 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Bayesian Image Reconstruction using Deep Generative Models
Dec 08, 2020
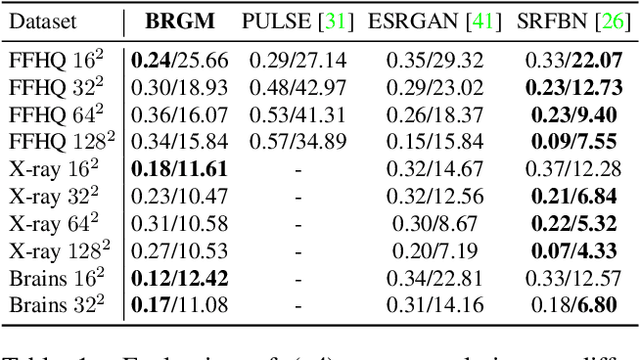
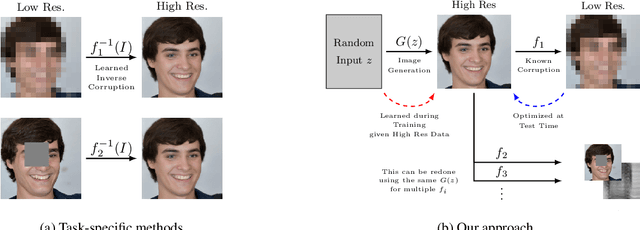
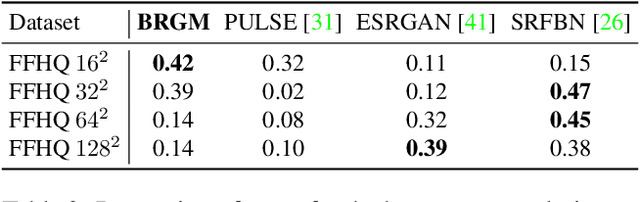

Machine learning models are commonly trained end-to-end and in a supervised setting, using paired (input, output) data. Classical examples include recent super-resolution methods that train on pairs of (low-resolution, high-resolution) images. However, these end-to-end approaches require re-training every time there is a distribution shift in the inputs (e.g., night images vs daylight) or relevant latent variables (e.g., camera blur or hand motion). In this work, we leverage state-of-the-art (SOTA) generative models (here StyleGAN2) for building powerful image priors, which enable application of Bayes' theorem for many downstream reconstruction tasks. Our method, called Bayesian Reconstruction through Generative Models (BRGM), uses a single pre-trained generator model to solve different image restoration tasks, i.e., super-resolution and in-painting, by combining it with different forward corruption models. We demonstrate BRGM on three large, yet diverse, datasets that enable us to build powerful priors: (i) 60,000 images from the Flick Faces High Quality dataset \cite{karras2019style} (ii) 240,000 chest X-rays from MIMIC III and (iii) a combined collection of 5 brain MRI datasets with 7,329 scans. Across all three datasets and without any dataset-specific hyperparameter tuning, our approach yields state-of-the-art performance on super-resolution, particularly at low-resolution levels, as well as inpainting, compared to state-of-the-art methods that are specific to each reconstruction task. We will make our code and pre-trained models available online.
