 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Implicit Mesh Reconstruction from Unannotated Image Collections
Jul 16, 2020
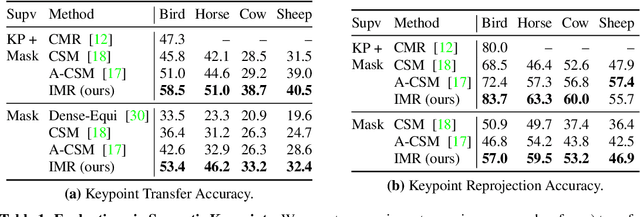
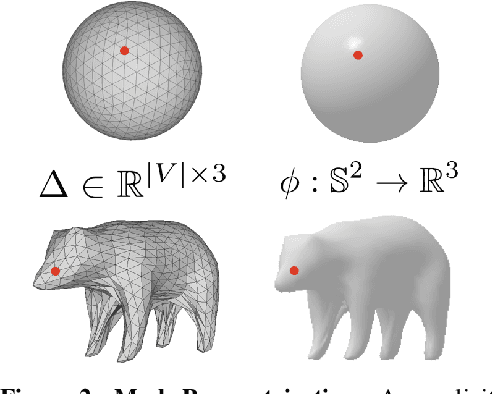
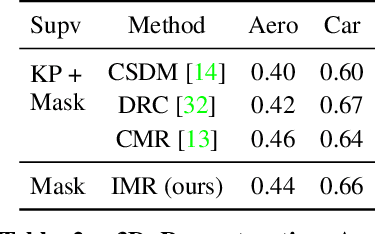
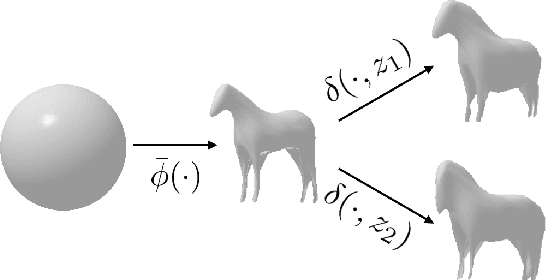
We present an approach to infer the 3D shape, texture, and camera pose for an object from a single RGB image, using only category-level image collections with foreground masks as supervision. We represent the shape as an image-conditioned implicit function that transforms the surface of a sphere to that of the predicted mesh, while additionally predicting the corresponding texture. To derive supervisory signal for learning, we enforce that: a) our predictions when rendered should explain the available image evidence, and b) the inferred 3D structure should be geometrically consistent with learned pixel to surface mappings. We empirically show that our approach improves over prior work that leverages similar supervision, and in fact performs competitively to methods that use stronger supervision. Finally, as our method enables learning with limited supervision, we qualitatively demonstrate its applicability over a set of about 30 object categories.
Improving Across-Dataset Brain Tissue Segmentation Using Transformer
Jan 21, 2022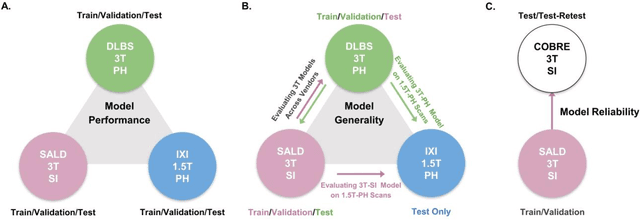
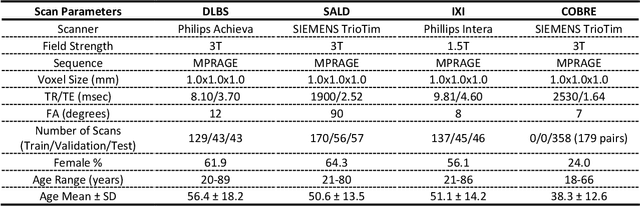
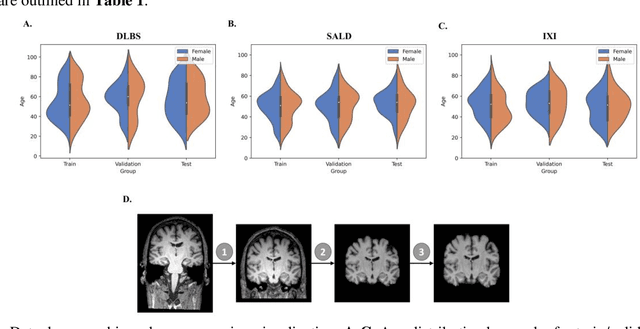
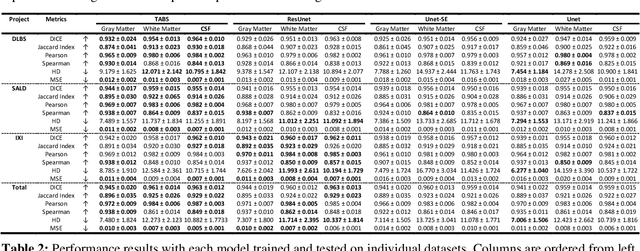
Brain tissue segmentation has demonstrated great utility in quantifying MRI data through Voxel-Based Morphometry and highlighting subtle structural changes associated with various conditions within the brain. However, manual segmentation is highly labor-intensive, and automated approaches have struggled due to properties inherent to MRI acquisition, leaving a great need for an effective segmentation tool. Despite the recent success of deep convolutional neural networks (CNNs) for brain tissue segmentation, many such solutions do not generalize well to new datasets, which is critical for a reliable solution. Transformers have demonstrated success in natural image segmentation and have recently been applied to 3D medical image segmentation tasks due to their ability to capture long-distance relationships