 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossATNet - A Novel Cross-Attention Based Framework for Sketch-Based Image Retrieval
Paper and Code
Apr 20, 2021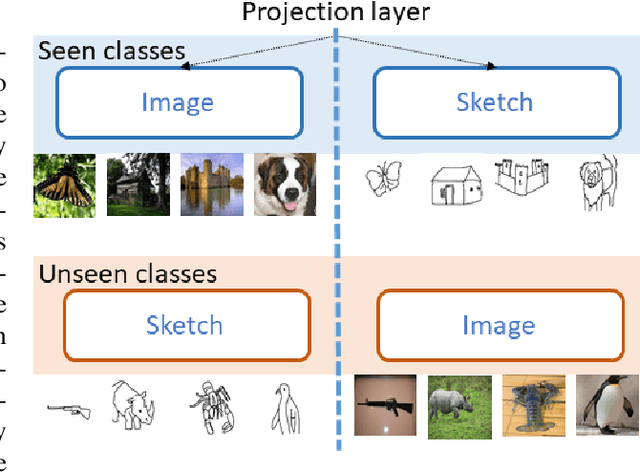
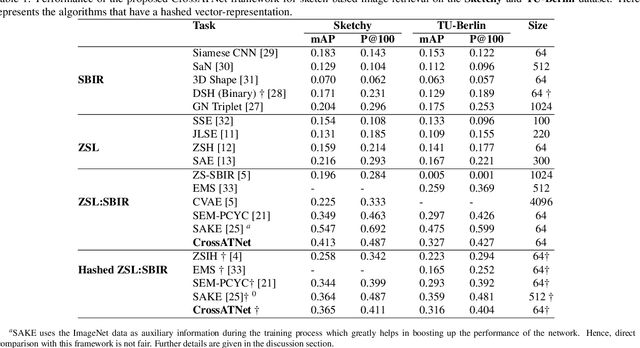
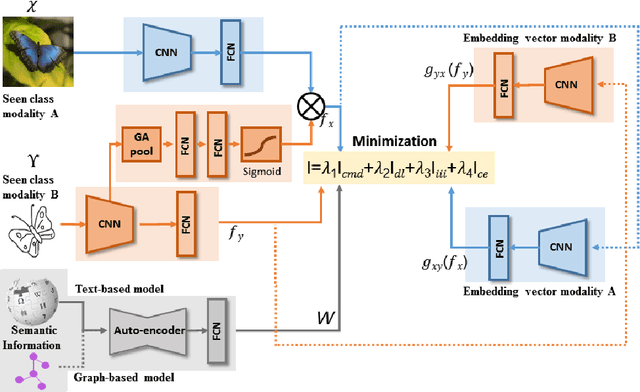
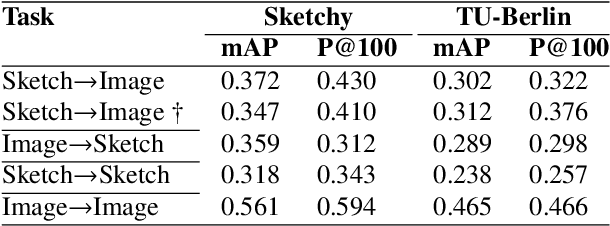
We propose a novel framework for cross-modal zero-shot learning (ZSL) in the context of sketch-based image retrieval (SBIR). Conventionally, the SBIR schema mainly considers simultaneous mappings among the two image views and the semantic side information. Therefore, it is desirable to consider fine-grained classes mainly in the sketch domain using highly discriminative and semantically rich feature space. However, the existing deep generative modeling-based SBIR approaches majorly focus on bridging the gaps between the seen and unseen classes by generating pseudo-unseen-class samples. Besides, violating the ZSL protocol by not utilizing any unseen-class information during training, such techniques do not pay explicit attention to modeling the discriminative nature of the shared space. Also, we note that learning a unified feature space for both the multi-view visual data is a tedious task considering the significant domain difference between sketches and color images. In this respect, as a remedy, we introduce a novel framework for zero-shot SBIR. While we define a cross-modal triplet loss to ensure the discriminative nature of the shared space, an innovative cross-modal attention learning strategy is also proposed to guide feature extraction from the image domain exploiting information from the respective sketch counterpart. In order to preserve the semantic consistency of the shared space, we consider a graph CNN-based module that propagates the semantic class topology to the shared space. To ensure an improved response time during inference, we further explore the possibility of representing the shared space in terms of hash codes. Experimental results obtained on the benchmark TU-Berlin and the Sketchy datasets confirm the superiority of CrossATNet in yielding state-of-the-art results.