 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
MRI-compatible electromagnetic servomotors for image-guided robotic procedures
Aug 16, 2021
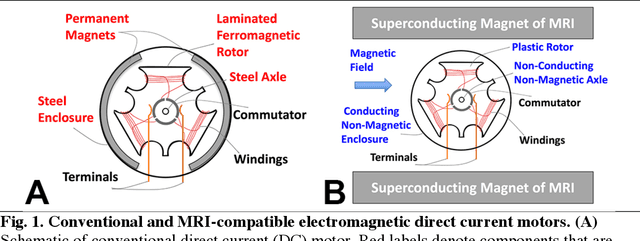
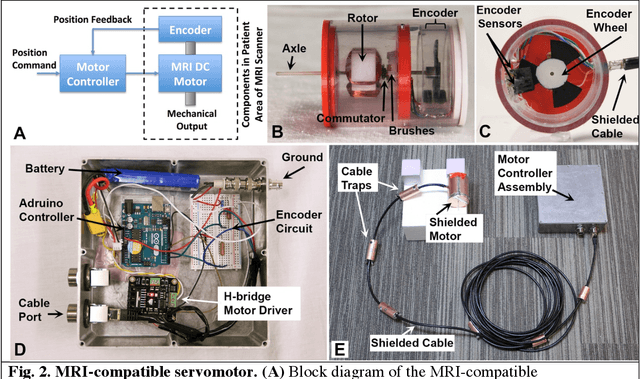
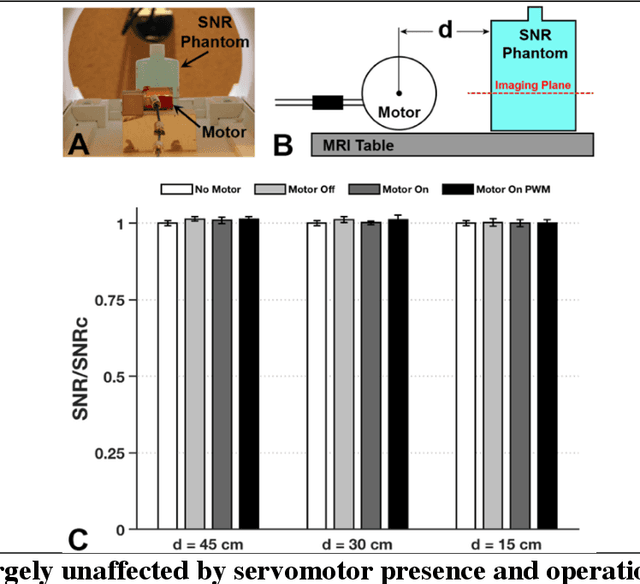
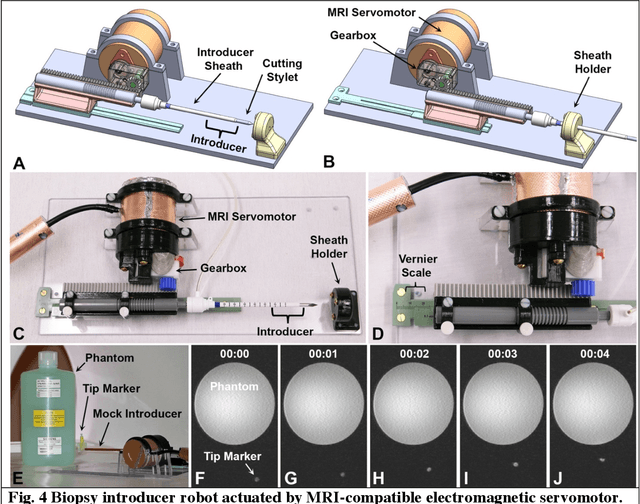
Combining the unmatched soft-tissue imaging capabilities of magnetic resonance imaging (MRI) with high precision robotics has the potential to improve the accuracy, precision, and safety of a wide range of image-guided medical procedures. However, the goal of highly functional MRI-compatible robotic systems has not yet been realized because conventional electromagnetic servomotors used by medical robots can become dangerous projectiles near the strong magnetic field of an MRI scanner. Here we report a novel electromagnetic servomotor design that is constructed from non-magnetic components and can operate within the patient area of clinical scanners. We show that this design enables high-torque and precisely controlled rotary actuation during imaging. Using this servomotor design, an MRI-compatible robot was constructed and tested. The robot demonstrated that the linear forces required to manipulate large diameter surgical instruments in tissues could be achieved during simultaneous imaging with MRI. This work presents the first fully functional electromagnetic servomotor that can be safely operated (while imaging) in the patient area of a 3 Tesla clinical MRI scanner.
