 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Without Eyes: 4D Human-Scene Understanding from Wearable IMUs
Apr 23, 2026Understanding human activities and their surrounding environments typically relies on visual perception, yet cameras pose persistent challenges in privacy, safety, energy efficiency, and scalability. We explore an alternative: 4D perception without vision. Its goal is to reconstruct human motion and 3D scene layouts purely from everyday wearable sensors. For this we introduce IMU-to-4D, a framework that repurposes large language models for non-visual spatiotemporal understanding of human-scene dynamics. IMU-to-4D uses data from a few inertial sensors from earbuds, watches, or smartphones and predicts detailed 4D human motion together with coarse scene structure. Experiments across diverse human-scene datasets show that IMU-to-4D yields more coherent and temporally stable results than SoTA cascaded pipelines, suggesting wearable motion sensors alone can support rich 4D understanding.
AutoVFX: Physically Realistic Video Editing from Natural Language Instructions
Nov 04, 2024



Modern visual effects (VFX) software has made it possible for skilled artists to create imagery of virtually anything. However, the creation process remains laborious, complex, and largely inaccessible to everyday users. In this work, we present AutoVFX, a framework that automatically creates realistic and dynamic VFX videos from a single video and natural language instructions. By carefully integrating neural scene modeling, LLM-based code generation, and physical simulation, AutoVFX is able to provide physically-grounded, photorealistic editing effects that can be controlled directly using natural language instructions. We conduct extensive experiments to validate AutoVFX's efficacy across a diverse spectrum of videos and instructions. Quantitative and qualitative results suggest that AutoVFX outperforms all competing methods by a large margin in generative quality, instruction alignment, editing versatility, and physical plausibility.
NeurMiPs: Neural Mixture of Planar Experts for View Synthesis
Apr 28, 2022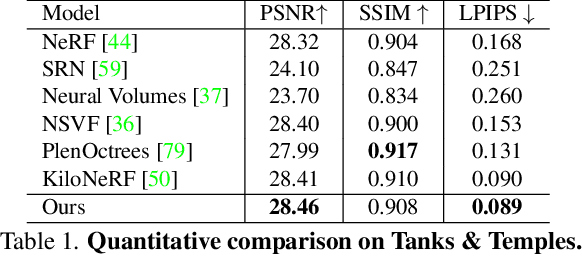
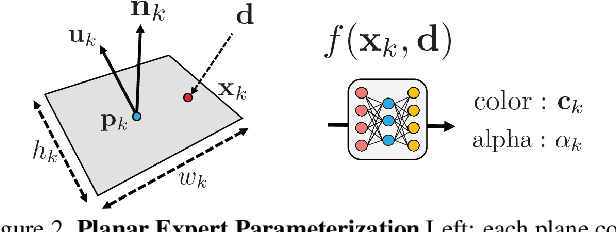
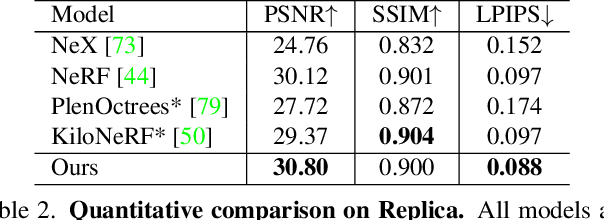
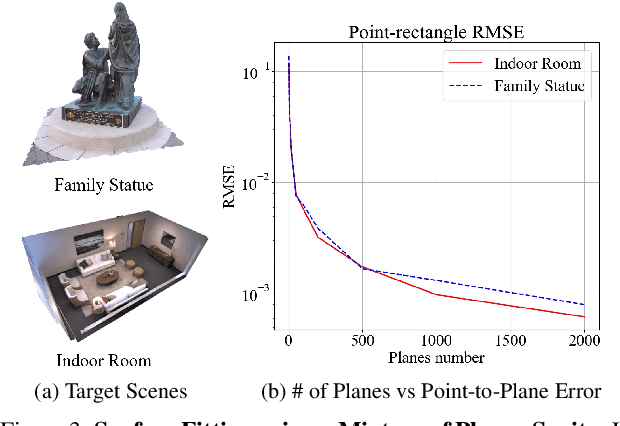
We present Neural Mixtures of Planar Experts (NeurMiPs), a novel planar-based scene representation for modeling geometry and appearance. NeurMiPs leverages a collection of local planar experts in 3D space as the scene representation. Each planar expert consists of the parameters of the local rectangular shape representing geometry and a neural radiance field modeling the color and opacity. We render novel views by calculating ray-plane intersections and composite output colors and densities at intersected points to the image. NeurMiPs blends the efficiency of explicit mesh rendering and flexibility of the neural radiance field. Experiments demonstrate superior performance and speed of our proposed method, compared to other 3D representations in novel view synthesis.