 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA biological vision inspired framework for machine perception of abutting grating illusory contours
Aug 24, 2025Higher levels of machine intelligence demand alignment with human perception and cognition. Deep neural networks (DNN) dominated machine intelligence have demonstrated exceptional performance across various real-world tasks. Nevertheless, recent evidence suggests that DNNs fail to perceive illusory contours like the abutting grating, a discrepancy that misaligns with human perception patterns. Departing from previous works, we propose a novel deep network called illusory contour perception network (ICPNet) inspired by the circuits of the visual cortex. In ICPNet, a multi-scale feature projection (MFP) module is designed to extract multi-scale representations. To boost the interaction between feedforward and feedback features, a feature interaction attention module (FIAM) is introduced. Moreover, drawing inspiration from the shape bias observed in human perception, an edge detection task conducted via the edge fusion module (EFM) injects shape constraints that guide the network to concentrate on the foreground. We assess our method on the existing AG-MNIST test set and the AG-Fashion-MNIST test sets constructed by this work. Comprehensive experimental results reveal that ICPNet is significantly more sensitive to abutting grating illusory contours than state-of-the-art models, with notable improvements in top-1 accuracy across various subsets. This work is expected to make a step towards human-level intelligence for DNN-based models.
Weak Supervision with Arbitrary Single Frame for Micro- and Macro-expression Spotting
Mar 21, 2024



Frame-level micro- and macro-expression spotting methods require time-consuming frame-by-frame observation during annotation. Meanwhile, video-level spotting lacks sufficient information about the location and number of expressions during training, resulting in significantly inferior performance compared with fully-supervised spotting. To bridge this gap, we propose a point-level weakly-supervised expression spotting (PWES) framework, where each expression requires to be annotated with only one random frame (i.e., a point). To mitigate the issue of sparse label distribution, the prevailing solution is pseudo-label mining, which, however, introduces new problems: localizing contextual background snippets results in inaccurate boundaries and discarding foreground snippets leads to fragmentary predictions. Therefore, we design the strategies of multi-refined pseudo label generation (MPLG) and distribution-guided feature contrastive learning (DFCL) to address these problems. Specifically, MPLG generates more reliable pseudo labels by merging class-specific probabilities, attention scores, fused features, and point-level labels. DFCL is utilized to enhance feature similarity for the same categories and feature variability for different categories while capturing global representations across the entire datasets. Extensive experiments on the CAS(ME)^2, CAS(ME)^3, and SAMM-LV datasets demonstrate PWES achieves promising performance comparable to that of recent fully-supervised methods.
Learning to Adapt to Light
Feb 16, 2022
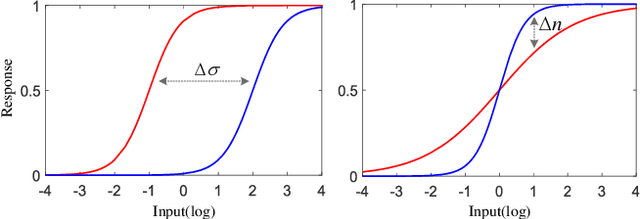
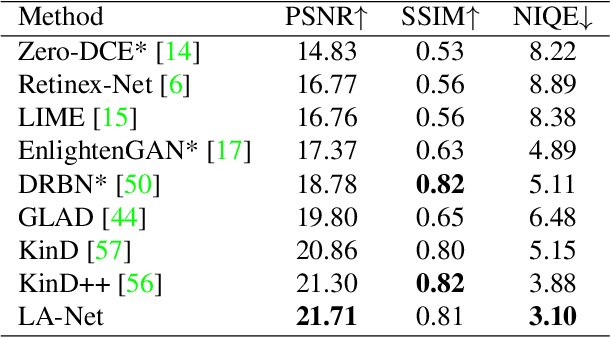
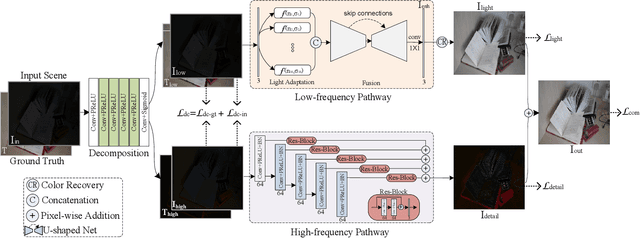
Light adaptation or brightness correction is a key step in improving the contrast and visual appeal of an image. There are multiple light-related tasks (for example, low-light enhancement and exposure correction) and previous studies have mainly investigated these tasks individually. However, it is interesting to consider whether these light-related tasks can be executed by a unified model, especially considering that our visual system adapts to external light in such way. In this study, we propose a biologically inspired method to handle light-related image-enhancement tasks with a unified network (called LA-Net). First, a frequency-based decomposition module is designed to decouple the common and characteristic sub-problems of light-related tasks into two pathways. Then, a new module is built inspired by biological visual adaptation to achieve unified light adaptation in the low-frequency pathway. In addition, noise suppression or detail enhancement is achieved effectively in the high-frequency pathway regardless of the light levels. Extensive experiments on three tasks -- low-light enhancement, exposure correction, and tone mapping -- demonstrate that the proposed method almost obtains state-of-the-art performance compared with recent methods designed for these individual tasks.