and our largest models attain a new state-of-the-art top-1 accuracy of 86.5%. In addition, Normalizer-Free models attain significantly better performance than their batch-normalized counterparts when finetuning on ImageNet after large-scale pre-training on a dataset of 300 million labeled images, with our best models obtaining an accuracy of 89.2%. Our code is available at https://github.com/deepmind/ deepmind-research/tree/master/nfnets
Informative Sample Mining Network for Multi-Domain Image-to-Image Translation
Jan 05, 2020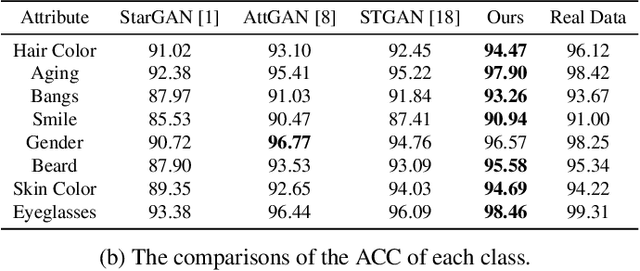
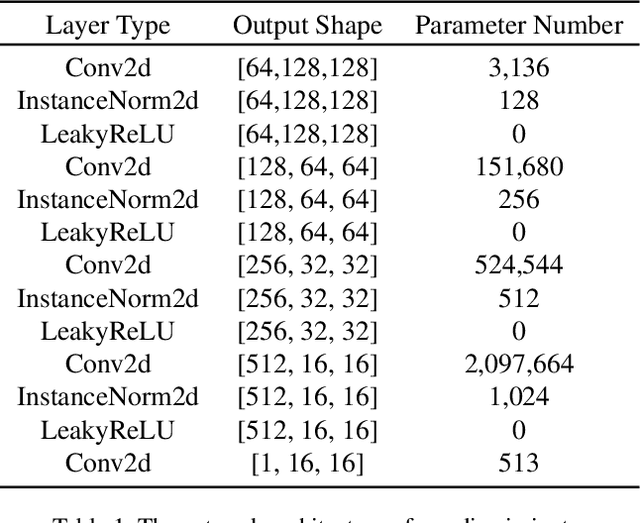

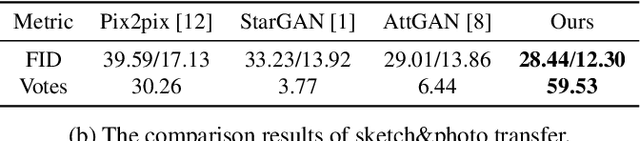
The performance of multi-domain image-to-image translation has been significantly improved by recent progress in deep generative models. Existing approaches can use a unified model to achieve translations between all the visual domains. However, their outcomes are far from satisfying when there are large domain variations. In this paper, we reveal that improving the strategy of sample selection is an effective solution. To select informative samples, we dynamically estimate sample importance during the training of Generative Adversarial Networks, presenting Informative Sample Mining Network. We theoretically analyze the relationship between the sample importance and the prediction of the global optimal discriminator. Then a practical importance estimation function based on general discriminators is derived. In addition, we propose a novel multi-stage sample training scheme to reduce sample hardness while preserving sample informativeness. Extensive experiments on a wide range of specific image-to-image translation tasks are conducted, and the results demonstrate our superiority over current state-of-the-art methods.