 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
End-to-End Learning of Multi-category 3D Pose and Shape Estimation
Dec 19, 2021

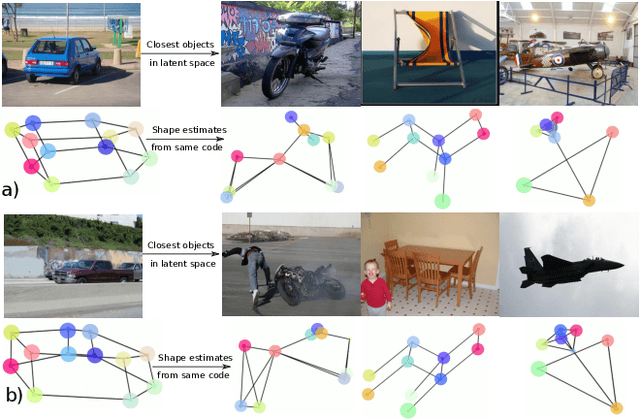
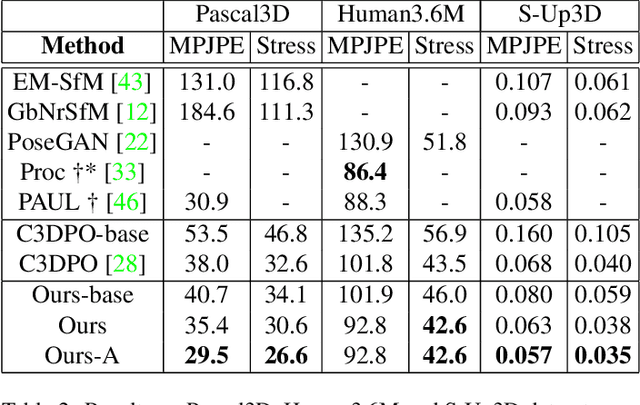
In this paper, we study the representation of the shape and pose of objects using their keypoints. Therefore, we propose an end-to-end method that simultaneously detects 2D keypoints from an image and lifts them to 3D. The proposed method learns both 2D detection and 3D lifting only from 2D keypoints annotations. In this regard, a novel method that explicitly disentangles the pose and 3D shape by means of augmentation-based cyclic self-supervision is proposed, for the first time. In addition of being end-to-end in image to 3D learning, our method also handles objects from multiple categories using a single neural network. We use a Transformer-based architecture to detect the keypoints, as well as to summarize the visual context of the image. This visual context information is then used while lifting the keypoints to 3D, so as to allow the context-based reasoning for better performance. While lifting, our method learns a small set of basis shapes and their sparse non-negative coefficients to represent the 3D shape in canonical frame. Our method can handle occlusions as well as wide variety of object classes. Our experiments on three benchmarks demonstrate that our method performs better than the state-of-the-art. Our source code will be made publicly available.
Convolutional versus Self-Organized Operational Neural Networks for Real-World Blind Image Denoising
Mar 04, 2021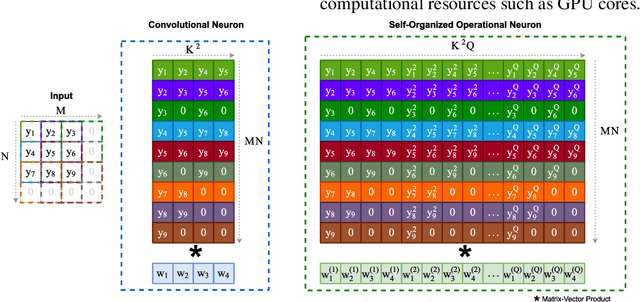
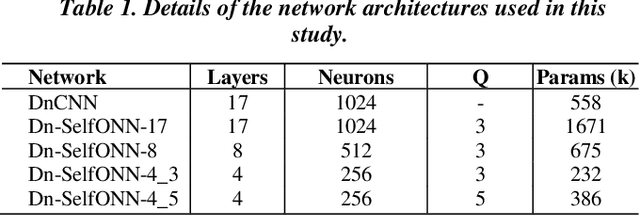
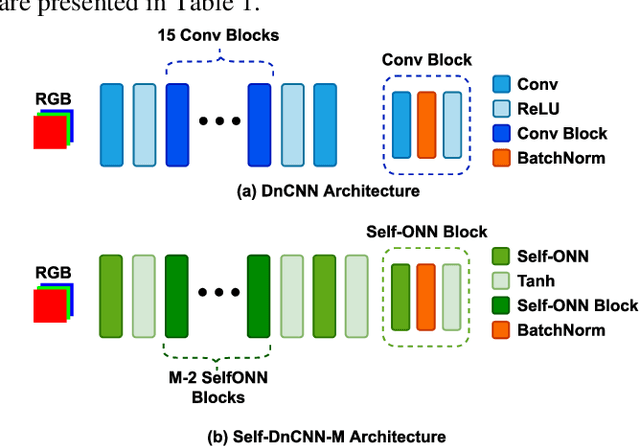
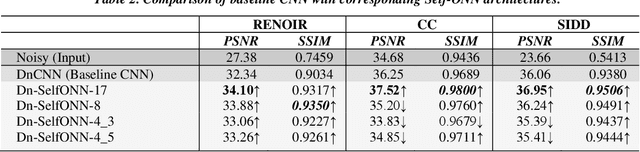
Real-world blind denoising poses a unique image restoration challenge due to the non-deterministic nature of the underlying noise distribution. Prevalent discriminative networks trained on synthetic noise models have been shown to generalize poorly to real-world noisy images. While curating real-world noisy images and improving ground truth estimation procedures remain key points of interest, a potential research direction is to explore extensions to the widely used convolutional neuron model to enable better generalization with fewer data and