in the input where the local receptive fields of CNNs struggle. This study introduces a novel CNN-Transformer hybrid architecture designed for brain tissue segmentation. We validate our model's performance across four multi-site T1w MRI datasets, covering different vendors, field strengths, scan parameters, time points, and neuropsychiatric conditions. In all situations, our model achieved the greatest generality and reliability. Out method is inherently robust and can serve as a valuable tool for brain-related T1w MRI studies. The code for the TABS network is available at: https://github.com/raovish6/TABS.
A deep learning method based on patchwise training for reconstructing temperature field
Jan 26, 2022
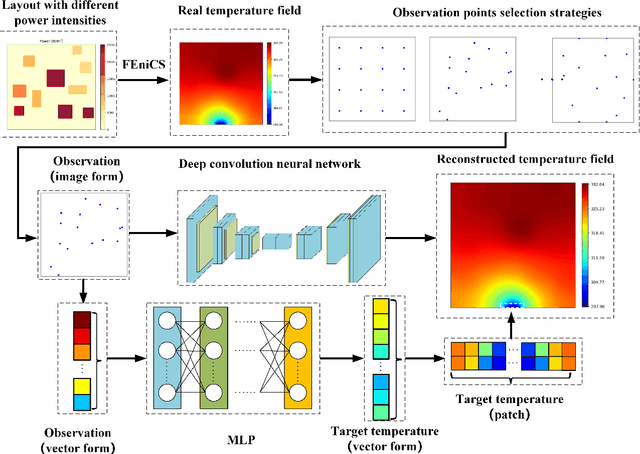

Physical field reconstruction is highly desirable for the measurement and control of engineering systems. The reconstruction of the temperature field from limited observation plays a crucial role in thermal management for electronic equipment. Deep learning has been employed in physical field reconstruction, whereas the accurate estimation for the regions with large gradients is still diffcult. To solve the problem, this work proposes a novel deep learning method based on patchwise training to reconstruct the temperature field of electronic equipment accurately from limited observation. Firstly, the temperature field reconstruction (TFR) problem of the electronic equipment is modeled mathematically and transformed as an image-to-image regression task. Then a patchwise training and inference framework consisting of an adaptive UNet and a shallow multilayer perceptron (MLP) is developed to establish the mapping from the observation to the temperature field. The adaptive UNet is utilized to reconstruct the whole temperature field while the MLP is designed to predict the patches with large temperature gradients. Experiments employing finite element simulation data are conducted to demonstrate the accuracy of the proposed method. Furthermore, the generalization is evaluated by investigating cases under different heat source layouts, different power intensities, and different observation point locations. The maximum absolute errors of the reconstructed temperature field are less than 1K under the patchwise training approach.
