 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Continual Learning with Bayesian Model based on a Fixed Pre-trained Feature Extractor
Apr 28, 2022
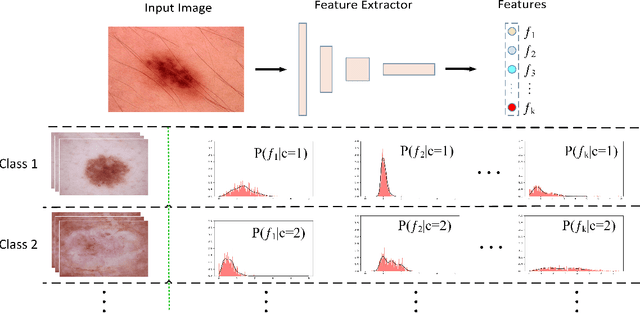
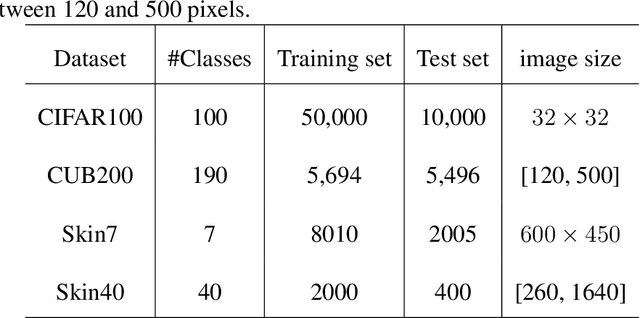
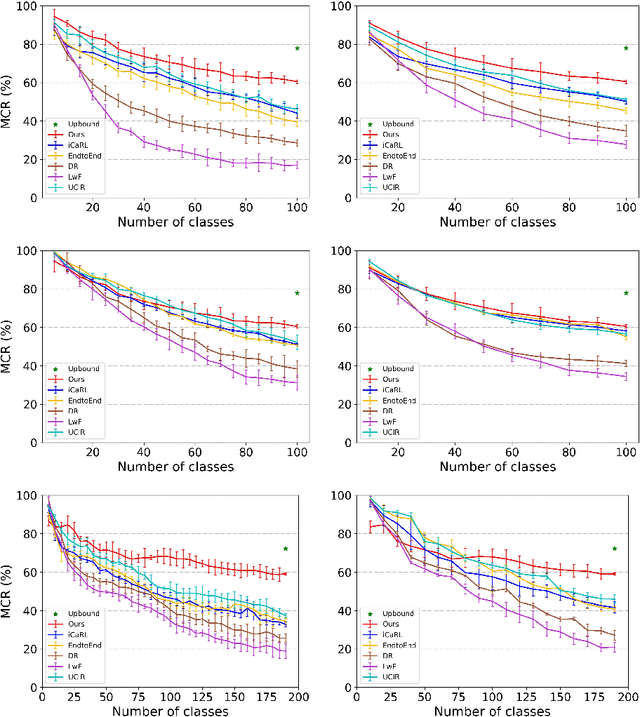
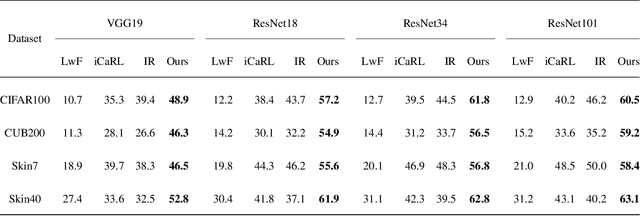
Deep learning has shown its human-level performance in various applications. However, current deep learning models are characterised by catastrophic forgetting of old knowledge when learning new classes. This poses a challenge particularly in intelligent diagnosis systems where initially only training data of a limited number of diseases are available. In this case, updating the intelligent system with data of new diseases would inevitably downgrade its performance on previously learned diseases. Inspired by the process of learning new knowledge in human brains, we propose a Bayesian generative model for continual learning built on a fixed pre-trained feature extractor. In this model, knowledge of each old class can be compactly represented by a collection of statistical distributions, e.g. with Gaussian mixture models, and naturally kept from forgetting in continual learning over time. Unlike existing class-incremental learning methods, the proposed approach is not sensitive to the continual learning process and can be additionally well applied to the data-incremental learning scenario. Experiments on multiple medical and natural image classification tasks showed that the proposed approach outperforms state-of-the-art approaches which even keep some images of old classes during continual learning of new classes.
