 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeshLeTemp: Leveraging the Learnable Vertex-Vertex Relationship to Generalize Human Pose and Mesh Reconstruction for In-the-Wild Scenes
Feb 15, 2022



We present MeshLeTemp, a powerful method for 3D human pose and mesh reconstruction from a single image. In terms of human body priors encoding, we propose using a learnable template human mesh instead of a constant template utilized by previous state-of-the-art methods. The proposed learnable template reflects not only vertex-vertex interactions but also the human pose and body shape, being able to adapt to diverse images. We also introduce a strategy to enrich the training data that contains both 2D and 3D annotations. We conduct extensive experiments to show the generalizability of our method and the effectiveness of our data strategy. As one of our ablation studies, we adapt MeshLeTemp to another domain which is 3D hand reconstruction.
RankingMatch: Delving into Semi-Supervised Learning with Consistency Regularization and Ranking Loss
Oct 09, 2021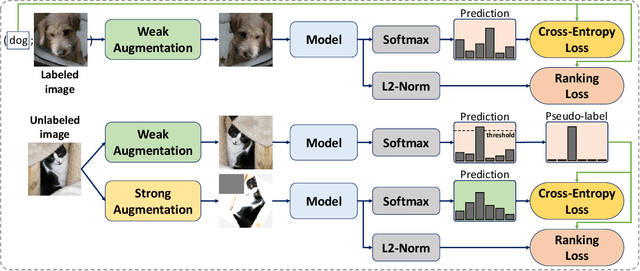
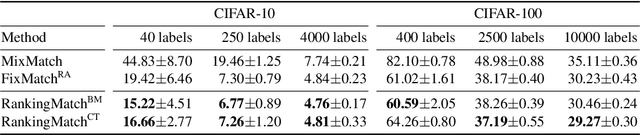
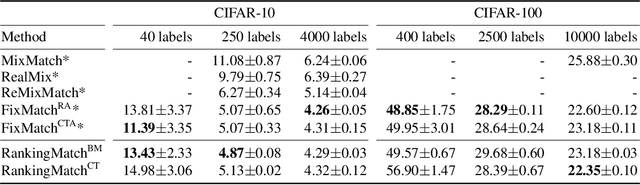
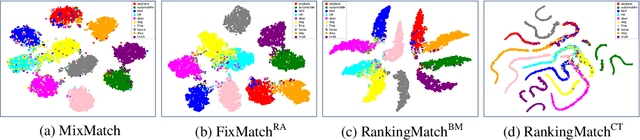
Semi-supervised learning (SSL) has played an important role in leveraging unlabeled data when labeled data is limited. One of the most successful SSL approaches is based on consistency regularization, which encourages the model to produce unchanged with perturbed input. However, there has been less attention spent on inputs that have the same label. Motivated by the observation that the inputs having the same label should have the similar model outputs, we propose a novel method, RankingMatch, that considers not only the perturbed inputs but also the similarity among the inputs having the same label. We especially introduce a new objective function, dubbed BatchMean Triplet loss, which has the advantage of computational efficiency while taking into account all input samples. Our RankingMatch achieves state-of-the-art performance across many standard SSL benchmarks with a variety of labeled data amounts, including 95.13% accuracy on CIFAR-10 with 250 labels, 77.65% accuracy on CIFAR-100 with 10000 labels, 97.76% accuracy on SVHN with 250 labels, and 97.77% accuracy on SVHN with 1000 labels. We also perform an ablation study to prove the efficacy of the proposed BatchMean Triplet loss against existing versions of Triplet loss.
Simple Multi-Resolution Representation Learning for Human Pose Estimation