A Patch-based Image Denoising Method Using Eigenvectors of the Geodesics' Gramian Matrix
Oct 14, 2020
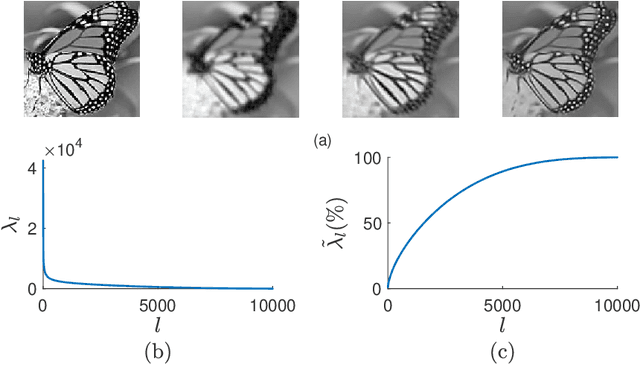
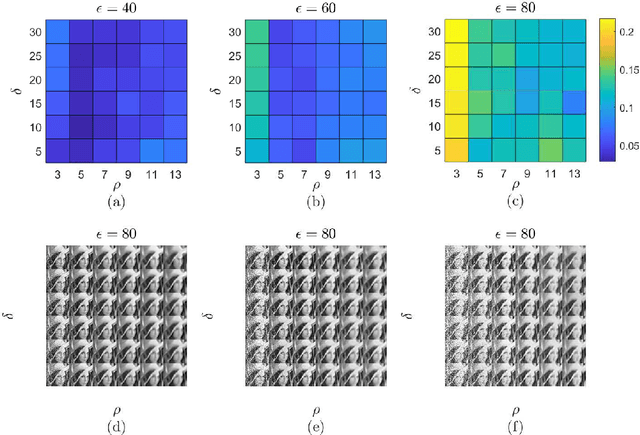
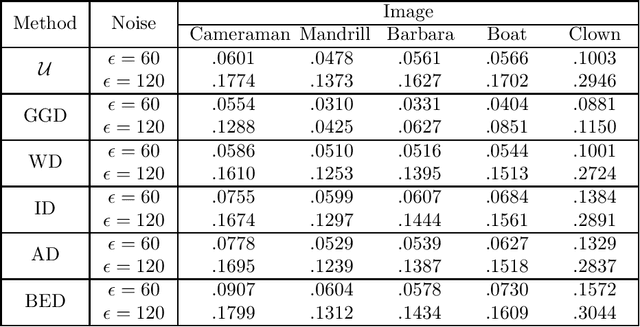
With the sophisticated modern technology in the camera industry, the demand for accurate and visually pleasing images is increasing. However, the quality of images captured by cameras are inevitably degraded by noise. Thus, some processing on images is required to filter out the noise without losing vital image features such as edges, corners, etc. Even though the current literature offers a variety of denoising methods, fidelity and efficiency of their denoising are sometimes uncertain. Thus, here we propose a novel and computationally efficient image denoising method that is capable of producing an accurate output. This method inputs patches partitioned from the image rather than pixels that are well known for preserving image smoothness. Then, it performs denoising on the manifold underlying the patch-space rather than that in the image domain to better preserve the features across the whole image. We validate the performance of this method against benchmark image processing methods.
