 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage interpretation by iterative bottom-up top-down processing
May 12, 2021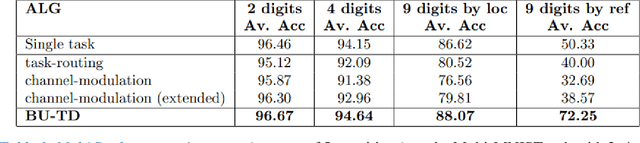
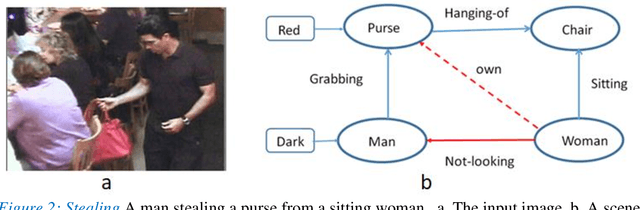

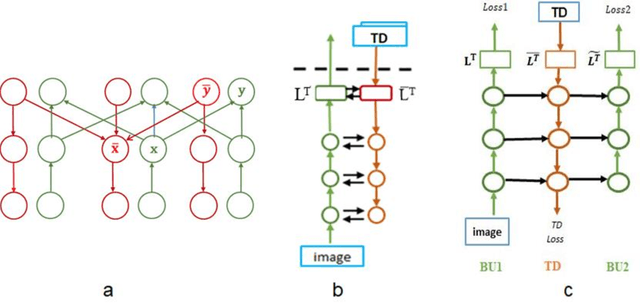
Scene understanding requires the extraction and representation of scene components together with their properties and inter-relations. We describe a model in which meaningful scene structures are extracted from the image by an iterative process, combining bottom-up (BU) and top-down (TD) networks, interacting through a symmetric bi-directional communication between them (counter-streams structure). The model constructs a scene representation by the iterative use of three components. The first model component is a BU stream that extracts selected scene elements, properties and relations. The second component (cognitive augmentation) augments the extracted visual representation based on relevant non-visual stored representations. It also provides input to the third component, the TD stream, in the form of a TD instruction, instructing the model what task to perform next. The TD stream then guides the BU visual stream to perform the selected task in the next cycle. During this process, the visual representations extracted from the image can be combined with relevant non-visual representations, so that the final scene representation is based on both visual information extracted from the scene and relevant stored knowledge of the world. We describe how a sequence of TD-instructions is used to extract from the scene structures of interest, including an algorithm to automatically select the next TD-instruction in the sequence. The extraction process is shown to have favorable properties in terms of combinatorial generalization, generalizing well to novel scene structures and new combinations of objects, properties and relations not seen during training. Finally, we compare the model with relevant aspects of the human vision, and suggest directions for using the BU-TD scheme for integrating visual and cognitive components in the process of scene understanding.