Apr 14, 2020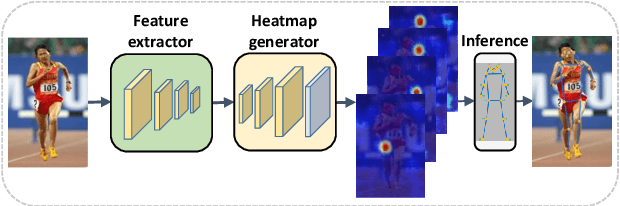
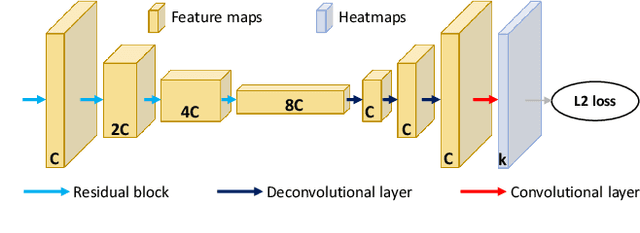
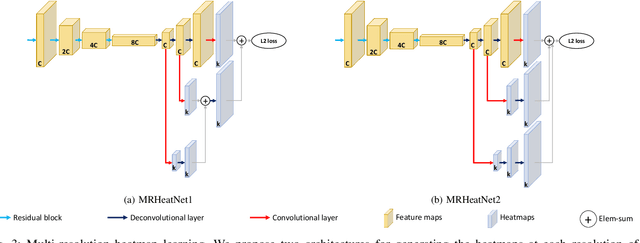
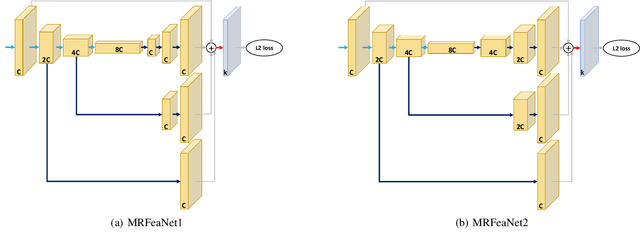
Human pose estimation - the process of recognizing human keypoints in a given image - is one of the most important tasks in computer vision and has a wide range of applications including movement diagnostics, surveillance, or self-driving vehicle. The accuracy of human keypoint prediction is increasingly improved thanks to the burgeoning development of deep learning. Most existing methods solved human pose estimation by generating heatmaps in which the ith heatmap indicates the location confidence of the ith keypoint. In this paper, we introduce novel network structures referred to as multiresolution representation learning for human keypoint prediction. At different resolutions in the learning process, our networks branch off and use extra layers to learn heatmap generation. We firstly consider the architectures for generating the multiresolution heatmaps after obtaining the lowest-resolution feature maps. Our second approach allows learning during the process of feature extraction in which the heatmaps are generated at each resolution of the feature extractor. The first and second approaches are referred to as multi-resolution heatmap learning and multi-resolution feature map learning respectively. Our architectures are simple yet effective, achieving good performance. We conducted experiments on two common benchmarks for human pose estimation: MS-COCO and MPII dataset.
AandP: Utilizing Prolog for converting between active sentence and passive sentence with three-steps conversion
Jan 16, 2020

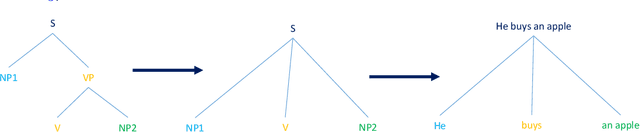

I introduce a simple but efficient method to solve one of the critical aspects of English grammar which is the relationship between active sentence and passive sentence. In fact, an active sentence and its corresponding passive sentence express the same meaning, but their structure is different. I utilized Prolog [4] along with Definite Clause Grammars (DCG) [5] for doing the conversion between active sentence and passive sentence. Some advanced techniques were also used such as Extra Arguments, Extra Goals, Lexicon, etc. I tried to solve a variety of cases of active and passive sentences such as 12 English tenses, modal verbs, negative form, etc. More details and my contributions will be presented in the following sections. The source code is available at https://github.com/tqtrunghnvn/ActiveAndPassive.