General Multi-label Image Classification with Transformers
Nov 27, 2020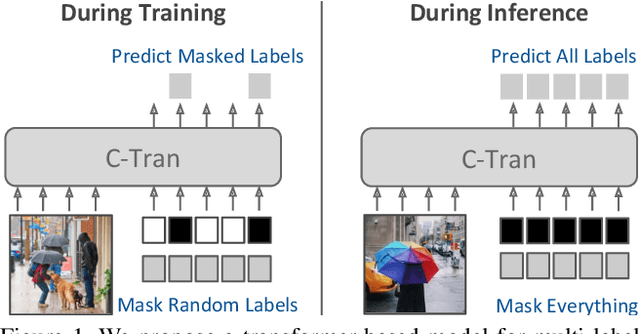
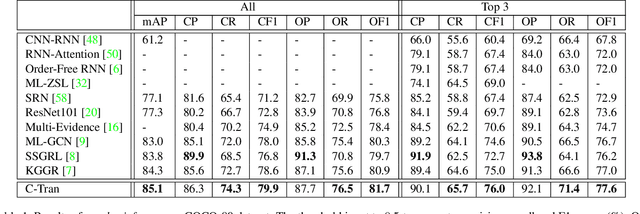


Multi-label image classification is the task of predicting a set of labels corresponding to objects, attributes or other entities present in an image. In this work we propose the Classification Transformer (C-Tran), a general framework for multi-label image classification that leverages Transformers to exploit the complex dependencies among visual features and labels. Our approach consists of a Transformer encoder trained to predict a set of target labels given an input set of masked labels, and visual features from a convolutional neural network. A key ingredient of our method is a label mask training objective that uses a ternary encoding scheme to represent the state of the labels as positive, negative, or unknown during training. Our model shows state-of-the-art performance on challenging datasets such as COCO and Visual Genome. Moreover, because our model explicitly represents the uncertainty of labels during training, it is more general by allowing us to produce improved results for images with partial or extra label annotations during inference. We demonstrate this additional capability in the COCO, Visual Genome, News500, and CUB image datasets.
Beam-Shape Effects and Noise Removal from THz Time-Domain Images in Reflection Geometry in the 0.25-6 THz Range
Mar 01, 2022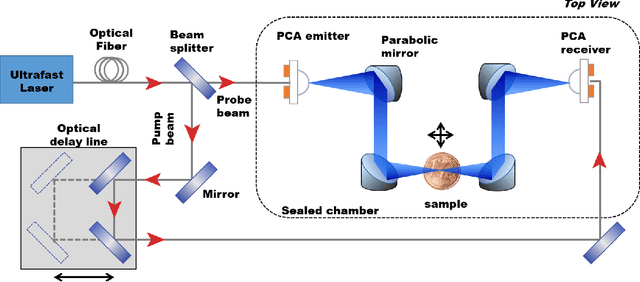


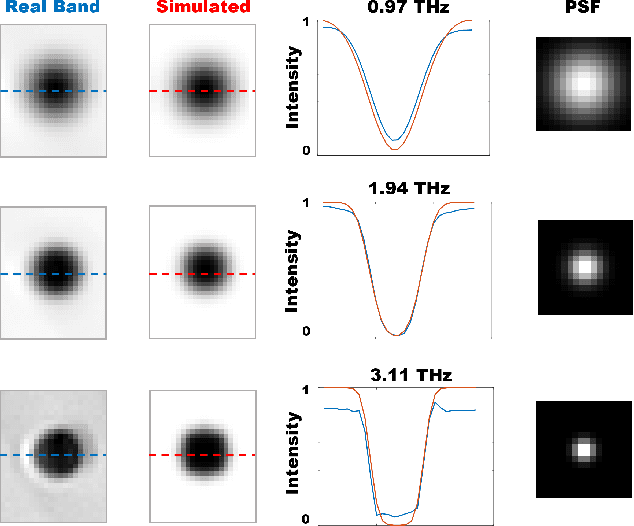
The increasing need of restoring high-resolution Hyper-Spectral (HS) images is determining a growing reliance on Computer Vision-based processing to enhance the clarity of the image content. HS images can, in fact, suffer from degradation effects or artefacts caused by instrument limitations. This paper focuses on a procedure aimed at reducing the degradation effects, frequency-dependent blur and noise, in Terahertz Time-Domain Spectroscopy (THz-TDS) images in reflection geometry. It describes the application of a joint deblurring and denoising approach that had been previously proved to be effective for the restoration of THz-TDS images in transmission geometry, but that had never been tested in reflection modality. This mode is often the only one that can be effectively used in most cases, for example when analyzing objects that are either opaque in the THz range, or that cannot be displaced from their location (e.g., museums), such as those of cultural interest. Compared to transmission mode, reflection geometry introduces, however, further distortion to THz data, neglected in existing literature. In this work, we successfully implement image deblurring and denoising of both uniform-shape samples (a contemporary 1 Euro cent coin and an inlaid pendant) and samples with the uneven reliefs and corrosion products on the surface which make the analysis of the object particularly complex (an ancient Roman silver coin). The study demonstrates the ability of image processing to restore data in the 0.25 - 6 THz range, spanning over more than four octaves, and providing the foundation for future analytical approaches of cultural heritage using the far-infrared spectrum still not sufficiently investigated in literature.
