 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Attacking Deep Learning AI Hardware with Universal Adversarial Perturbation
Nov 18, 2021
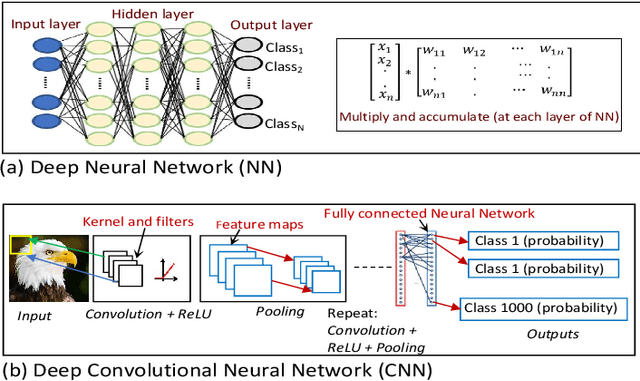

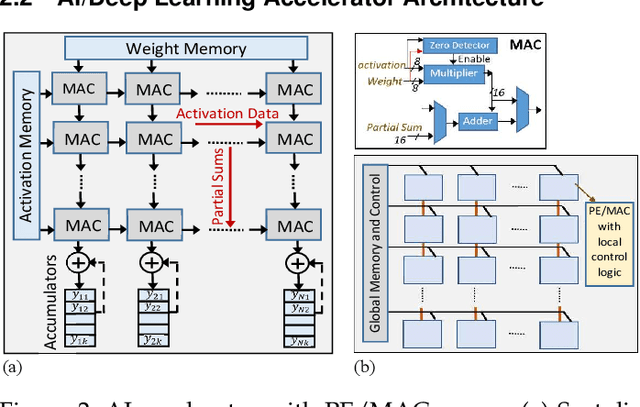

Universal Adversarial Perturbations are image-agnostic and model-independent noise that when added with any image can mislead the trained Deep Convolutional Neural Networks into the wrong prediction. Since these Universal Adversarial Perturbations can seriously jeopardize the security and integrity of practical Deep Learning applications, existing techniques use additional neural networks to detect the existence of these noises at the input image source. In this paper, we demonstrate an attack strategy that when activated by rogue means (e.g., malware, trojan) can bypass these existing countermeasures by augmenting the adversarial noise at the AI hardware accelerator stage. We demonstrate the accelerator-level universal adversarial noise attack on several deep Learning models using co-simulation of the software kernel of Conv2D function and the Verilog RTL model of the hardware under the FuseSoC environment.
Multimodal Entity Tagging with Multimodal Knowledge Base
Dec 21, 2021
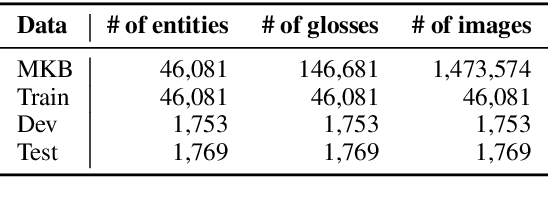
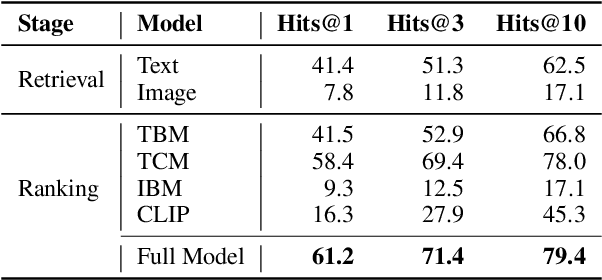
To enhance research on multimodal knowledge base and multimodal information processing, we propose a new task called multimodal entity tagging (MET) with a multimodal knowledge base (MKB). We also develop a dataset for the problem using an existing MKB. In an MKB, there are entities and their associated texts and images. In MET, given a text-image pair, one uses the information in the MKB to automatically identify the related entity in the text-image pair. We solve the task by using the information retrieval paradigm and implement several baselines using state-of-the-art methods in NLP and CV. We conduct extensive experiments and make analyses on the experimental results. The results show that the task is challenging, but current technologies can achieve relatively high performance. We will release the dataset, code, and models for future research.
