 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Self-Adaptively Learning to Demoire from Focused and Defocused Image Pairs
Nov 03, 2020
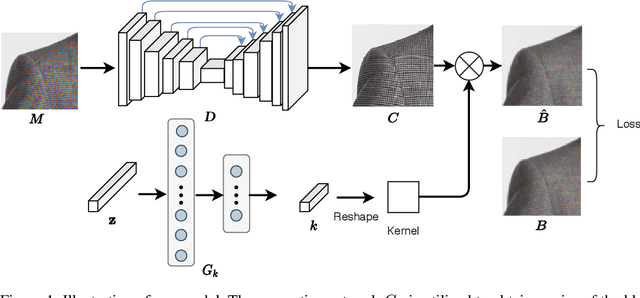



Moire artifacts are common in digital photography, resulting from the interference between high-frequency scene content and the color filter array of the camera. Existing deep learning-based demoireing methods trained on large scale datasets are limited in handling various complex moire patterns, and mainly focus on demoireing of photos taken of digital displays. Moreover, obtaining moire-free ground-truth in natural scenes is difficult but needed for training. In this paper, we propose a self-adaptive learning method for demoireing a high-frequency image, with the help of an additional defocused moire-free blur image. Given an image degraded with moire artifacts and a moire-free blur image, our network predicts a moire-free clean image and a blur kernel with a self-adaptive strategy that does not require an explicit training stage, instead performing test-time adaptation. Our model has two sub-networks and works iteratively. During each iteration, one sub-network takes the moire image as input, removing moire patterns and restoring image details, and the other sub-network estimates the blur kernel from the blur image. The two sub-networks are jointly optimized. Extensive experiments demonstrate that our method outperforms state-of-the-art methods and can produce high-quality demoired results. It can generalize well to the task of removing moire artifacts caused by display screens. In addition, we build a new moire dataset, including images with screen and texture moire artifacts. As far as we know, this is the first dataset with real texture moire patterns.
An Interactive Explanatory AI System for Industrial Quality Control
Mar 17, 2022Machine learning based image classification algorithms, such as deep neural network approaches, will be increasingly employed in critical settings such as quality control in industry, where transparency and comprehensibility of decisions are crucial. Therefore, we aim to extend the defect detection task towards an interactive human-in-the-loop approach that allows us to integrate rich background knowledge and the inference of complex relationships going beyond traditional purely data-driven approaches. We propose an approach for an interactive support system for classifications in an industrial quality control setting that combines the advantages of both (explainable) knowledge-driven and data-driven machine learning methods, in particular inductive logic programming and convolutional neural networks, with human expertise and control. The resulting system can assist domain experts with decisions, provide transparent explanations for results, and integrate feedback from users; thus reducing workload for humans while both respecting their expertise and without removing their agency or accountability.
Checkerboard-Artifact-Free Image-Enhancement Network Considering Local and Global Features
Oct 13, 2020
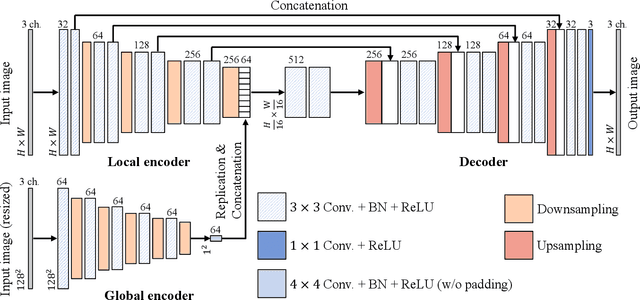
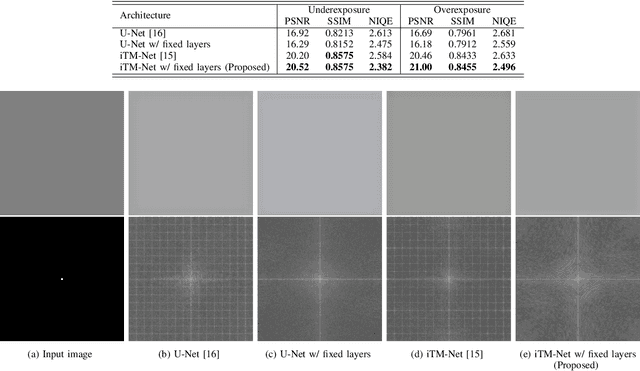

In this paper, we propose a novel convolutional neural network (CNN) that never causes checkerboard artifacts, for image enhancement. In research fields of image-to-image translation problems, it is well-known that images generated by usual CNNs are distorted by checkerboard artifacts which mainly caused in forward-propagation of upsampling layers. However, checkerboard artifacts in image enhancement have never been discussed. In this paper, we point out that applying U-Net based CNNs to image enhancement causes checkerboard artifacts. In contrast, the proposed network that contains fixed convolutional layers can perfectly prevent the artifacts. In addition, the proposed network architecture, which can handle both local and global features, enables us to improve the performance of image enhancement. Experimental results show that the use of fixed convolutional layers can prevent checkerboard artifacts and the proposed network outperforms state-of-the-art CNN-based image-enhancement methods in terms of various objective quality metrics: PSNR, SSIM, and NIQE.
