 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TerrainMesh: Metric-Semantic Terrain Reconstruction from Aerial Images Using Joint 2D-3D Learning
Apr 23, 2022
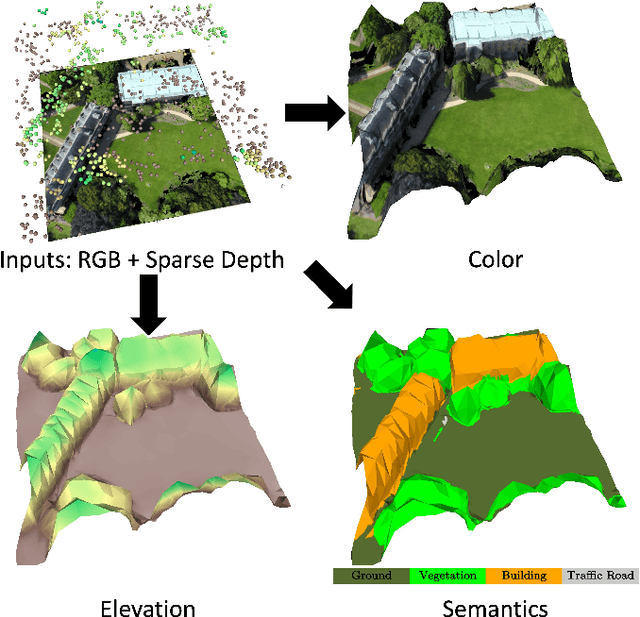

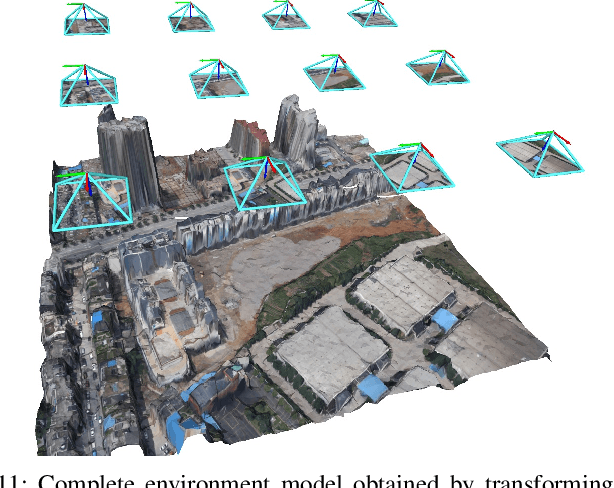
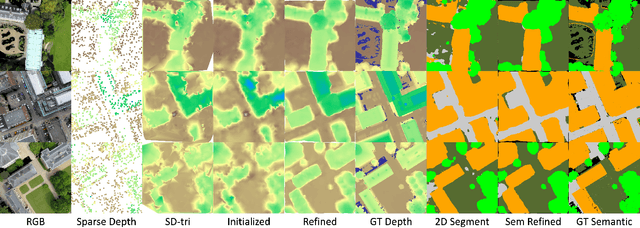
This paper considers outdoor terrain mapping using RGB images obtained from an aerial vehicle. While feature-based localization and mapping techniques deliver real-time vehicle odometry and sparse keypoint depth reconstruction, a dense model of the environment geometry and semantics (vegetation, buildings, etc.) is usually recovered offline with significant computation and storage. This paper develops a joint 2D-3D learning approach to reconstruct a local metric-semantic mesh at each camera keyframe maintained by a visual odometry algorithm. Given the estimated camera trajectory, the local meshes can be assembled into a global environment model to capture the terrain topology and semantics during online operation. A local mesh is reconstructed using an initialization and refinement stage. In the initialization stage, we estimate the mesh vertex elevation by solving a least squares problem relating the vertex barycentric coordinates to the sparse keypoint depth measurements. In the refinement stage, we associate 2D image and semantic features with the 3D mesh vertices using camera projection and apply graph convolution to refine the mesh vertex spatial coordinates and semantic features based on joint 2D and 3D supervision. Quantitative and qualitative evaluation using real aerial images show the potential of our method to support environmental monitoring and surveillance applications.