Meta-RangeSeg: LiDAR Sequence Semantic Segmentation Using Multiple Feature Aggregation
Mar 03, 2022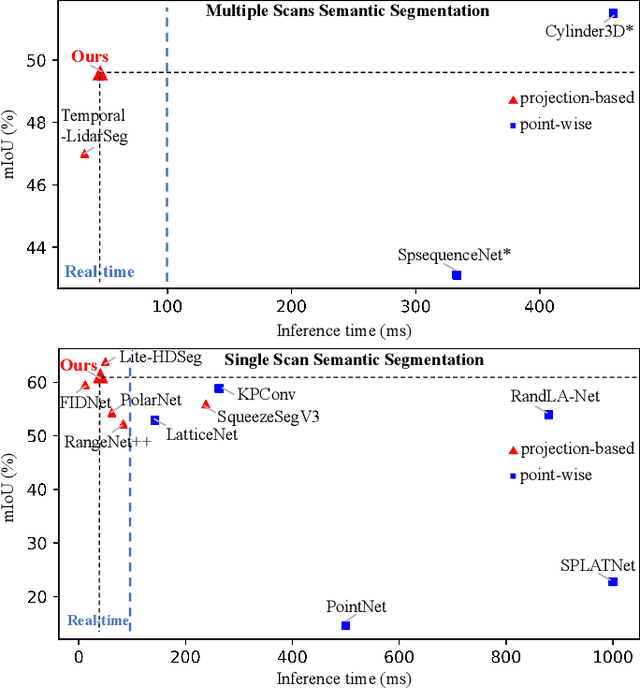
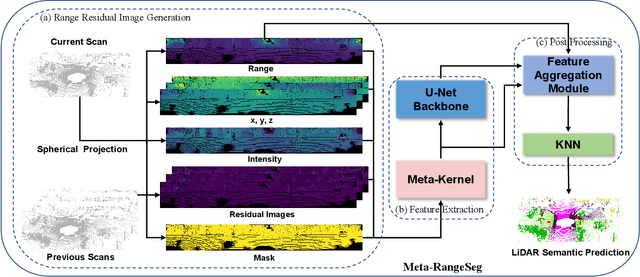
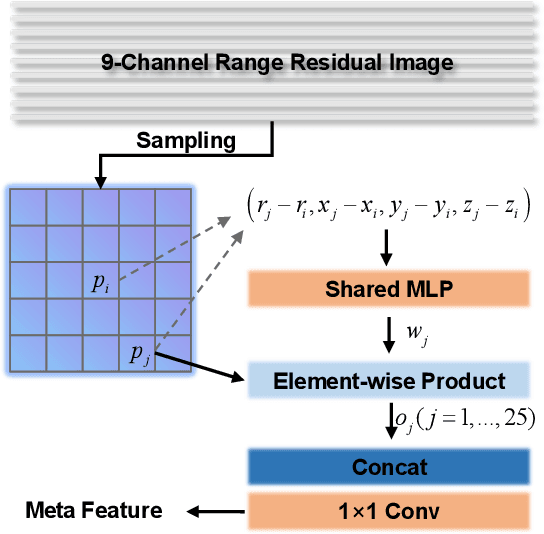
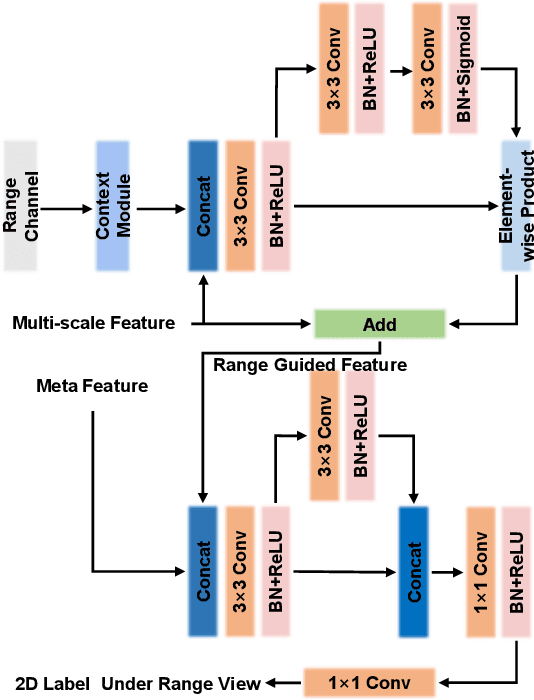
LiDAR sensor is essential to the perception system in autonomous vehicles and intelligent robots. To fulfill the real-time requirements in real-world applications, it is necessary to efficiently segment the LiDAR scans. Most of previous approaches directly project 3D point cloud onto the 2D spherical range image so that they can make use of the efficient 2D convolutional operations for image segmentation. Although having achieved the encouraging results, the neighborhood information is not well-preserved in the spherical projection. Moreover, the temporal information is not taken into consideration in the single scan segmentation task. To tackle these problems, we propose a novel approach to semantic segmentation for LiDAR sequences named Meta-RangeSeg, where a novel range residual image representation is introduced to capture the spatial-temporal information. Specifically, Meta-Kernel is employed to extract the meta features, which reduces the inconsistency between the 2D range image coordinates input and Cartesian coordinates output. An efficient U-Net backbone is used to obtain the multi-scale features. Furthermore, Feature Aggregation Module (FAM) aggregates the meta features and multi-scale features, which tends to strengthen the role of range channel. We have conducted extensive experiments for performance evaluation on SemanticKITTI, which is the de-facto dataset for LiDAR semantic segmentation. The promising results show that our proposed Meta-RangeSeg method is more efficient and effective than the existing approaches. Our full implementation is publicly available at https://github.com/songw-zju/Meta-RangeSeg .