TransZero++: Cross Attribute-Guided Transformer for Zero-Shot Learning
Dec 21, 2021
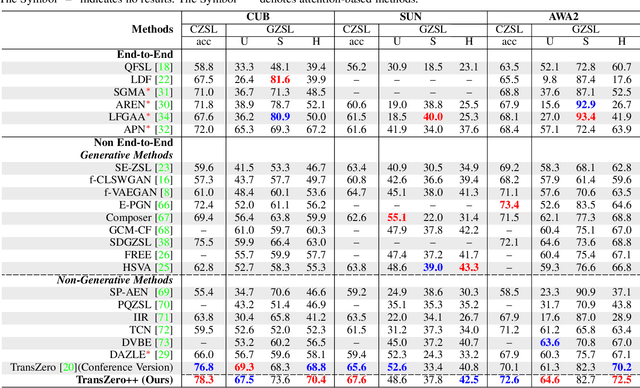
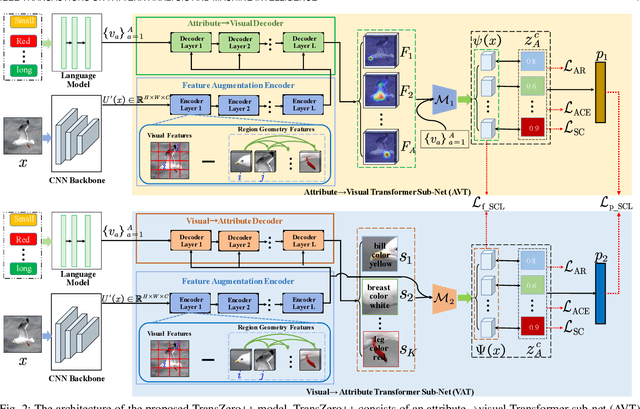
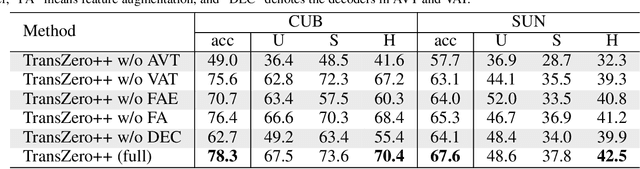
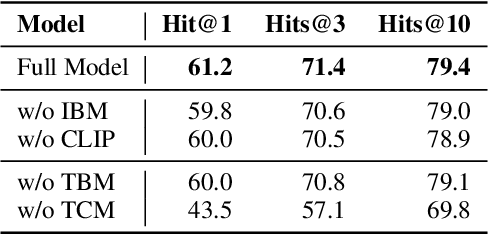
Zero-shot learning (ZSL) tackles the novel class recognition problem by transferring semantic knowledge from seen classes to unseen ones. Existing attention-based models have struggled to learn inferior region features in a single image by solely using unidirectional attention, which ignore the transferability and discriminative attribute localization of visual features. In this paper, we propose a cross attribute-guided Transformer network, termed TransZero++, to refine visual features and learn accurate attribute localization for semantic-augmented visual embedding representations in ZSL. TransZero++ consists of an attribute$\rightarrow$visual Transformer sub-net (AVT) and a visual$\rightarrow$attribute Transformer sub-net (VAT). Specifically, AVT first takes a feature augmentation encoder to alleviate the cross-dataset problem, and improves the transferability of visual features by reducing the entangled relative geometry relationships among region features. Then, an attribute$\rightarrow$visual decoder is employed to localize the image regions most relevant to each attribute in a given image for attribute-based visual feature representations. Analogously, VAT uses the similar feature augmentation encoder to refine the visual features, which are further applied in visual$\rightarrow$attribute decoder to learn visual-based attribute features. By further introducing semantical collaborative losses, the two attribute-guided transformers teach each other to learn semantic-augmented visual embeddings via semantical collaborative learning. Extensive experiments show that TransZero++ achieves the new state-of-the-art results on three challenging ZSL benchmarks. The codes are available at: \url{https://github.com/shiming-chen/TransZero_pp}.