Self-Training Vision Language BERTs with a Unified Conditional Model
Jan 06, 2022
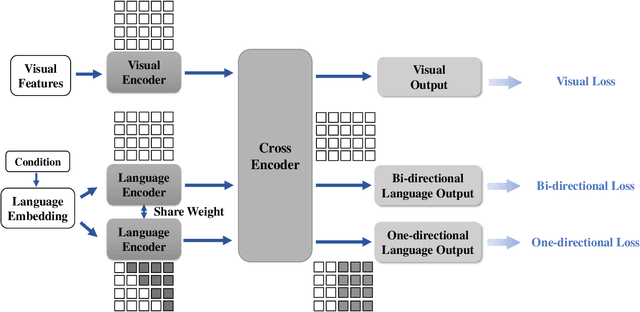
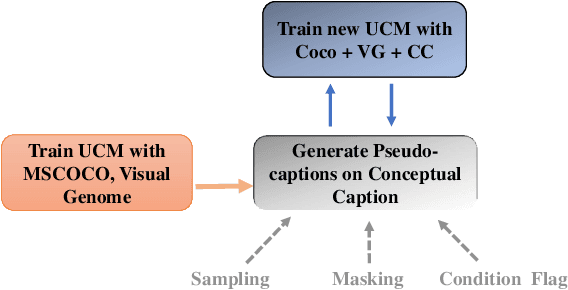

Natural language BERTs are trained with language corpus in a self-supervised manner. Unlike natural language BERTs, vision language BERTs need paired data to train, which restricts the scale of VL-BERT pretraining. We propose a self-training approach that allows training VL-BERTs from unlabeled image data. The proposed method starts with our unified conditional model -- a vision language BERT model that can perform zero-shot conditional generation. Given different conditions, the unified conditional model can generate captions, dense captions, and even questions. We use the labeled image data to train a teacher model and use the trained model to generate pseudo captions on unlabeled image data. We then combine the labeled data and pseudo labeled data to train a student model. The process is iterated by putting the student model as a new teacher. By using the proposed self-training approach and only 300k unlabeled extra data, we are able to get competitive or even better performances compared to the models of similar model size trained with 3 million extra image data.
MetaHDR: Model-Agnostic Meta-Learning for HDR Image Reconstruction
Mar 20, 2021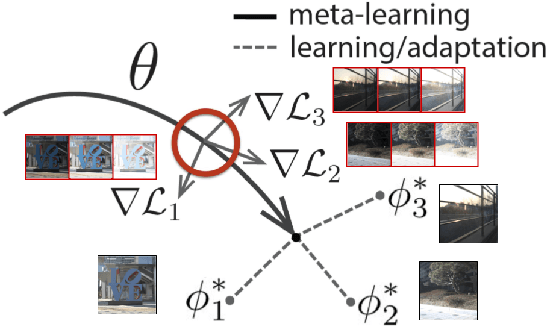
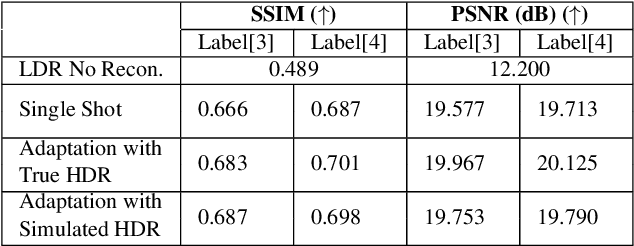

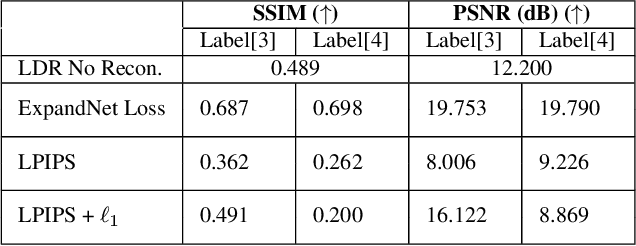
Capturing scenes with a high dynamic range is crucial to reproducing images that appear similar to those seen by the human visual system. Despite progress in developing data-driven deep learning approaches for converting low dynamic range images to high dynamic range images, existing approaches are limited by the assumption that all conversions are governed by the same nonlinear mapping. To address this problem, we propose "Model-Agnostic Meta-Learning for HDR Image Reconstruction" (MetaHDR), which applies meta-learning to the LDR-to-HDR conversion problem using existing HDR datasets. Our key novelty is the reinterpretation of LDR-to-HDR conversion scenes as independently sampled tasks from a common LDR-to-HDR conversion task distribution. Naturally, we use a meta-learning framework that learns a set of meta-parameters which capture the common structure consistent across all LDR-to-HDR conversion tasks. Finally, we perform experimentation with MetaHDR to demonstrate its capacity to tackle challenging LDR-to-HDR image conversions. Code and pretrained models are available at https://github.com/edwin-pan/MetaHDR.
