 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Omni-DETR: Omni-Supervised Object Detection with Transformers
Mar 30, 2022
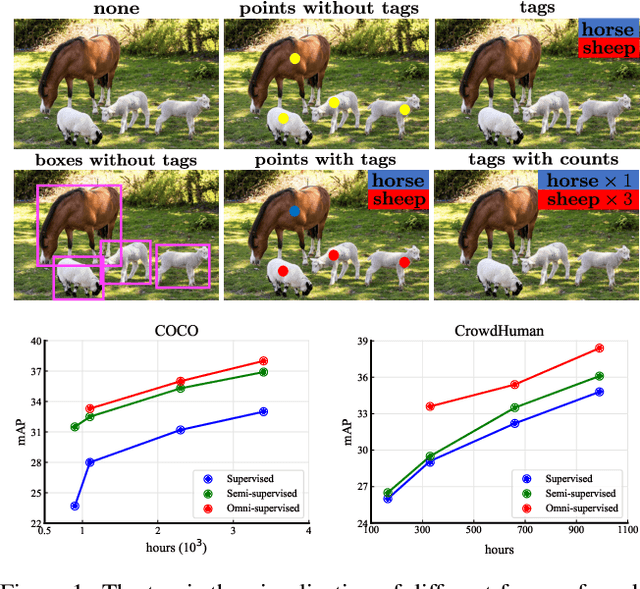


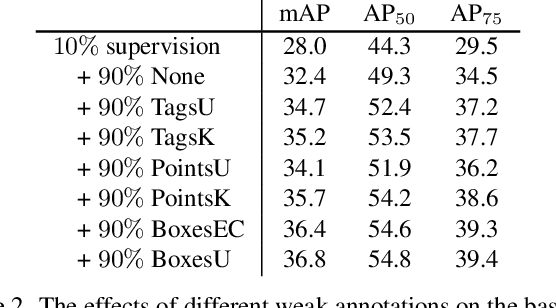
We consider the problem of omni-supervised object detection, which can use unlabeled, fully labeled and weakly labeled annotations, such as image tags, counts, points, etc., for object detection. This is enabled by a unified architecture, Omni-DETR, based on the recent progress on student-teacher framework and end-to-end transformer based object detection. Under this unified architecture, different types of weak labels can be leveraged to generate accurate pseudo labels, by a bipartite matching based filtering mechanism, for the model to learn. In the experiments, Omni-DETR has achieved state-of-the-art results on multiple datasets and settings. And we have found that weak annotations can help to improve detection performance and a mixture of them can achieve a better trade-off between annotation cost and accuracy than the standard complete annotation. These findings could encourage larger object detection datasets with mixture annotations. The code is available at https://github.com/amazon-research/omni-detr.