Deep neural networks-based denoising models for CT imaging and their efficacy
Nov 18, 2021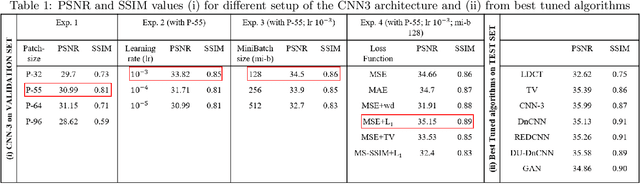
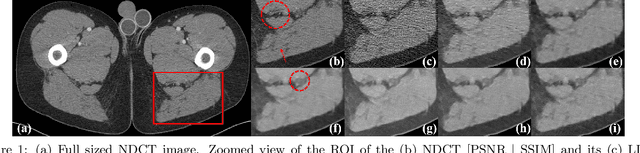
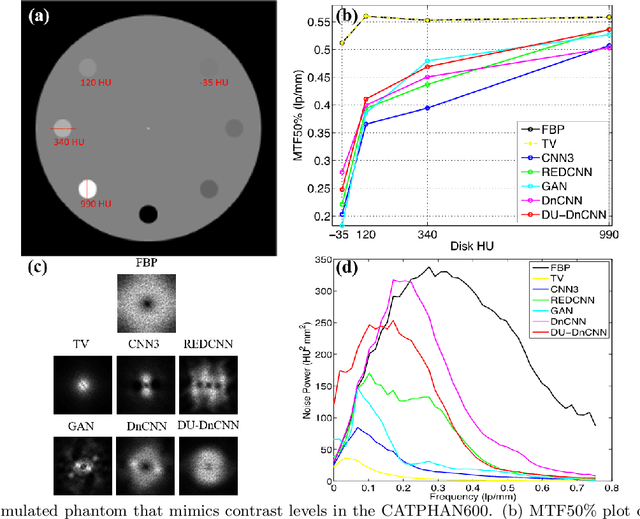
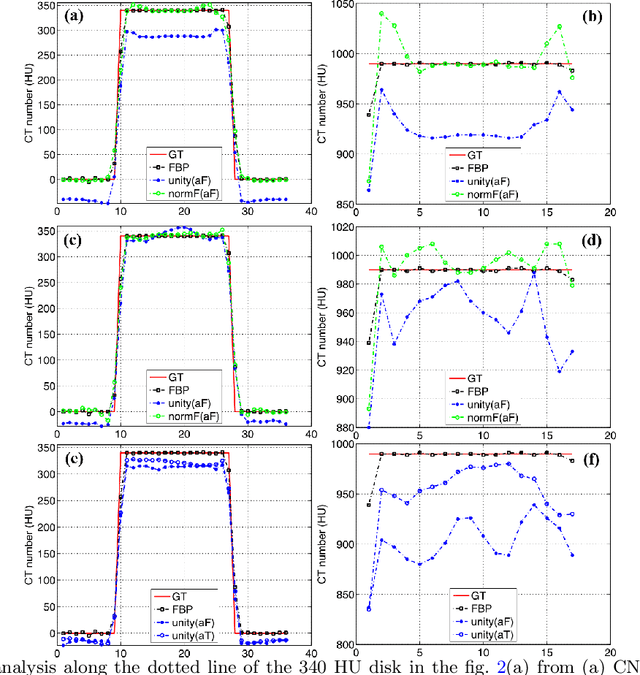
Most of the Deep Neural Networks (DNNs) based CT image denoising literature shows that DNNs outperform traditional iterative methods in terms of metrics such as the RMSE, the PSNR and the SSIM. In many instances, using the same metrics, the DNN results from low-dose inputs are also shown to be comparable to their high-dose counterparts. However, these metrics do not reveal if the DNN results preserve the visibility of subtle lesions or if they alter the CT image properties such as the noise texture. Accordingly, in this work, we seek to examine the image quality of the DNN results from a holistic viewpoint for low-dose CT image denoising. First, we build a library of advanced DNN denoising architectures. This library is comprised of denoising architectures such as the DnCNN, U-Net, Red-Net, GAN, etc. Next, each network is modeled, as well as trained, such that it yields its best performance in terms of the PSNR and SSIM. As such, data inputs (e.g. training patch-size, reconstruction kernel) and numeric-optimizer inputs (e.g. minibatch size, learning rate, loss function) are accordingly tuned. Finally, outputs from thus trained networks are further subjected to a series of CT bench testing metrics such as the contrast-dependent MTF, the NPS and the HU accuracy. These metrics are employed to perform a more nuanced study of the resolution of the DNN outputs' low-contrast features, their noise textures, and their CT number accuracy to better understand the impact each DNN algorithm has on these underlying attributes of image quality.