Attention-based Stylisation for Exemplar Image Colourisation
May 04, 2021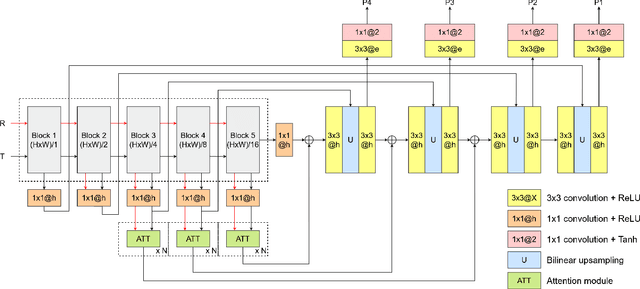
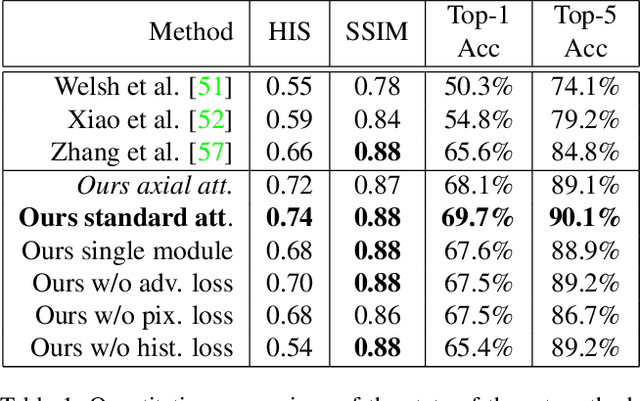
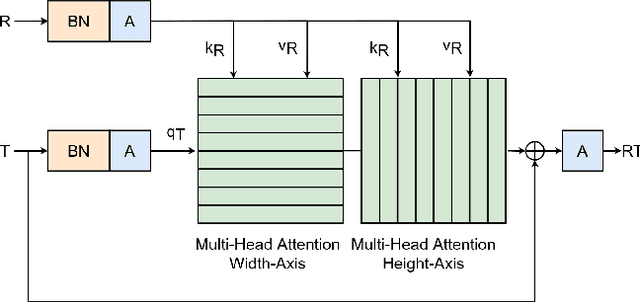
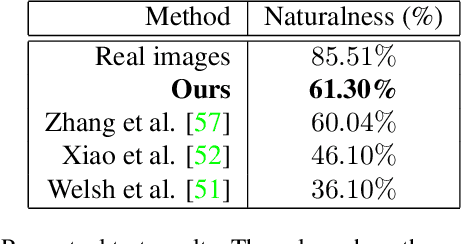
Exemplar-based colourisation aims to add plausible colours to a grayscale image using the guidance of a colour reference image. Most of the existing methods tackle the task as a style transfer problem, using a convolutional neural network (CNN) to obtain deep representations of the content of both inputs. Stylised outputs are then obtained by computing similarities between both feature representations in order to transfer the style of the reference to the content of the target input. However, in order to gain robustness towards dissimilar references, the stylised outputs need to be refined with a second colourisation network, which significantly increases the overall system complexity. This work reformulates the existing methodology introducing a novel end-to-end colourisation network that unifies the feature matching with the colourisation process. The proposed architecture integrates attention modules at different resolutions that learn how to perform the style transfer task in an unsupervised way towards decoding realistic colour predictions. Moreover, axial attention is proposed to simplify the attention operations and to obtain a fast but robust cost-effective architecture. Experimental validations demonstrate efficiency of the proposed methodology which generates high quality and visual appealing colourisation. Furthermore, the complexity of the proposed methodology is reduced compared to the state-of-the-art methods.
