 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning and Inference in Sparse Coding Models with Langevin Dynamics
Apr 23, 2022
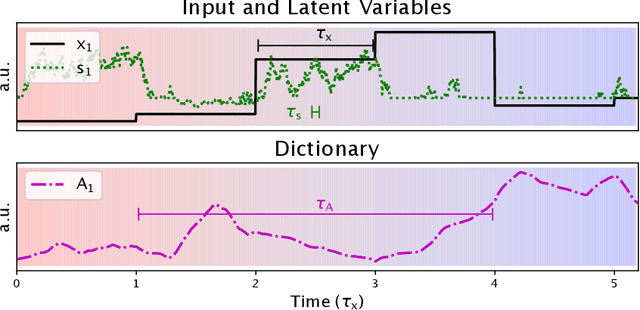
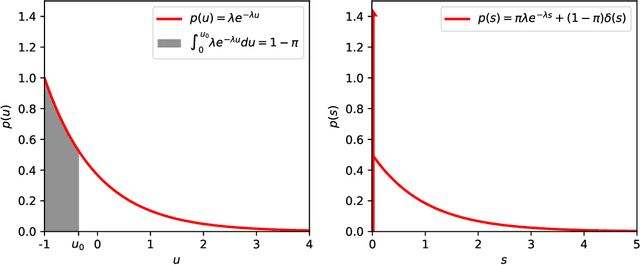

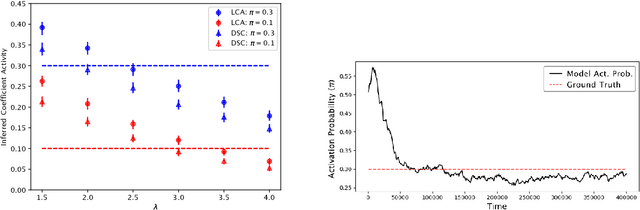
We describe a stochastic, dynamical system capable of inference and learning in a probabilistic latent variable model. The most challenging problem in such models - sampling the posterior distribution over latent variables - is proposed to be solved by harnessing natural sources of stochasticity inherent in electronic and neural systems. We demonstrate this idea for a sparse coding model by deriving a continuous-time equation for inferring its latent variables via Langevin dynamics. The model parameters are learned by simultaneously evolving according to another continuous-time equation, thus bypassing the need for digital accumulators or a global clock. Moreover we show that Langevin dynamics lead to an efficient procedure for sampling from the posterior distribution in the 'L0 sparse' regime, where latent variables are encouraged to be set to zero as opposed to having a small L1 norm. This allows the model to properly incorporate the notion of sparsity rather than having to resort to a relaxed version of sparsity to make optimization tractable. Simulations of the proposed dynamical system on both synthetic and natural image datasets demonstrate that the model is capable of probabilistically correct inference, enabling learning of the dictionary as well as parameters of the prior.
