 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Realistic Defocus Blur for Multiplane Computer-Generated Holography
May 14, 2022


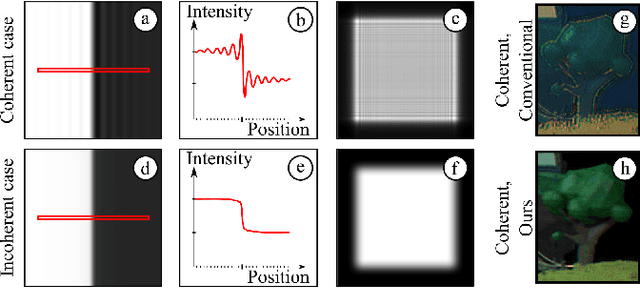

This paper introduces a new multiplane CGH computation method to reconstruct artefact-free high-quality holograms with natural-looking defocus blur. Our method introduces a new targeting scheme and a new loss function. While the targeting scheme accounts for defocused parts of the scene at each depth plane, the new loss function analyzes focused and defocused parts separately in reconstructed images. Our method support phase-only CGH calculations using various iterative (e.g., Gerchberg-Saxton, Gradient Descent) and non-iterative (e.g., Double Phase) CGH techniques. We achieve our best image quality using a modified gradient descent-based optimization recipe where we introduce a constraint inspired by the double phase method. We validate our method experimentally using our proof-of-concept holographic display, comparing various algorithms, including multi-depth scenes with sparse and dense contents.
Evaluating the Generalization Ability of Super-Resolution Networks
May 14, 2022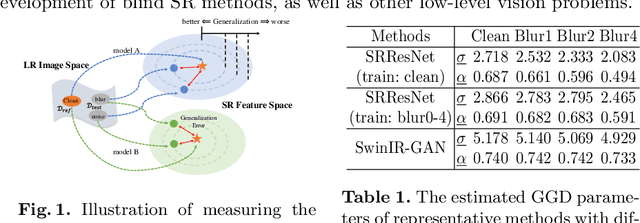


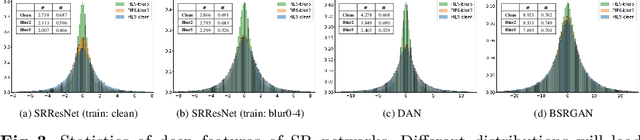
Performance and generalization ability are two important aspects to evaluate deep learning models. However, research on the generalization ability of Super-Resolution (SR) networks is currently absent. We make the first attempt to propose a Generalization Assessment Index for SR networks, namely SRGA. SRGA exploits the statistical characteristics of internal features of deep networks, not output images to measure the generalization ability. Specially, it is a non-parametric and non-learning metric. To better validate our method, we collect a patch-based image evaluation set (PIES) that includes both synthetic and real-world images, covering a wide range of degradations. With SRGA and PIES dataset, we benchmark existing SR models on the generalization ability. This work could lay the foundation for future research on model generalization in low-level vision.