Gate-Shift-Fuse for Video Action Recognition
Mar 16, 2022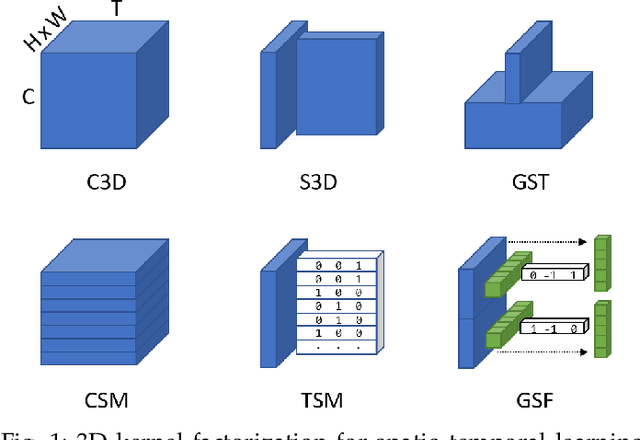
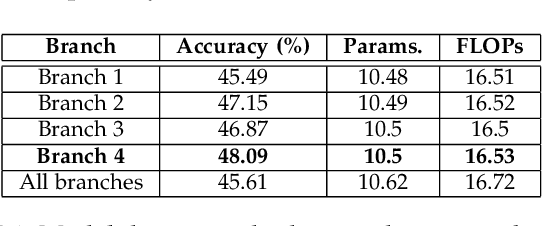
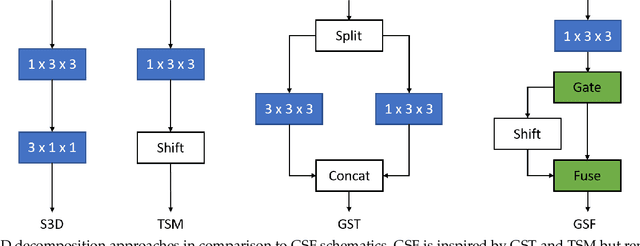
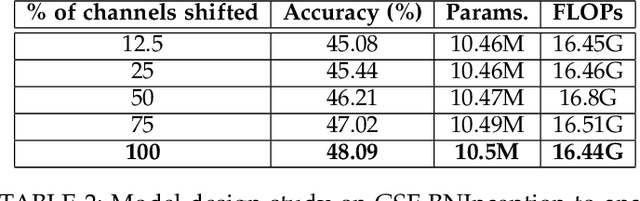
Convolutional Neural Networks are the de facto models for image recognition. However 3D CNNs, the straight forward extension of 2D CNNs for video recognition, have not achieved the same success on standard action recognition benchmarks. One of the main reasons for this reduced performance of 3D CNNs is the increased computational complexity requiring large scale annotated datasets to train them in scale. 3D kernel factorization approaches have been proposed to reduce the complexity of 3D CNNs. Existing kernel factorization approaches follow hand-designed and hard-wired techniques. In this paper we propose Gate-Shift-Fuse (GSF), a novel spatio-temporal feature extraction module which controls interactions in spatio-temporal decomposition and learns to adaptively route features through time and combine them in a data dependent manner. GSF leverages grouped spatial gating to decompose input tensor and channel weighting to fuse the decomposed tensors. GSF can be inserted into existing 2D CNNs to convert them into an efficient and high performing spatio-temporal feature extractor, with negligible parameter and compute overhead. We perform an extensive analysis of GSF using two popular 2D CNN families and achieve state-of-the-art or competitive performance on five standard action recognition benchmarks. Code and models will be made publicly available at https://github.com/swathikirans/GSF.
DD-NeRF: Double-Diffusion Neural Radiance Field as a Generalizable Implicit Body Representation
Dec 23, 2021
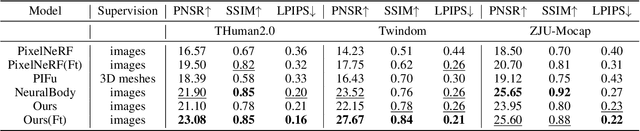
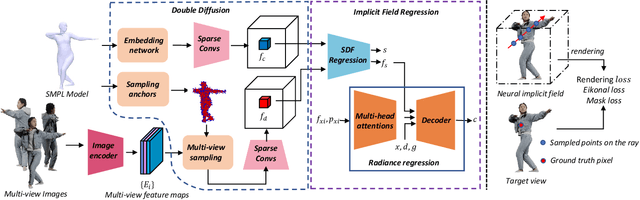
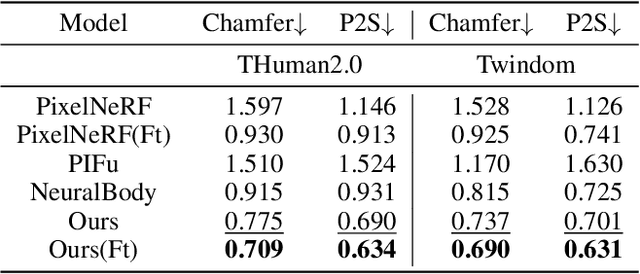
We present DD-NeRF, a novel generalizable implicit field for representing human body geometry and appearance from arbitrary input views. The core contribution is a double diffusion mechanism, which leverages the sparse convolutional neural network to build two volumes that represent a human body at different levels: a coarse body volume takes advantage of unclothed deformable mesh to provide the large-scale geometric guidance, and a detail feature volume learns the intricate geometry from local image features. We also employ a transformer network to aggregate image features and raw pixels across views, for computing the final high-fidelity radiance field. Experiments on various datasets show that the proposed approach outperforms previous works in both geometry reconstruction and novel view synthesis quality.