AI-based Carcinoma Detection and Classification Using Histopathological Images: A Systematic Review
Jan 18, 2022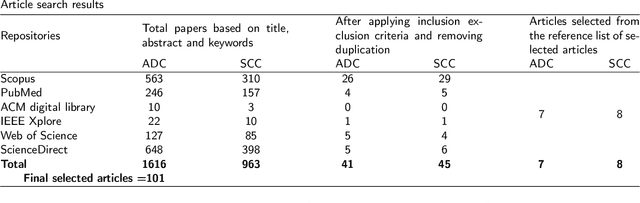
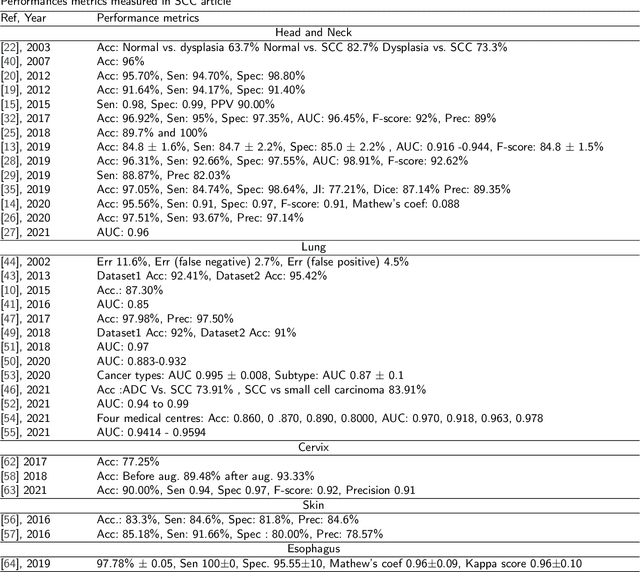

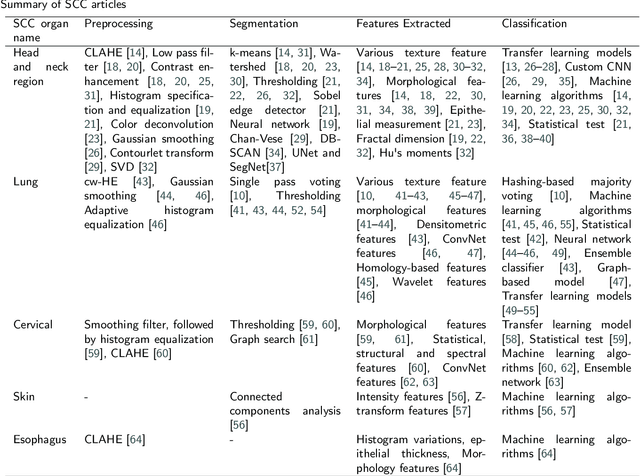
Histopathological image analysis is the gold standard to diagnose cancer. Carcinoma is a subtype of cancer that constitutes more than 80% of all cancer cases. Squamous cell carcinoma and adenocarcinoma are two major subtypes of carcinoma, diagnosed by microscopic study of biopsy slides. However, manual microscopic evaluation is a subjective and time-consuming process. Many researchers have reported methods to automate carcinoma detection and classification. The increasing use of artificial intelligence (AI) in the automation of carcinoma diagnosis also reveals a significant rise in the use of deep network models. In this systematic literature review, we present a comprehensive review of the state-of-the-art approaches reported in carcinoma diagnosis using histopathological images. Studies are selected from well-known databases with strict inclusion/exclusion criteria. We have categorized the articles and recapitulated their methods based on specific organs of carcinoma origin. Further, we have summarized pertinent literature on AI methods, highlighted critical challenges and limitations, and provided insights on future research direction in automated carcinoma diagnosis. Out of 101 articles selected, most of the studies experimented on private datasets with varied image sizes, obtaining accuracy between 63% and 100%. Overall, this review highlights the need for a generalized AI-based carcinoma diagnostic system. Additionally, it is desirable to have accountable approaches to extract microscopic features from images of multiple magnifications that should mimic pathologists' evaluations.
