Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3M: Multi-style image caption generation using Multi-modality features under Multi-UPDOWN model
Paper and Code
Mar 20, 2021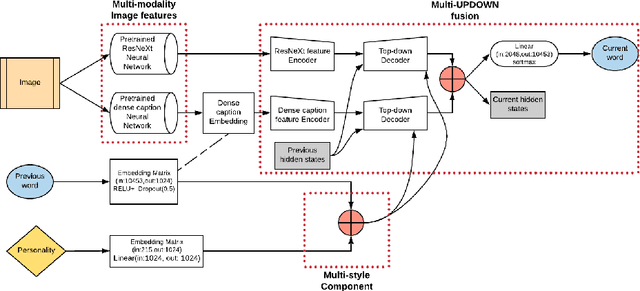

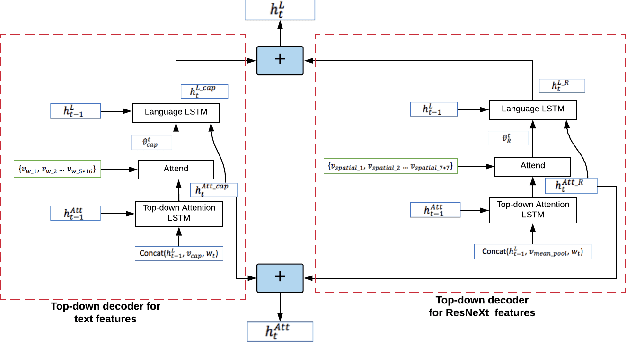

In this paper, we build a multi-style generative model for stylish image captioning which uses multi-modality image features, ResNeXt features and text features generated by DenseCap. We propose the 3M model, a Multi-UPDOWN caption model that encodes multi-modality features and decode them to captions. We demonstrate the effectiveness of our model on generating human-like captions by examining its performance on two datasets, the PERSONALITY-CAPTIONS dataset and the FlickrStyle10K dataset. We compare against a variety of state-of-the-art baselines on various automatic NLP metrics such as BLEU, ROUGE-L, CIDEr, SPICE, etc. A qualitative study has also been done to verify our 3M model can be used for generating different stylized captions.
* To be published at FLAIRS-34
View paper on