Adversarially-regularized mixed effects deep learning (ARMED) models for improved interpretability, performance, and generalization on clustered data
Mar 28, 2022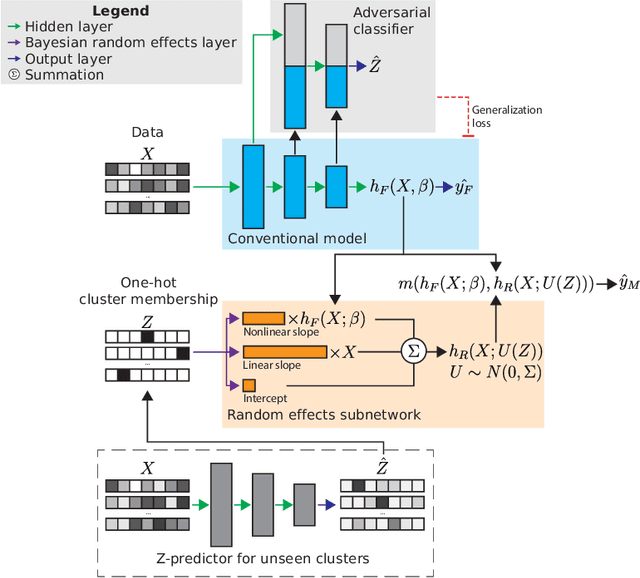
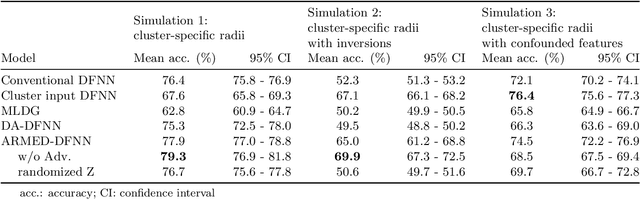
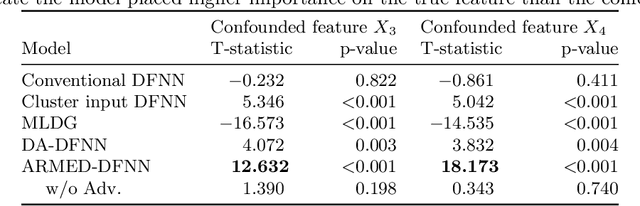
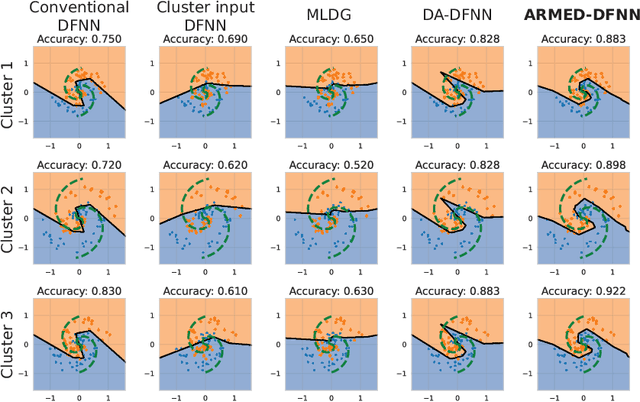
Data in the natural sciences frequently violate assumptions of independence. Such datasets have samples with inherent clustering (eg by study site, subject, experimental batch), leading to spurious associations, poor model fitting, and confounded analyses. While largely unaddressed in deep learning, this problem has been handled in the statistics community through mixed effects models. These models separate cluster-invariant, population-level fixed effects from cluster-specific random effects. We propose a general-purpose framework for Adversarially-Regularized Mixed Effects Deep learning (ARMED) models through three non-intrusive additions to existing neural networks: 1) a domain adversarial classifier constraining the original model to learn only cluster-invariant features, 2) a random effects subnetwork capturing cluster-specific features, and 3) an approach to apply random effects to clusters unseen during training. We apply ARMED to dense feedforward neural networks, convolutional neural networks, and autoencoders on 4 applications including classification of synthesized nonlinear data, dementia prognosis and diagnosis, and live-cell microscopy image analysis. We compare to conventional models, domain adversarial-only models, and the inclusion of cluster membership as an input covariate. ARMED models better distinguish confounded from true associations in synthetic data and emphasize more biologically plausible features in clinical applications. They also quantify inter-cluster variance in clinical data and can visualize batch effects in cell images. Finally, ARMED improves accuracy on data from clusters seen during training (up to 28% vs conventional models) and generalization to unseen clusters (up to 9% vs conventional models). By incorporating powerful mixed effects modeling into deep learning, ARMED increases interpretability, performance, and generalization on clustered data.