lower network complexity, as opposed to simply using deeper Convolutional Neural Networks (CNNs). Operational Neural Networks (ONNs) and their recent variant, Self-organized ONNs (Self-ONNs), propose to embed enhanced non-linearity into the neuron model and have been shown to outperform CNNs across a variety of regression tasks. However, all such comparisons have been made for compact networks and the efficacy of deploying operational layers as a drop-in replacement for convolutional layers in contemporary deep architectures remains to be seen. In this work, we tackle the real-world blind image denoising problem by employing, for the first time, a deep Self-ONN. Extensive quantitative and qualitative evaluations spanning multiple metrics and four high-resolution real-world noisy image datasets against the state-of-the-art deep CNN network, DnCNN, reveal that deep Self-ONNs consistently achieve superior results with performance gains of up to 1.76dB in PSNR. Furthermore, Self-ONNs with half and even quarter the number of layers that require only a fraction of computational resources as that of DnCNN can still achieve similar or better results compared to the state-of-the-art.
Image-based Portrait Engraving
Aug 12, 2020



This paper describes a simple image-based method that applies engraving stylisation to portraits using ordered dithering. Face detection is used to estimate a rough proxy geometry of the head consisting of a cylinder, which is used to warp the dither matrix, causing the engraving lines to curve around the face for better stylisation. Finally, an application of the approach to colour engraving is demonstrated.
QDrop: Randomly Dropping Quantization for Extremely Low-bit Post-Training Quantization
Mar 11, 2022
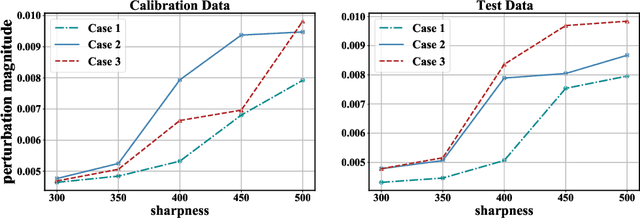

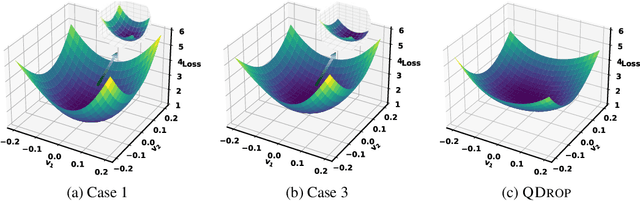
Recently, post-training quantization (PTQ) has driven much attention to produce efficient neural networks without long-time retraining. Despite its low cost, current PTQ works tend to fail under the extremely low-bit setting. In this study, we pioneeringly confirm that properly incorporating activation quantization into the PTQ reconstruction benefits the final accuracy. To deeply understand the inherent reason, a theoretical framework is established, indicating that the flatness of