Retrieval Augmented Classification for Long-Tail Visual Recognition
Feb 22, 2022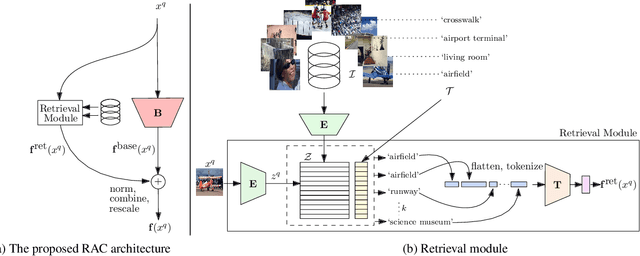
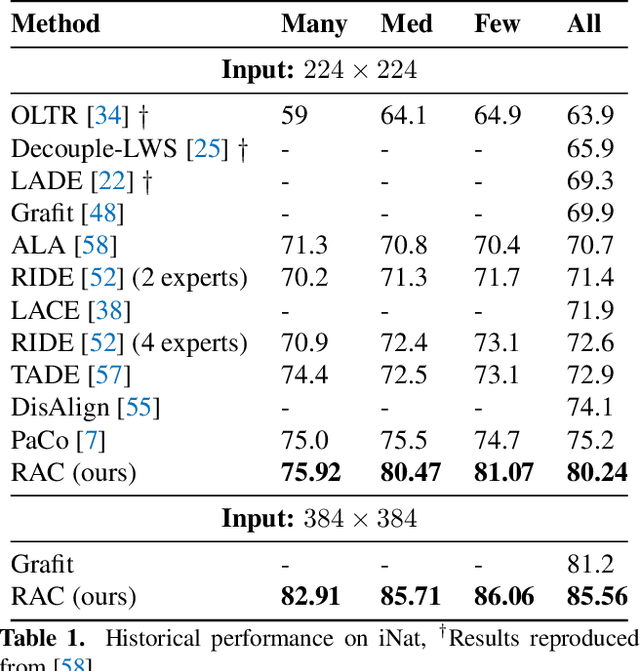
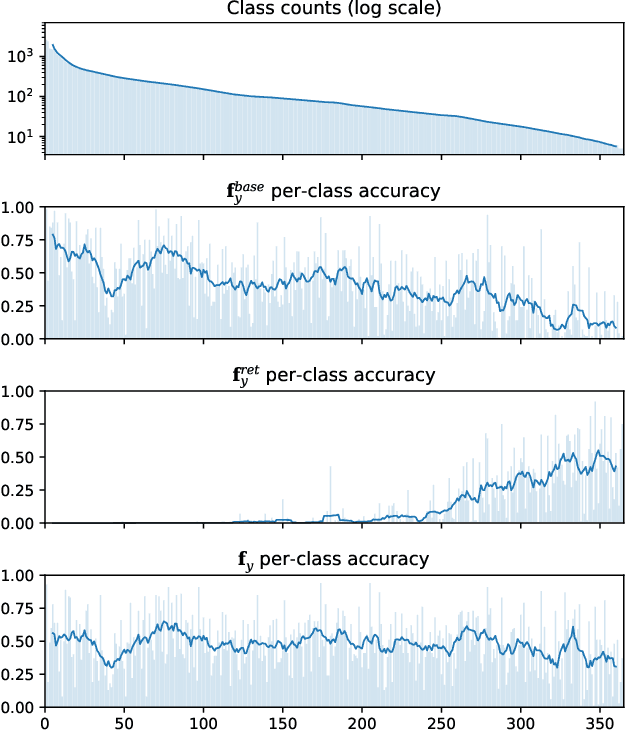
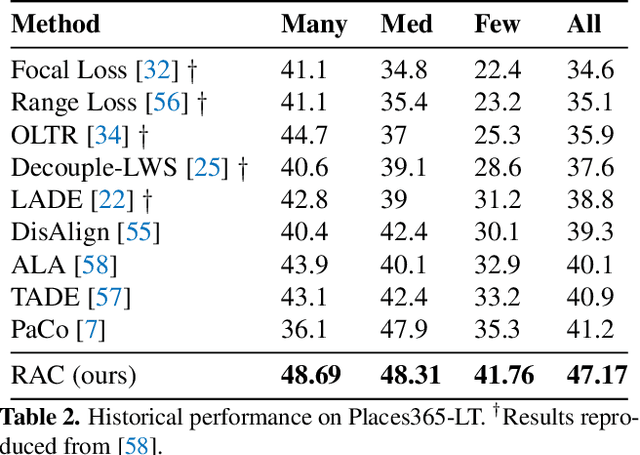
We introduce Retrieval Augmented Classification (RAC), a generic approach to augmenting standard image classification pipelines with an explicit retrieval module. RAC consists of a standard base image encoder fused with a parallel retrieval branch that queries a non-parametric external memory of pre-encoded images and associated text snippets. We apply RAC to the problem of long-tail classification and demonstrate a significant improvement over previous state-of-the-art on Places365-LT and iNaturalist-2018 (14.5% and 6.7% respectively), despite using only the training datasets themselves as the external information source. We demonstrate that RAC's retrieval module, without prompting, learns a high level of accuracy on tail classes. This, in turn, frees the base encoder to focus on common classes, and improve its performance thereon. RAC represents an alternative approach to utilizing large, pretrained models without requiring fine-tuning, as well as a first step towards more effectively making use of external memory within common computer vision architectures.