BSRT: Improving Burst Super-Resolution with Swin Transformer and Flow-Guided Deformable Alignment
Apr 18, 2022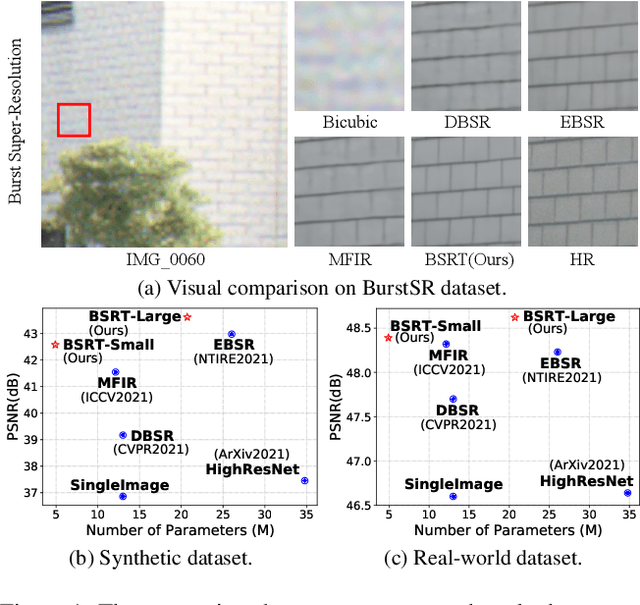
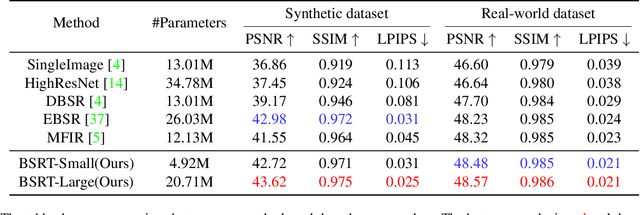
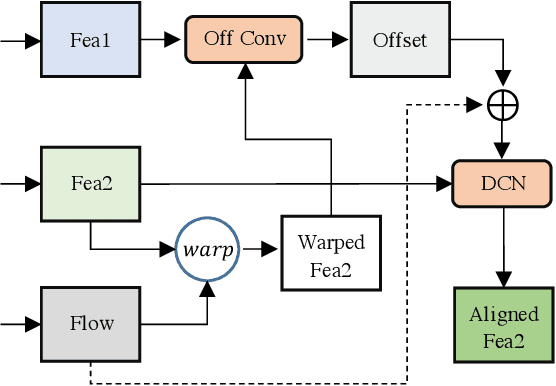
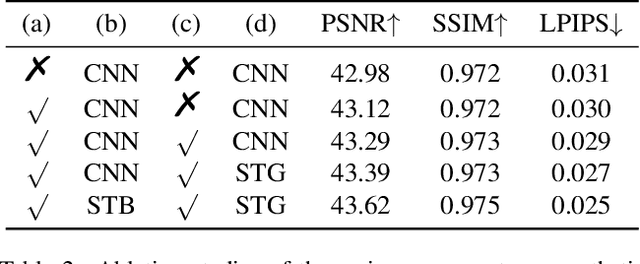
This work addresses the Burst Super-Resolution (BurstSR) task using a new architecture, which requires restoring a high-quality image from a sequence of noisy, misaligned, and low-resolution RAW bursts. To overcome the challenges in BurstSR, we propose a Burst Super-Resolution Transformer (BSRT), which can significantly improve the capability of extracting inter-frame information and reconstruction. To achieve this goal, we propose a Pyramid Flow-Guided Deformable Convolution Network (Pyramid FG-DCN) and incorporate Swin Transformer Blocks and Groups as our main backbone. More specifically, we combine optical flows and deformable convolutions, hence our BSRT can handle misalignment and aggregate the potential texture information in multi-frames more efficiently. In addition, our Transformer-based structure can capture long-range dependency to further improve the performance. The evaluation on both synthetic and real-world tracks demonstrates that our approach achieves a new state-of-the-art in BurstSR task. Further, our BSRT wins the championship in the NTIRE2022 Burst Super-Resolution Challenge.
