 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching Mobile App Screens via Text + Doodle
May 12, 2023Locating a specific mobile application screen from existing repositories is restricted to basic keyword searches, such as Google Image Search, or necessitates a complete query screen image, as in the case of Swire. However, interactive partial sketch-based solutions like PSDoodle have limitations, including inaccuracy and an inability to consider text appearing on the screen. A potentially effective solution involves implementing a system that provides interactive partial sketching functionality for efficiently structuring user interface elements. Additionally, the system should incorporate text queries to enhance its capabilities further. Our approach, TpD, represents the pioneering effort to enable an iterative search of screens by combining interactive sketching and keyword search techniques. TpD is built on a combination of the Rico repository of approximately 58k Android app screens and the PSDoodle. Our evaluation with third-party software developers showed that PSDoodle provided higher top-10 screen retrieval accuracy than state-of-the-art Swire and required less time to complete a query than other interactive solutions.
PSDoodle: Searching for App Screens via Interactive Sketching
Apr 06, 2022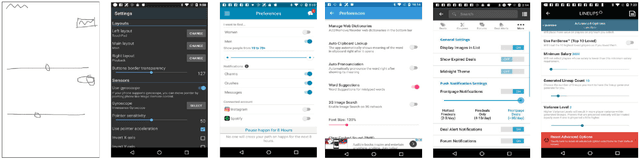
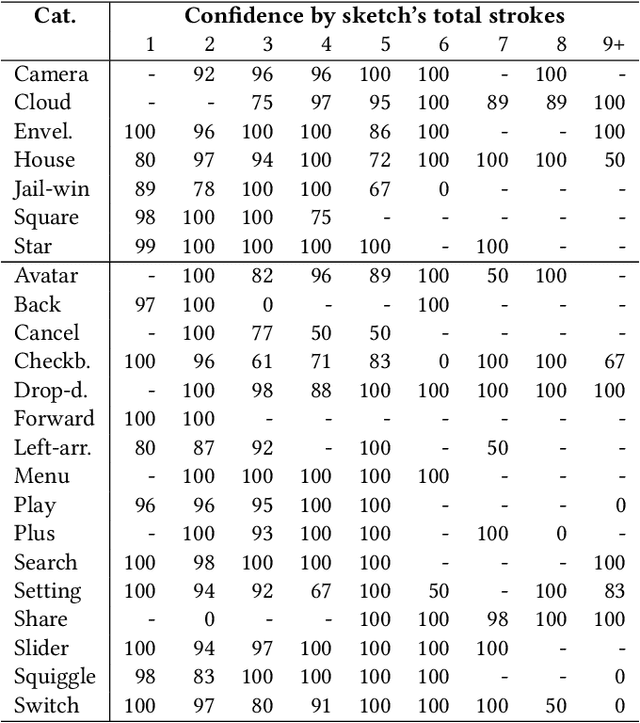
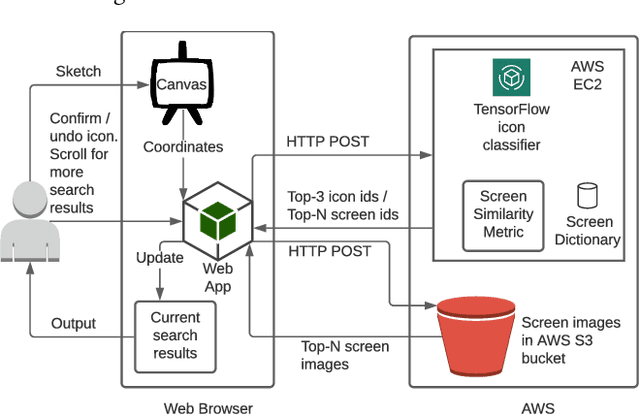
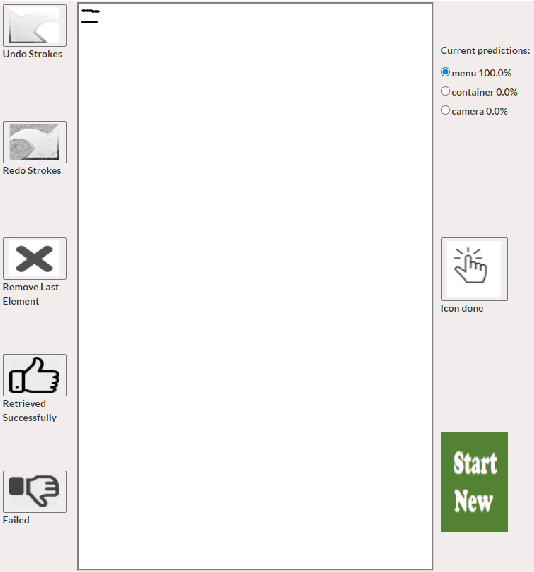