Context-Aware Layout to Image Generation with Enhanced Object Appearance
Mar 22, 2021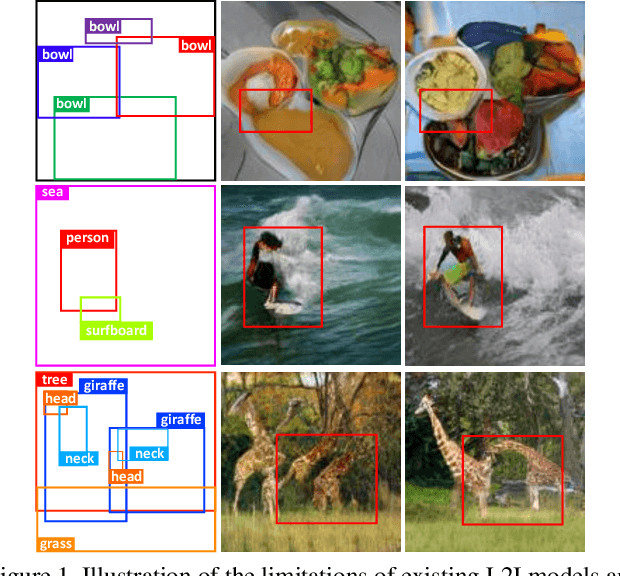
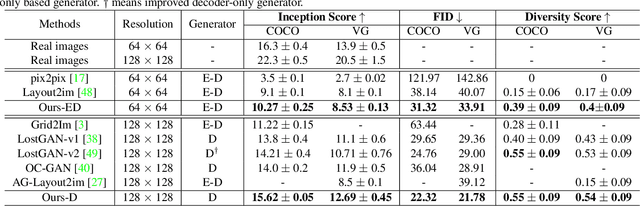
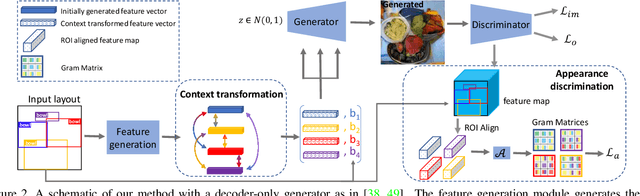

A layout to image (L2I) generation model aims to generate a complicated image containing multiple objects (things) against natural background (stuff), conditioned on a given layout. Built upon the recent advances in generative adversarial networks (GANs), existing L2I models have made great progress. However, a close inspection of their generated images reveals two major limitations: (1) the object-to-object as well as object-to-stuff relations are often broken and (2) each object's appearance is typically distorted lacking the key defining characteristics associated with the object class. We argue that these are caused by the lack of context-aware object and stuff feature encoding in their generators, and location-sensitive appearance representation in their discriminators. To address these limitations, two new modules are proposed in this work. First, a context-aware feature transformation module is introduced in the generator to ensure that the generated feature encoding of either object or stuff is aware of other co-existing objects/stuff in the scene. Second, instead of feeding location-insensitive image features to the discriminator, we use the Gram matrix computed from the feature maps of the generated object images to preserve location-sensitive information, resulting in much enhanced object appearance. Extensive experiments show that the proposed method achieves state-of-the-art performance on the COCO-Thing-Stuff and Visual Genome benchmarks.
Deep morphological recognition of kidney stones using intra-operative endoscopic digital videos
May 12, 2022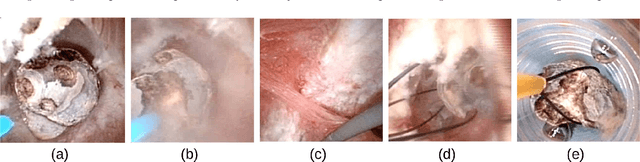

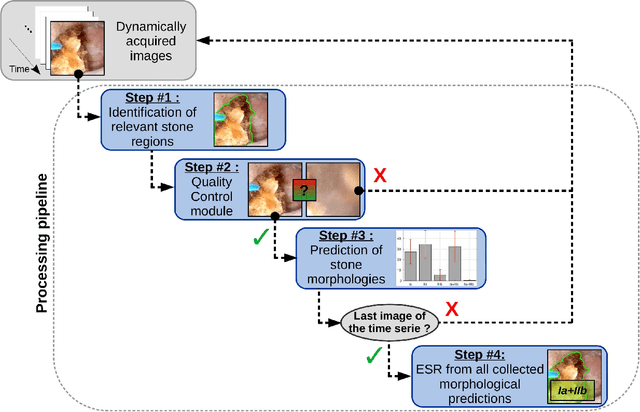
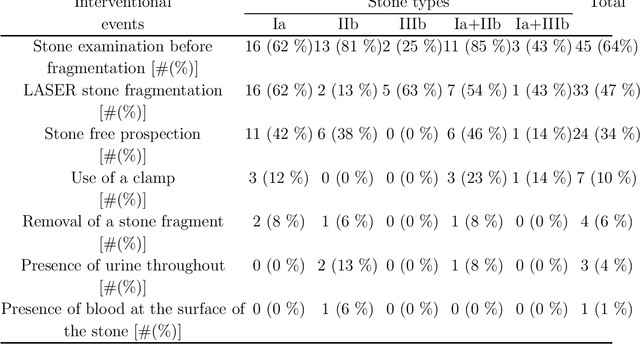