DRBM-ClustNet: A Deep Restricted Boltzmann-Kohonen Architecture for Data Clustering
May 13, 2022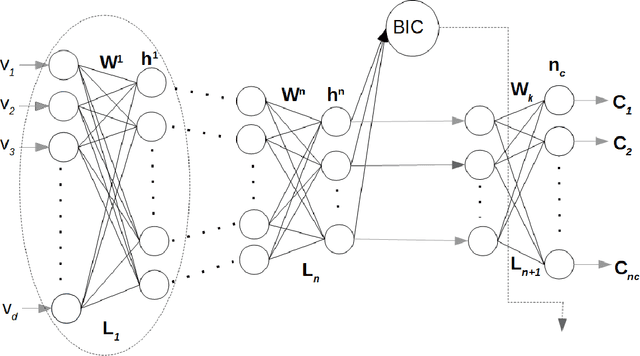
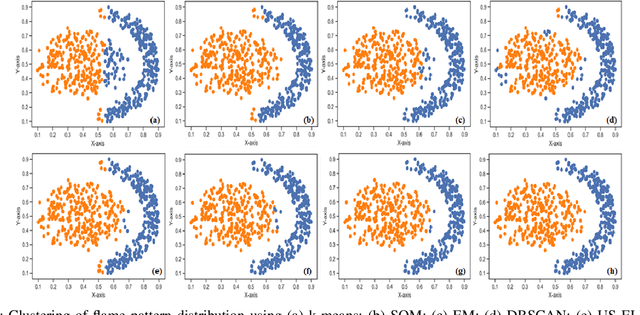
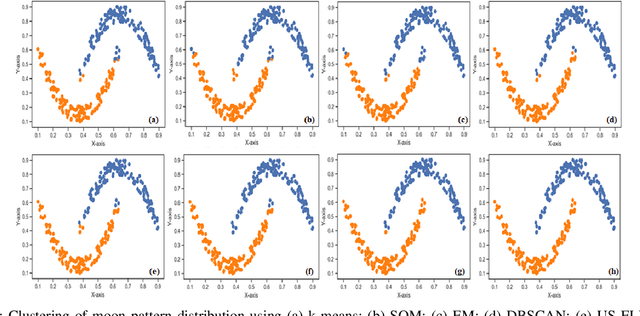
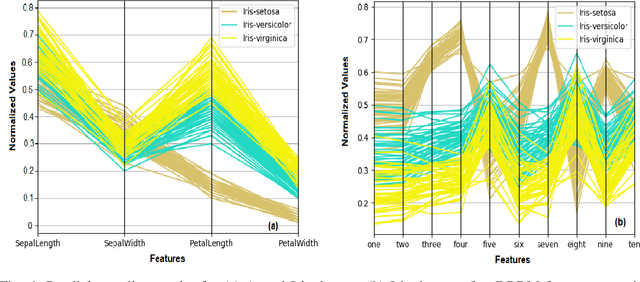
A Bayesian Deep Restricted Boltzmann-Kohonen architecture for data clustering termed as DRBM-ClustNet is proposed. This core-clustering engine consists of a Deep Restricted Boltzmann Machine (DRBM) for processing unlabeled data by creating new features that are uncorrelated and have large variance with each other. Next, the number of clusters are predicted using the Bayesian Information Criterion (BIC), followed by a Kohonen Network-based clustering layer. The processing of unlabeled data is done in three stages for efficient clustering of the non-linearly separable datasets. In the first stage, DRBM performs non-linear feature extraction by capturing the highly complex data representation by projecting the feature vectors of $d$ dimensions into $n$ dimensions. Most clustering algorithms require the number of clusters to be decided a priori, hence here to automate the number of clusters in the second stage we use BIC. In the third stage, the number of clusters derived from BIC forms the input for the Kohonen network, which performs clustering of the feature-extracted data obtained from the DRBM. This method overcomes the general disadvantages of clustering algorithms like the prior specification of the number of clusters, convergence to local optima and poor clustering accuracy on non-linear datasets. In this research we use two synthetic datasets, fifteen benchmark datasets from the UCI Machine Learning repository, and four image datasets to analyze the DRBM-ClustNet. The proposed framework is evaluated based on clustering accuracy and ranked against other state-of-the-art clustering methods. The obtained results demonstrate that the DRBM-ClustNet outperforms state-of-the-art clustering algorithms.