More Grounded Image Captioning by Distilling Image-Text Matching Model
Apr 01, 2020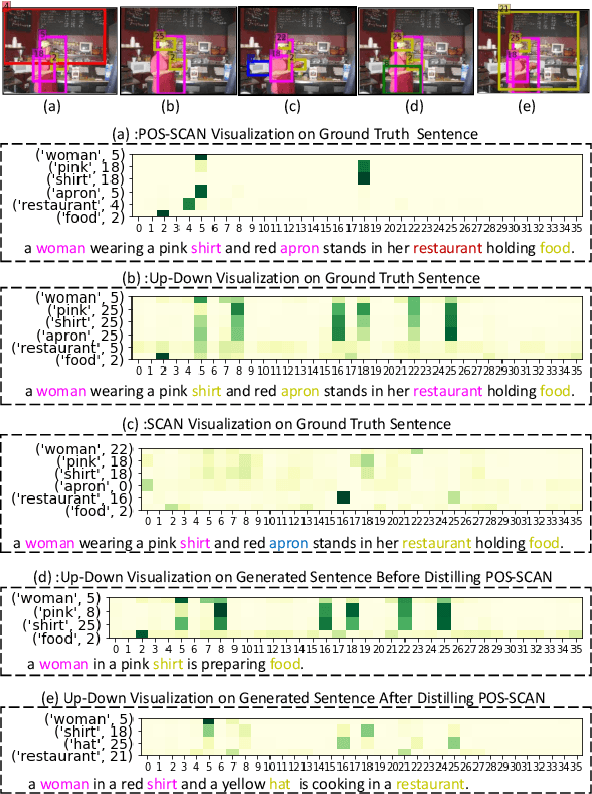

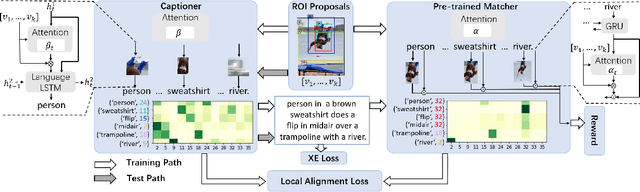
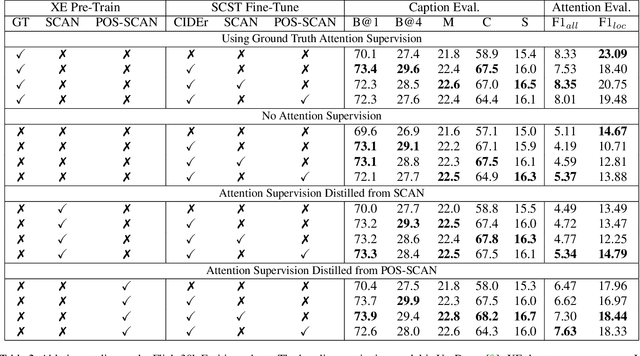
Visual attention not only improves the performance of image captioners, but also serves as a visual interpretation to qualitatively measure the caption rationality and model transparency. Specifically, we expect that a captioner can fix its attentive gaze on the correct objects while generating the corresponding words. This ability is also known as grounded image captioning. However, the grounding accuracy of existing captioners is far from satisfactory. To improve the grounding accuracy while retaining the captioning quality, it is expensive to collect the word-region alignment as strong supervision. To this end, we propose a Part-of-Speech (POS) enhanced image-text matching model (SCAN \cite{lee2018stacked}): POS-SCAN, as the effective knowledge distillation for more grounded image captioning. The benefits are two-fold: 1) given a sentence and an image, POS-SCAN can ground the objects more accurately than SCAN; 2) POS-SCAN serves as a word-region alignment regularization for the captioner's visual attention module. By showing benchmark experimental results, we demonstrate that conventional image captioners equipped with POS-SCAN can significantly improve the grounding accuracy without strong supervision. Last but not the least, we explore the indispensable Self-Critical Sequence Training (SCST) \cite{Rennie_2017_CVPR} in the context of grounded image captioning and show that the image-text matching score can serve as a reward for more grounded captioning \footnote{https://github.com/YuanEZhou/Grounded-Image-Captioning}.