Fully Automated Assessment of Cardiac Coverage in Cine Cardiovascular Magnetic Resonance Images using an Explainable Deep Visual Salient Region Detection Model
Jun 14, 2022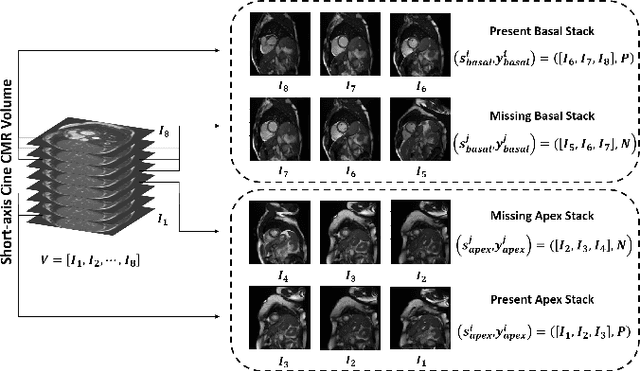

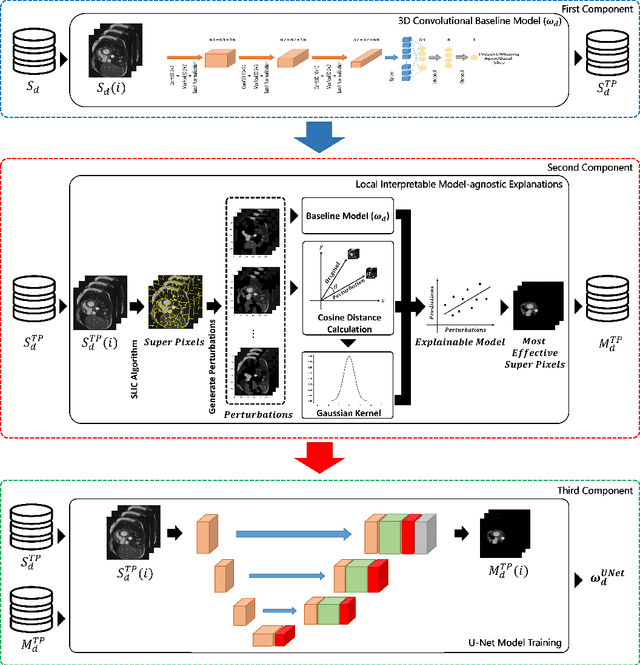
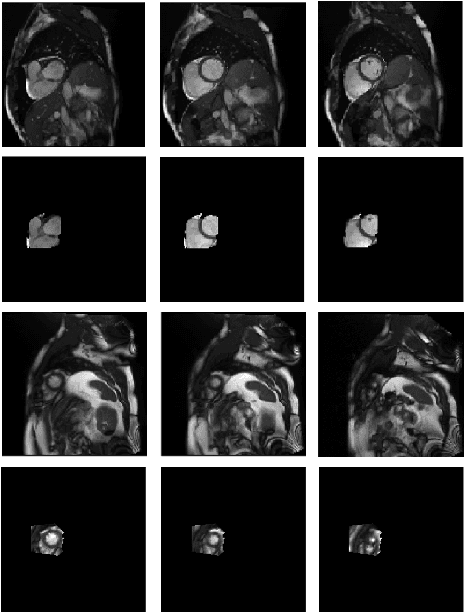
Cardiovascular magnetic resonance (CMR) imaging has become a modality with superior power for the diagnosis and prognosis of cardiovascular diseases. One of the essential basic quality controls of CMR images is to investigate the complete cardiac coverage, which is necessary for the volumetric and functional assessment. This study examines the full cardiac coverage using a 3D convolutional model and then reduces the number of false predictions using an innovative salient region detection model. Salient regions are extracted from the short-axis cine CMR stacks using a three-step proposed algorithm. Combining the 3D CNN baseline model with the proposed salient region detection model provides a cascade detector that can reduce the number of false negatives of the baseline model. The results obtained on the images of over 6,200 participants of the UK Biobank population cohort study show the superiority of the proposed model over the previous state-of-the-art studies. The dataset is the largest regarding the number of participants to control the cardiac coverage. The accuracy of the baseline model in identifying the presence/absence of basal/apical slices is 96.25\% and 94.51\%, respectively, which increases to 96.88\% and 95.72\% after improving using the proposed salient region detection model. Using the salient region detection model by forcing the baseline model to focus on the most informative areas of the images can help the model correct misclassified samples' predictions. The proposed fully automated model's performance indicates that this model can be used in image quality control in population cohort datasets and also real-time post-imaging quality assessments.