The collection and the analysis of kidney stone morphological criteria are essential for an aetiological diagnosis of stone disease. However, in-situ LASER-based fragmentation of urinary stones, which is now the most established chirurgical intervention, may destroy the morphology of the targeted stone. In the current study, we assess the performance and added value of processing complete digital endoscopic video sequences for the automatic recognition of stone morphological features during a standard-of-care intra-operative session. To this end, a computer-aided video classifier was developed to predict in-situ the morphology of stone using an intra-operative digital endoscopic video acquired in a clinical setting. The proposed technique was evaluated on pure (i.e. include one morphology) and mixed (i.e. include at least two morphologies) stones involving "Ia/Calcium Oxalate Monohydrate (COM)", "IIb/ Calcium Oxalate Dihydrate (COD)" and "IIIb/Uric Acid (UA)" morphologies. 71 digital endoscopic videos (50 exhibited only one morphological type and 21 displayed two) were analyzed using the proposed video classifier (56840 frames processed in total). Using the proposed approach, diagnostic performances (averaged over both pure and mixed stone types) were as follows: balanced accuracy=88%, sensitivity=80%, specificity=95%, precision=78% and F1-score=78%. The obtained results demonstrate that AI applied on digital endoscopic video sequences is a promising tool for collecting morphological information during the time-course of the stone fragmentation process without resorting to any human intervention for stone delineation or selection of good quality steady frames. To this end, irrelevant image information must be removed from the prediction process at both frame and pixel levels, which is now feasible thanks to the use of AI-dedicated networks.
HyperTransformer: A Textural and Spectral Feature Fusion Transformer for Pansharpening
Mar 09, 2022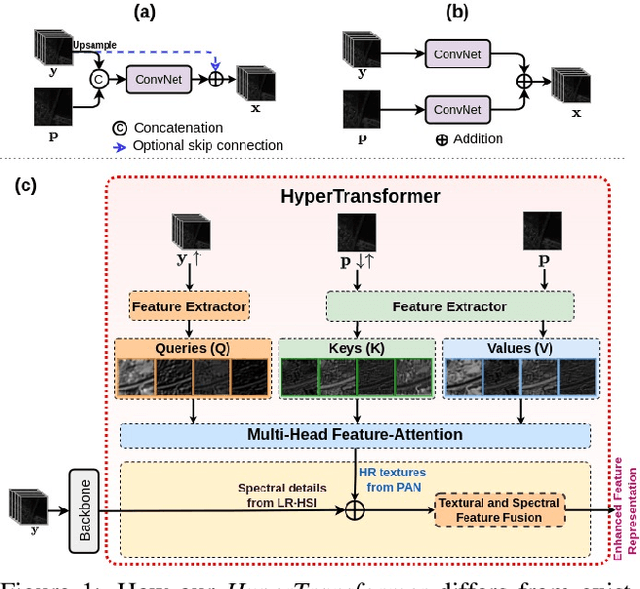
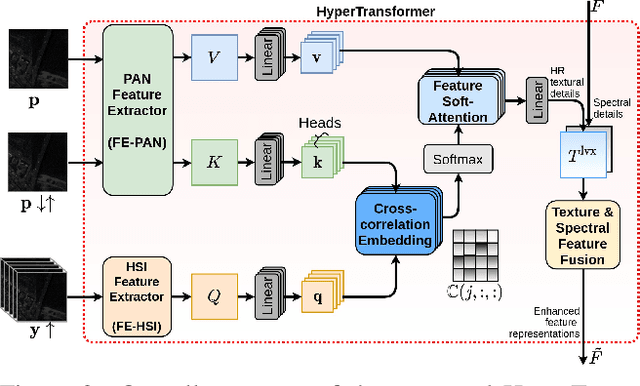
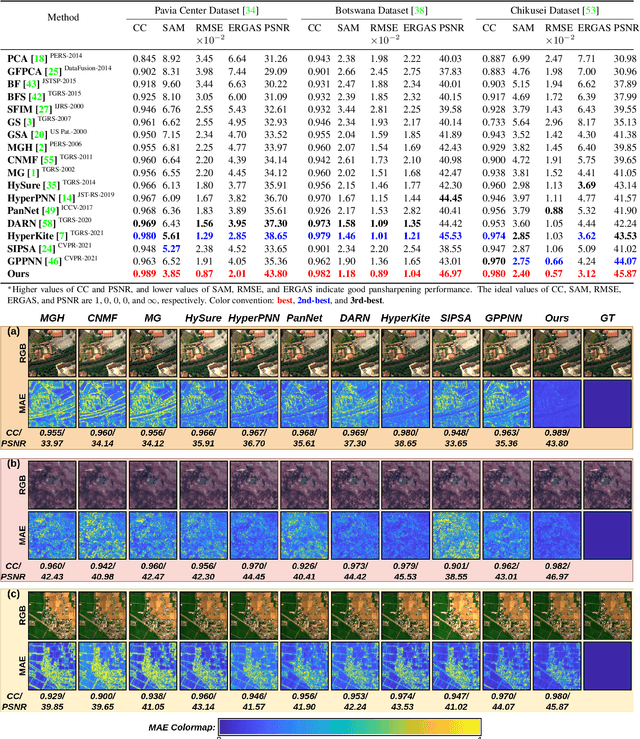
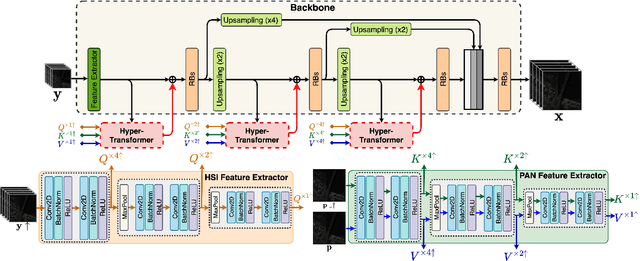
Pansharpening aims to fuse a registered high-resolution panchromatic image (PAN) with a low-resolution hyperspectral image (LR-HSI) to generate an enhanced HSI with high spectral and spatial resolution. Existing pansharpening approaches neglect using an attention mechanism to transfer HR texture features from PAN to LR-HSI features, resulting in spatial and spectral distortions. In this paper, we present a novel attention mechanism for