I2L-MeshNet: Image-to-Lixel Prediction Network for Accurate 3D Human Pose and Mesh Estimation from a Single RGB Image
Aug 09, 2020
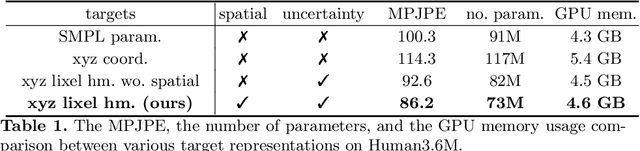
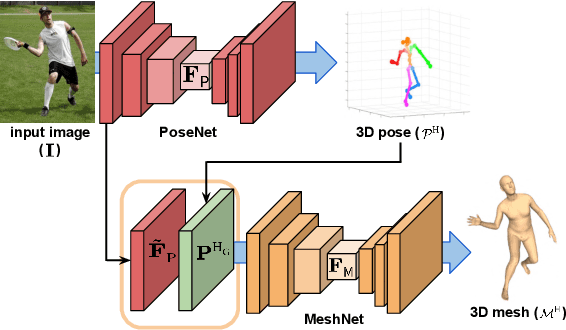
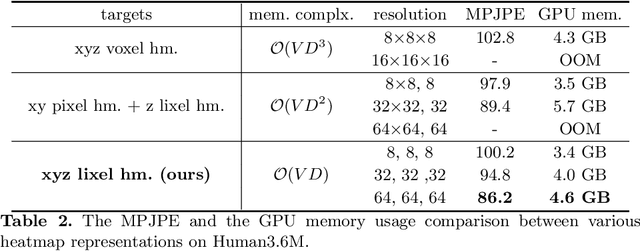
Most of the previous image-based 3D human pose and mesh estimation methods estimate parameters of the human mesh model from an input image. However, directly regressing the parameters from the input image is a highly non-linear mapping because it breaks the spatial relationship between pixels in the input image. In addition, it cannot model the prediction uncertainty, which can make training harder. To resolve the above issues, we propose I2L-MeshNet, an image-to-lixel (line+pixel) prediction network. The proposed I2L-MeshNet predicts the per-lixel likelihood on 1D heatmaps for each mesh vertex coordinate instead of directly regressing the parameters. Our lixel-based 1D heatmap preserves the spatial relationship in the input image and models the prediction uncertainty. We demonstrate the benefit of the image-to-lixel prediction and show that the proposed I2L-MeshNet outperforms previous methods. The code is publicly available \footnote{\url{https://github.com/mks0601/I2L-MeshNet_RELEASE}}.