the optimized low-bit model on calibration and test data is crucial. Based on the conclusion, a simple yet effective approach dubbed as QDROP is proposed, which randomly drops the quantization of activations during PTQ. Extensive experiments on various tasks including computer vision (image classification, object detection) and natural language processing (text classification and question answering) prove its superiority. With QDROP, the limit of PTQ is pushed to the 2-bit activation for the first time and the accuracy boost can be up to 51.49%. Without bells and whistles, QDROP establishes a new state of the art for PTQ. Our code is available at https://github.com/wimh966/QDrop and has been integrated into MQBench (https://github.com/ModelTC/MQBench)
Domain Generalization via Shuffled Style Assembly for Face Anti-Spoofing
Mar 11, 2022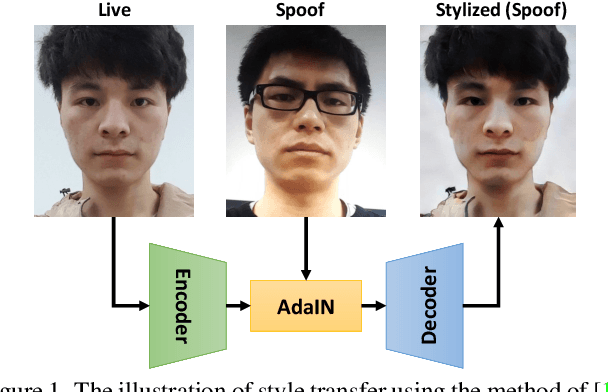
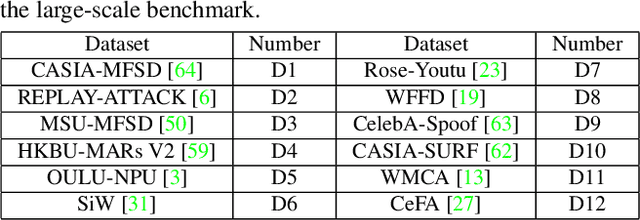
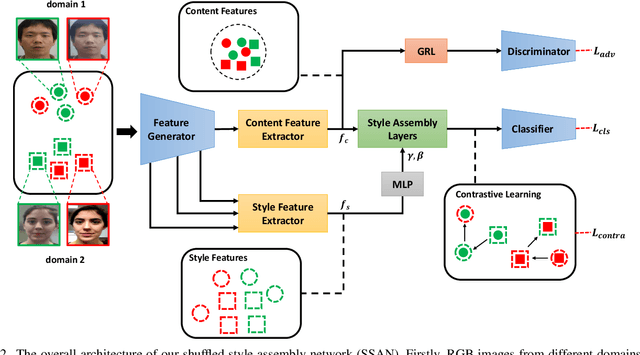
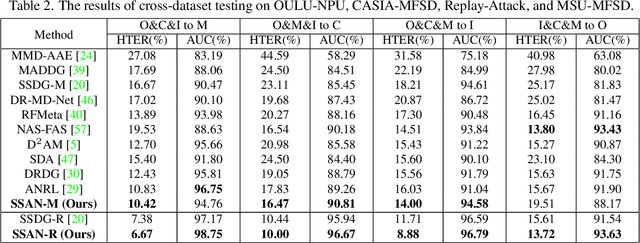
With diverse presentation attacks emerging continually, generalizable face anti-spoofing (FAS) has drawn growing attention. Most existing methods implement domain generalization (DG) on the complete representations. However, different image statistics may have unique properties for the FAS tasks. In this work, we separate the complete representation into content and style ones. A novel Shuffled Style Assembly Network (SSAN) is proposed to extract and reassemble different content and style features for a stylized feature space. Then, to obtain a generalized representation, a contrastive learning strategy is developed to emphasize liveness-related style information while suppress the domain-specific one. Finally, the representations of the correct assemblies are used to distinguish between living and spoofing during the inferring. On the other hand, despite the decent performance, there still exists a gap between academia and industry, due to the difference in data quantity and distribution. Thus, a new large-scale benchmark for FAS is built up to further evaluate the performance of algorithms in reality. Both qualitative and quantitative results on existing and proposed benchmarks demonstrate the effectiveness of our methods. The codes will be available at https://github.com/wangzhuo2019/SSAN.
