 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Social Perception in Intuitive Physics
Mar 28, 2026People infer rich social information from others' actions. These inferences are often constrained by the physical world: what agents can do, what obstacles permit, and how the physical actions of agents causally change an environment and other agents' mental states and behavior. We propose that such rich social perception is more than visual pattern matching, but rather a reasoning process grounded in an integration of intuitive psychology with intuitive physics. To test this hypothesis, we introduced PHASE (PHysically grounded Abstract Social Events), a large dataset of procedurally generated animations, depicting physically simulated two-agent interactions on a 2D surface. Each animation follows the style of the Heider and Simmel movie, with systematic variation in environment geometry, object dynamics, agent capacities, goals, and relationships (friendly/adversarial/neutral). We then present a computational model, SIMPLE, a physics-grounded Bayesian inverse planning model that integrates planning, probabilistic planning, and physics simulation to infer agents' goals and relations from their trajectories. Our experimental results showed that SIMPLE achieved high accuracy and agreement with human judgments across diverse scenarios, while feedforward baseline models -- including strong vision-language models -- and physics-agnostic inverse planning failed to achieve human-level performance and did not align with human judgments. These results suggest that our model provides a computational account for how people understand physically grounded social scenes by inverting a generative model of physics and agents.
Known Unknowns: Out-of-Distribution Property Prediction in Materials and Molecules
Feb 09, 2025Discovery of high-performance materials and molecules requires identifying extremes with property values that fall outside the known distribution. Therefore, the ability to extrapolate to out-of-distribution (OOD) property values is critical for both solid-state materials and molecular design. Our objective is to train predictor models that extrapolate zero-shot to higher ranges than in the training data, given the chemical compositions of solids or molecular graphs and their property values. We propose using a transductive approach to OOD property prediction, achieving improvements in prediction accuracy. In particular, the True Positive Rate (TPR) of OOD classification of materials and molecules improved by 3x and 2.5x, respectively, and precision improved by 2x and 1.5x compared to non-transductive baselines. Our method leverages analogical input-target relations in the training and test sets, enabling generalization beyond the training target support, and can be applied to any other material and molecular tasks.
Few-Shot Task Learning through Inverse Generative Modeling
Nov 07, 2024



Learning the intents of an agent, defined by its goals or motion style, is often extremely challenging from just a few examples. We refer to this problem as task concept learning and present our approach, Few-Shot Task Learning through Inverse Generative Modeling (FTL-IGM), which learns new task concepts by leveraging invertible neural generative models. The core idea is to pretrain a generative model on a set of basic concepts and their demonstrations. Then, given a few demonstrations of a new concept (such as a new goal or a new action), our method learns the underlying concepts through backpropagation without updating the model weights, thanks to the invertibility of the generative model. We evaluate our method in five domains -- object rearrangement, goal-oriented navigation, motion caption of human actions, autonomous driving, and real-world table-top manipulation. Our experimental results demonstrate that via the pretrained generative model, we successfully learn novel concepts and generate agent plans or motion corresponding to these concepts in (1) unseen environments and (2) in composition with training concepts.
Diagnosis, Feedback, Adaptation: A Human-in-the-Loop Framework for Test-Time Policy Adaptation
Jul 13, 2023



Policies often fail due to distribution shift -- changes in the state and reward that occur when a policy is deployed in new environments. Data augmentation can increase robustness by making the model invariant to task-irrelevant changes in the agent's observation. However, designers don't know which concepts are irrelevant a priori, especially when different end users have different preferences about how the task is performed. We propose an interactive framework to leverage feedback directly from the user to identify personalized task-irrelevant concepts. Our key idea is to generate counterfactual demonstrations that allow users to quickly identify possible task-relevant and irrelevant concepts. The knowledge of task-irrelevant concepts is then used to perform data augmentation and thus obtain a policy adapted to personalized user objectives. We present experiments validating our framework on discrete and continuous control tasks with real human users. Our method (1) enables users to better understand agent failure, (2) reduces the number of demonstrations required for fine-tuning, and (3) aligns the agent to individual user task preferences.
Learning to Extrapolate: A Transductive Approach
Apr 27, 2023Machine learning systems, especially with overparameterized deep neural networks, can generalize to novel test instances drawn from the same distribution as the training data. However, they fare poorly when evaluated on out-of-support test points. In this work, we tackle the problem of developing machine learning systems that retain the power of overparameterized function approximators while enabling extrapolation to out-of-support test points when possible. This is accomplished by noting that under certain conditions, a "transductive" reparameterization can convert an out-of-support extrapolation problem into a problem of within-support combinatorial generalization. We propose a simple strategy based on bilinear embeddings to enable this type of combinatorial generalization, thereby addressing the out-of-support extrapolation problem under certain conditions. We instantiate a simple, practical algorithm applicable to various supervised learning and imitation learning tasks.
Discovering Generalizable Spatial Goal Representations via Graph-based Active Reward Learning
Nov 24, 2022In this work, we consider one-shot imitation learning for object rearrangement tasks, where an AI agent needs to watch a single expert demonstration and learn to perform the same task in different environments. To achieve a strong generalization, the AI agent must infer the spatial goal specification for the task. However, there can be multiple goal specifications that fit the given demonstration. To address this, we propose a reward learning approach, Graph-based Equivalence Mappings (GEM), that can discover spatial goal representations that are aligned with the intended goal specification, enabling successful generalization in unseen environments. Specifically, GEM represents a spatial goal specification by a reward function conditioned on i) a graph indicating important spatial relationships between objects and ii) state equivalence mappings for each edge in the graph indicating invariant properties of the corresponding relationship. GEM combines inverse reinforcement learning and active reward learning to efficiently improve the reward function by utilizing the graph structure and domain randomization enabled by the equivalence mappings. We conducted experiments with simulated oracles and with human subjects. The results show that GEM can drastically improve the generalizability of the learned goal representations over strong baselines.
Image interpretation by iterative bottom-up top-down processing
May 12, 2021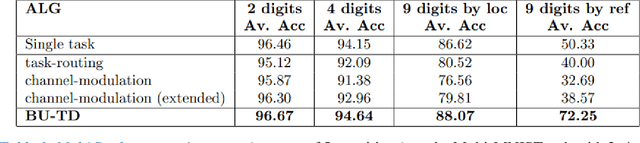
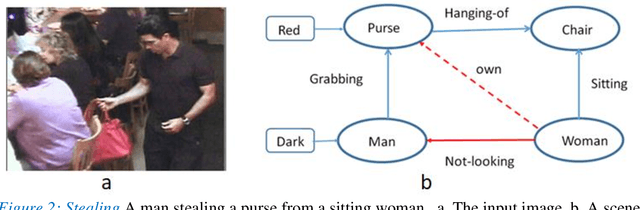