A GAN-Based Input-Size Flexibility Model for Single Image Dehazing
Feb 19, 2021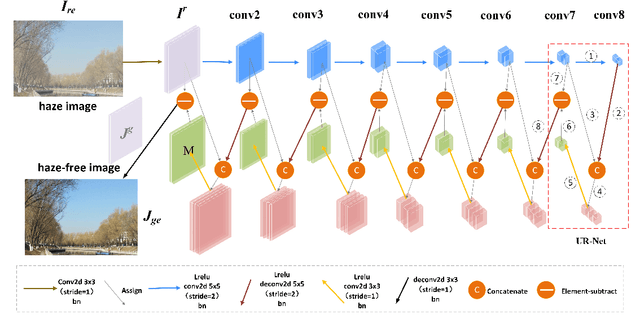
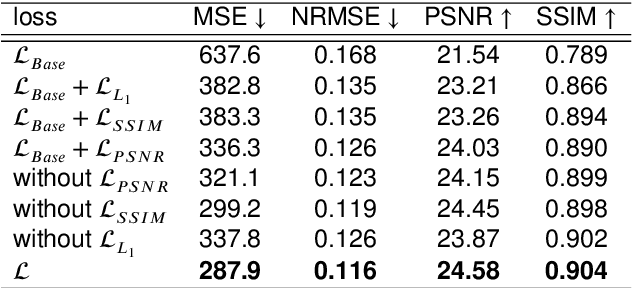
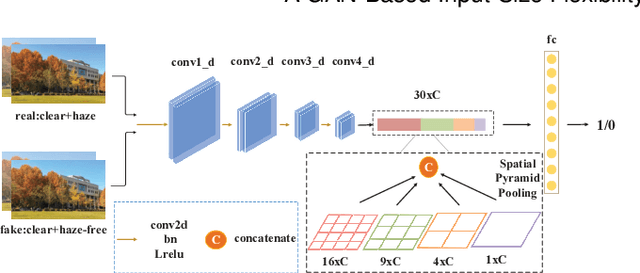
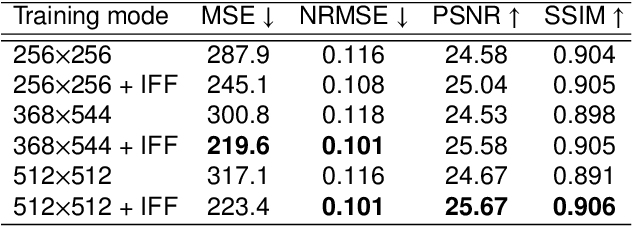
Image-to-image translation based on generative adversarial network (GAN) has achieved state-of-the-art performance in various image restoration applications. Single image dehazing is a typical example, which aims to obtain the haze-free image of a haze one. This paper concentrates on the challenging task of single image dehazing. Based on the atmospheric scattering model, we design a novel model to directly generate the haze-free image. The main challenge of image dehazing is that the atmospheric scattering model has two parameters, i.e., transmission map and atmospheric light. When we estimate them respectively, the errors will be accumulated to compromise dehazing quality. Considering this reason and various image sizes, we propose a novel input-size flexibility conditional generative adversarial network (cGAN) for single image dehazing, which is input-size flexibility at both training and test stages for image-to-image translation with cGAN framework. We propose a simple and effective U-type residual network (UR-Net) to combine the generator and adopt the spatial pyramid pooling (SPP) to design the discriminator. Moreover, the model is trained with multi-loss function, in which the consistency loss is a novel designed loss in this paper. We finally build a multi-scale cGAN fusion model to realize state-of-the-art single image dehazing performance. The proposed models receive a haze image as input and directly output a haze-free one. Experimental results demonstrate the effectiveness and efficiency of the proposed models.