Two Decades of Bengali Handwritten Digit Recognition: A Survey
Jun 05, 2022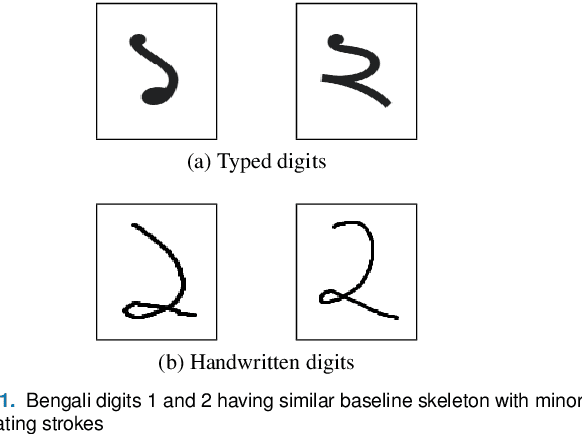
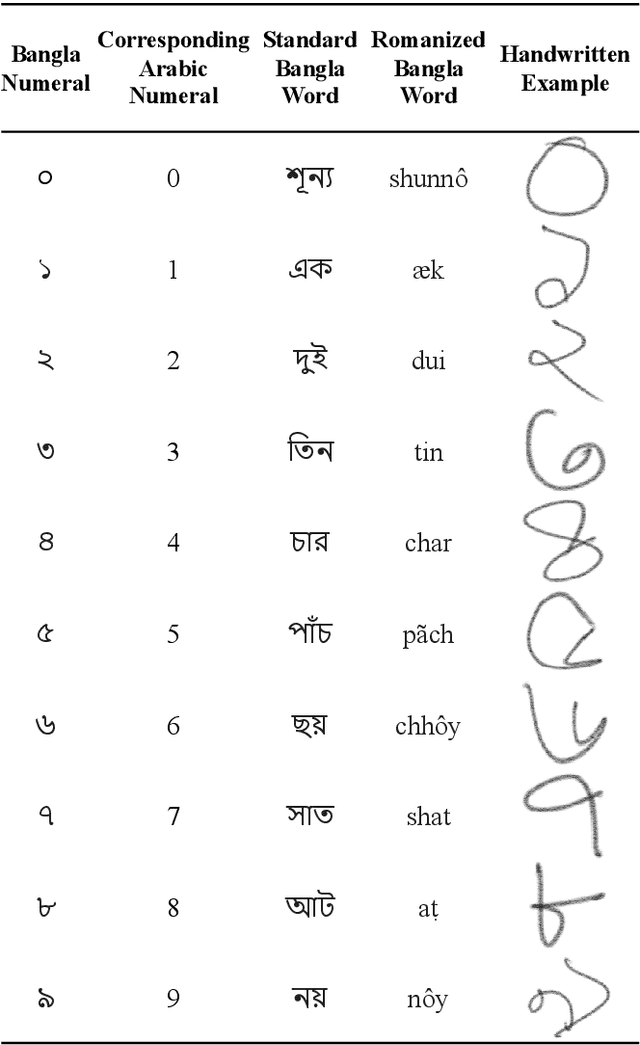
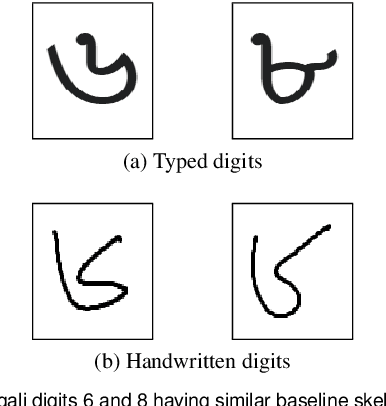

Handwritten Digit Recognition (HDR) is one of the most challenging tasks in the domain of Optical Character Recognition (OCR). Irrespective of language, there are some inherent challenges of HDR, which mostly arise due to the variations in writing styles across individuals, writing medium and environment, inability to maintain the same strokes while writing any digit repeatedly, etc. In addition to that, the structural complexities of the digits of a particular language may lead to ambiguous scenarios of HDR. Over the years, researchers have developed numerous offline and online HDR pipelines, where different image processing techniques are combined with traditional Machine Learning (ML)-based and/or Deep Learning (DL)-based architectures. Although evidence of extensive review studies on HDR exists in the literature for languages, such as: English, Arabic, Indian, Farsi, Chinese, etc., few surveys on Bengali HDR (BHDR) can be found, which lack a comprehensive analysis of the challenges, the underlying recognition process, and possible future directions. In this paper, the characteristics and inherent ambiguities of Bengali handwritten digits along with a comprehensive insight of two decades of the state-of-the-art datasets and approaches towards offline BHDR have been analyzed. Furthermore, several real-life application-specific studies, which involve BHDR, have also been discussed in detail. This paper will also serve as a compendium for researchers interested in the science behind offline BHDR, instigating the exploration of newer avenues of relevant research that may further lead to better offline recognition of Bengali handwritten digits in different application areas.
