 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Disentangling Noise from Images: A Flow-Based Image Denoising Neural Network
May 11, 2021

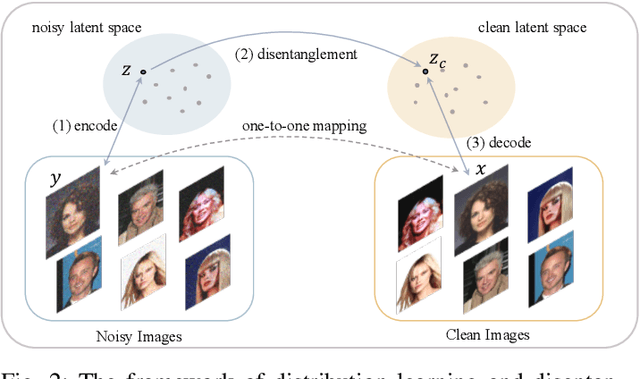
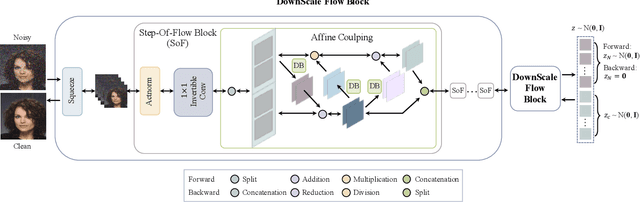
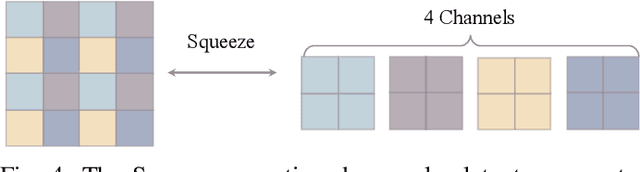
The prevalent convolutional neural network (CNN) based image denoising methods extract features of images to restore the clean ground truth, achieving high denoising accuracy. However, these methods may ignore the underlying distribution of clean images, inducing distortions or artifacts in denoising results. This paper proposes a new perspective to treat image denoising as a distribution learning and disentangling task. Since the noisy image distribution can be viewed as a joint distribution of clean images and noise, the denoised images can be obtained via manipulating the latent representations to the clean counterpart. This paper also provides a distribution learning based denoising framework. Following this framework, we present an invertible denoising network, FDN, without any assumptions on either clean or noise distributions, as well as a distribution disentanglement method. FDN learns the distribution of noisy images, which is different from the previous CNN based discriminative mapping. Experimental results demonstrate FDN's capacity to remove synthetic additive white Gaussian noise (AWGN) on both category-specific and remote sensing images. Furthermore, the performance of FDN surpasses that of previously published methods in real image denoising with fewer parameters and faster speed. Our code is available at: https://github.com/Yang-Liu1082/FDN.git.
Morphence-2.0: Evasion-Resilient Moving Target Defense Powered by Out-of-Distribution Detection
Jun 15, 2022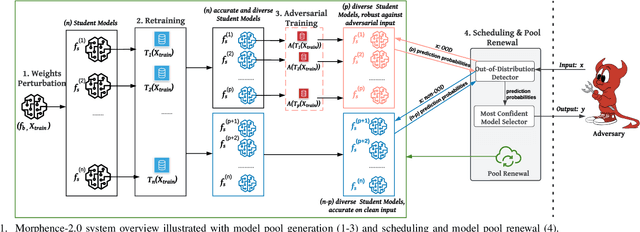
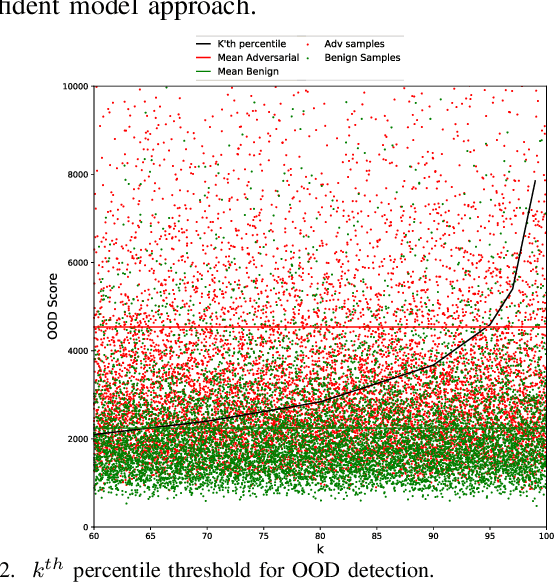
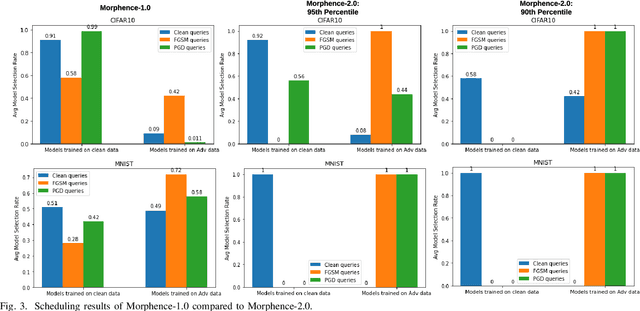
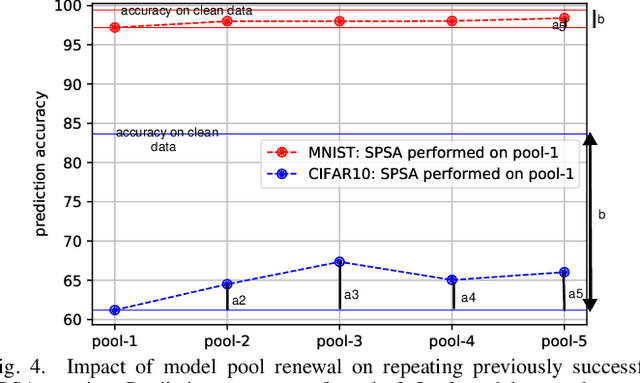
Evasion attacks against machine learning models often succeed via iterative probing of a fixed target model, whereby an attack that succeeds once will succeed repeatedly. One promising approach to counter this threat is making a model a moving target against adversarial inputs. To this end, we introduce Morphence-2.0, a scalable moving target defense (MTD) powered by out-of-distribution (OOD) detection to defend against adversarial examples. By regularly moving the decision function of a model, Morphence-2.0 makes it significantly challenging for repeated or correlated attacks to succeed. Morphence-2.0 deploys a pool of models generated from a base model in a manner that introduces sufficient randomness when it responds to prediction queries. Via OOD detection, Morphence-2.0 is equipped with a scheduling approach that assigns adversarial examples to robust decision functions and