Self-supervised learning unveils morphological clusters behind lung cancer types and prognosis
May 04, 2022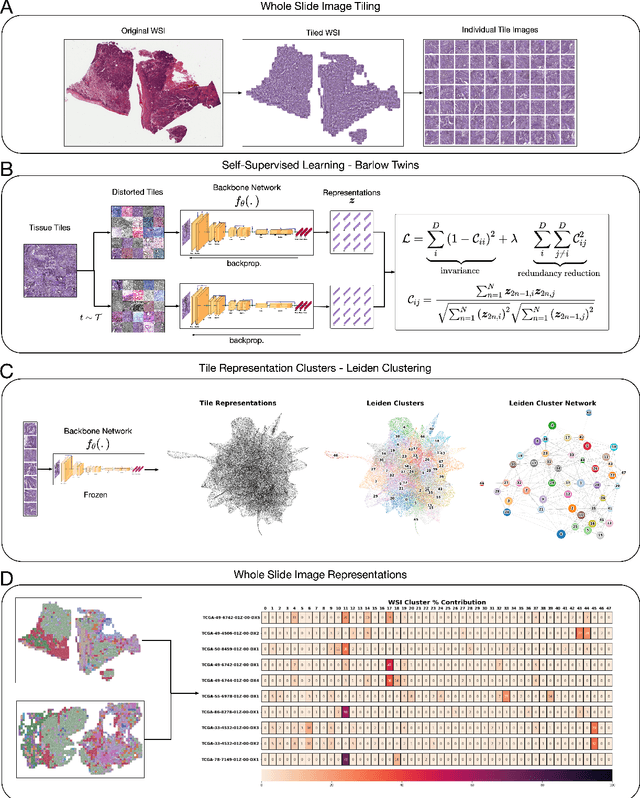
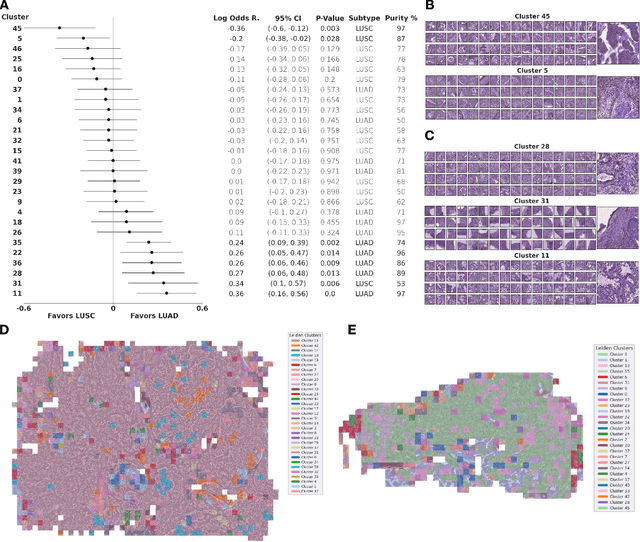
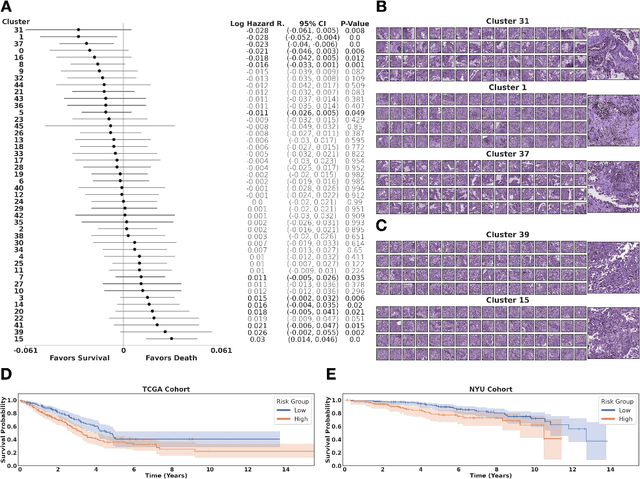
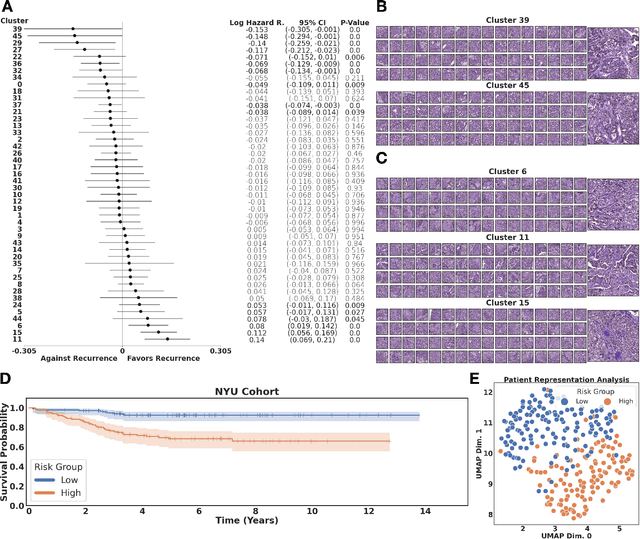
Histopathological images of tumors contain abundant information about how tumors grow and how they interact with their micro-environment. Characterizing and improving our understanding of phenotypes could reveal factors related to tumor progression and their underpinning biological processes, ultimately improving diagnosis and treatment. In recent years, the field of histological deep learning applications has seen great progress, yet most of these applications focus on a supervised approach, relating tissue and associated sample annotations. Supervised approaches have their impact limited by two factors. Firstly, high-quality labels are expensive in time and effort, which makes them not easily scalable. Secondly, these methods focus on predicting annotations from histological images, fundamentally restricting the discovery of new tissue phenotypes. These limitations emphasize the importance of using new methods that can characterize tissue by the features enclosed in the image, without pre-defined annotation or supervision. We present Phenotype Representation Learning (PRL), a methodology to extract histomorphological phenotypes through self-supervised learning and community detection. PRL creates phenotype clusters by identifying tissue patterns that share common morphological and cellular features, allowing to describe whole slide images through compositional representations of cluster contributions. We used this framework to analyze histopathology slides of LUAD and LUSC lung