Tracking monocular camera pose and deformation for SLAM inside the human body
Apr 18, 2022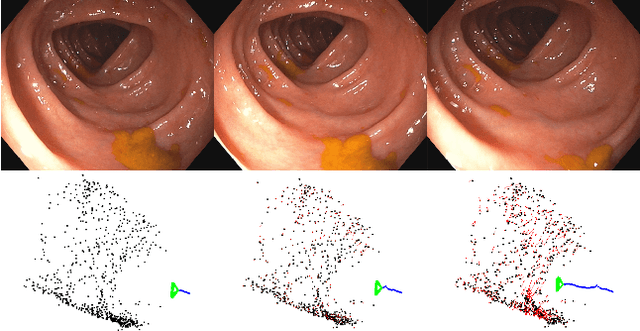
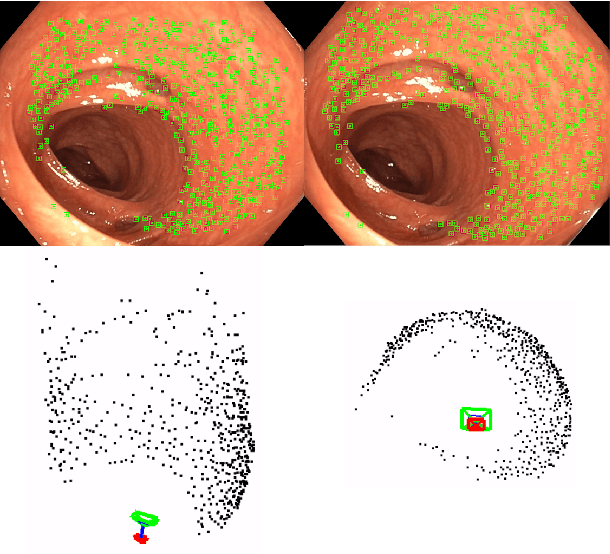
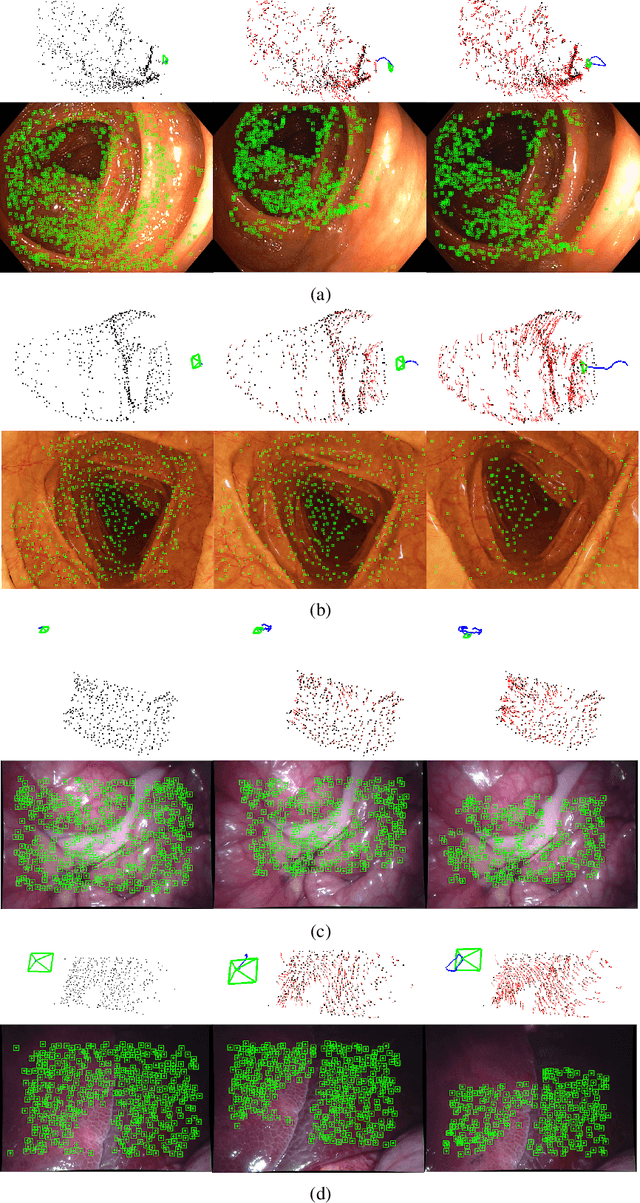
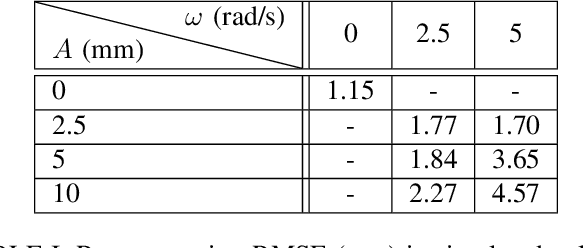
Monocular SLAM in deformable scenes will open the way to multiple medical applications like computer-assisted navigation in endoscopy, automatic drug delivery or autonomous robotic surgery. In this paper we propose a novel method to simultaneously track the camera pose and the 3D scene deformation, without any assumption about environment topology or shape. The method uses an illumination-invariant photometric method to track image features and estimates camera motion and deformation combining reprojection error with spatial and temporal regularization of deformations. Our results in simulated colonoscopies show the method's accuracy and robustness in complex scenes under increasing levels of deformation. Our qualitative results in human colonoscopies from Endomapper dataset show that the method is able to successfully cope with the challenges of real endoscopies: deformations, low texture and strong illumination changes. We also compare with previous tracking methods in simpler scenarios from Hamlyn dataset where we obtain competitive performance, without needing any topological assumption.