Towards Annotation-Free Evaluation of Cross-Lingual Image Captioning
Dec 09, 2020
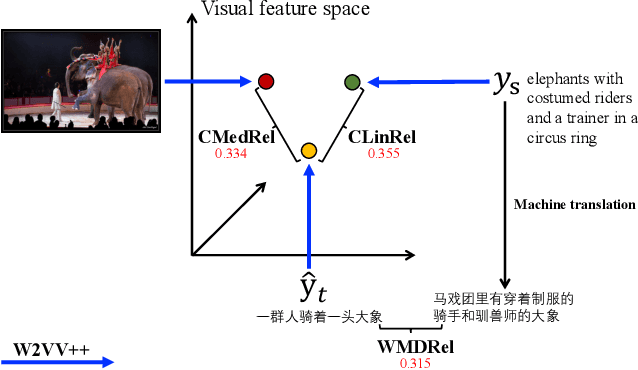
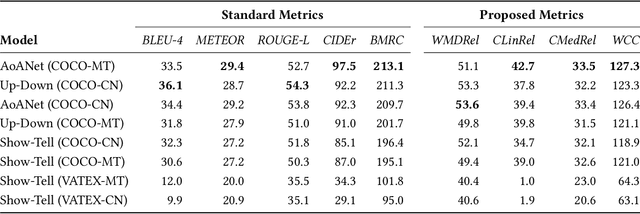
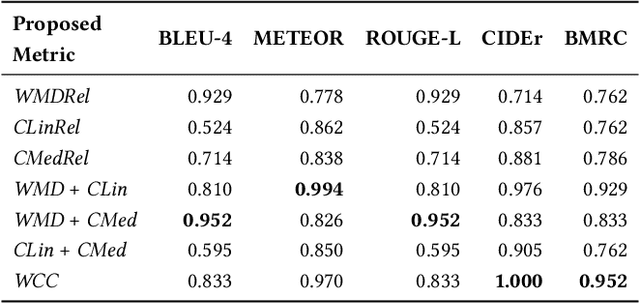
Cross-lingual image captioning, with its ability to caption an unlabeled image in a target language other than English, is an emerging topic in the multimedia field. In order to save the precious human resource from re-writing reference sentences per target language, in this paper we make a brave attempt towards annotation-free evaluation of cross-lingual image captioning. Depending on whether we assume the availability of English references, two scenarios are investigated. For the first scenario with the references available, we propose two metrics, i.e., WMDRel and CLinRel. WMDRel measures the semantic relevance between a model-generated caption and machine translation of an English reference using their Word Mover's Distance. By projecting both captions into a deep visual feature space, CLinRel is a visual-oriented cross-lingual relevance measure. As for the second scenario, which has zero reference and is thus more challenging, we propose CMedRel to compute a cross-media relevance between the generated caption and the image content, in the same visual feature space as used by CLinRel. The promising results show high potential of the new metrics for evaluation with no need of references in the target language.
MDMMT-2: Multidomain Multimodal Transformer for Video Retrieval, One More Step Towards Generalization
Mar 14, 2022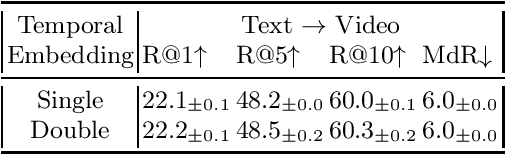
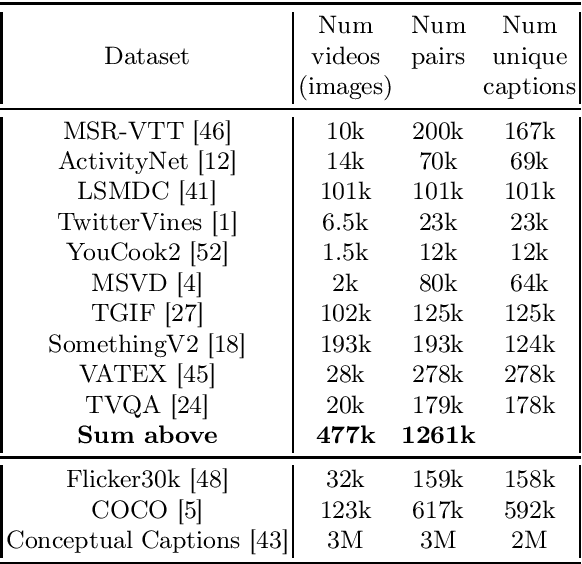


In this work we present a new State-of-The-Art on the text-to-video retrieval task on MSR-VTT, LSMDC, MSVD, YouCook2 and TGIF obtained by a single model. Three different data sources are combined: weakly-supervised videos, crowd-labeled text-image pairs and text-video pairs. A careful analysis of available pre-trained networks helps to choose the best prior-knowledge ones. We introduce three-stage training procedure that provides high transfer knowledge efficiency and allows to use noisy datasets during training without prior knowledge degradation. Additionally, double positional encoding is used for better fusion of different modalities and a simple method for non-square inputs processing is suggested.