pansharpening called HyperTransformer, in which features of LR-HSI and PAN are formulated as queries and keys in a transformer, respectively. HyperTransformer consists of three main modules, namely two separate feature extractors for PAN and HSI, a multi-head feature soft attention module, and a spatial-spectral feature fusion module. Such a network improves both spatial and spectral quality measures of the pansharpened HSI by learning cross-feature space dependencies and long-range details of PAN and LR-HSI. Furthermore, HyperTransformer can be utilized across multiple spatial scales at the backbone for obtaining improved performance. Extensive experiments conducted on three widely used datasets demonstrate that HyperTransformer achieves significant improvement over the state-of-the-art methods on both spatial and spectral quality measures. Implementation code and pre-trained weights can be accessed at https://github.com/wgcban/HyperTransformer.
Deep Iteration Assisted by Multi-level Obey-pixel Network Discriminator (DIAMOND) for Medical Image Recovery
Feb 08, 2021Image restoration is a typical ill-posed problem, and it contains various tasks. In the medical imaging field, an ill-posed image interrupts diagnosis and even following image processing. Both traditional iterative and up-to-date deep networks have attracted much attention and obtained a significant improvement in reconstructing satisfying images. This study combines their advantages into one unified mathematical model and proposes a general image restoration strategy to deal with such problems. This strategy consists of two modules. First, a novel generative adversarial net(GAN) with WGAN-GP training is built to recover image structures and subtle details. Then, a deep iteration module promotes image quality with a combination of pre-trained deep networks and compressed sensing algorithms by ADMM optimization. (D)eep (I)teration module suppresses image artifacts and further recovers subtle image details, (A)ssisted by (M)ulti-level (O)bey-pixel feature extraction networks (D)iscriminator to recover general structures. Therefore, the proposed strategy is named DIAMOND.
Can Foundation Models Perform Zero-Shot Task Specification For Robot Manipulation?