* 13 pages, 9 figures, SPIE proceeding
High-Accuracy RGB-D Face Recognition via Segmentation-Aware Face Depth Estimation and Mask-Guided Attention Network
Dec 22, 2021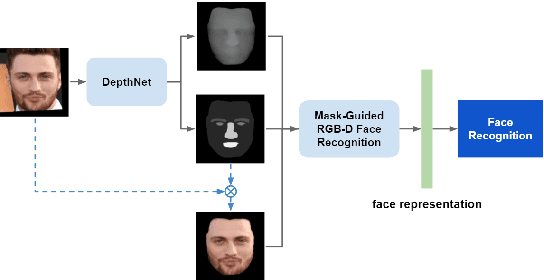
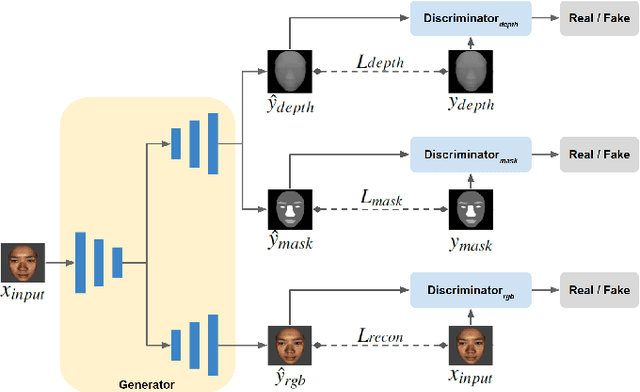
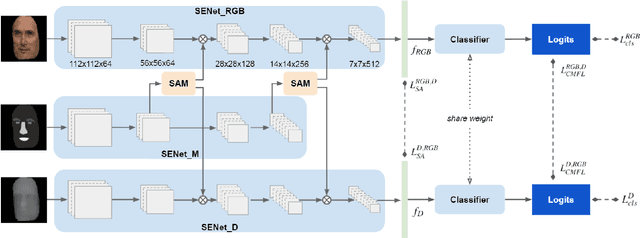

Deep learning approaches have achieved highly accurate face recognition by training the models with very large face image datasets. Unlike the availability of large 2D face image datasets, there is a lack of large 3D face datasets available to the public. Existing public 3D face datasets were usually collected with few subjects, leading to the over-fitting problem. This paper proposes two CNN models to improve the RGB-D face recognition task. The first is a segmentation-aware depth estimation network, called DepthNet, which estimates depth maps from RGB face images by including semantic segmentation information for more accurate face region localization. The other is a novel mask-guided RGB-D face recognition model that contains an RGB recognition branch, a depth map recognition branch, and an auxiliary segmentation mask branch with a spatial attention module. Our DepthNet is used to augment a large 2D face image dataset to a large RGB-D face dataset, which is used for training an accurate RGB-D face recognition model. Furthermore, the proposed mask-guided RGB-D face recognition model can fully exploit the depth map and segmentation mask information and is more robust against pose variation than previous methods. Our experimental results show that DepthNet can produce more reliable depth maps from face images with the segmentation mask. Our mask-guided face recognition model outperforms state-of-the-art methods on several public 3D face datasets.
CLIP meets GamePhysics: Towards bug identification in gameplay videos using zero-shot transfer learning
Mar 22, 2022
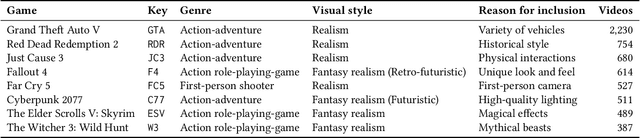

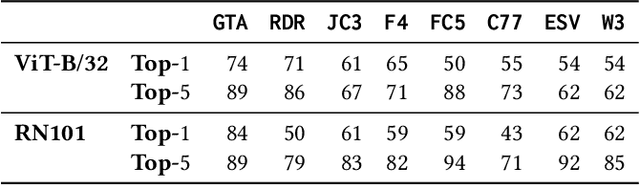
Gameplay videos contain rich information about how players interact with the game and how the game responds. Sharing gameplay videos on social media platforms, such as Reddit, has become a common practice for many players. Often, players will share gameplay videos that showcase video game bugs. Such gameplay videos are software artifacts that can be utilized for game testing, as they provide insight for bug analysis. Although large repositories of gameplay videos exist, parsing and mining them in an effective and structured fashion has still remained a big challenge. In this paper, we propose a search method that accepts any English text query as input to retrieve relevant videos from large repositories of gameplay videos. Our approach does not rely on any external information (such as video metadata); it works solely based on the content of the video. By leveraging the zero-shot