Parallel Neural Local Lossless Compression
Jan 23, 2022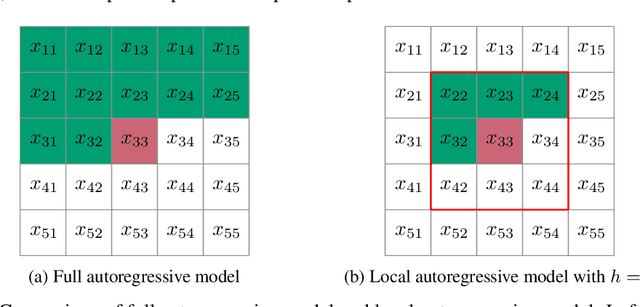
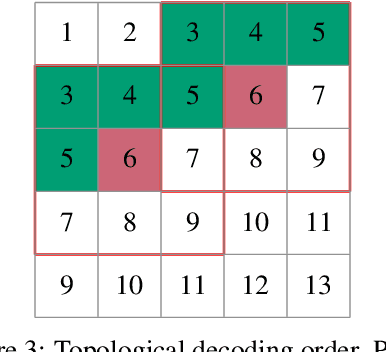

The recently proposed Neural Local Lossless Compression (NeLLoC), which is based on a local autoregressive model, has achieved state-of-the-art (SOTA) out-of-distribution (OOD) generalization performance in the image compression task. In addition to the encouragement of OOD generalization, the local model also allows parallel inference in the decoding stage. In this paper, we propose a parallelization scheme for local autoregressive models. We discuss the practicalities of implementing this scheme, and provide experimental evidence of significant gains in compression runtime compared to the previous, non-parallel implementation.
A Bag of Visual Words Model for Medical Image Retrieval
Jul 18, 2020
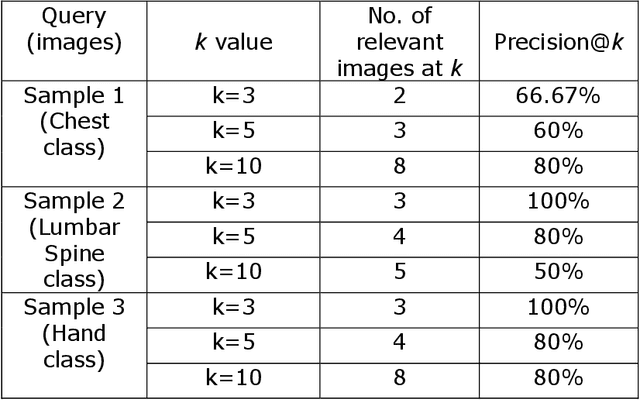
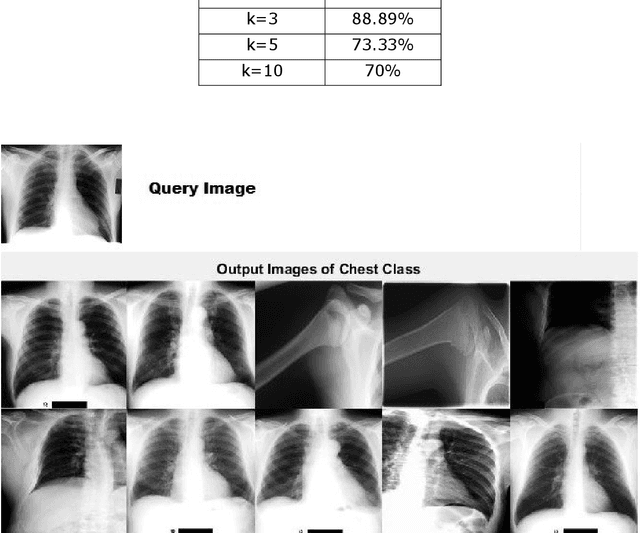
Medical Image Retrieval is a challenging field in Visual information retrieval, due to the multi-dimensional and multi-modal context of the underlying content. Traditional models often fail to take the intrinsic characteristics of data into consideration, and have thus achieved limited accuracy when applied to medical images. The Bag of Visual Words (BoVW) is a technique that can be used to effectively represent intrinsic image features in vector space, so that applications like image classification and similar-image search can be optimized. In this paper, we present a MedIR approach based on the BoVW model for content-based medical image retrieval. As