VolNet: Estimating Human Body Part Volumes from a Single RGB Image
Jul 05, 2021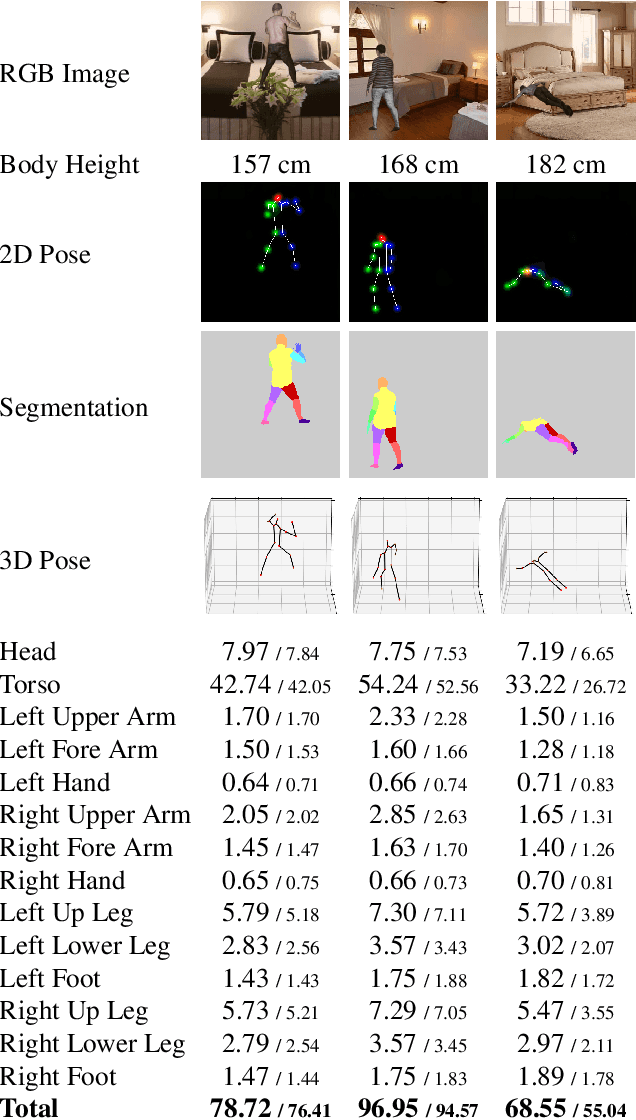
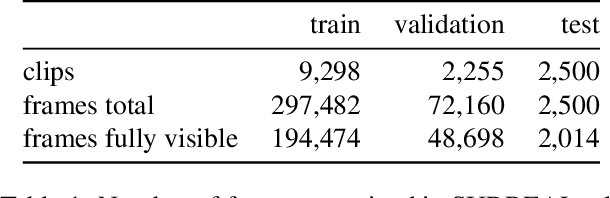
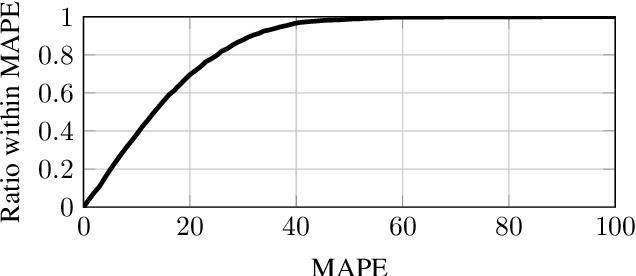
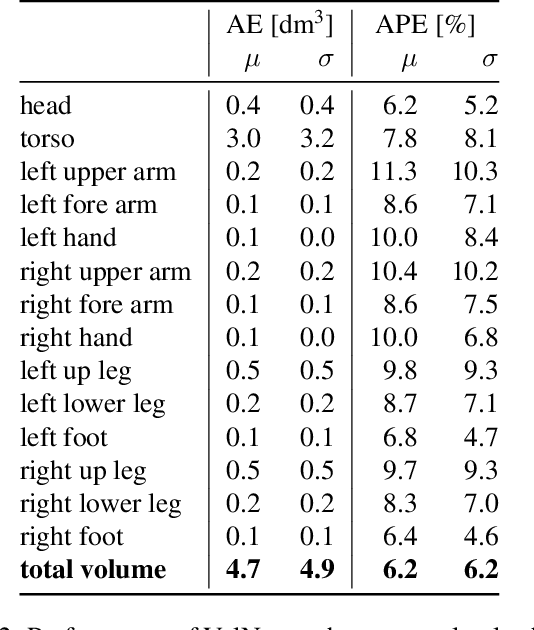
Human body volume estimation from a single RGB image is a challenging problem despite minimal attention from the research community. However VolNet, an architecture leveraging 2D and 3D pose estimation, body part segmentation and volume regression extracted from a single 2D RGB image combined with the subject's body height can be used to estimate the total body volume. VolNet is designed to predict the 2D and 3D pose as well as the body part segmentation in intermediate tasks. We generated a synthetic, large-scale dataset of photo-realistic images of human bodies with a wide range of body shapes and realistic poses called SURREALvols. By using Volnet and combining multiple stacked hourglass networks together with ResNeXt, our model correctly predicted the volume in ~82% of cases with a 10% tolerance threshold. This is a considerable improvement compared to state-of-the-art solutions such as BodyNet with only a ~38% success rate.