CrossATNet - A Novel Cross-Attention Based Framework for Sketch-Based Image Retrieval
Apr 20, 2021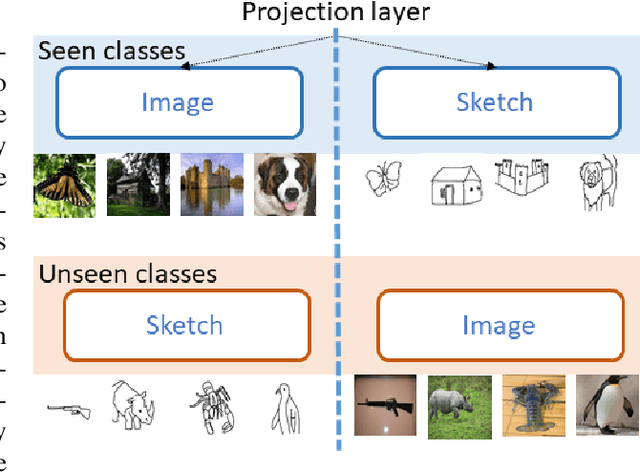
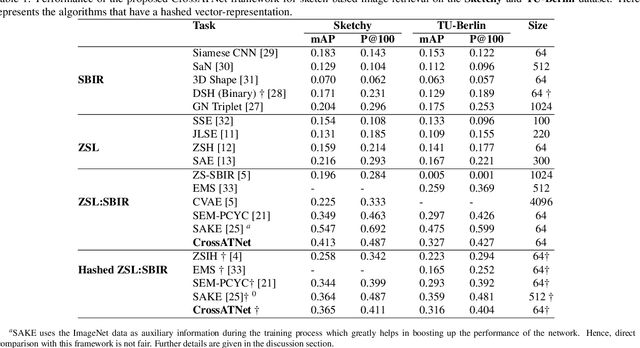
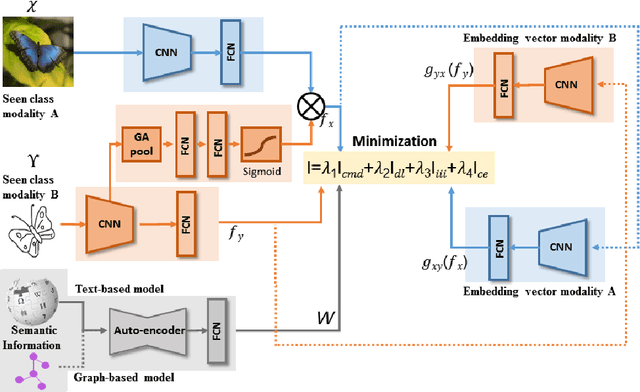
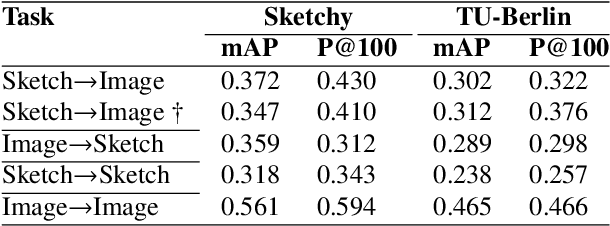
We propose a novel framework for cross-modal zero-shot learning (ZSL) in the context of sketch-based image retrieval (SBIR). Conventionally, the SBIR schema mainly considers simultaneous mappings among the two image views and the semantic side information. Therefore, it is desirable to consider fine-grained classes mainly in the sketch domain using highly discriminative and semantically rich feature space. However, the existing deep generative modeling-based SBIR approaches majorly focus on bridging the gaps between the seen and unseen classes by generating pseudo-unseen-class samples. Besides, violating the ZSL protocol by not utilizing any unseen-class information during training, such techniques do not pay explicit attention to modeling the discriminative nature of the shared space. Also, we note that learning a unified feature space for both the multi-view visual data is a tedious task considering the significant domain difference between sketches and color images. In this respect, as a remedy, we introduce a novel framework for zero-shot SBIR. While we define a cross-modal triplet loss to ensure the discriminative nature of the shared space, an innovative cross-modal attention learning strategy is also proposed to guide feature extraction from the image domain exploiting information from the respective sketch counterpart. In order to preserve the semantic consistency of the shared space, we consider a graph CNN-based module that propagates the semantic class topology to the shared space. To ensure an improved response time during inference, we further explore the possibility of representing the shared space in terms of hash codes. Experimental results obtained on the benchmark TU-Berlin and the Sketchy datasets confirm the superiority of CrossATNet in yielding state-of-the-art results.