Slice-Connection Clustering Algorithm for Tree Roots Recognition in Noisy 3D GPR Data
Mar 08, 2022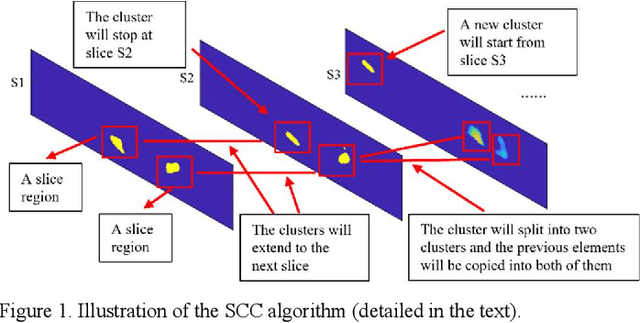
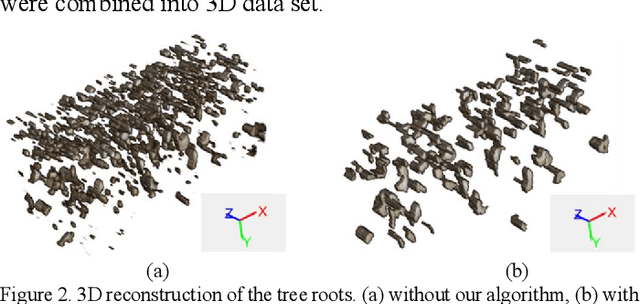

3D mapping of tree roots is a popular ground-penetrating radar (GPR) application. In real field tests, the recognition of tree roots suffers due to noisey reflection patterns from subsurface targets that are not of interest, such as rocks, cavities, soil unevenness, etc. A Slice-Connection Clustering Algorithm (SCC) is applied to separate the regions of interest from each other in a reconstructed 3D image. The proposed method can successfully recognize the radar signatures of the roots and distinguish roots from other objects. Meanwhile, most noise radar features are ignored through our method. The final 3D mapping of the radargram obtained by the method can be used to estimate the location and extension trend of the tree roots. The effectiveness of the proposed system is tested on real GPR data.
HDRUNet: Single Image HDR Reconstruction with Denoising and Dequantization
May 27, 2021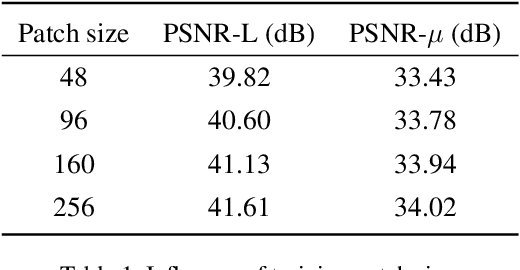
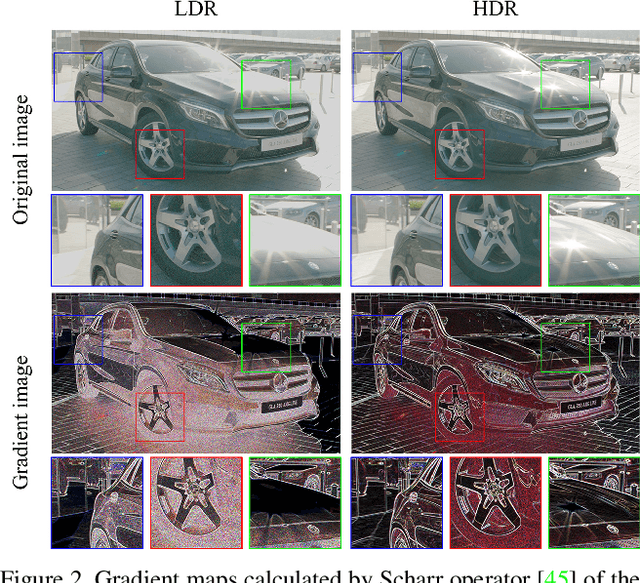
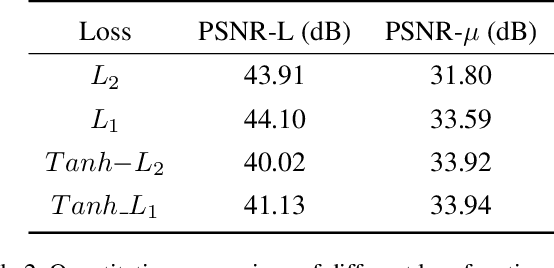
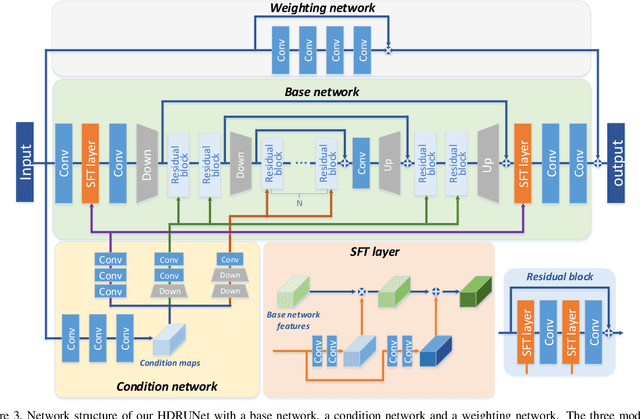
Most consumer-grade digital cameras can only capture a limited range of luminance in real-world scenes due to sensor constraints. Besides, noise and quantization errors are often introduced in the imaging process. In order to obtain high dynamic range (HDR) images with excellent visual quality, the most common solution is to combine multiple images with different exposures. However, it is not always feasible to obtain multiple images of the same scene and most HDR reconstruction methods ignore the noise and quantization loss. In this work, we propose a novel learning-based approach using a spatially dynamic encoder-decoder network, HDRUNet, to learn