Fine-grained Semantic Constraint in Image Synthesis
Jan 12, 2021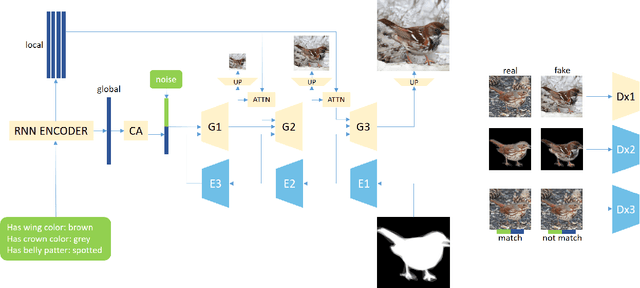

In this paper, we propose a multi-stage and high-resolution model for image synthesis that uses fine-grained attributes and masks as input. With a fine-grained attribute, the proposed model can detailedly constrain the features of the generated image through rich and fine-grained semantic information in the attribute. With mask as prior, the model in this paper is constrained so that the generated images conform to visual senses, which will reduce the unexpected diversity of samples generated from the generative adversarial network. This paper also proposes a scheme to improve the discriminator of the generative adversarial network by simultaneously discriminating the total image and sub-regions of the image. In addition, we propose a method for optimizing the labeled attribute in datasets, which reduces the manual labeling noise. Extensive quantitative results show that our image synthesis model generates more realistic images.
SUD: Supervision by Denoising for Medical Image Segmentation
Feb 07, 2022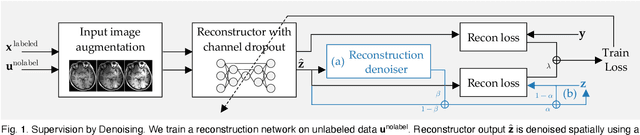

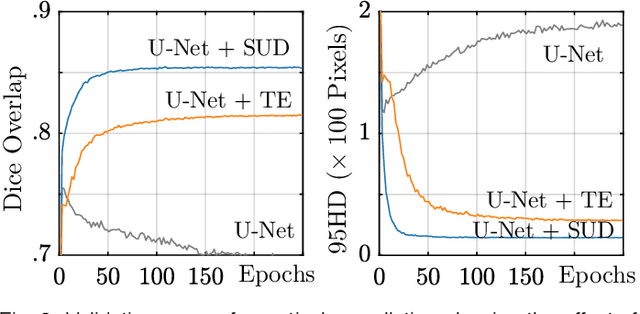
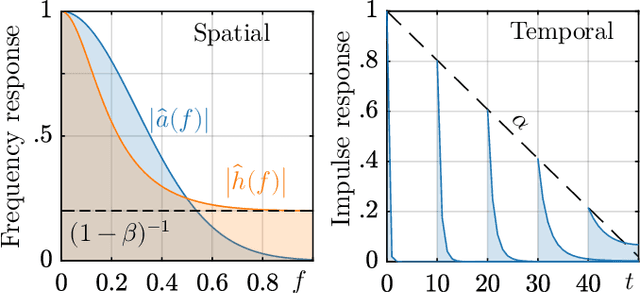
Training a fully convolutional network for semantic segmentation typically requires a large, labeled dataset with little label noise if good generalization is to be guaranteed. For many segmentation problems, however, data with pixel- or voxel-level labeling accuracy are scarce due to the cost of manual labeling. This problem is exacerbated in domains where manual annotation is difficult, resulting in large amounts of variability in the labeling even across domain experts. Therefore, training segmentation networks to generalize better by learning from both labeled and unlabeled images (called semi-supervised learning) is problem of both practical and theoretical interest. However, traditional semi-supervised learning methods for segmentation often necessitate hand-crafting a differentiable regularizer specific to a given segmentation problem, which can be extremely time-consuming. In this work, we propose "supervision by denoising" (SUD), a framework that enables us to supervise segmentation models using their denoised output as targets. SUD unifies temporal ensembling and spatial denoising techniques under a spatio-temporal denoising framework and alternates denoising and network weight update in an optimization framework for semi-supervision. We validate SUD on three tasks-kidney and tumor (3D), and brain (3D) segmentation, and cortical parcellation (2D)-demonstrating a significant improvement in the Dice overlap and the Hausdorff distance of segmentations over supervised-only and temporal ensemble baselines.
Towards Lifelong Federated Learning in Autonomous Mobile Robots with Continuous Sim-to-Real Transfer
May 31, 2022
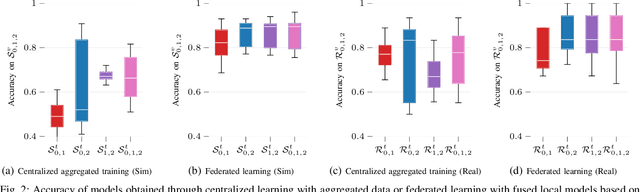
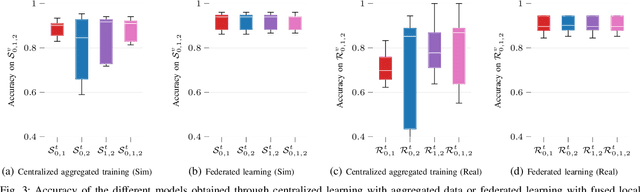
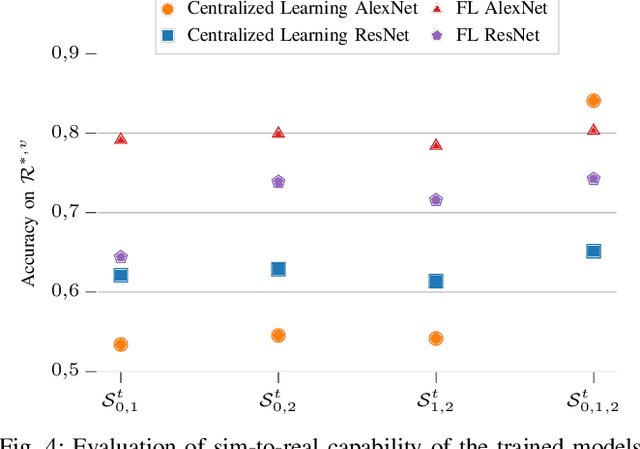
The role of deep learning (DL) in robotics has significantly deepened over the last decade. Intelligent robotic systems today are highly connected systems that rely on DL for a variety of perception, control, and other tasks. At the same time, autonomous robots are being increasingly deployed as part of fleets, with collaboration among robots becoming a more relevant factor. From the perspective of collaborative learning, federated learning (FL) enables continuous training of models in a distributed, privacy-preserving way. This paper focuses on vision-based obstacle avoidance for mobile robot navigation. On this basis, we explore the potential of FL for distributed systems of mobile robots enabling continuous learning via the engagement of robots in both simulated and real-world scenarios. We extend previous works by studying the performance of different image classifiers for FL, compared to centralized, cloud-based learning with a priori aggregated data. We also introduce an approach to continuous learning from mobile robots with extended sensor suites able to provide automatically labeled data while they are completing other tasks. We show that higher accuracies can be achieved by training the models in both simulation and reality, enabling continuous updates to deployed models.