Data Efficient Language-supervised Zero-shot Recognition with Optimal Transport Distillation
Dec 20, 2021



Traditional computer vision models are trained to predict a fixed set of predefined categories. Recently, natural language has been shown to be a broader and richer source of supervision that provides finer descriptions to visual concepts than supervised "gold" labels. Previous works, such as CLIP, use InfoNCE loss to train a model to predict the pairing between images and text captions. CLIP, however, is data hungry and requires more than 400M image-text pairs for training. The inefficiency can be partially attributed to the fact that the image-text pairs are noisy. To address this, we propose OTTER (Optimal TransporT distillation for Efficient zero-shot Recognition), which uses online entropic optimal transport to find a soft image-text match as labels for contrastive learning. Based on pretrained image and text encoders, models trained with OTTER achieve strong performance with only 3M image text pairs. Compared with InfoNCE loss, label smoothing, and knowledge distillation, OTTER consistently outperforms these baselines in zero shot evaluation on Google Open Images (19,958 classes) and multi-labeled ImageNet 10K (10032 classes) from Tencent ML-Images. Over 42 evaluations on 7 different dataset/architecture settings x 6 metrics, OTTER outperforms (32) or ties (2) all baselines in 34 of them.
Domain-Aware Unsupervised Hyperspectral Reconstruction for Aerial Image Dehazing
Nov 07, 2020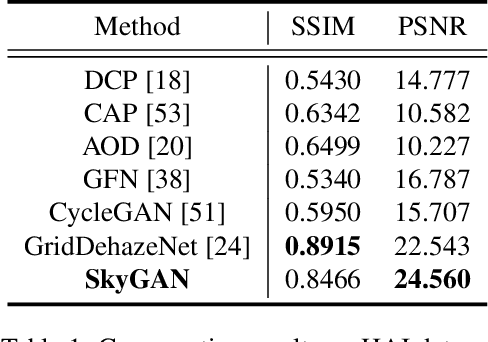

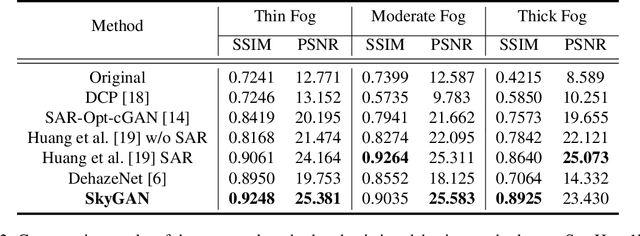
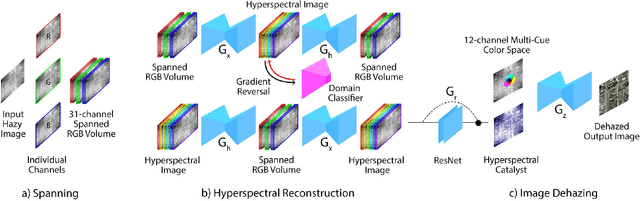
Haze removal in aerial images is a challenging problem due to considerable variation in spatial details and varying contrast. Changes in particulate matter density often lead to degradation in visibility. Therefore, several approaches utilize multi-spectral data as auxiliary information for haze removal. In this paper, we propose SkyGAN for haze removal in aerial images. SkyGAN consists of 1) a domain-aware hazy-to-hyperspectral (H2H) module, and 2) a conditional GAN (cGAN) based multi-cue image-to-image translation module (I2I) for dehazing. The proposed H2H module reconstructs