cancer subtypes from TCGA and NYU cohorts. We show that PRL achieves a robust lung subtype prediction providing statistically relevant phenotypes for each lung subtype. We further demonstrate the significance of these phenotypes in lung adenocarcinoma overall and recurrence free survival, relating clusters with patient outcomes, cell types, grown patterns, and omic-based immune signatures.
Self-Organized Residual Blocks for Image Super-Resolution
May 31, 2021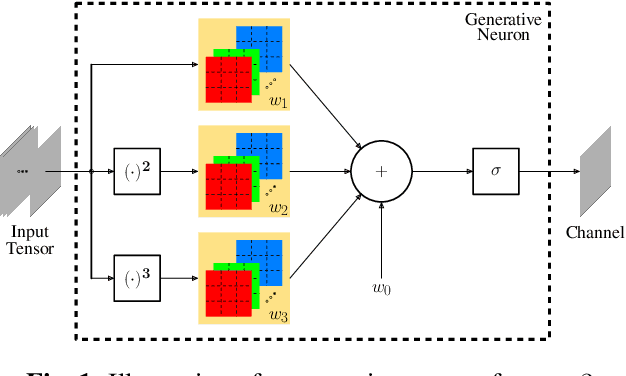
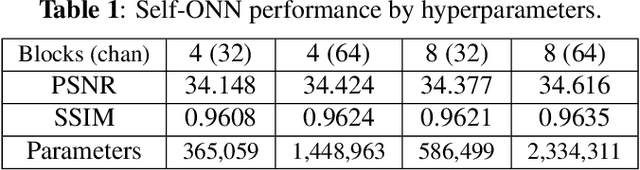
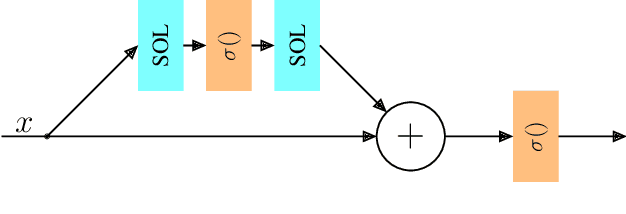
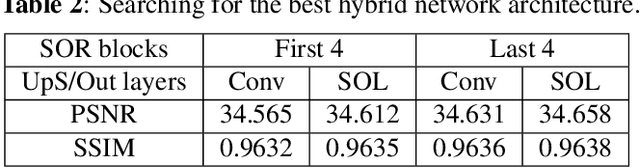
It has become a standard practice to use the convolutional networks (ConvNet) with RELU non-linearity in image restoration and super-resolution (SR). Although the universal approximation theorem states that a multi-layer neural network can approximate any non-linear function with the desired precision, it does not reveal the best network architecture to do so. Recently, operational neural networks (ONNs) that choose the best non-linearity from a set of alternatives, and their "self-organized" variants (Self-ONN) that approximate any non-linearity via Taylor series have been proposed to address the well-known limitations and drawbacks of conventional ConvNets such as network homogeneity using only the McCulloch-Pitts neuron model. In this paper, we propose the concept of self-organized operational residual (SOR) blocks, and present hybrid network architectures combining regular residual and SOR blocks to strike a balance between the benefits of stronger non-linearity and the overall number of parameters. The experimental results demonstrate that the~proposed architectures yield performance improvements in both PSNR and perceptual metrics.