Dual-Task Mutual Learning for Semi-Supervised Medical Image Segmentation
Mar 08, 2021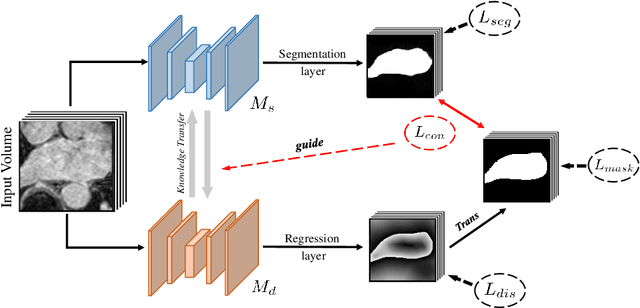
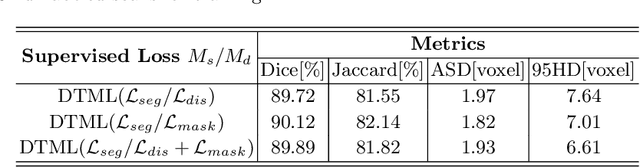
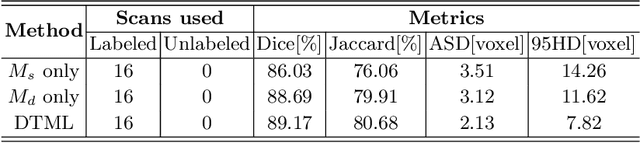
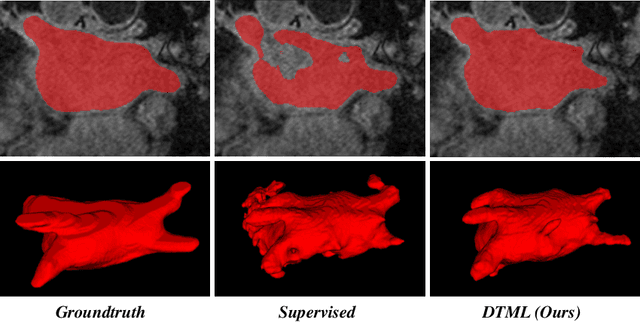
The success of deep learning methods in medical image segmentation tasks usually requires a large amount of labeled data. However, obtaining reliable annotations is expensive and time-consuming. Semi-supervised learning has attracted much attention in medical image segmentation by taking the advantage of unlabeled data which is much easier to acquire. In this paper, we propose a novel dual-task mutual learning framework for semi-supervised medical image segmentation. Our framework can be formulated as an integration of two individual segmentation networks based on two tasks: learning region-based shape constraint and learning boundary-based surface mismatch. Different from the one-way transfer between teacher and student networks, an ensemble of dual-task students can learn collaboratively and implicitly explore useful knowledge from each other during the training process. By jointly learning the segmentation probability maps and signed distance maps of targets, our framework can enforce the geometric shape constraint and learn more reliable information. Experimental results demonstrate that our method achieves performance gains by leveraging unlabeled data and outperforms the state-of-the-art semi-supervised segmentation methods.