Shed Various Lights on a Low-Light Image: Multi-Level Enhancement Guided by Arbitrary References
Jan 04, 2021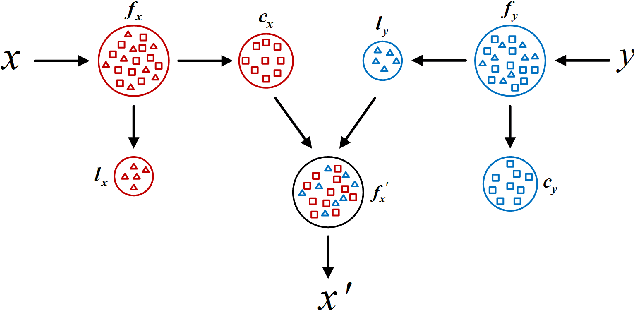


It is suggested that low-light image enhancement realizes one-to-many mapping since we have different definitions of NORMAL-light given application scenarios or users' aesthetic. However, most existing methods ignore subjectivity of the task, and simply produce one result with fixed brightness. This paper proposes a neural network for multi-level low-light image enhancement, which is user-friendly to meet various requirements by selecting different images as brightness reference. Inspired by style transfer, our method decomposes an image into two low-coupling feature components in the latent space, which allows the concatenation feasibility of the content components from low-light images and the luminance components from reference images. In such a way, the network learns to extract scene-invariant and brightness-specific information from a set of image pairs instead of learning brightness differences. Moreover, information except for the brightness is preserved to the greatest extent to alleviate color distortion. Extensive results show strong capacity and superiority of our network against existing methods.
Invariance Learning in Deep Neural Networks with Differentiable Laplace Approximations
Feb 22, 2022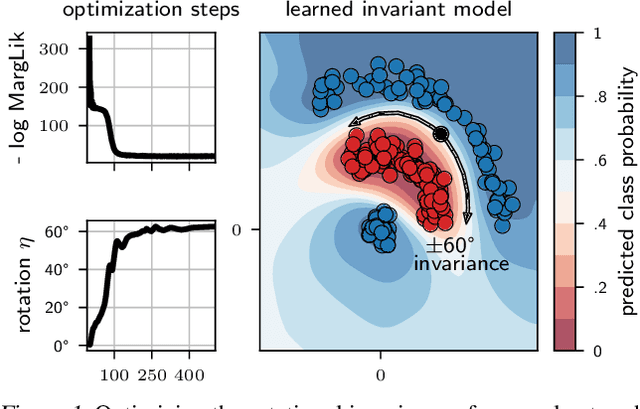
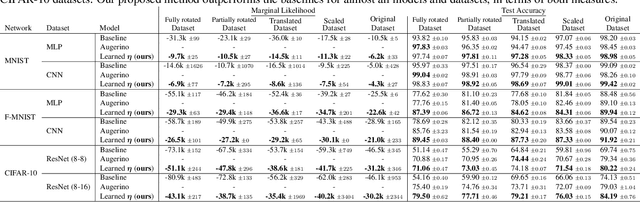
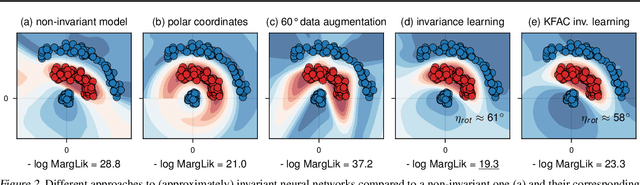

Data augmentation is commonly applied to improve performance of deep learning by enforcing the knowledge that certain transformations on the input preserve the output. Currently, the correct data augmentation is chosen by human effort and costly cross-validation, which makes it cumbersome to apply to new datasets. We develop a convenient gradient-based method for selecting the data augmentation. Our approach relies on phrasing data augmentation as an invariance in the prior distribution and learning it using Bayesian model selection, which has been shown to work in Gaussian processes, but not yet for deep neural networks. We use a differentiable Kronecker-factored Laplace approximation to the marginal likelihood as our objective, which can be optimised without human supervision or validation data. We show that our method can successfully recover invariances present in the data, and that this improves generalisation on image datasets.