Apr 23, 2022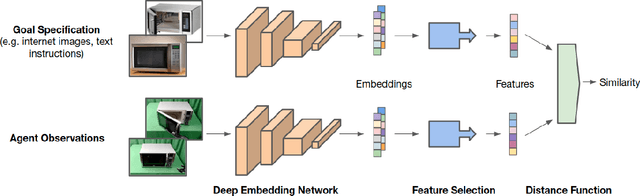
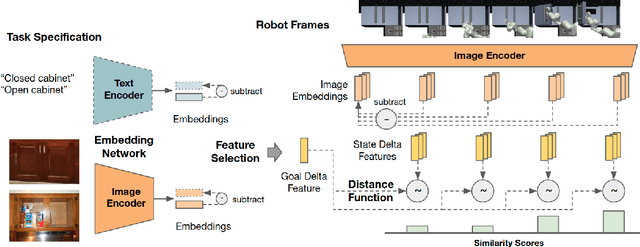
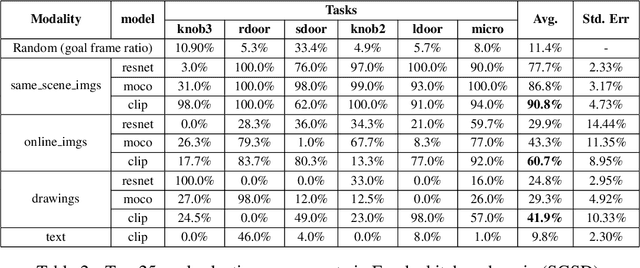

Task specification is at the core of programming autonomous robots. A low-effort modality for task specification is critical for engagement of non-expert end-users and ultimate adoption of personalized robot agents. A widely studied approach to task specification is through goals, using either compact state vectors or goal images from the same robot scene. The former is hard to interpret for non-experts and necessitates detailed state estimation and scene understanding. The latter requires the generation of desired goal image, which often requires a human to complete the task, defeating the purpose of having autonomous robots. In this work, we explore alternate and more general forms of goal specification that are expected to be easier for humans to specify and use such as images obtained from the internet, hand sketches that provide a visual description of the desired task, or simple language descriptions. As a preliminary step towards this, we investigate the capabilities of large scale pre-trained models (foundation models) for zero-shot goal specification, and find promising results in a collection of simulated robot manipulation tasks and real-world datasets.
AFINet: Attentive Feature Integration Networks for Image Classification
May 10, 2021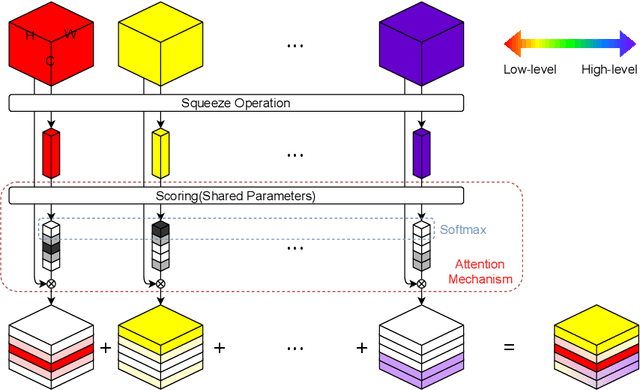
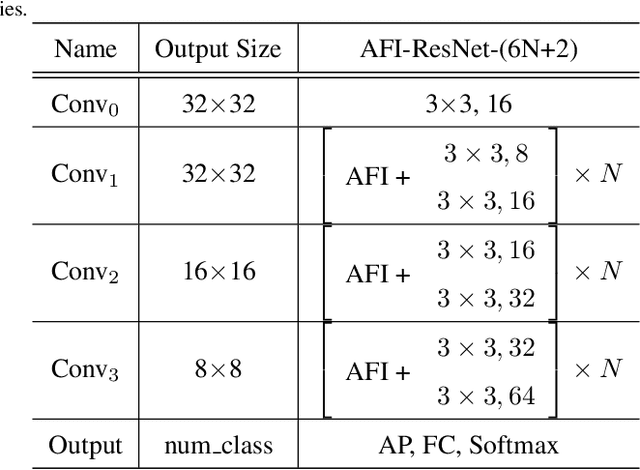

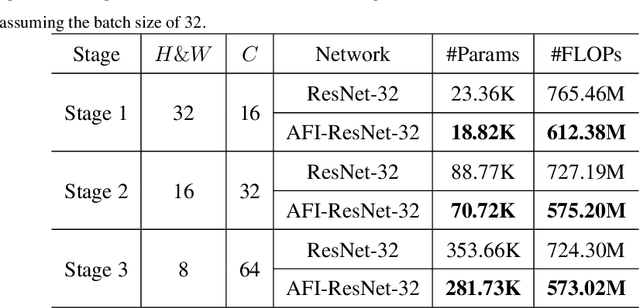
Convolutional Neural Networks (CNNs) have achieved tremendous success in a number of learning tasks including image classification. Recent advanced models in CNNs, such as ResNets, mainly focus on the skip connection to avoid gradient vanishing. DenseNet designs suggest creating additional bypasses to transfer features as an alternative strategy in network design. In this paper, we design Attentive Feature Integration (AFI) modules, which are widely applicable to most recent network architectures, leading to new architectures named AFI-Nets. AFI-Nets explicitly model the correlations among different levels of features and selectively transfer features with a little overhead.AFI-ResNet-152 obtains a 1.24% relative improvement on the ImageNet dataset while decreases the FLOPs by about 10% and the number of parameters by about 9.2% compared to ResNet-152.