MonoDistill: Learning Spatial Features for Monocular 3D Object Detection
Jan 26, 2022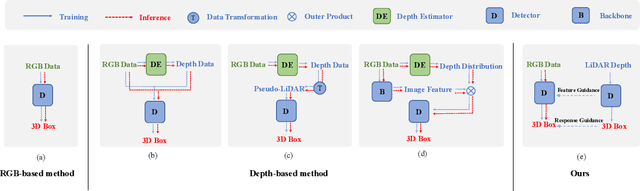
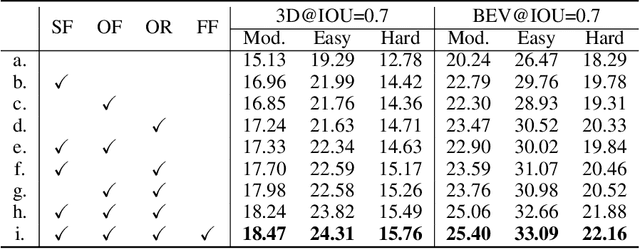

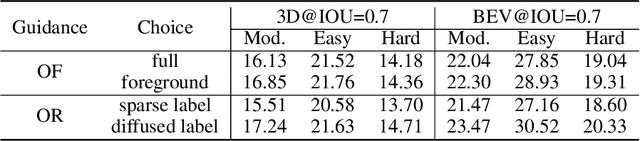
3D object detection is a fundamental and challenging task for 3D scene understanding, and the monocular-based methods can serve as an economical alternative to the stereo-based or LiDAR-based methods. However, accurately detecting objects in the 3D space from a single image is extremely difficult due to the lack of spatial cues. To mitigate this issue, we propose a simple and effective scheme to introduce the spatial information from LiDAR signals to the monocular 3D detectors, without introducing any extra cost in the inference phase. In particular, we first project the LiDAR signals into the image plane and align them with the RGB images. After that, we use the resulting data to train a 3D detector (LiDAR Net) with the same architecture as the baseline model. Finally, this LiDAR Net can serve as the teacher to transfer the learned knowledge to the baseline model. Experimental results show that the proposed method can significantly boost the performance of the baseline model and ranks the $1^{st}$ place among all monocular-based methods on the KITTI benchmark. Besides, extensive ablation studies are conducted, which further prove the effectiveness of each part of our designs and illustrate what the baseline model has learned from the LiDAR Net. Our code will be released at \url{https://github.com/monster-ghost/MonoDistill}.