Towards performant and reliable undersampled MR reconstruction via diffusion model sampling
Mar 11, 2022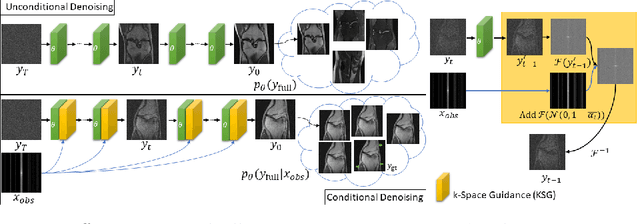
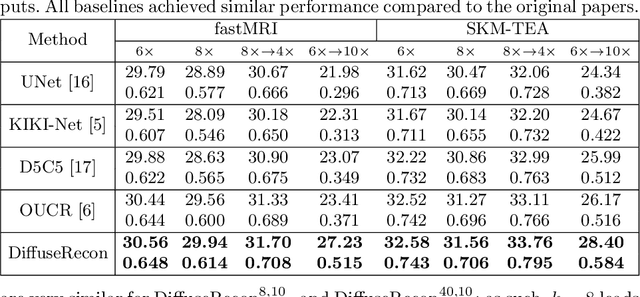
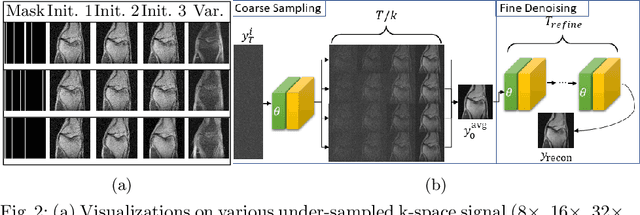
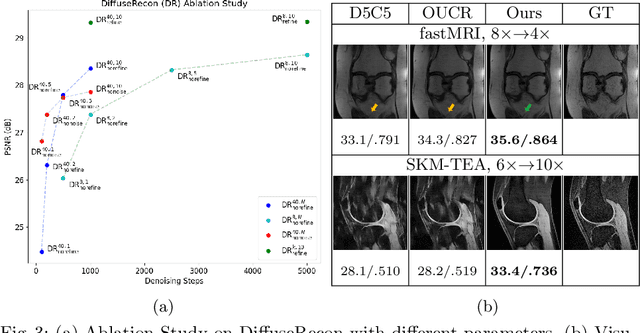
Magnetic Resonance (MR) image reconstruction from under-sampled acquisition promises faster scanning time. To this end, current State-of-The-Art (SoTA) approaches leverage deep neural networks and supervised training to learn a recovery model. While these approaches achieve impressive performances, the learned model can be fragile on unseen degradation, e.g. when given a different acceleration factor. These methods are also generally deterministic and provide a single solution to an ill-posed problem; as such, it can be difficult for practitioners to understand the reliability of the reconstruction. We introduce DiffuseRecon, a novel diffusion model-based MR reconstruction method. DiffuseRecon guides the generation process based on the observed signals and a pre-trained diffusion model, and does not require additional training on specific acceleration factors. DiffuseRecon is stochastic in nature and generates results from a distribution of fully-sampled MR images; as such, it allows us to explicitly visualize different potential reconstruction solutions. Lastly, DiffuseRecon proposes an accelerated, coarse-to-fine Monte-Carlo sampling scheme to approximate the most likely reconstruction candidate. The proposed DiffuseRecon achieves SoTA performances reconstructing from raw acquisition signals in fastMRI and SKM-TEA. Code will be open-sourced at www.github.com/cpeng93/DiffuseRecon.
MeshLeTemp: Leveraging the Learnable Vertex-Vertex Relationship to Generalize Human Pose and Mesh Reconstruction for In-the-Wild Scenes
Feb 15, 2022
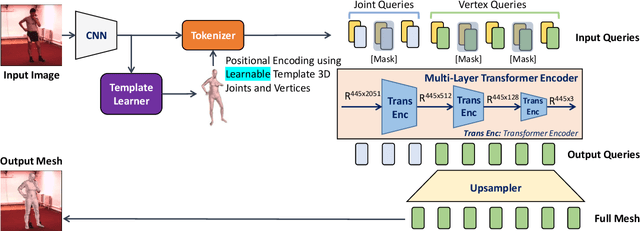
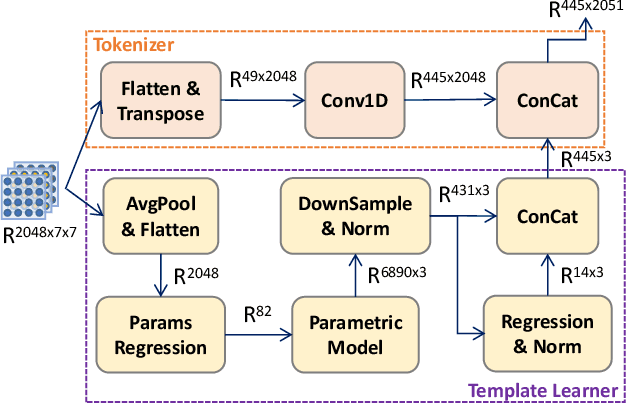

We present MeshLeTemp, a powerful method for 3D human pose and mesh reconstruction from a single image. In terms of human body priors encoding, we propose using a learnable template human mesh instead of a constant template utilized by previous state-of-the-art methods. The proposed learnable template reflects not only vertex-vertex interactions but also the human pose and body shape, being able to adapt to diverse images. We also introduce a strategy to enrich the training data that contains both 2D and 3D annotations. We conduct extensive experiments to show the generalizability of our method and the effectiveness of our data strategy. As one of our ablation studies, we adapt MeshLeTemp to another domain which is 3D hand reconstruction.