transfer capabilities of the Contrastive Language-Image Pre-Training (CLIP) model, our approach does not require any data labeling or training. To evaluate our approach, we present the $\texttt{GamePhysics}$ dataset consisting of 26,954 videos from 1,873 games, that were collected from the GamePhysics section on the Reddit website. Our approach shows promising results in our extensive analysis of simple queries, compound queries, and bug queries, indicating that our approach is useful for object and event detection in gameplay videos. An example application of our approach is as a gameplay video search engine to aid in reproducing video game bugs. Please visit the following link for the code and the data: https://asgaardlab.github.io/CLIPxGamePhysics/
Towards Streaming Image Understanding
May 21, 2020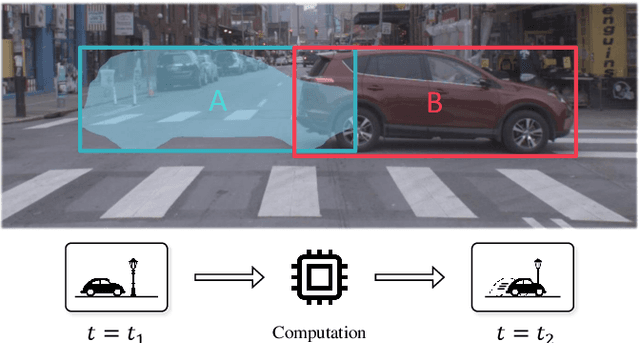
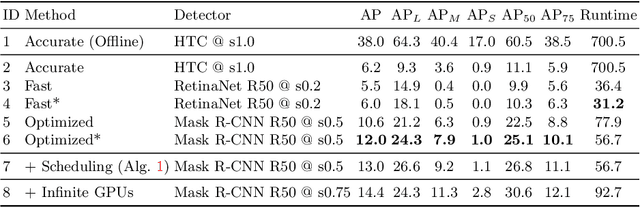
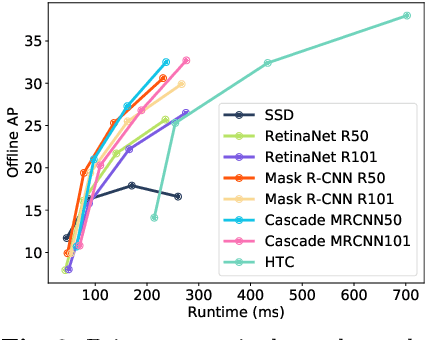

Embodied perception refers to the ability of an autonomous agent to perceive its environment so that it can (re)act. The responsiveness of the agent is largely governed by latency of its processing pipeline. While past work has studied the algorithmic trade-off between latency and accuracy, there has not been a clear metric to compare different methods along the Pareto optimal latency-accuracy curve. We point out a discrepancy between standard offline evaluation and real-time applications: by the time an algorithm finishes processing a particular image frame, the surrounding world has changed. To these ends, we present an approach that coherently integrates latency and accuracy into a single metric for real-time online perception, which we refer to as "streaming accuracy". The key insight behind this metric is to jointly evaluate the output of the entire perception stack at every time instant, forcing the stack to consider the amount of streaming data that should be ignored while computation is occurring. More broadly, building upon this metric, we introduce a meta-benchmark that systematically converts any image understanding task into a streaming image understanding task. We focus on the illustrative tasks of object detection and instance segmentation in urban video streams, and contribute a novel dataset with high-quality and temporally-dense annotations. Our proposed solutions and their empirical analysis demonstrate a number of surprising conclusions: (1) there exists an optimal "sweet spot" that maximizes streaming accuracy along the Pareto optimal latency-accuracy curve, (2) asynchronous tracking and future forecasting naturally emerge as internal representations that enable streaming image understanding, and (3) dynamic scheduling can be used to overcome temporal aliasing, yielding the paradoxical result that latency is sometimes minimized by sitting idle and "doing nothing".