A Novel Framework for Assessment of Learning-based Detectors in Realistic Conditions with Application to Deepfake Detection
Mar 22, 2022

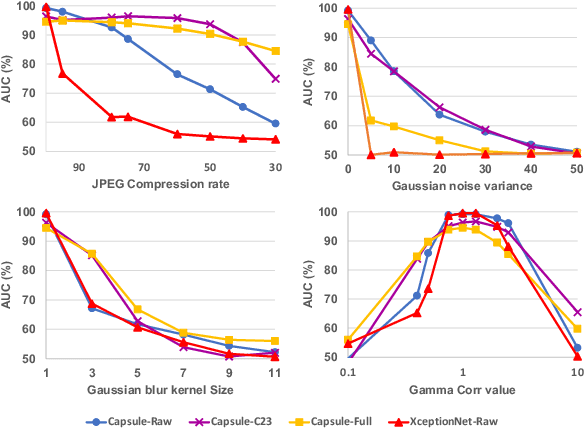
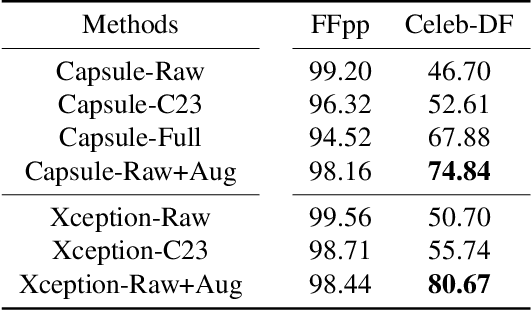
Deep convolutional neural networks have shown remarkable results on multiple detection tasks. Despite the significant progress, the performance of such detectors are often assessed in public benchmarks under non-realistic conditions. Specifically, impact of conventional distortions and processing operations such as compression, noise, and enhancement are not sufficiently studied. This paper proposes a rigorous framework to assess performance of learning-based detectors in more realistic situations. An illustrative example is shown under deepfake detection context. Inspired by the assessment results, a data augmentation strategy based on natural image degradation process is designed, which significantly improves the generalization ability of two deepfake detectors.