an end-to-end mapping for single image HDR reconstruction with denoising and dequantization. The network consists of a UNet-style base network to make full use of the hierarchical multi-scale information, a condition network to perform pattern-specific modulation and a weighting network for selectively retaining information. Moreover, we propose a Tanh_L1 loss function to balance the impact of over-exposed values and well-exposed values on the network learning. Our method achieves the state-of-the-art performance in quantitative comparisons and visual quality. The proposed HDRUNet model won the second place in the single frame track of NITRE2021 High Dynamic Range Challenge.
Resolution-Based Distillation for Efficient Histology Image Classification
Jan 11, 2021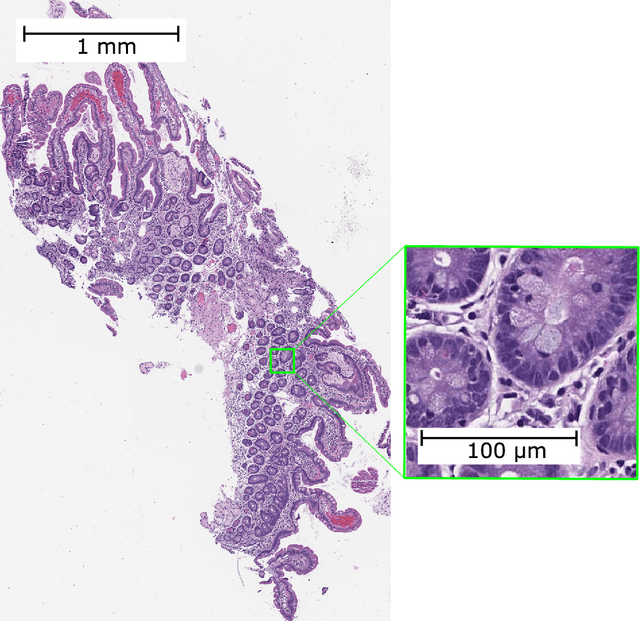
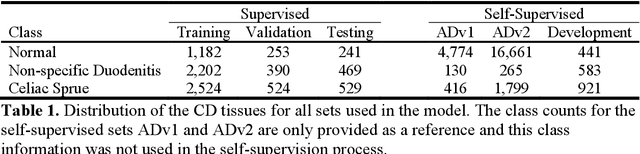
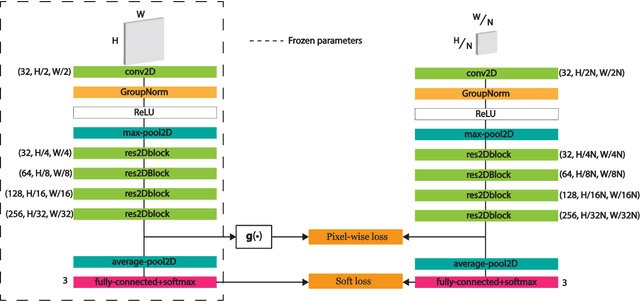
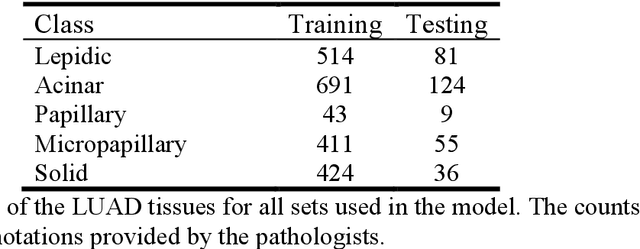
Developing deep learning models to analyze histology images has been computationally challenging, as the massive size of the images causes excessive strain on all parts of the computing pipeline. This paper proposes a novel deep learning-based methodology for improving the computational efficiency of histology image classification. The proposed approach is robust when used with images that have reduced input resolution and can be trained effectively with limited labeled data. Pre-trained on the original high-resolution (HR) images, our method uses knowledge distillation (KD) to transfer learned knowledge from a teacher model to a student model trained on the same images at a much lower resolution. To address the lack of large-scale labeled histology image datasets, we perform KD in a self-supervised manner. We evaluate our approach on two histology image datasets associated with celiac disease (CD) and lung adenocarcinoma (LUAD). Our results show