A Novel Framework for Characterization of Tumor-Immune Spatial Relationships in Tumor Microenvironment
May 01, 2022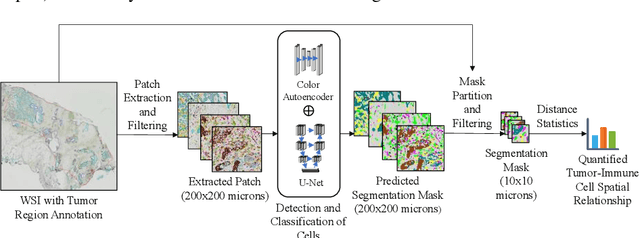

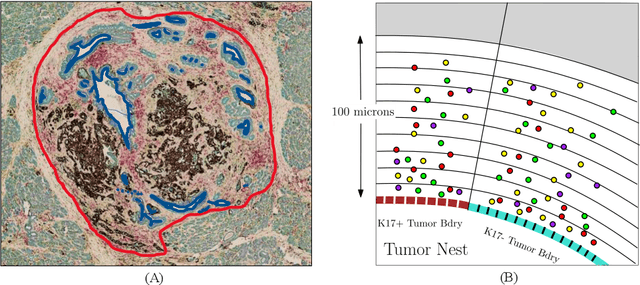
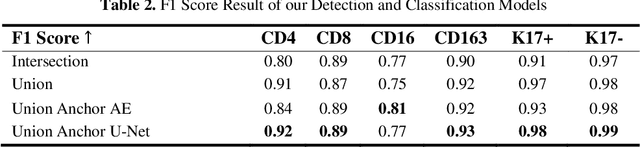
Understanding the impact of tumor biology on the composition of nearby cells often requires characterizing the impact of biologically distinct tumor regions. Biomarkers have been developed to label biologically distinct tumor regions, but challenges arise because of differences in the spatial extent and distribution of differentially labeled regions. In this work, we present a framework for systematically investigating the impact of distinct tumor regions on cells near the tumor borders, accounting their cross spatial distributions. We apply the framework to multiplex immunohistochemistry (mIHC) studies of pancreatic cancer and show its efficacy in demonstrating how biologically different tumor regions impact the immune response in the tumor microenvironment. Furthermore, we show that the proposed framework can be extended to largescale whole slide image analysis.
All-Photonic Artificial Neural Network Processor Via Non-linear Optics
May 17, 2022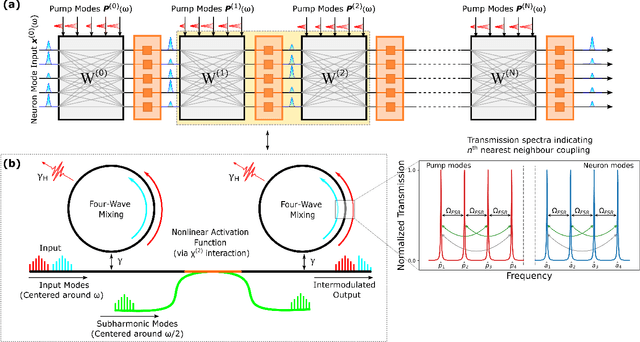
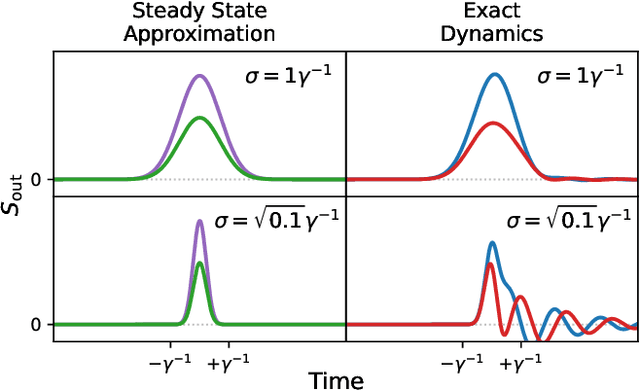
Optics and photonics has recently captured interest as a platform to accelerate linear matrix processing, that has been deemed as a bottleneck in traditional digital electronic architectures. In this paper, we propose an all-photonic artificial neural network processor wherein information is encoded in the amplitudes of frequency modes that act as neurons. The weights among connected layers are encoded in the amplitude of controlled frequency modes that act as pumps. Interaction among these modes for information processing is enabled by non-linear optical processes. Both the matrix multiplication and element-wise activation functions are performed through coherent processes, enabling the direct representation of negative and complex numbers without the use of detectors or digital electronics. Via numerical simulations, we show that our design achieves a performance commensurate with present-day state-of-the-art computational networks on image-classification benchmarks. Our architecture is unique in providing a completely unitary, reversible mode of computation. Additionally, the computational speed increases with the power of the pumps to arbitrarily high rates, as long as the circuitry can sustain the higher optical power.