Enhancement of damaged-image prediction through Cahn-Hilliard Image Inpainting
Jul 21, 2020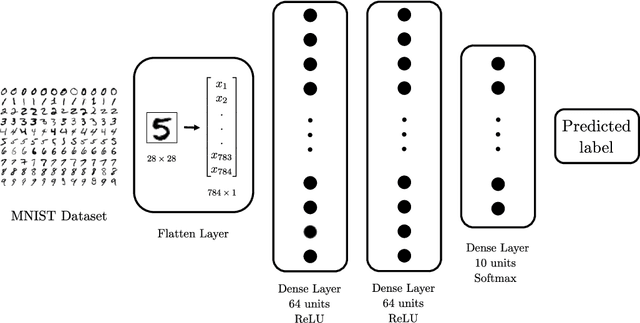
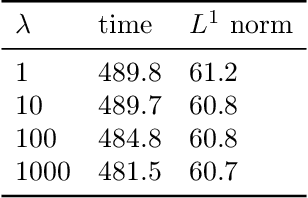
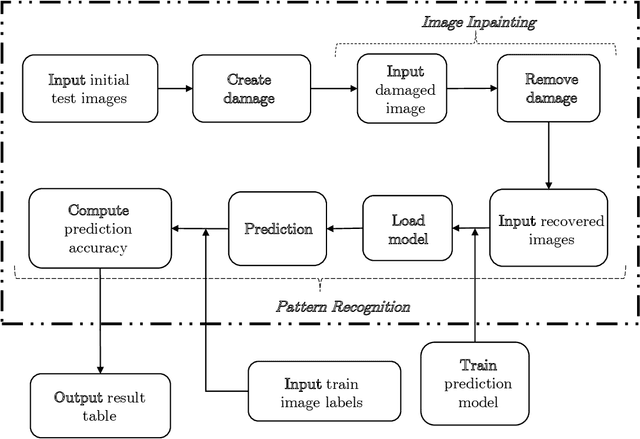

We assess the benefit of including an image inpainting filter before passing damaged images into a classification neural network. For this we employ a modified Cahn-Hilliard equation as an image inpainting filter, which is solved via a finite volume scheme with reduced computational cost and adequate properties for energy stability and boundedness. The benchmark dataset employed here is the MNIST dataset, which consists in binary images of digits. We train a neural network based of dense layers with the training set of MNIST, and subsequently we contaminate the test set with damage of different types and intensities. We then compare the prediction accuracy of the neural network with and without applying the Cahn-Hilliard filter to the damaged images test. Our results quantify the significant improvement of damaged-image prediction due to applying the Cahn-Hilliard filter, which for specific damages can increase up to 50% and is in general advantageous for low to moderate damage.