medical images as multi-dimensional, they exhibit underlying cluster and manifold information which enhances semantic relevance and allows for label uniformity. Hence, the BoVW features extracted for each image are used to train a supervised machine learning classifier based on positive and negative training images, for extending content based image retrieval. During experimental validation, the proposed model performed very well, achieving a Mean Average Precision of 88.89% during top-3 image retrieval experiments.
Implicit Data Augmentation Using Feature Interpolation for Diversified Low-Shot Image Generation
Dec 04, 2021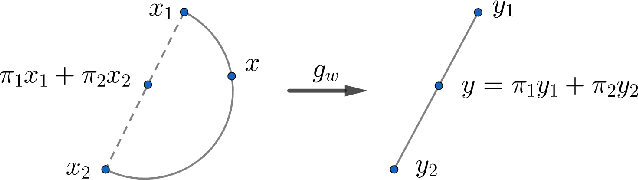
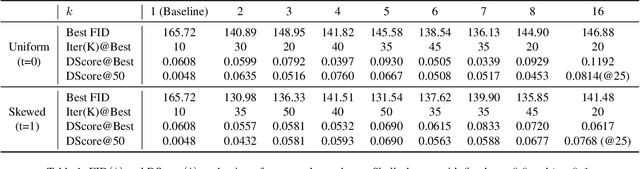
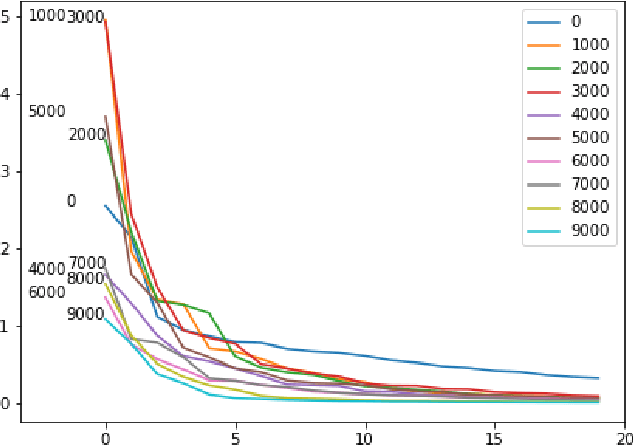
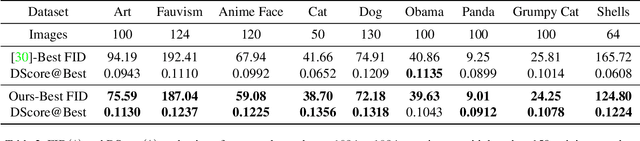
Training of generative models especially Generative Adversarial Networks can easily diverge in low-data setting. To mitigate this issue, we propose a novel implicit data augmentation approach which facilitates stable training and synthesize diverse samples. Specifically, we view the discriminator as a metric embedding of the real data manifold, which offers proper distances between real data points. We then utilize information in the feature space to develop a data-driven augmentation method. We further bring up a simple metric to evaluate the diversity of synthesized samples. Experiments on few-shot generation tasks show our method improves FID and diversity of results compared to current methods, and allows generating high-quality and diverse images with less than 100 training samples.