benign samples to an undefended accurate models. To ensure repeated or correlated attacks fail, the deployed pool of models automatically expires after a query budget is reached and the model pool is seamlessly replaced by a new model pool generated in advance. We evaluate Morphence-2.0 on two benchmark image classification datasets (MNIST and CIFAR10) against 4 reference attacks (3 white-box and 1 black-box). Morphence-2.0 consistently outperforms prior defenses while preserving accuracy on clean data and reducing attack transferability. We also show that, when powered by OOD detection, Morphence-2.0 is able to precisely make an input-based movement of the model's decision function that leads to higher prediction accuracy on both adversarial and benign queries.
Holistic Approach to Measure Sample-level Adversarial Vulnerability and its Utility in Building Trustworthy Systems
May 05, 2022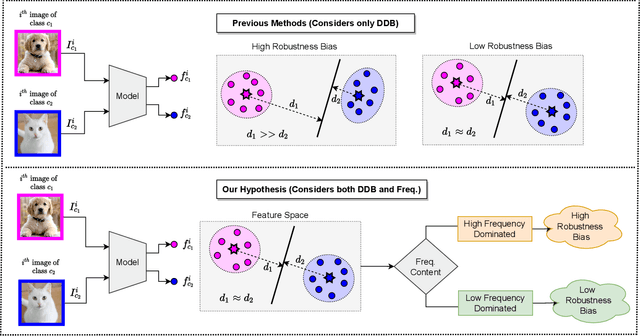
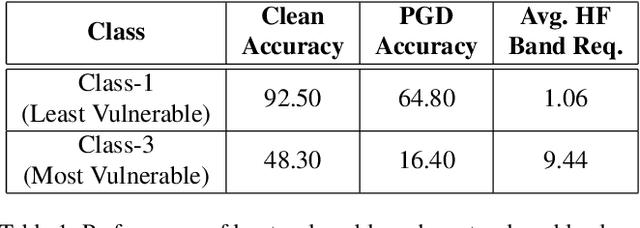

Adversarial attack perturbs an image with an imperceptible noise, leading to incorrect model prediction. Recently, a few works showed inherent bias associated with such attack (robustness bias), where certain subgroups in a dataset (e.g. based on class, gender, etc.) are less robust than others. This bias not only persists even after adversarial training, but often results in severe performance discrepancies across these subgroups. Existing works characterize the subgroup's robustness bias by only checking individual sample's proximity to the decision boundary. In this work, we argue that this measure alone is not sufficient and validate our argument via extensive experimental analysis. It has been observed that adversarial attacks often corrupt the high-frequency components of the input image. We, therefore, propose a holistic approach for quantifying adversarial vulnerability of a sample by combining these different perspectives, i.e., degree of model's reliance on high-frequency features and the (conventional) sample-distance to the decision boundary. We demonstrate that by reliably estimating adversarial vulnerability at the sample level using the proposed holistic metric, it is possible to develop a trustworthy system where humans can be alerted about the incoming samples that are highly likely to be misclassified at test time. This is achieved with better precision when our holistic metric is used over individual measures. To further corroborate the utility of the proposed holistic approach, we perform knowledge distillation in a limited-sample setting. We observe that the student network trained with the subset of samples selected using our combined metric performs better than both the competing baselines, viz., where samples are selected randomly or based on their distances to the decision boundary.