Image interpretation by iterative bottom-up top-down processing
May 12, 2021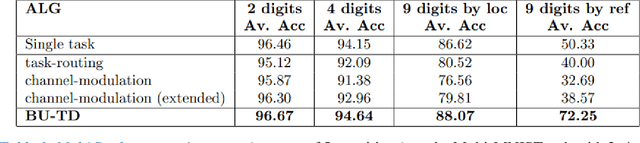

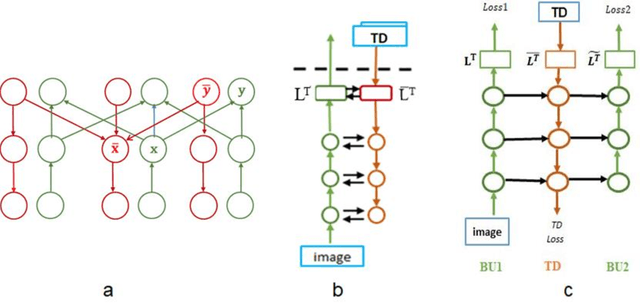
Scene understanding requires the extraction and representation of scene components together with their properties and inter-relations. We describe a model in which meaningful scene structures are extracted from the image by an iterative process, combining bottom-up (BU) and top-down (TD) networks, interacting through a symmetric bi-directional communication between them (counter-streams structure). The model constructs a scene representation by the iterative use of three components. The first model component is a BU stream that extracts selected scene elements, properties and relations. The second component (cognitive augmentation) augments the extracted visual representation based on relevant non-visual stored representations. It also provides input to the third component, the TD stream, in the form of a TD instruction, instructing the model what task to perform next. The TD stream then guides the BU visual stream to perform the selected task in the next cycle. During this process, the visual representations extracted from the image can be combined with relevant non-visual representations, so that the final scene representation is based on both visual information extracted from the scene and relevant stored knowledge of the world. We describe how a sequence of TD-instructions is used to extract from the scene structures of interest, including an algorithm to automatically select the next TD-instruction in the sequence. The extraction process is shown to have favorable properties in terms of combinatorial generalization, generalizing well to novel scene structures and new combinations of objects, properties and relations not seen during training. Finally, we compare the model with relevant aspects of the human vision, and suggest directions for using the BU-TD scheme for integrating visual and cognitive components in the process of scene understanding.
Self Supervised Lesion Recognition For Breast Ultrasound Diagnosis
Apr 18, 2022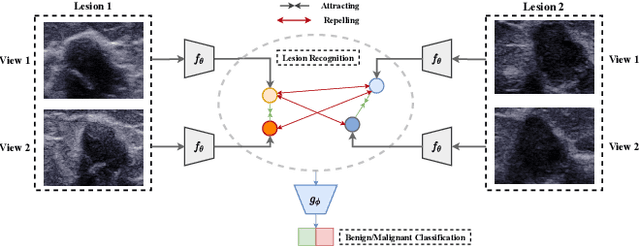


Previous deep learning based Computer Aided Diagnosis (CAD) system treats multiple views of the same lesion as independent images. Since an ultrasound image only describes a partial 2D projection of a 3D lesion, such paradigm ignores the semantic relationship between different views of a lesion, which is inconsistent with the traditional diagnosis where sonographers analyze a lesion from at least two views. In this paper, we propose a multi-task framework that complements Benign/Malignant classification task with lesion recognition (LR) which helps leveraging relationship among multiple views of a single lesion to learn a complete representation of the lesion. To be specific, LR task employs contrastive learning to encourage representation that pulls multiple views of the same lesion and repels those of different lesions. The task therefore facilitates a representation that is not only invariant to the view change of the lesion, but also capturing fine-grained features to distinguish between different lesions. Experiments show that the proposed multi-task framework boosts the performance of Benign/Malignant classification as two sub-tasks complement each other and enhance the learned representation of ultrasound images.