FaPN: Feature-aligned Pyramid Network for Dense Image Prediction
Aug 16, 2021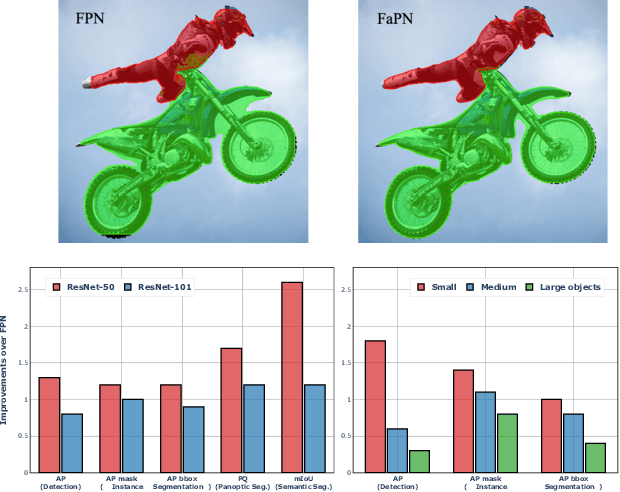
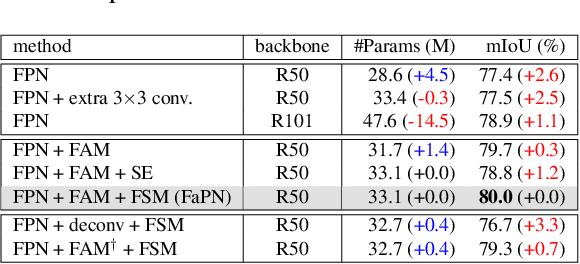
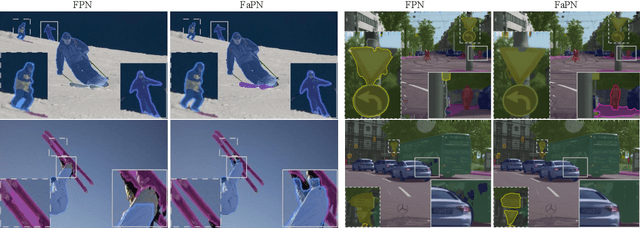
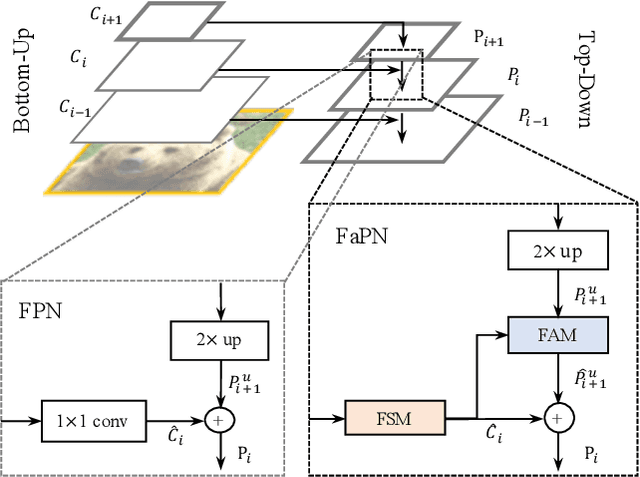
Recent advancements in deep neural networks have made remarkable leap-forwards in dense image prediction. However, the issue of feature alignment remains as neglected by most existing approaches for simplicity. Direct pixel addition between upsampled and local features leads to feature maps with misaligned contexts that, in turn, translate to mis-classifications in prediction, especially on object boundaries. In this paper, we propose a feature alignment module that learns transformation offsets of pixels to contextually align upsampled higher-level features; and another feature selection module to emphasize the lower-level features with rich spatial details. We then integrate these two modules in a top-down pyramidal architecture and present the Feature-aligned Pyramid Network (FaPN). Extensive experimental evaluations on four dense prediction tasks and four datasets have demonstrated the efficacy of FaPN, yielding an overall improvement of 1.2 - 2.6 points in AP / mIoU over FPN when paired with Faster / Mask R-CNN. In particular, our FaPN achieves the state-of-the-art of 56.7% mIoU on ADE20K when integrated within Mask-Former. The code is available from https://github.com/EMI-Group/FaPN.