SemAffiNet: Semantic-Affine Transformation for Point Cloud Segmentation
May 26, 2022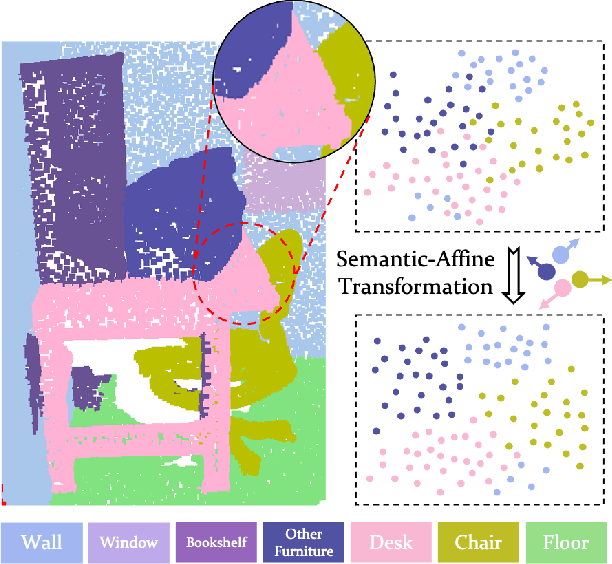
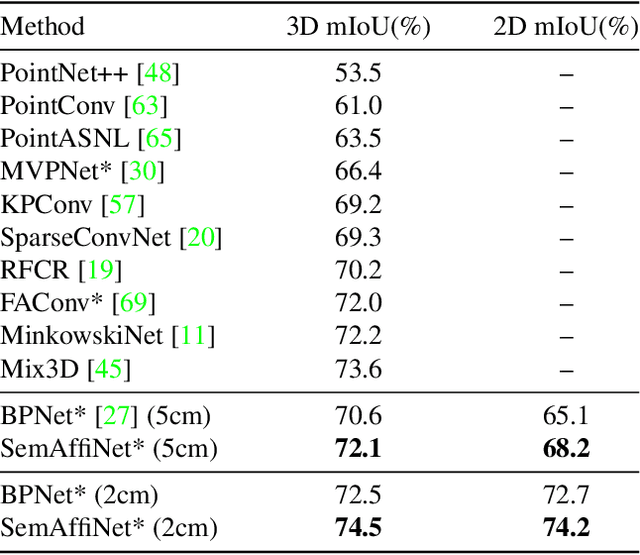
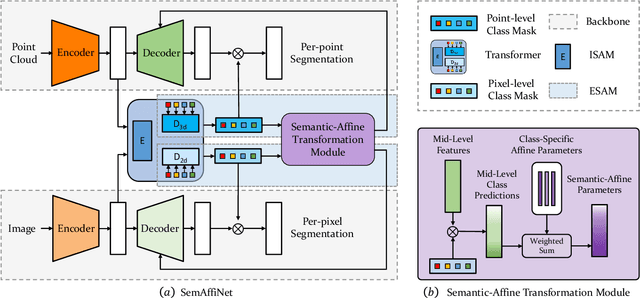
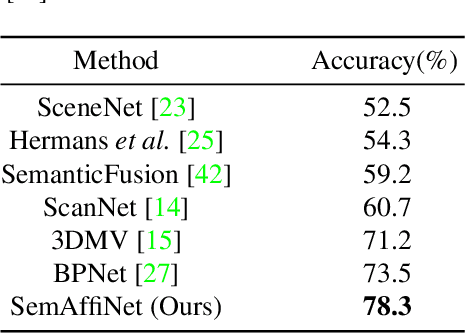
Conventional point cloud semantic segmentation methods usually employ an encoder-decoder architecture, where mid-level features are locally aggregated to extract geometric information. However, the over-reliance on these class-agnostic local geometric representations may raise confusion between local parts from different categories that are similar in appearance or spatially adjacent. To address this issue, we argue that mid-level features can be further enhanced with semantic information, and propose semantic-affine transformation that transforms features of mid-level points belonging to different categories with class-specific affine parameters. Based on this technique, we propose SemAffiNet for point cloud semantic segmentation, which utilizes the attention mechanism in the Transformer module to implicitly and explicitly capture global structural knowledge within local parts for overall comprehension of each category. We conduct extensive experiments on the ScanNetV2 and NYUv2 datasets, and evaluate semantic-affine transformation on various 3D point cloud and 2D image segmentation baselines, where both qualitative and quantitative results demonstrate the superiority and generalization ability of our proposed approach. Code is available at https://github.com/wangzy22/SemAffiNet.