Keyword-based mobile screen search does not account for screen content and fails to operate as a universal tool for all levels of users. Visual searching (e.g., image, sketch) is structured and easy to adopt. Current visual search approaches count on a complete screen and are therefore slow and tedious. PSDoodle employs a deep neural network to recognize partial screen element drawings instantly on a digital drawing interface and shows results in real-time. PSDoodle is the first tool that utilizes partial sketches and searches for screens in an interactive iterative way. PSDoodle supports different drawing styles and retrieves search results that are relevant to the user's sketch query. A short video demonstration is available online at: https://youtu.be/3cVLHFm5pY4
SLGPT: Using Transfer Learning to Directly Generate Simulink Model Files and Find Bugs in the Simulink Toolchain
May 18, 2021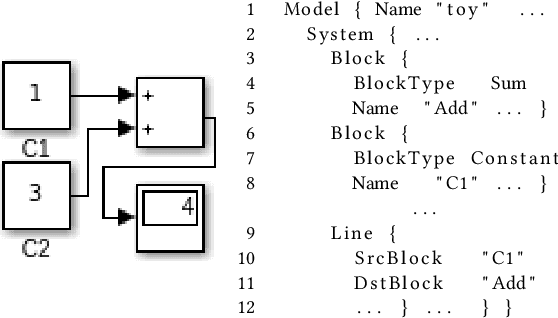
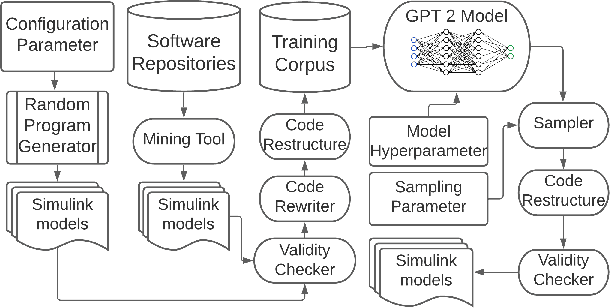
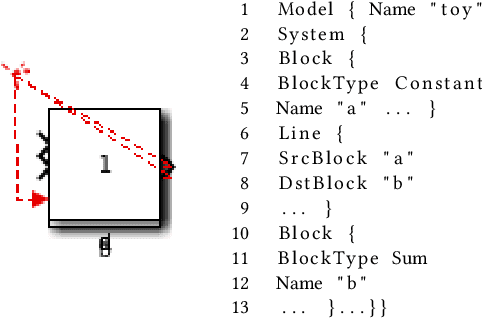
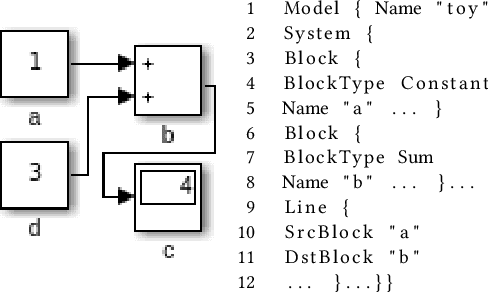
Finding bugs in a commercial cyber-physical system (CPS) development tool such as Simulink is hard as its codebase contains millions of lines of code and complete formal language specifications are not available. While deep learning techniques promise to learn such language specifications from sample models, deep learning needs a large number of training data to work well. SLGPT addresses this problem by using transfer learning to leverage the powerful Generative Pre-trained Transformer 2 (GPT-2) model, which has been pre-trained on a large set of training data. SLGPT adapts GPT-2 to Simulink with both randomly generated models and models mined from open-source repositories. SLGPT produced Simulink models that are both more similar to open-source models than its closest competitor, DeepFuzzSL, and found a super-set of the Simulink development toolchain bugs found by DeepFuzzSL.