Analyzing the Latent Space of GAN through Local Dimension Estimation
May 26, 2022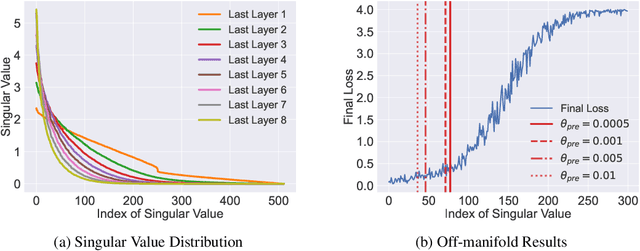
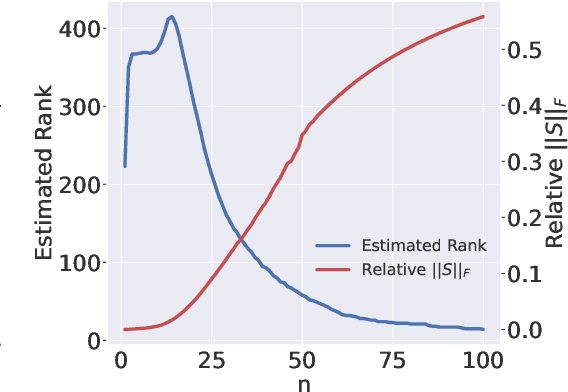
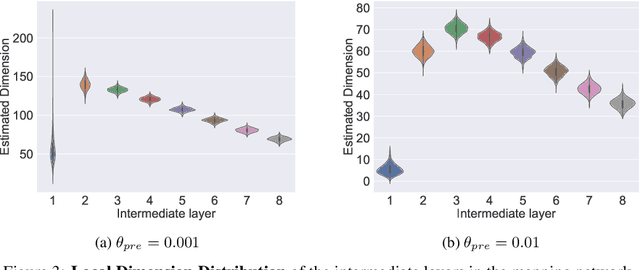
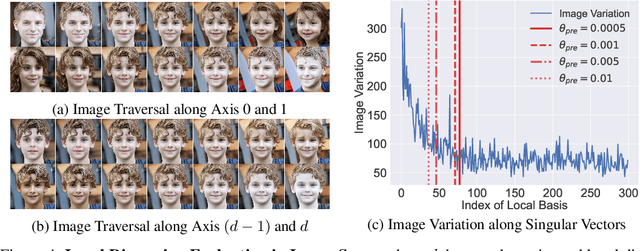
The impressive success of style-based GANs (StyleGANs) in high-fidelity image synthesis has motivated research to understand the semantic properties of their latent spaces. Recently, a close relationship was observed between the semantically disentangled local perturbations and the local PCA components in the learned latent space $\mathcal{W}$. However, understanding the number of disentangled perturbations remains challenging. Building upon this observation, we propose a local dimension estimation algorithm for an arbitrary intermediate layer in a pre-trained GAN model. The estimated intrinsic dimension corresponds to the number of disentangled local perturbations. In this perspective, we analyze the intermediate layers of the mapping network in StyleGANs. Our analysis clarifies the success of $\mathcal{W}$-space in StyleGAN and suggests an alternative. Moreover, the intrinsic dimension estimation opens the possibility of unsupervised evaluation of global-basis-compatibility and disentanglement for a latent space. Our proposed metric, called Distortion, measures an inconsistency of intrinsic tangent space on the learned latent space. The metric is purely geometric and does not require any additional attribute information. Nevertheless, the metric shows a high correlation with the global-basis-compatibility and supervised disentanglement score. Our findings pave the way towards an unsupervised selection of globally disentangled latent space among the intermediate latent spaces in a GAN.
