 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Implicit Body Representations from Double Diffusion Based Neural Radiance Fields
Paper and Code
Jan 17, 2022
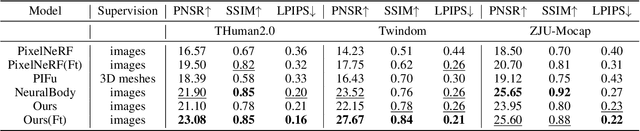
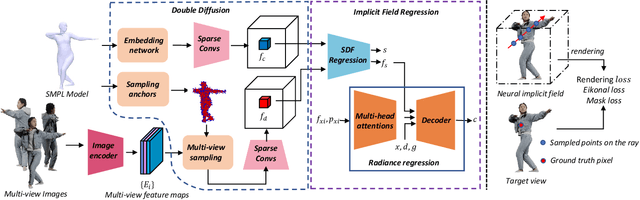
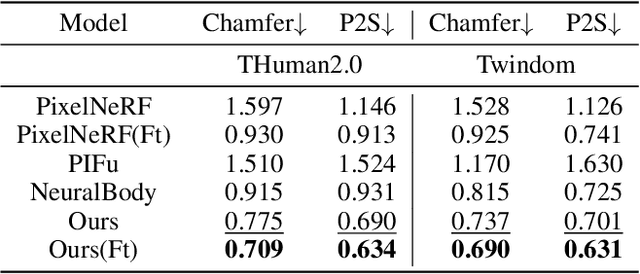
In this paper, we present a novel double diffusion based neural radiance field, dubbed DD-NeRF, to reconstruct human body geometry and render the human body appearance in novel views from a sparse set of images. We first propose a double diffusion mechanism to achieve expressive representations of input images by fully exploiting human body priors and image appearance details at two levels. At the coarse level, we first model the coarse human body poses and shapes via an unclothed 3D deformable vertex model as guidance. At the fine level, we present a multi-view sampling network to capture subtle geometric deformations and image detailed appearances, such as clothing and hair, from multiple input views. Considering the sparsity of the two level features, we diffuse them into feature volumes in the canonical space to construct neural radiance fields. Then, we present a signed distance function (SDF) regression network to construct body surfaces from the diffused features. Thanks to our double diffused representations, our method can even synthesize novel views of unseen subjects. Experiments on various datasets demonstrate that our approach outperforms the state-of-the-art in both geometric reconstruction and novel view synthesis.