several visual bands from RGB images in an unsupervised manner, which overcomes the lack of hazy hyperspectral aerial image datasets. The module utilizes task supervision and domain adaptation in order to create a "hyperspectral catalyst" for image dehazing. The I2I module uses the hyperspectral catalyst along with a 12-channel multi-cue input and performs effective image dehazing by utilizing the entire visual spectrum. In addition, this work introduces a new dataset, called Hazy Aerial-Image (HAI) dataset, that contains more than 65,000 pairs of hazy and ground truth aerial images with realistic, non-homogeneous haze of varying density. The performance of SkyGAN is evaluated on the recent SateHaze1k dataset as well as the HAI dataset. We also present a comprehensive evaluation of HAI dataset with a representative set of state-of-the-art techniques in terms of PSNR and SSIM.
Language-Driven Region Pointer Advancement for Controllable Image Captioning
Nov 30, 2020
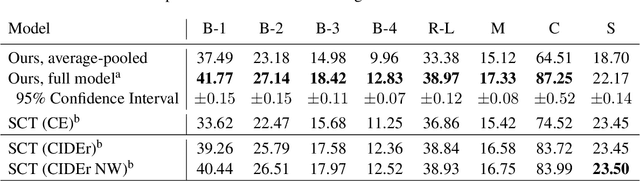
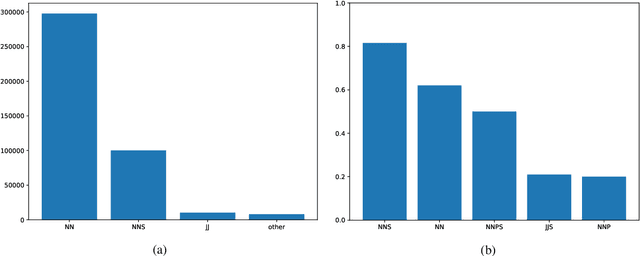
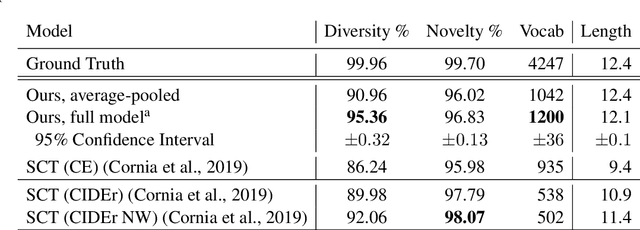
Controllable Image Captioning is a recent sub-field in the multi-modal task of Image Captioning wherein constraints are placed on which regions in an image should be described in the generated natural language caption. This puts a stronger focus on producing more detailed descriptions, and opens the door for more end-user control over results. A vital component of the Controllable Image Captioning architecture is the mechanism that decides the timing of attending to each region through the advancement of a region pointer. In this paper, we propose a novel method for predicting the timing of region pointer advancement by treating the advancement step as a natural part of the language structure via a NEXT-token, motivated by a strong correlation to the sentence structure in the training data. We find that our timing agrees with the ground-truth timing in the Flickr30k Entities test data with a precision of 86.55% and a recall of 97.92%. Our model implementing this technique improves the state-of-the-art on standard captioning metrics while additionally demonstrating a considerably larger effective vocabulary size.