Activation Modulation and Recalibration Scheme for Weakly Supervised Semantic Segmentation
Dec 16, 2021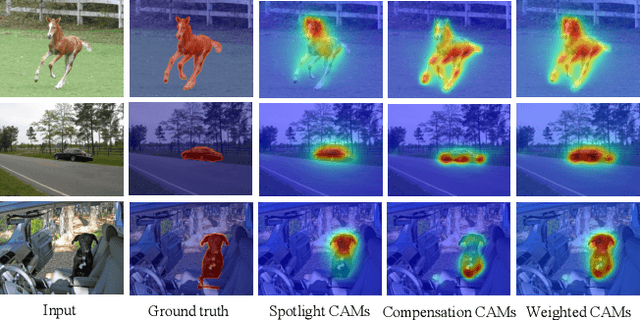
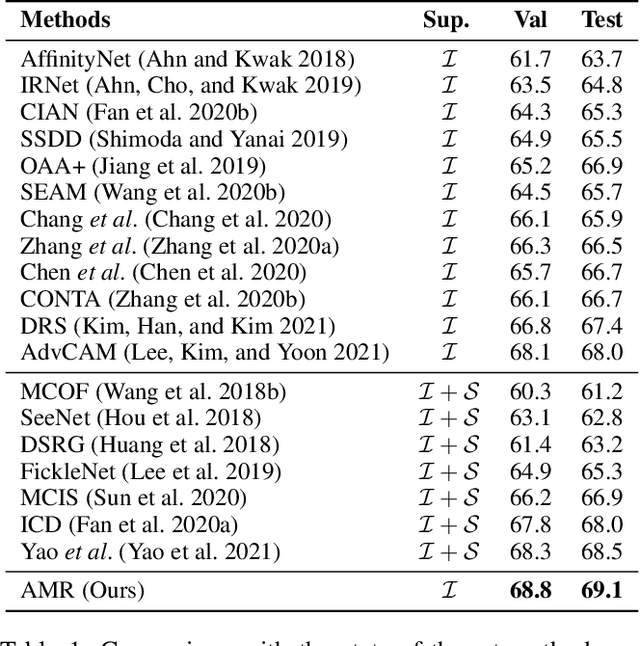
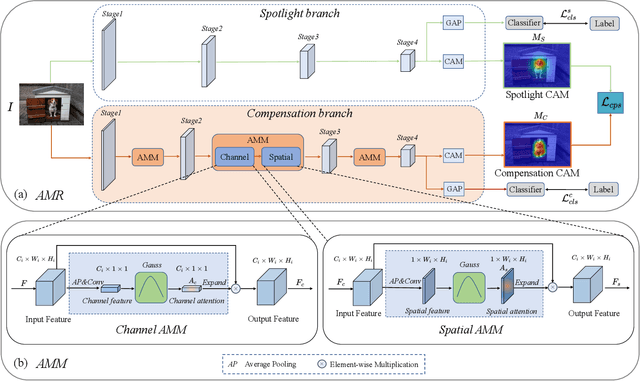
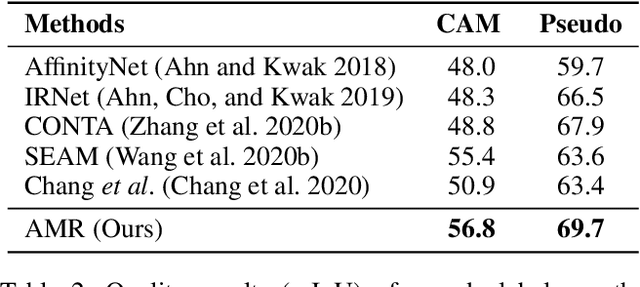
Image-level weakly supervised semantic segmentation (WSSS) is a fundamental yet challenging computer vision task facilitating scene understanding and automatic driving. Most existing methods resort to classification-based Class Activation Maps (CAMs) to play as the initial pseudo labels, which tend to focus on the discriminative image regions and lack customized characteristics for the segmentation task. To alleviate this issue, we propose a novel activation modulation and recalibration (AMR) scheme, which leverages a spotlight branch and a compensation branch to obtain weighted CAMs that can provide recalibration supervision and task-specific concepts. Specifically, an attention modulation module (AMM) is employed to rearrange the distribution of feature importance from the channel-spatial sequential perspective, which helps to explicitly model channel-wise interdependencies and spatial encodings to adaptively modulate segmentation-oriented activation responses. Furthermore, we introduce a cross pseudo supervision for dual branches, which can be regarded as a semantic similar regularization to mutually refine two branches. Extensive experiments show that AMR establishes a new state-of-the-art performance on the PASCAL VOC 2012 dataset, surpassing not only current methods trained with the image-level of supervision but also some methods relying on stronger supervision, such as saliency label. Experiments also reveal that our scheme is plug-and-play and can be incorporated with other approaches to boost their performance.
Structural Beauty: A Structure-based Approach to Quantifying the Beauty of an Image
Apr 16, 2021