FaceMap: Towards Unsupervised Face Clustering via Map Equation
Mar 21, 2022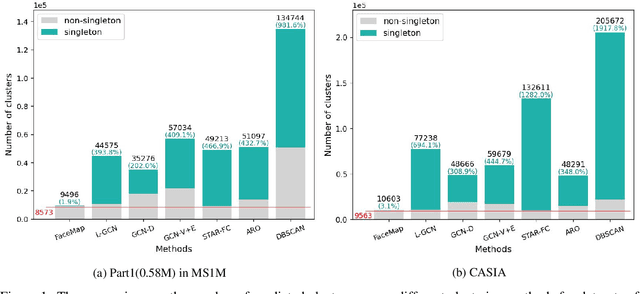
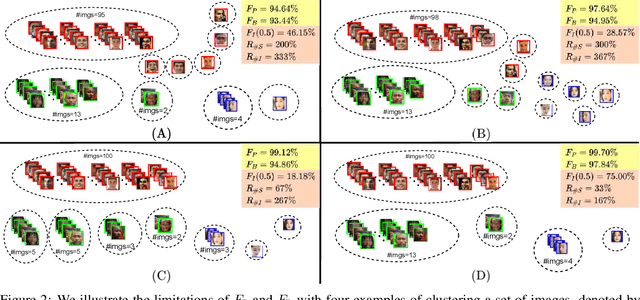

Face clustering is an essential task in computer vision due to the explosion of related applications such as augmented reality or photo album management. The main challenge of this task lies in the imperfectness of similarities among image feature representations. Given an existing feature extraction model, it is still an unresolved problem that how can the inherent characteristics of similarities of unlabelled images be leveraged to improve the clustering performance. Motivated by answering the question, we develop an effective unsupervised method, named as FaceMap, by formulating face clustering as a process of non-overlapping community detection, and minimizing the entropy of information flows on a network of images. The entropy is denoted by the map equation and its minimum represents the least description of paths among images in expectation. Inspired by observations on the ranked transition probabilities in the affinity graph constructed from facial images, we develop an outlier detection strategy to adaptively adjust transition probabilities among images. Experiments with ablation studies demonstrate that FaceMap significantly outperforms existing methods and achieves new state-of-the-arts on three popular large-scale datasets for face clustering, e.g., an absolute improvement of more than $10\%$ and $4\%$ comparing with prior unsupervised and supervised methods respectively in terms of average of Pairwise F-score. Our code is publicly available on github.
MinkLoc++: Lidar and Monocular Image Fusion for Place Recognition
Apr 12, 2021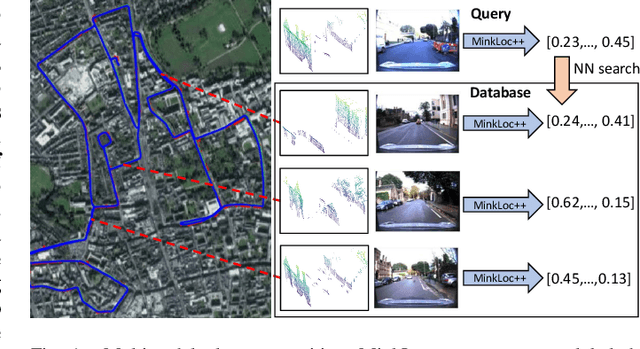
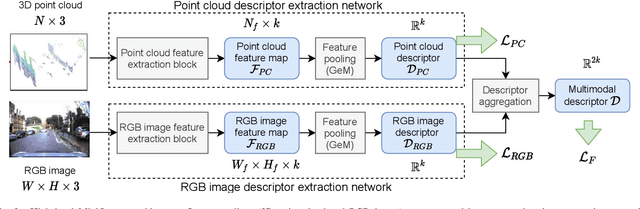
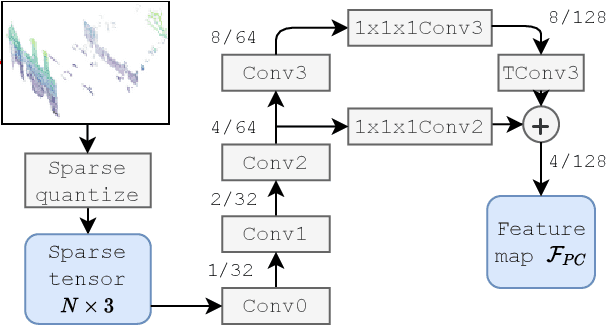

We introduce a discriminative multimodal descriptor based on a pair of sensor readings: a point cloud from a LiDAR and an image from an RGB camera. Our descriptor, named MinkLoc++, can be used for place recognition, re-localization and loop closure purposes in robotics or autonomous vehicles applications. We use late fusion approach, where each modality is processed separately and fused in the final part of the processing pipeline. The proposed method achieves state-of-the-art performance on standard place recognition benchmarks. We also identify dominating modality problem when training a multimodal descriptor. The problem manifests itself when the network focuses on a modality with a larger overfit to the training data. This drives the loss down during the training but leads to suboptimal performance on the evaluation set. In this work we describe how to detect and mitigate such risk when using a deep metric learning approach to train a multimodal neural network. Our code is publicly available on the project website: https://github.com/jac99/MinkLoc3DRGB.