Measuring Unintended Memorisation of Unique Private Features in Neural Networks
Feb 16, 2022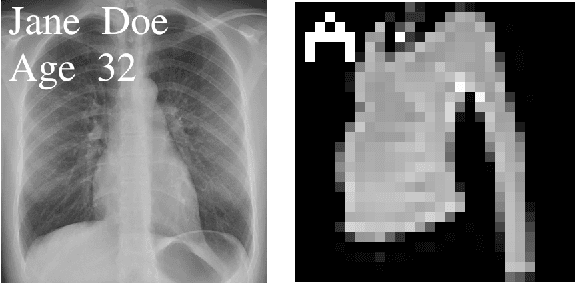
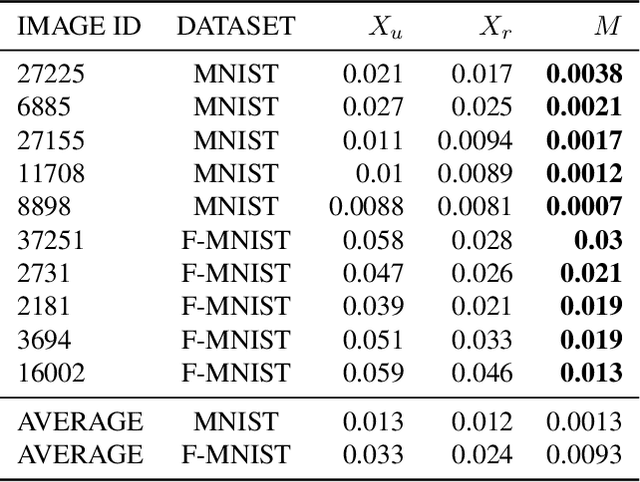

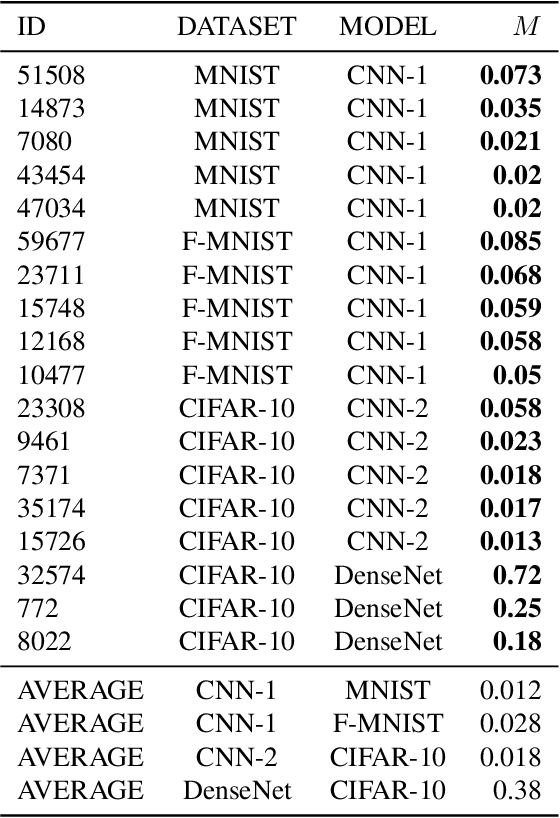
Neural networks pose a privacy risk to training data due to their propensity to memorise and leak information. Focusing on image classification, we show that neural networks also unintentionally memorise unique features even when they occur only once in training data. An example of a unique feature is a person's name that is accidentally present on a training image. Assuming access to the inputs and outputs of a trained model, the domain of the training data, and knowledge of unique features, we develop a score estimating the model's sensitivity to a unique feature by comparing the KL divergences of the model's output distributions given modified out-of-distribution images. Our results suggest that unique features are memorised by multi-layer perceptrons and convolutional neural networks trained on benchmark datasets, such as MNIST, Fashion-MNIST and CIFAR-10. We find that strategies to prevent overfitting (e.g.\ early stopping, regularisation, batch normalisation) do not prevent memorisation of unique features. These results imply that neural networks pose a privacy risk to rarely occurring private information. These risks can be more pronounced in healthcare applications if patient information is present in the training data.