SAGE: SLAM with Appearance and Geometry Prior for Endoscopy
Feb 22, 2022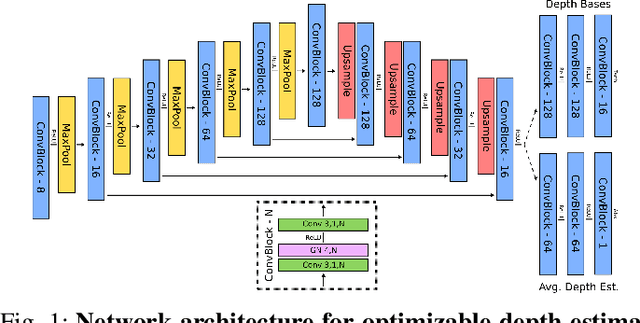
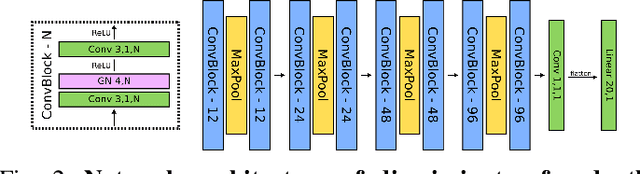
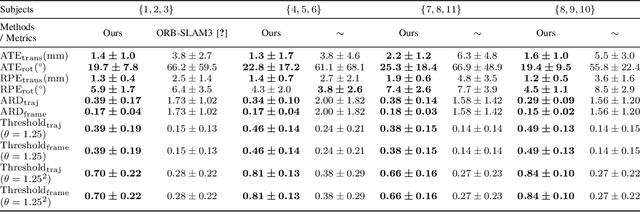
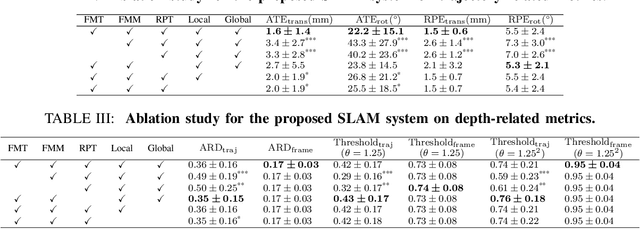
In endoscopy, many applications (e.g., surgical navigation) would benefit from a real-time method that can simultaneously track the endoscope and reconstruct the dense 3D geometry of the observed anatomy from a monocular endoscopic video. To this end, we develop a Simultaneous Localization and Mapping system by combining the learning-based appearance and optimizable geometry priors and factor graph optimization. The appearance and geometry priors are explicitly learned in an end-to-end differentiable training pipeline to master the task of pair-wise image alignment, one of the core components of the SLAM system. In our experiments, the proposed SLAM system is shown to robustly handle the challenges of texture scarceness and illumination variation that are commonly seen in endoscopy. The system generalizes well to unseen endoscopes and subjects and performs favorably compared with a state-of-the-art feature-based SLAM system. The code repository is available at https://github.com/lppllppl920/SAGE-SLAM.git.
Image Analysis Based on Nonnegative/Binary Matrix Factorization
Jul 02, 2020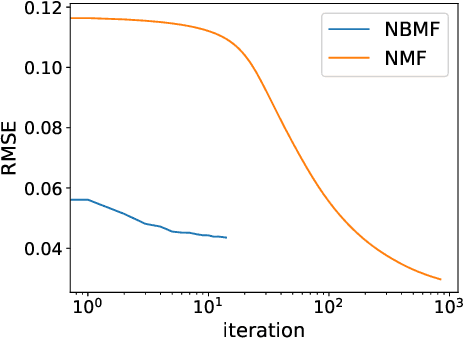
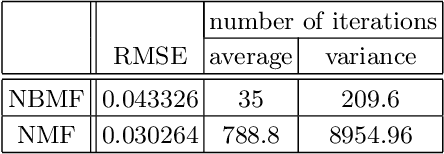
Using nonnegative/binary matrix factorization (NBMF), a matrix can be decomposed into a nonnegative matrix and a binary matrix. Our analysis of facial images, based on NBMF and using the Fujitsu Digital Annealer, leads to successful image reconstruction and image classification. The NBMF algorithm converges in fewer iterations than those required for the convergence of nonnegative matrix factorization (NMF), although both techniques perform comparably in image classification.