An Object Detection based Solver for Google's Image reCAPTCHA v2
Apr 07, 2021
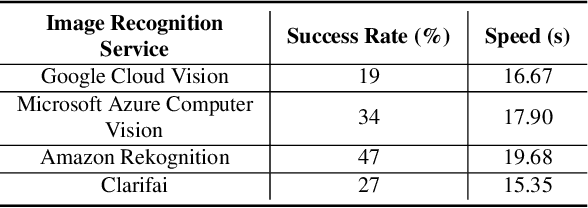
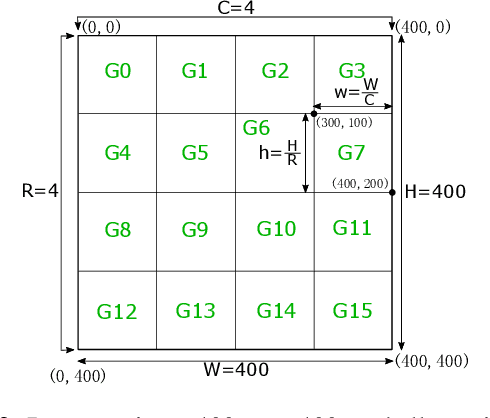
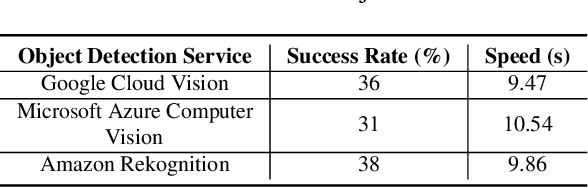
Previous work showed that reCAPTCHA v2's image challenges could be solved by automated programs armed with Deep Neural Network (DNN) image classifiers and vision APIs provided by off-the-shelf image recognition services. In response to emerging threats, Google has made significant updates to its image reCAPTCHA v2 challenges that can render the prior approaches ineffective to a great extent. In this paper, we investigate the robustness of the latest version of reCAPTCHA v2 against advanced object detection based solvers. We propose a fully automated object detection based system that breaks the most advanced challenges of reCAPTCHA v2 with an online success rate of 83.25%, the highest success rate to date, and it takes only 19.93 seconds (including network delays) on average to crack a challenge. We also study the updated security features of reCAPTCHA v2, such as anti-recognition mechanisms, improved anti-bot detection techniques, and adjustable security preferences. Our extensive experiments show that while these security features can provide some resistance against automated attacks, adversaries can still bypass most of them. Our experimental findings indicate that the recent advances in object detection technologies pose a severe threat to the security of image captcha designs relying on simple object detection as their underlying AI problem.