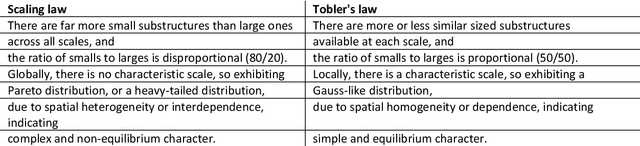
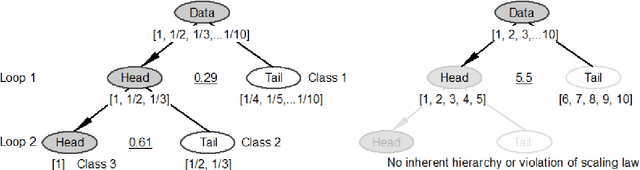

To say that beauty is in the eye of the beholder means that beauty is largely subjective so varies from person to person. While the subjectivity view is commonly held, there is also an objectivity view that seeks to measure beauty or aesthetics in some quantitative manners. Christopher Alexander has long discovered that beauty or coherence highly correlates to the number of subsymmetries or substructures and demonstrated that there is a shared notion of beauty - structural beauty - among people and even different peoples, regardless of their faiths, cultures, and ethnicities. This notion of structural beauty arises directly out of living structure or wholeness, a physical and mathematical structure that underlies all space and matter. Based on the concept of living structure, this paper develops an approach for computing the structural beauty or life of an image (L) based on the number of automatically derived substructures (S) and their inherent hierarchy (H). To verify this approach, we conducted a series of case studies applied to eight pairs of images including Leonardo da Vinci's Mona Lisa and Jackson Pollock's Blue Poles. We discovered among others that Blue Poles is more structurally beautiful than the Mona Lisa, and traditional buildings are in general more structurally beautiful than their modernist counterparts. This finding implies that goodness of things or images is largely a matter of fact rather than an opinion or personal preference as conventionally conceived. The research on structural beauty has deep implications on many disciplines, where beauty or aesthetics is a major concern such as image understanding and computer vision, architecture and urban design, humanities and arts, neurophysiology, and psychology. Keywords: Life; wholeness; figural goodness; head/tail breaks; computer vision
