 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessment Design in the AI Era: A Method for Identifying Items Functioning Differentially for Humans and Chatbots
Mar 24, 2026The rapid adoption of large language models (LLMs) in education raises profound challenges for assessment design. To adapt assessments to the presence of LLM-based tools, it is crucial to characterize the strengths and weaknesses of LLMs in a generalizable, valid and reliable manner. However, current LLM evaluations often rely on descriptive statistics derived from benchmarks, and little research applies theory-grounded measurement methods to characterize LLM capabilities relative to human learners in ways that directly support assessment design. Here, by combining educational data mining and psychometric theory, we introduce a statistically principled approach for identifying items on which humans and LLMs show systematic response differences, pinpointing where assessments may be most vulnerable to AI misuse, and which task dimensions make problems particularly easy or difficult for generative AI. The method is based on Differential Item Functioning (DIF) analysis -- traditionally used to detect bias across demographic groups -- together with negative control analysis and item-total correlation discrimination analysis. It is evaluated on responses from human learners and six leading chatbots (ChatGPT-4o \& 5.2, Gemini 1.5 \& 3 Pro, Claude 3.5 \& 4.5 Sonnet) to two instruments: a high school chemistry diagnostic test and a university entrance exam. Subject-matter experts then analyzed DIF-flagged items to characterize task dimensions associated with chatbot over- or under-performance. Results show that DIF-informed analytics provide a robust framework for understanding where LLM and human capabilities diverge, and highlight their value for improving the design of valid, reliable, and fair assessment in the AI era.
Applying IRT to Distinguish Between Human and Generative AI Responses to Multiple-Choice Assessments
Dec 12, 2024



Generative AI is transforming the educational landscape, raising significant concerns about cheating. Despite the widespread use of multiple-choice questions in assessments, the detection of AI cheating in MCQ-based tests has been almost unexplored, in contrast to the focus on detecting AI-cheating on text-rich student outputs. In this paper, we propose a method based on the application of Item Response Theory to address this gap. Our approach operates on the assumption that artificial and human intelligence exhibit different response patterns, with AI cheating manifesting as deviations from the expected patterns of human responses. These deviations are modeled using Person-Fit Statistics. We demonstrate that this method effectively highlights the differences between human responses and those generated by premium versions of leading chatbots (ChatGPT, Claude, and Gemini), but that it is also sensitive to the amount of AI cheating in the data. Furthermore, we show that the chatbots differ in their reasoning profiles. Our work provides both a theoretical foundation and empirical evidence for the application of IRT to identify AI cheating in MCQ-based assessments.
Image interpretation by iterative bottom-up top-down processing
May 12, 2021
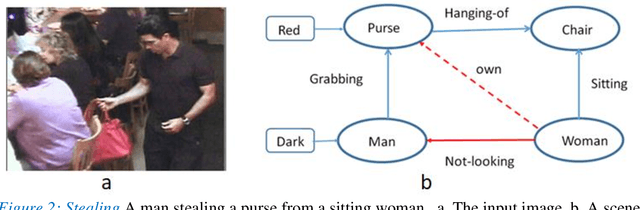

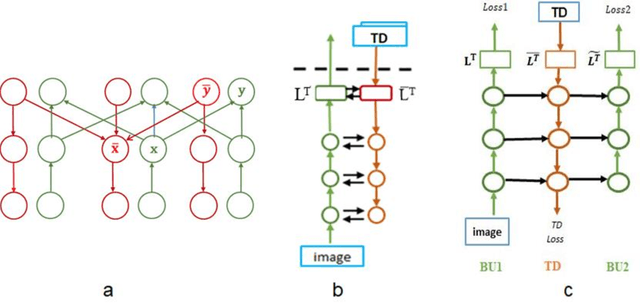
Scene understanding requires the extraction and representation of scene components together with their properties and inter-relations. We describe a model in which meaningful scene structures are extracted from the image by an iterative process, combining bottom-up (BU) and top-down (TD) networks, interacting through a symmetric bi-directional communication between them (counter-streams structure). The model constructs a scene representation by the iterative use of three components. The first model component is a BU stream that extracts selected scene elements, properties and relations. The second component (cognitive augmentation) augments the extracted visual representation based on relevant non-visual stored representations. It also provides input to the third component, the TD stream, in the form of a TD instruction, instructing the model what task to perform next. The TD stream then guides the BU visual stream to perform the selected task in the next cycle. During this process, the visual representations extracted from the image can be combined with relevant non-visual representations, so that the final scene representation is based on both visual information extracted from the scene and relevant stored knowledge of the world. We describe how a sequence of TD-instructions is used to extract from the scene structures of interest, including an algorithm to automatically select the next TD-instruction in the sequence. The extraction process is shown to have favorable properties in terms of combinatorial generalization, generalizing well to novel scene structures and new combinations of objects, properties and relations not seen during training. Finally, we compare the model with relevant aspects of the human vision, and suggest directions for using the BU-TD scheme for integrating visual and cognitive components in the process of scene understanding.