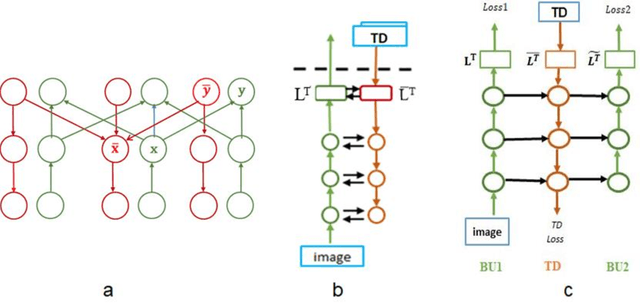
Scene understanding requires the extraction and representation of scene components together with their properties and inter-relations. We describe a model in which meaningful scene structures are extracted from the image by an iterative process, combining bottom-up (BU) and top-down (TD) networks, interacting through a symmetric bi-directional communication between them (counter-streams structure). The model constructs a scene representation by the iterative use of three components. The first model component is a BU stream that extracts selected scene elements, properties and relations. The second component (cognitive augmentation) augments the extracted visual representation based on relevant non-visual stored representations. It also provides input to the third component, the TD stream, in the form of a TD instruction, instructing the model what task to perform next. The TD stream then guides the BU visual stream to perform the selected task in the next cycle. During this process, the visual representations extracted from the image can be combined with relevant non-visual representations, so that the final scene representation is based on both visual information extracted from the scene and relevant stored knowledge of the world. We describe how a sequence of TD-instructions is used to extract from the scene structures of interest, including an algorithm to automatically select the next TD-instruction in the sequence. The extraction process is shown to have favorable properties in terms of combinatorial generalization, generalizing well to novel scene structures and new combinations of objects, properties and relations not seen during training. Finally, we compare the model with relevant aspects of the human vision, and suggest directions for using the BU-TD scheme for integrating visual and cognitive components in the process of scene understanding.
PHASE: PHysically-grounded Abstract Social Events for Machine Social Perception
Mar 19, 2021
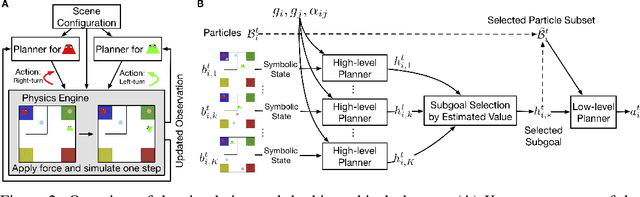

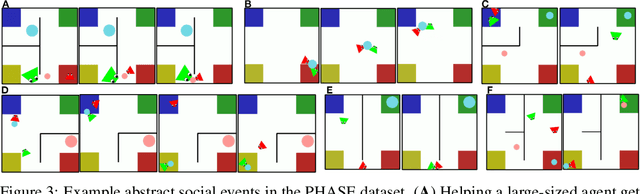
The ability to perceive and reason about social interactions in the context of physical environments is core to human social intelligence and human-machine cooperation. However, no prior dataset or benchmark has systematically evaluated physically grounded perception of complex social interactions that go beyond short actions, such as high-fiving, or simple group activities, such as gathering. In this work, we create a dataset of physically-grounded abstract social events, PHASE, that resemble a wide range of real-life social interactions by including social concepts such as helping another agent. PHASE consists of 2D animations of pairs of agents moving in a continuous space generated procedurally using a physics engine and a hierarchical planner. Agents have a limited field of view, and can interact with multiple objects, in an environment that has multiple landmarks and obstacles. Using PHASE, we design a social recognition task and a social prediction task. PHASE is validated with human experiments demonstrating that humans perceive rich interactions in the social events, and that the simulated agents behave similarly to humans. As a baseline model, we introduce a Bayesian inverse planning approach, SIMPLE (SIMulation, Planning and Local Estimation), which outperforms state-of-the-art feed-forward neural networks. We hope that PHASE can serve as a difficult new challenge for developing new models that can recognize complex social interactions.