Benchmarking Test-Time Unsupervised Deep Neural Network Adaptation on Edge Devices
Mar 21, 2022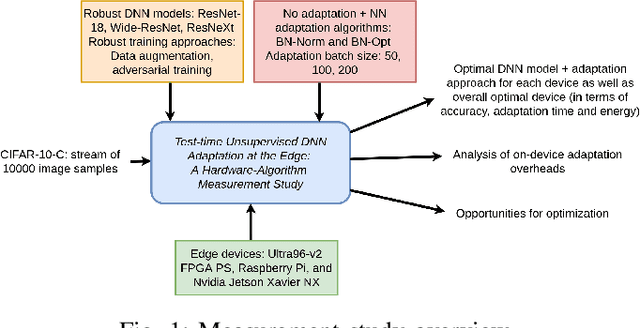
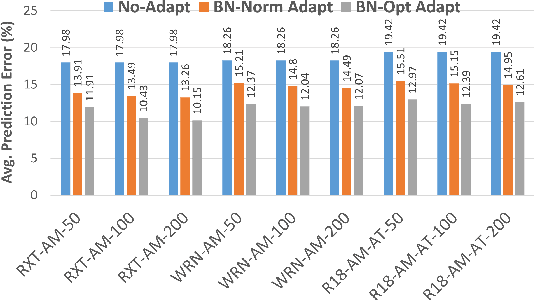
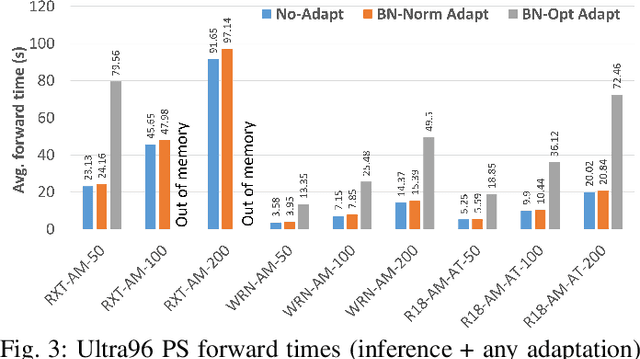
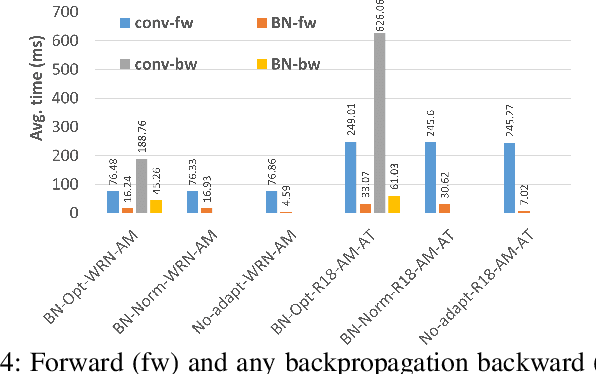
The prediction accuracy of the deep neural networks (DNNs) after deployment at the edge can suffer with time due to shifts in the distribution of the new data. To improve robustness of DNNs, they must be able to update themselves to enhance their prediction accuracy. This adaptation at the resource-constrained edge is challenging as: (i) new labeled data may not be present; (ii) adaptation needs to be on device as connections to cloud may not be available; and (iii) the process must not only be fast but also memory- and energy-efficient. Recently, lightweight prediction-time unsupervised DNN adaptation techniques have been introduced that improve prediction accuracy of the models for noisy data by re-tuning the batch normalization (BN) parameters. This paper, for the first time, performs a comprehensive measurement study of such techniques to quantify their performance and energy on various edge devices as well as find bottlenecks and propose optimization opportunities. In particular, this study considers CIFAR-10-C image classification dataset with corruptions, three robust DNNs (ResNeXt, Wide-ResNet, ResNet-18), two BN adaptation algorithms (one that updates normalization statistics and the other that also optimizes transformation parameters), and three edge devices (FPGA, Raspberry-Pi, and Nvidia Xavier NX). We find that the approach that only updates the normalization parameters with Wide-ResNet, running on Xavier GPU, to be overall effective in terms of balancing multiple cost metrics. However, the adaptation overhead can still be significant (around 213 ms). The results strongly motivate the need for algorithm-hardware co-design for efficient on-device DNN adaptation.