A Neural Ordinary Differential Equation Model for Visualizing Deep Neural Network Behaviors in Multi-Parametric MRI based Glioma Segmentation
Mar 23, 2022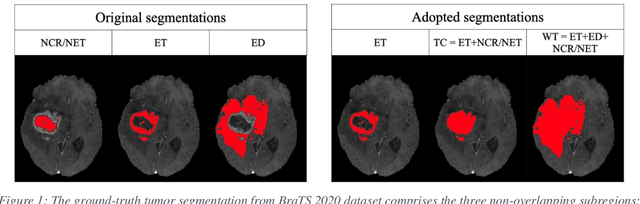
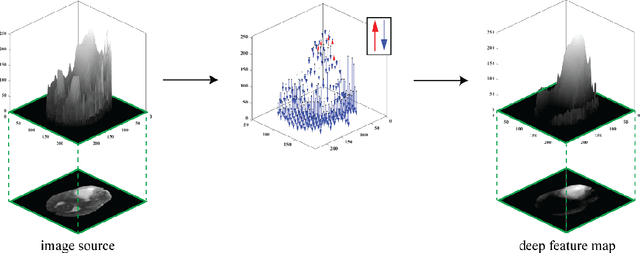
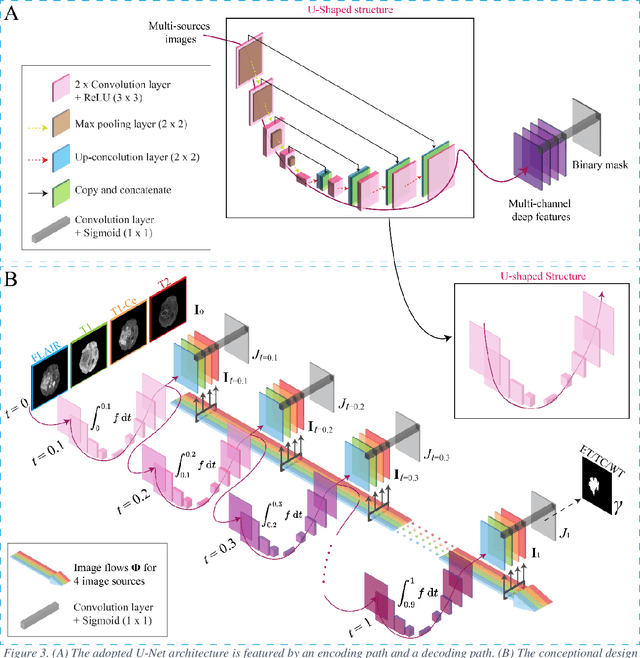
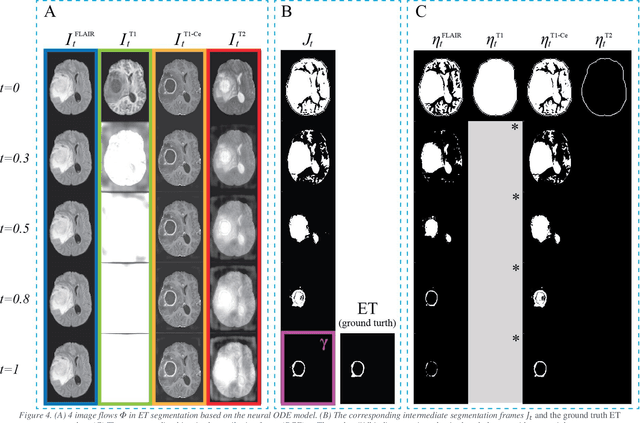
Purpose: To develop a neural ordinary differential equation (ODE) model for visualizing deep neural network (DNN) behavior during multi-parametric MRI (mp-MRI) based glioma segmentation as a method to enhance deep learning explainability. Methods: By hypothesizing that deep feature extraction can be modeled as a spatiotemporally continuous process, we designed a novel deep learning model, neural ODE, in which deep feature extraction was governed by an ODE without explicit expression. The dynamics of 1) MR images after interactions with DNN and 2) segmentation formation can be visualized after solving ODE. An accumulative contribution curve (ACC) was designed to quantitatively evaluate the utilization of each MRI by DNN towards the final segmentation results. The proposed neural ODE model was demonstrated using 369 glioma patients with a 4-modality mp-MRI protocol: T1, contrast-enhanced T1 (T1-Ce), T2, and FLAIR. Three neural ODE models were trained to segment enhancing tumor (ET), tumor core (TC), and whole tumor (WT). The key MR modalities with significant utilization by DNN were identified based on ACC analysis. Segmentation results by DNN using only the key MR modalities were compared to the ones using all 4 MR modalities. Results: All neural ODE models successfully illustrated image dynamics as expected. ACC analysis identified T1-Ce as the only key modality in ET and TC segmentations, while both FLAIR and T2 were key modalities in WT segmentation. Compared to the U-Net results using all 4 MR modalities, Dice coefficient of ET (0.784->0.775), TC (0.760->0.758), and WT (0.841->0.837) using the key modalities only had minimal differences without significance. Conclusion: The neural ODE model offers a new tool for optimizing the deep learning model inputs with enhanced explainability. The presented methodology can be generalized to other medical image-related deep learning applications.