that a combination of KD and self-supervision allows the student model to approach, and in some cases, surpass the classification accuracy of the teacher, while being much more efficient. Additionally, we observe an increase in student classification performance as the size of the unlabeled dataset increases, indicating that there is potential to scale further. For the CD data, our model outperforms the HR teacher model, while needing 4 times fewer computations. For the LUAD data, our student model results at 1.25x magnification are within 3% of the teacher model at 10x magnification, with a 64 times computational cost reduction. Moreover, our CD outcomes benefit from performance scaling with the use of more unlabeled data. For 0.625x magnification, using unlabeled data improves accuracy by 4% over the baseline. Thus, our method can improve the feasibility of deep learning solutions for digital pathology with standard computational hardware.
3M: Multi-style image caption generation using Multi-modality features under Multi-UPDOWN model
Mar 20, 2021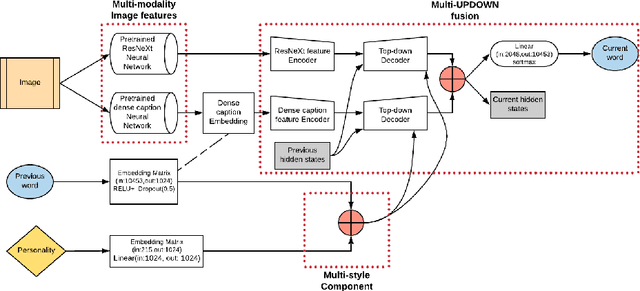

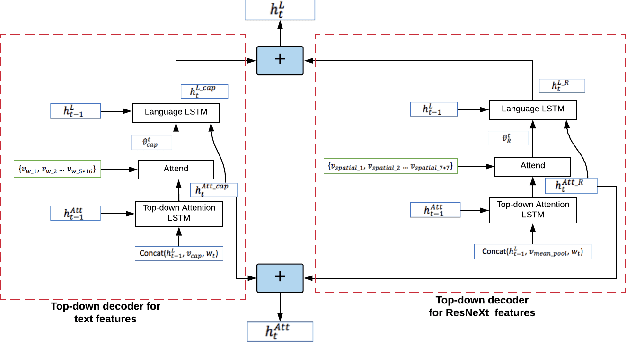

In this paper, we build a multi-style generative model for stylish image captioning which uses multi-modality image features, ResNeXt features and text features generated by DenseCap. We propose the 3M model, a Multi-UPDOWN caption model that encodes multi-modality features and decode them to captions. We demonstrate the effectiveness of our model on generating human-like captions by examining its performance on two datasets, the PERSONALITY-CAPTIONS dataset and the FlickrStyle10K dataset. We compare against a variety of state-of-the-art baselines on various automatic NLP metrics such as BLEU, ROUGE-L, CIDEr, SPICE, etc. A qualitative study has also been done to verify our 3M model can be used for generating different stylized captions.