Masked Co-attentional Transformer reconstructs 100x ultra-fast/low-dose whole-body PET from longitudinal images and anatomically guided MRI
May 09, 2022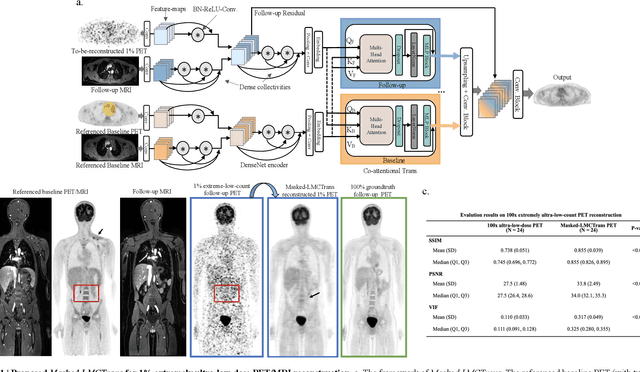
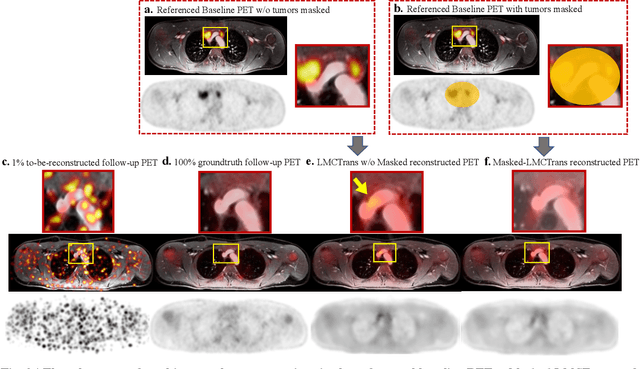
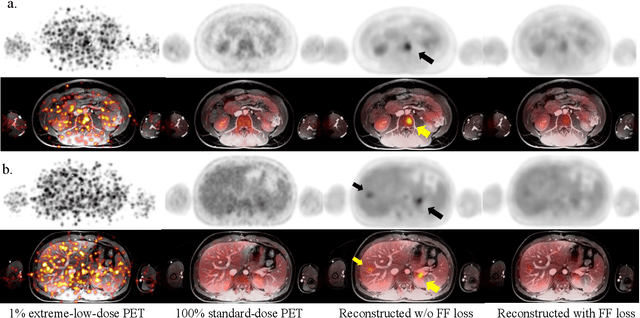
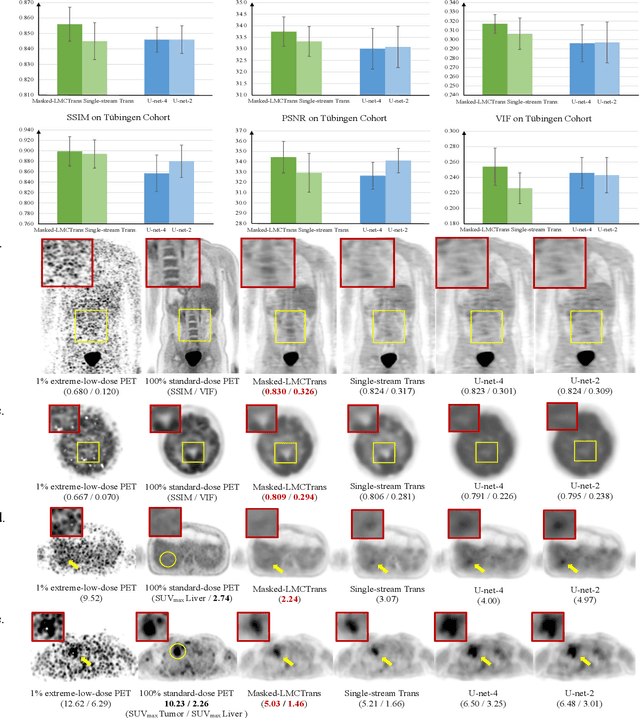
Despite its tremendous value for the diagnosis, treatment monitoring and surveillance of children with cancer, whole body staging with positron emission tomography (PET) is time consuming and associated with considerable radiation exposure. 100x (1% of the standard clinical dosage) ultra-low-dose/ultra-fast whole-body PET reconstruction has the potential for cancer imaging with unprecedented speed and improved safety, but it cannot be achieved by the naive use of machine learning techniques. In this study, we utilize the global similarity between baseline and follow-up PET and magnetic resonance (MR) images to develop Masked-LMCTrans, a longitudinal multi-modality co-attentional CNN-Transformer that provides interaction and joint reasoning between serial PET/MRs of the same patient. We mask the tumor area in the referenced baseline PET and reconstruct the follow-up PET scans. In this manner, Masked-LMCTrans reconstructs 100x almost-zero radio-exposure whole-body PET that was not possible before. The technique also opens a new pathway for longitudinal radiology imaging reconstruction, a significantly under-explored area to date. Our model was trained and tested with Stanford PET/MRI scans of pediatric lymphoma patients and evaluated externally on PET/MRI images from T\"ubingen University. The high image quality of the reconstructed 100x whole-body PET images resulting from the application of Masked-LMCTrans will substantially advance the development of safer imaging approaches and shorter exam-durations for pediatric patients, as well as expand the possibilities for frequent longitudinal monitoring of these patients by PET.