* 3 pages, 1 figure
Rib Suppression in Digital Chest Tomosynthesis
Mar 05, 2022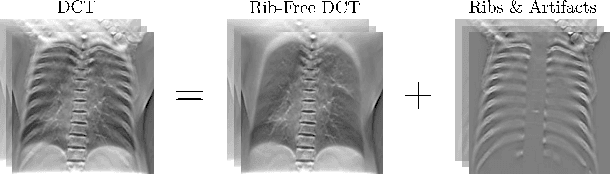
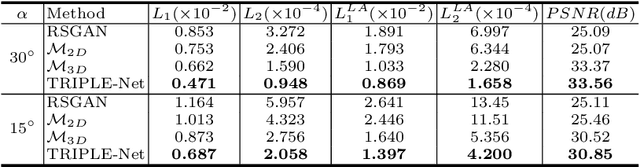
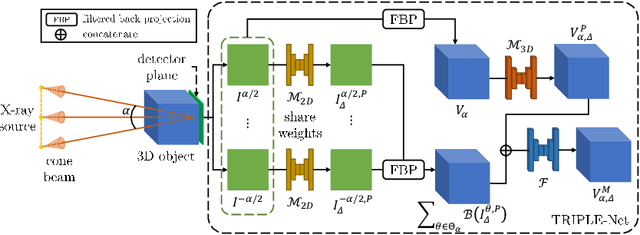
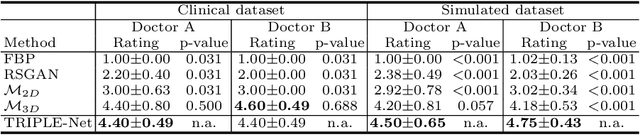
Digital chest tomosynthesis (DCT) is a technique to produce sectional 3D images of a human chest for pulmonary disease screening, with 2D X-ray projections taken within an extremely limited range of angles. However, under the limited angle scenario, DCT contains strong artifacts caused by the presence of ribs, jamming the imaging quality of the lung area. Recently, great progress has been achieved for rib suppression in a single X-ray image, to reveal a clearer lung texture. We firstly extend the rib suppression problem to the 3D case at the software level. We propose a $\textbf{T}$omosynthesis $\textbf{RI}$b Su$\textbf{P}$pression and $\textbf{L}$ung $\textbf{E}$nhancement $\textbf{Net}$work (TRIPLE-Net) to model the 3D rib component and provide a rib-free DCT. TRIPLE-Net takes the advantages from both 2D and 3D domains, which model the ribs in DCT with the exact FBP procedure and 3D depth information, respectively. The experiments on simulated datasets and clinical data have shown the effectiveness of TRIPLE-Net to preserve lung details as well as improve the imaging quality of pulmonary diseases. Finally, an expert user study confirms our findings.
Focal Modulation Networks
Mar 22, 2022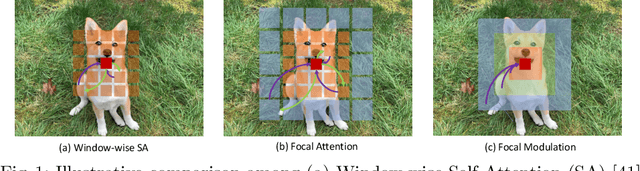
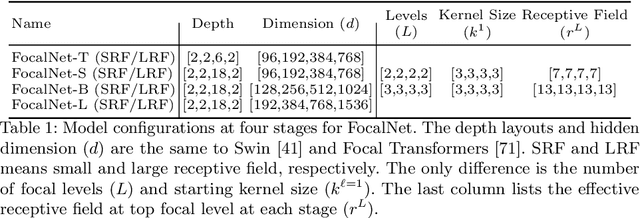
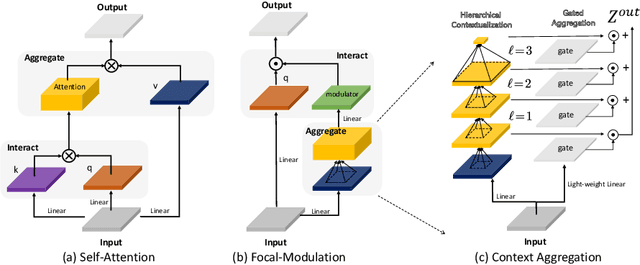
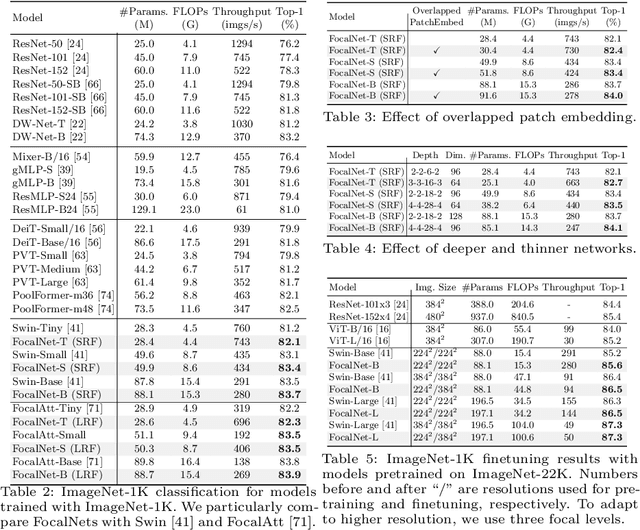
In this work, we propose focal modulation network (FocalNet in short), where self-attention (SA) is completely replaced by a focal modulation module that is more effective and efficient for modeling token interactions. Focal modulation comprises three components: $(i)$ hierarchical contextualization, implemented using a stack of depth-wise convolutional layers, to encode visual contexts from short to long ranges at different granularity levels, $(ii)$ gated aggregation to selectively aggregate context features for each visual token (query) based on its content, and $(iii)$ modulation or element-wise