Hybrid Diffractive Optics Design via Hardware-in-the-Loop Methodology for Achromatic Extended-Depth-of-Field Imaging
Mar 30, 2022
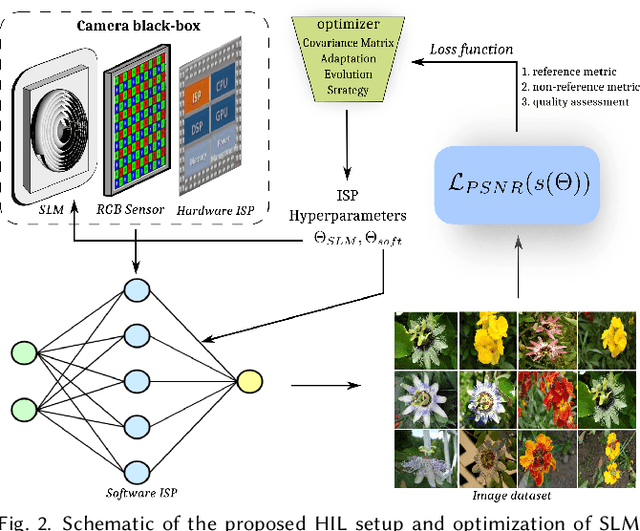
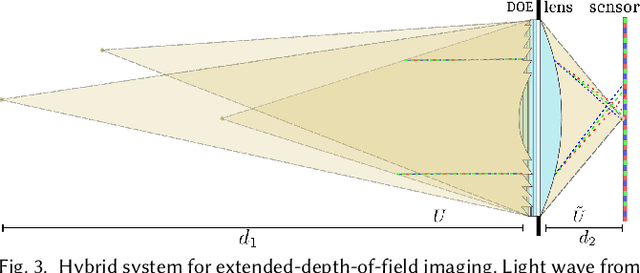
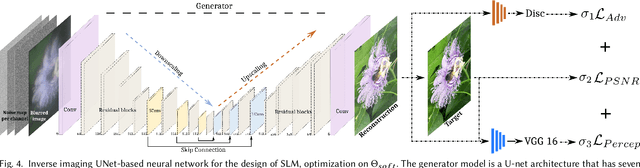
End-to-end optimization of diffractive optical elements (DOEs) profile through a digital differentiable model combined with computational imaging have gained an increasing attention in emerging applications due to the compactness of resultant physical setups. Despite recent works have shown the potential of this methodology to design optics, its performance in physical setups is still limited and affected by manufacturing artifacts of DOE, mismatch between simulated and resultant experimental point spread functions, and calibration errors. Additionally, the computational burden of the digital differentiable model to effectively design the DOE is increasing, thus limiting the size of the DOE that can be designed. To overcome the above mentioned limitations, the broadband imaging system with phase-only spatial light modulator (SLM) as an encoded DOE is proposed and developed in this paper. A co-design of the SLM phase pattern and image reconstruction algorithm is produced following the end-to-end strategy, using for optimization a convolutional neural network equipped with quantitative and qualitative loss functions. The optics of the imaging system is hybrid consisting of SLM as DOE and refractive lens. SLM phase-pattern is optimized by applying the Hardware-in-the-loop technique, which helps to eliminate the mismatch between numerical modeling and physical reality of image formation as light propagation is not numerically modeled but is physically done. In our experiments, the hybrid optics is implemented by the optical projection of the SLM phase-pattern on a lens plane for a depth range 0.4-1.9m. Comparison with compound multi-lens optics such as Sony A7 III and iPhone Xs Max cameras show that the proposed system is advanced in all-in-focus sharp imaging.
PSDoodle: Searching for App Screens via Interactive Sketching