VQA with no questions-answers training
Nov 20, 2018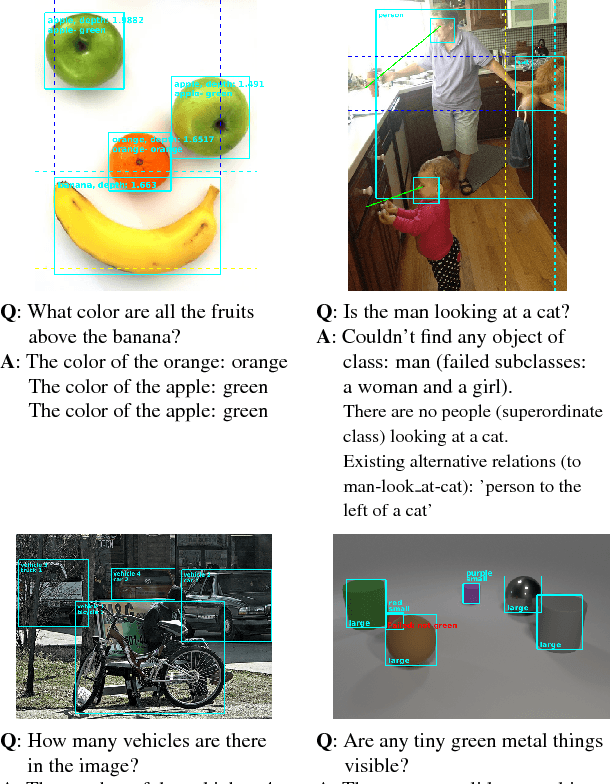
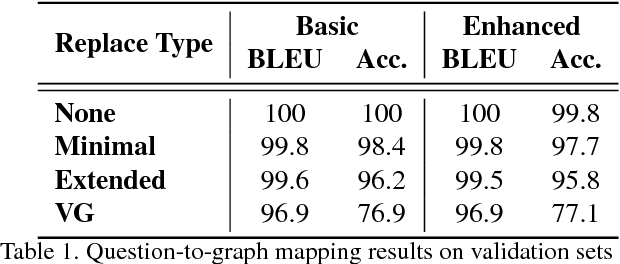
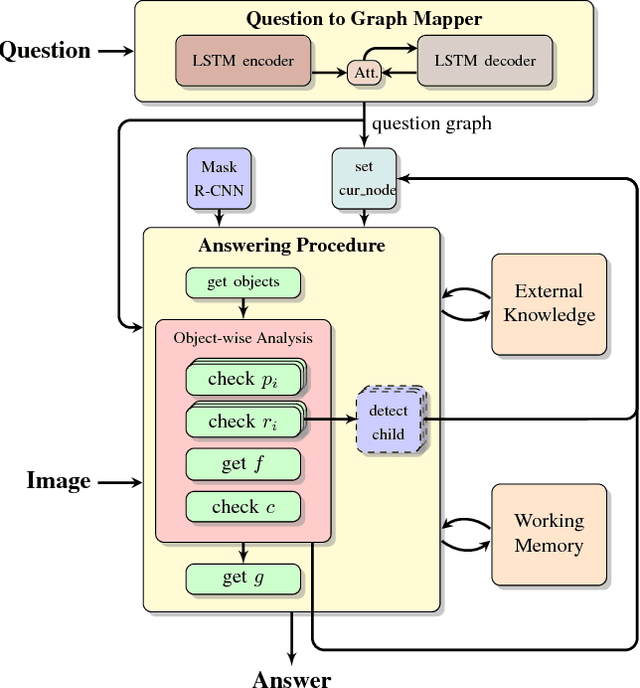
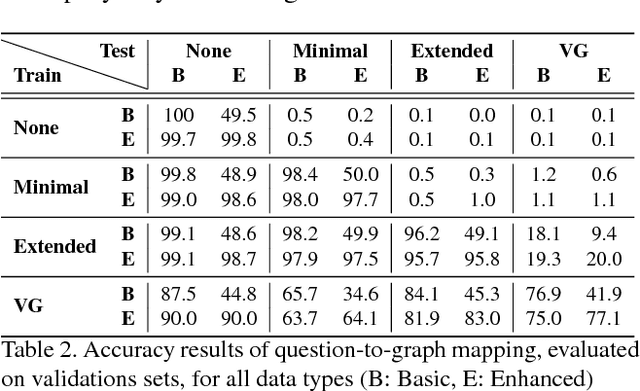
Methods for teaching machines to answer visual questions have made significant progress in the last few years, but although demonstrating impressive results on particular datasets, these methods lack some important human capabilities, including integrating new visual classes and concepts in a modular manner, providing explanations for the answer and handling new domains without new examples. In this paper we present a system that achieves state-of-the-art results on the CLEVR dataset without any questions-answers training, utilizes real visual estimators and explains the answer. The system includes a question representation stage followed by an answering procedure, which invokes an extendable set of visual estimators. It can explain the answer, including its failures, and provide alternatives to negative answers. The scheme builds upon a framework proposed recently, with extensions allowing the system to deal with novel domains without relying on training examples.