affine transformation to fuse the aggregated features into the query vector. Extensive experiments show that FocalNets outperform the state-of-the-art SA counterparts (e.g., Swin Transformers) with similar time and memory cost on the tasks of image classification, object detection, and semantic segmentation. Specifically, our FocalNets with tiny and base sizes achieve 82.3% and 83.9% top-1 accuracy on ImageNet-1K. After pretrained on ImageNet-22K, it attains 86.5% and 87.3% top-1 accuracy when finetuned with resolution 224$\times$224 and 384$\times$384, respectively. FocalNets exhibit remarkable superiority when transferred to downstream tasks. For object detection with Mask R-CNN, our FocalNet base trained with 1$\times$ already surpasses Swin trained with 3$\times$ schedule (49.0 v.s. 48.5). For semantic segmentation with UperNet, FocalNet base evaluated at single-scale outperforms Swin evaluated at multi-scale (50.5 v.s. 49.7). These results render focal modulation a favorable alternative to SA for effective and efficient visual modeling in real-world applications. Code is available at https://github.com/microsoft/FocalNet.
Masked Autoencoders Are Scalable Vision Learners
Dec 02, 2021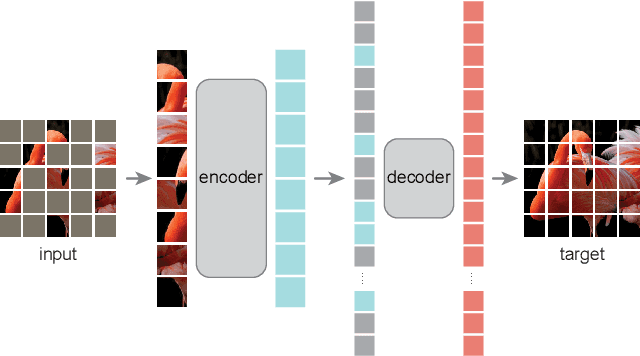
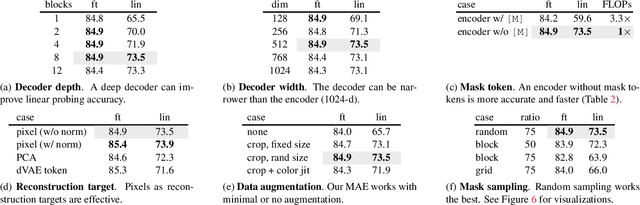

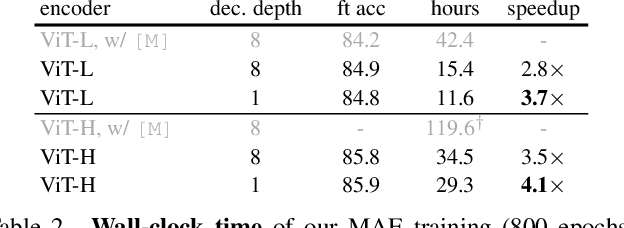
This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the input image and reconstruct the missing pixels. It is based on two core designs. First, we develop an asymmetric encoder-decoder architecture, with an encoder that operates only on the visible subset of patches (without mask tokens), along with a lightweight decoder that reconstructs the original image from the latent representation and mask tokens. Second, we find that masking a high proportion of the input image, e.g., 75%, yields a nontrivial and meaningful self-supervisory task. Coupling these two designs enables us to train large models efficiently and effectively: we accelerate training (by 3x or more) and improve accuracy. Our scalable approach allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data. Transfer performance in downstream tasks outperforms supervised pre-training and shows promising scaling behavior.