Indication as Prior Knowledge for Multimodal Disease Classification in Chest Radiographs with Transformers
Feb 12, 2022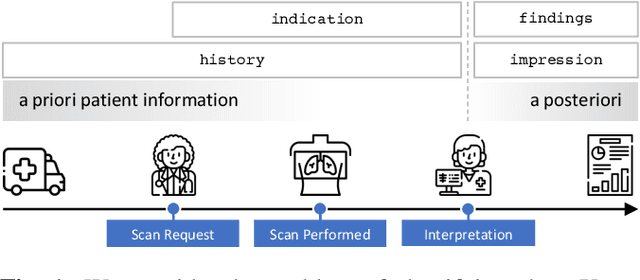

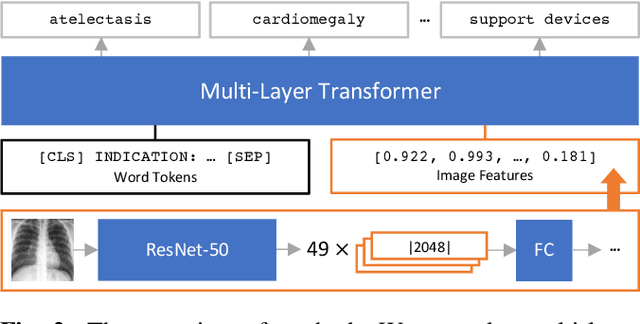
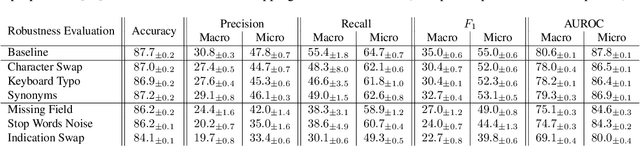
When a clinician refers a patient for an imaging exam, they include the reason (e.g. relevant patient history, suspected disease) in the scan request; this appears as the indication field in the radiology report. The interpretation and reporting of the image are substantially influenced by this request text, steering the radiologist to focus on particular aspects of the image. We use the indication field to drive better image classification, by taking a transformer network which is unimodally pre-trained on text (BERT) and fine-tuning it for multimodal classification of a dual image-text input. We evaluate the method on the MIMIC-CXR dataset, and present ablation studies to investigate the effect of the indication field on the classification performance. The experimental results show our approach achieves 87.8 average micro AUROC, outperforming the state-of-the-art methods for unimodal (84.4) and multimodal (86.0) classification. Our code is available at https://github.com/jacenkow/mmbt.
NeurMiPs: Neural Mixture of Planar Experts for View Synthesis
Apr 28, 2022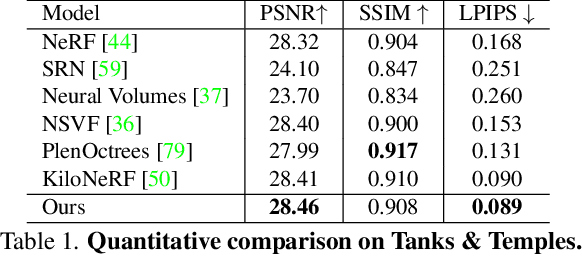
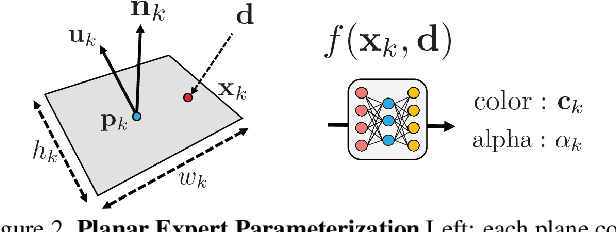
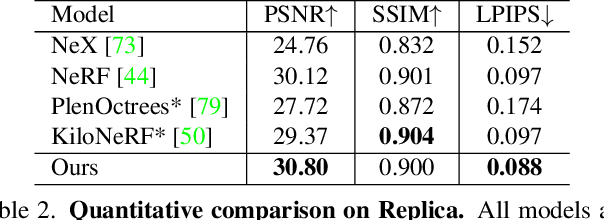
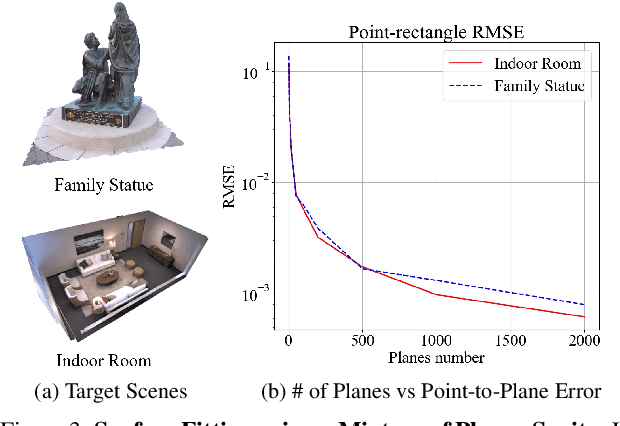
We present Neural Mixtures of Planar Experts (NeurMiPs), a novel planar-based scene representation for modeling geometry and appearance. NeurMiPs leverages a collection of local planar experts in 3D space as the scene representation. Each planar expert consists of the parameters of the local rectangular shape representing geometry and a neural radiance field modeling the color and opacity. We render novel views by calculating ray-plane intersections and composite output colors and densities at intersected points to the image. NeurMiPs blends the efficiency of explicit mesh rendering and flexibility of the neural radiance field. Experiments demonstrate superior performance and speed of our proposed method, compared to other 3D representations in novel view synthesis.