A Training Framework for Stereo-Aware Speech Enhancement using Deep Neural Networks
Dec 09, 2021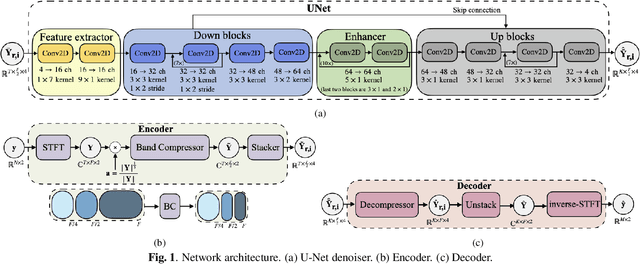
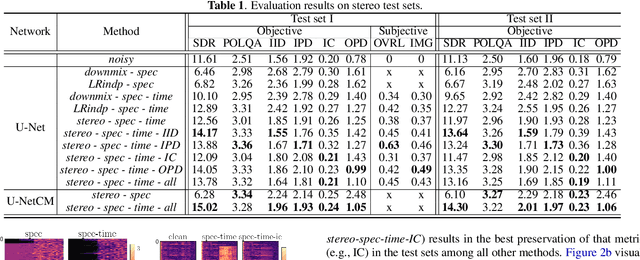
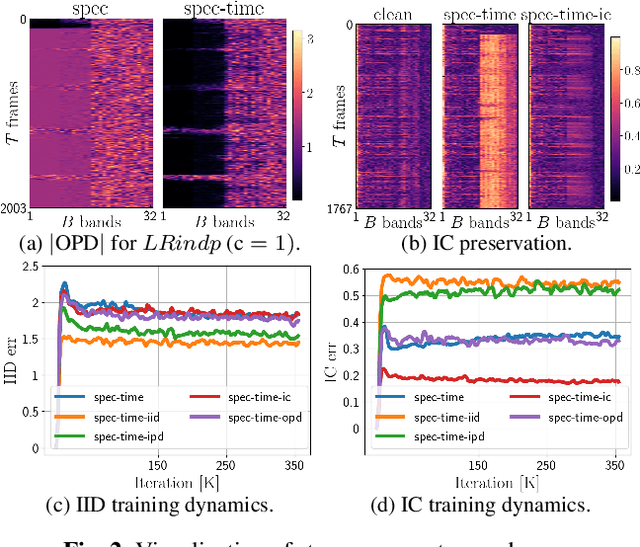
Deep learning-based speech enhancement has shown unprecedented performance in recent years. The most popular mono speech enhancement frameworks are end-to-end networks mapping the noisy mixture into an estimate of the clean speech. With growing computational power and availability of multichannel microphone recordings, prior works have aimed to incorporate spatial statistics along with spectral information to boost up performance. Despite an improvement in enhancement performance of mono output, the spatial image preservation and subjective evaluations have not gained much attention in the literature. This paper proposes a novel stereo-aware framework for speech enhancement, i.e., a training loss for deep learning-based speech enhancement to preserve the spatial image while enhancing the stereo mixture. The proposed framework is model independent, hence it can be applied to any deep learning based architecture. We provide an extensive objective and subjective evaluation of the trained models through a listening test. We show that by regularizing for an image preservation loss, the overall performance is improved, and the stereo aspect of the speech is better preserved.