Real-time Rendering for Integral Imaging Light Field Displays Based on a Voxel-Pixel Lookup Table
Jan 20, 2022A real-time elemental image array (EIA) generation method which does not sacrifice accuracy nor rely on high-performance hardware is developed, through raytracing and pre-stored voxel-pixel lookup table (LUT). Benefiting from both offline and online working flow, experiments verified the effectiveness.
Encryption and encoding of facial images into quick response and high capacity color 2d code for biometric passport security system
Mar 17, 2022
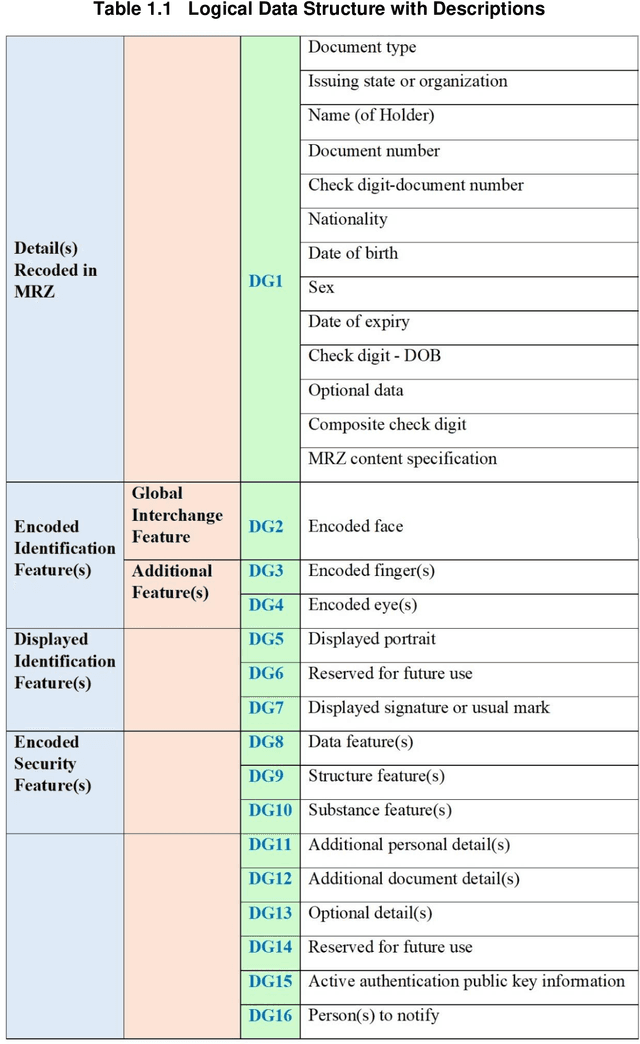
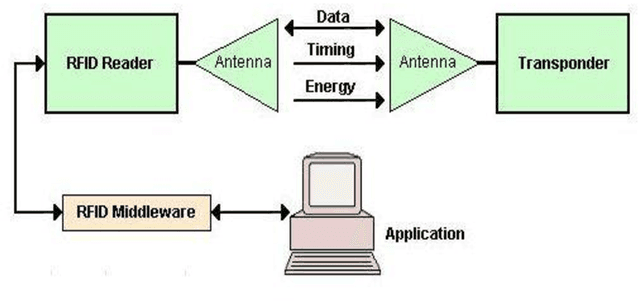

In this thesis, a multimodal biometric, secure encrypted data and encrypted biometric encoded into the QR code-based biometric-passport authentication method is proposed for national security applications. Firstly, using the Extended Profile - Local Binary Patterns (EP-LBP), a Canny edge detector, and the Scale Invariant Feature Transform (SIFT) algorithm with Image File Information (IMFINFO) process, the facial mark size recognition is initially achieved. Secondly, by using the Active Shape Model (ASM) into Active Appearance Model (AAM) to follow the hand and infusion the hand geometry characteristics for verification and identification, hand geometry recognition is achieved. Thirdly, the encrypted biometric passport information that is publicly accessible is encoded into the QR code and inserted into the electronic passport to improve protection. Further, Personal information and biometric data are encrypted by applying the Advanced Encryption Standard (AES) and the Secure Hash Algorithm (SHA) 256 algorithm. It will enhance the biometric passport security system.