Learning to Adapt to Light
Feb 16, 2022
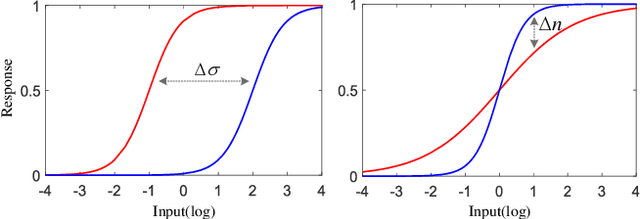
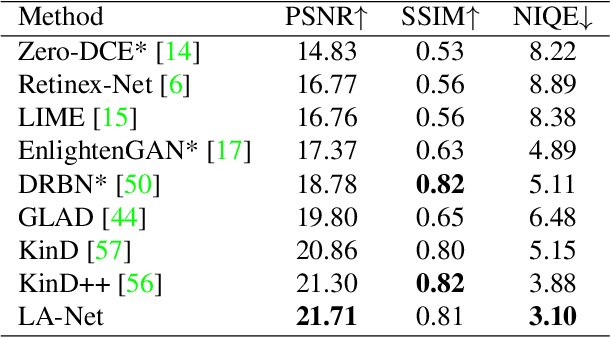
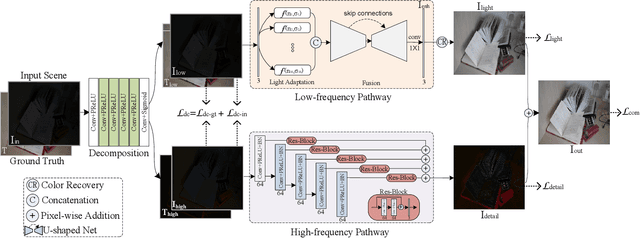
Light adaptation or brightness correction is a key step in improving the contrast and visual appeal of an image. There are multiple light-related tasks (for example, low-light enhancement and exposure correction) and previous studies have mainly investigated these tasks individually. However, it is interesting to consider whether these light-related tasks can be executed by a unified model, especially considering that our visual system adapts to external light in such way. In this study, we propose a biologically inspired method to handle light-related image-enhancement tasks with a unified network (called LA-Net). First, a frequency-based decomposition module is designed to decouple the common and characteristic sub-problems of light-related tasks into two pathways. Then, a new module is built inspired by biological visual adaptation to achieve unified light adaptation in the low-frequency pathway. In addition, noise suppression or detail enhancement is achieved effectively in the high-frequency pathway regardless of the light levels. Extensive experiments on three tasks -- low-light enhancement, exposure correction, and tone mapping -- demonstrate that the proposed method almost obtains state-of-the-art performance compared with recent methods designed for these individual tasks.
The Structured Abstain Problem and the Lovász Hinge
Mar 17, 2022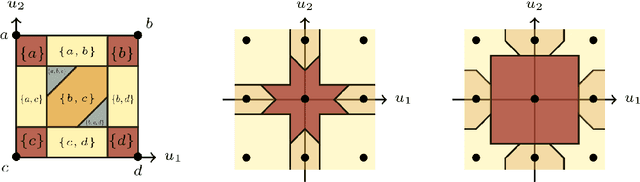


The Lov\'asz hinge is a convex surrogate recently proposed for structured binary classification, in which $k$ binary predictions are made simultaneously and the error is judged by a submodular set function. Despite its wide usage in image segmentation and related problems, its consistency has remained open. We resolve this open question, showing that the Lov\'asz hinge is inconsistent for its desired target unless the set function is modular. Leveraging a recent embedding framework, we instead derive the target loss for which the Lov\'asz hinge is consistent. This target, which we call the structured abstain problem, allows one to abstain on any subset of the $k$ predictions. We derive two link functions, each of which are consistent for all submodular set functions simultaneously.