Apr 06, 2022
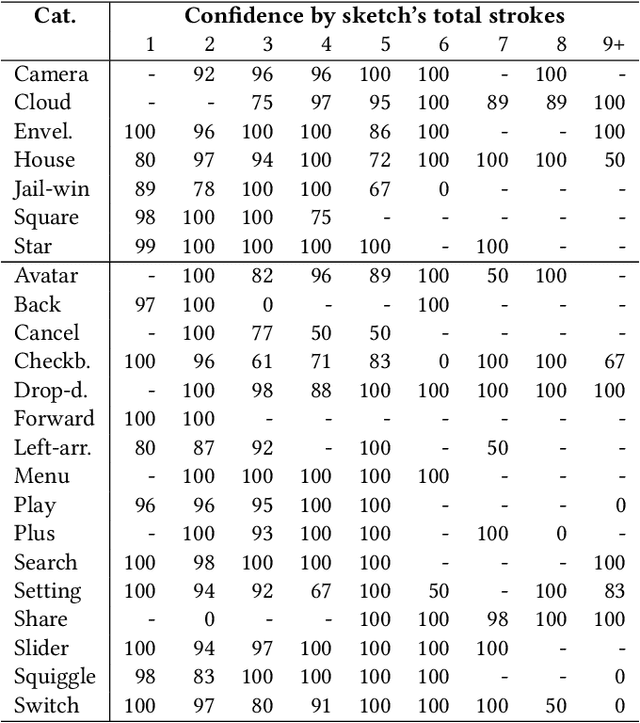
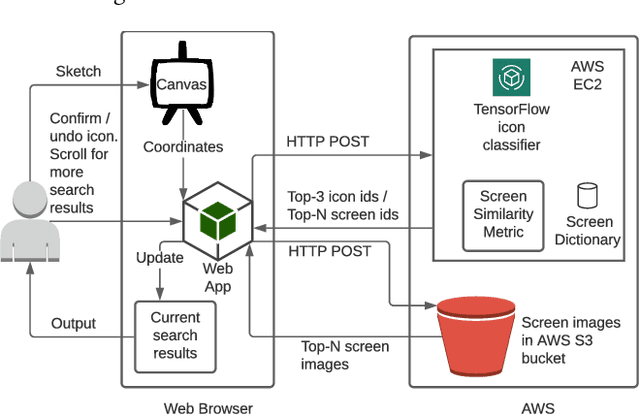
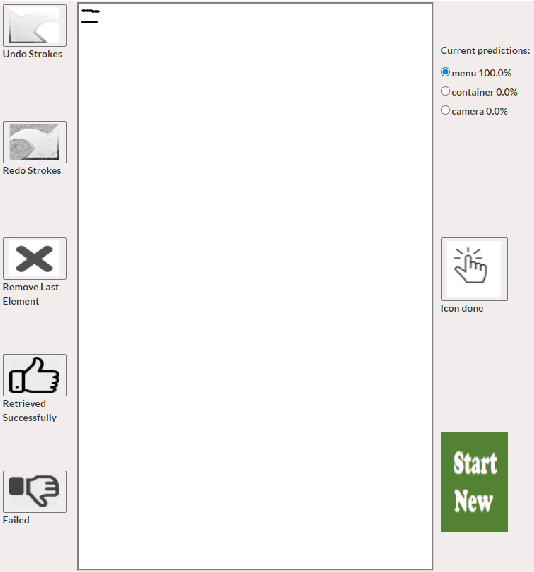
Keyword-based mobile screen search does not account for screen content and fails to operate as a universal tool for all levels of users. Visual searching (e.g., image, sketch) is structured and easy to adopt. Current visual search approaches count on a complete screen and are therefore slow and tedious. PSDoodle employs a deep neural network to recognize partial screen element drawings instantly on a digital drawing interface and shows results in real-time. PSDoodle is the first tool that utilizes partial sketches and searches for screens in an interactive iterative way. PSDoodle supports different drawing styles and retrieves search results that are relevant to the user's sketch query. A short video demonstration is available online at: https://youtu.be/3cVLHFm5pY4
Syfer: Neural Obfuscation for Private Data Release
Jan 28, 2022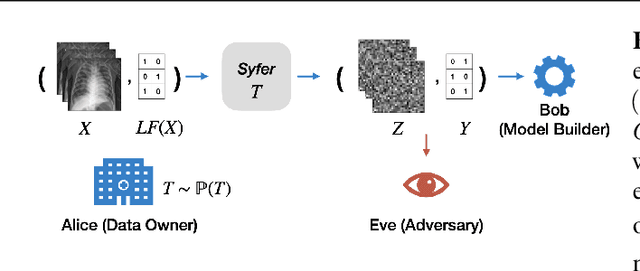
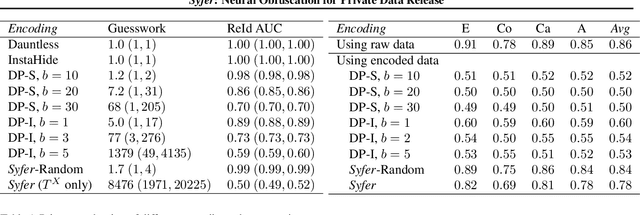
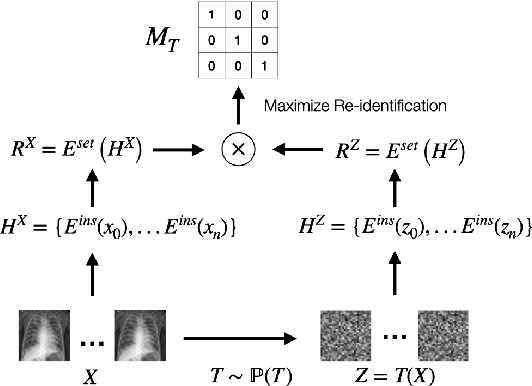

Balancing privacy and predictive utility remains a central challenge for machine learning in healthcare. In this paper, we develop Syfer, a neural obfuscation method to protect against re-identification attacks. Syfer composes trained layers with random neural networks to encode the original data (e.g. X-rays) while maintaining the ability to predict diagnoses from the encoded data. The randomness in the encoder acts as the private key for the data owner. We quantify privacy as the number of attacker guesses required to re-identify a single image (guesswork). We propose a contrastive learning algorithm to estimate guesswork. We show empirically that differentially private methods, such as DP-Image, obtain privacy at a significant loss of utility. In contrast, Syfer achieves strong privacy while preserving utility. For example, X-ray classifiers built with DP-image, Syfer, and original data achieve average AUCs of 0.53, 0.78, and 0.86, respectively.