 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecay Pruning Method: Smooth Pruning With a Self-Rectifying Procedure
Jun 06, 2024



Current structured pruning methods often result in considerable accuracy drops due to abrupt network changes and loss of information from pruned structures. To address these issues, we introduce the Decay Pruning Method (DPM), a novel smooth pruning approach with a self-rectifying mechanism. DPM consists of two key components: (i) Smooth Pruning: It converts conventional single-step pruning into multi-step smooth pruning, gradually reducing redundant structures to zero over N steps with ongoing optimization. (ii) Self-Rectifying: This procedure further enhances the aforementioned process by rectifying sub-optimal pruning based on gradient information. Our approach demonstrates strong generalizability and can be easily integrated with various existing pruning methods. We validate the effectiveness of DPM by integrating it with three popular pruning methods: OTOv2, Depgraph, and Gate Decorator. Experimental results show consistent improvements in performance compared to the original pruning methods, along with further reductions of FLOPs in most scenarios.
Continual Learning with Bayesian Model based on a Fixed Pre-trained Feature Extractor
Apr 28, 2022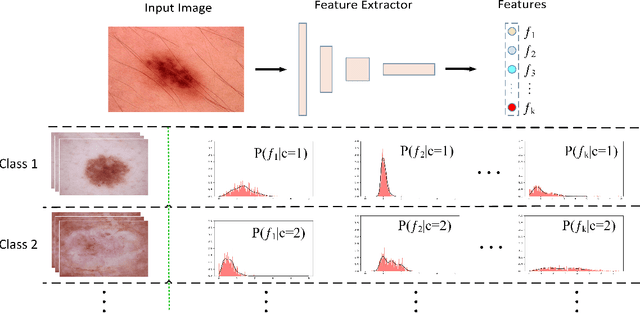
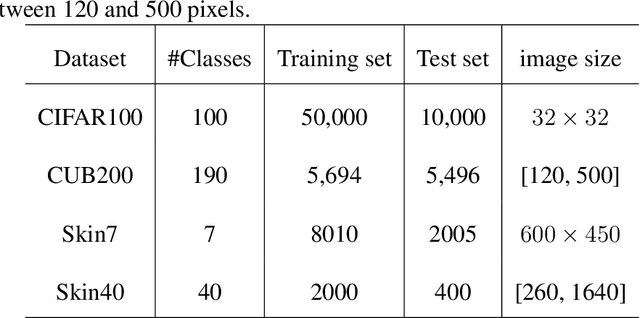
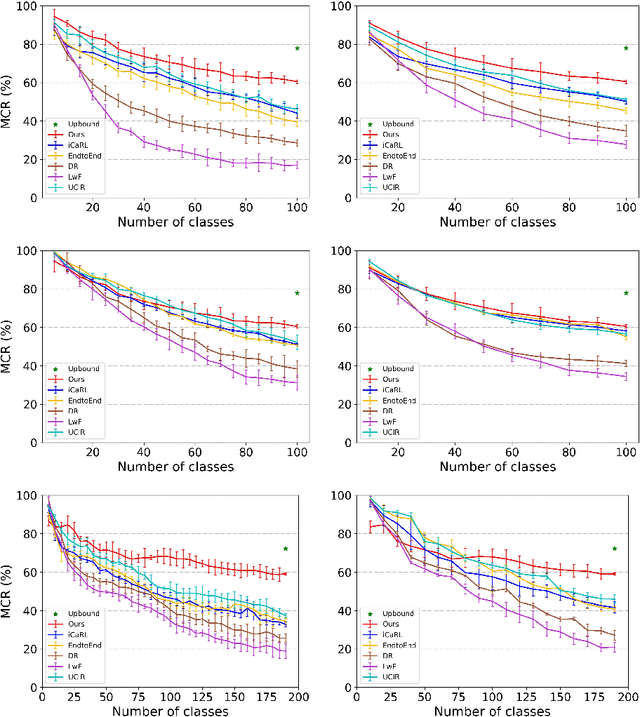
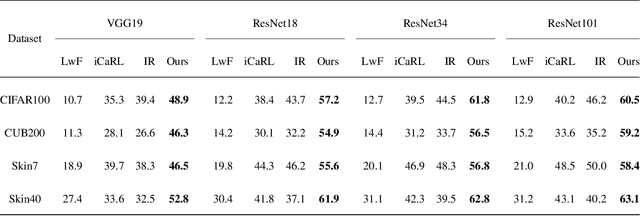
Deep learning has shown its human-level performance in various applications. However, current deep learning models are characterised by catastrophic forgetting of old knowledge when learning new classes. This poses a challenge particularly in intelligent diagnosis systems where initially only training data of a limited number of diseases are available. In this case, updating the intelligent system with data of new diseases would inevitably downgrade its performance on previously learned diseases. Inspired by the process of learning new knowledge in human brains, we propose a Bayesian generative model for continual learning built on a fixed pre-trained feature extractor. In this model, knowledge of each old class can be compactly represented by a collection of statistical distributions, e.g. with Gaussian mixture models, and naturally kept from forgetting in continual learning over time. Unlike existing class-incremental learning methods, the proposed approach is not sensitive to the continual learning process and can be additionally well applied to the data-incremental learning scenario. Experiments on multiple medical and natural image classification tasks showed that the proposed approach outperforms state-of-the-art approaches which even keep some images of old classes during continual learning of new classes.
Discriminative Distillation to Reduce Class Confusion in Continual Learning
Aug 11, 2021
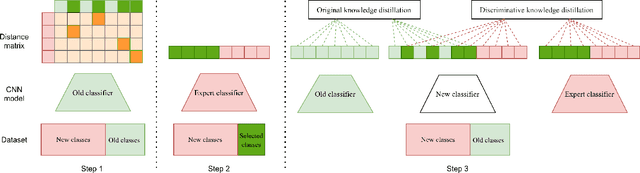
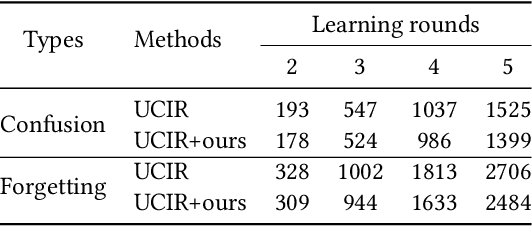
Successful continual learning of new knowledge would enable intelligent systems to recognize more and more classes of objects. However, current intelligent systems often fail to correctly recognize previously learned classes of objects when updated to learn new classes. It is widely believed that such downgraded performance is solely due to the catastrophic forgetting of previously learned knowledge. In this study, we argue that the class confusion phenomena may also play a role in downgrading the classification performance during continual learning, i.e., the high similarity between new classes and any previously learned classes would also cause the classifier to make mistakes in recognizing these old classes, even if the knowledge of these old classes is not forgotten. To alleviate the class confusion issue, we propose a discriminative distillation strategy to help the classify well learn the discriminative features between confusing classes during continual learning. Experiments on multiple natural image classification tasks support that the proposed distillation strategy, when combined with existing methods, is effective in further improving continual learning.