Psychologically-Inspired, Unsupervised Inference of Perceptual Groups of GUI Widgets from GUI Images
Jun 15, 2022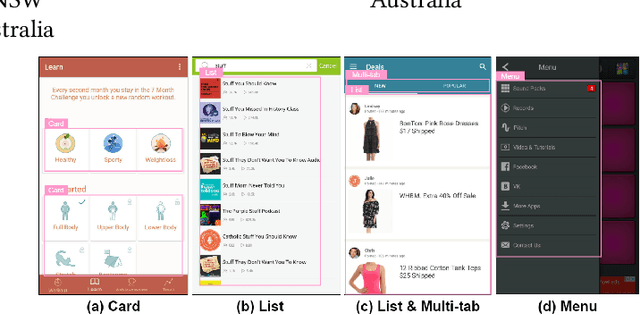
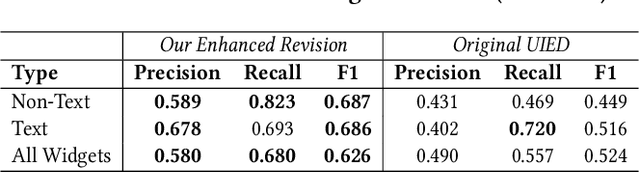
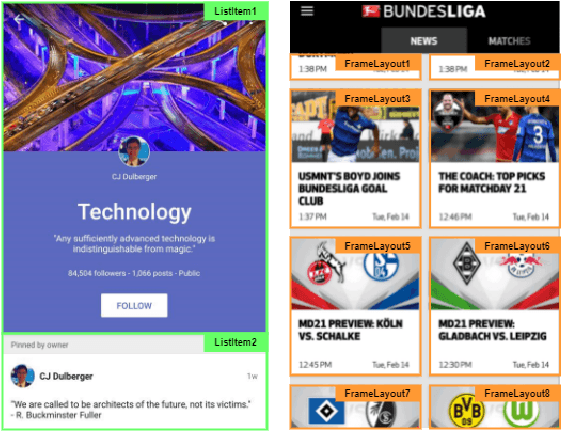
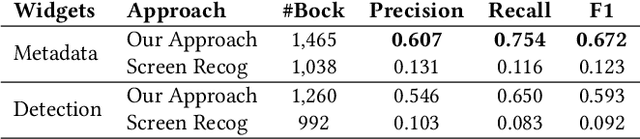
Graphical User Interface (GUI) is not merely a collection of individual and unrelated widgets, but rather partitions discrete widgets into groups by various visual cues, thus forming higher-order perceptual units such as tab, menu, card or list. The ability to automatically segment a GUI into perceptual groups of widgets constitutes a fundamental component of visual intelligence to automate GUI design, implementation and automation tasks. Although humans can partition a GUI into meaningful perceptual groups of widgets in a highly reliable way, perceptual grouping is still an open challenge for computational approaches. Existing methods rely on ad-hoc heuristics or supervised machine learning that is dependent on specific GUI implementations and runtime information. Research in psychology and biological vision has formulated a set of principles (i.e., Gestalt theory of perception) that describe how humans group elements in visual scenes based on visual cues like connectivity, similarity, proximity and continuity. These principles are domain-independent and have been widely adopted by practitioners to structure content on GUIs to improve aesthetic pleasant and usability. Inspired by these principles, we present a novel unsupervised image-based method for inferring perceptual groups of GUI widgets. Our method requires only GUI pixel images, is independent of GUI implementation, and does not require any training data. The evaluation on a dataset of 1,091 GUIs collected from 772 mobile apps and 20 UI design mockups shows that our method significantly outperforms the state-of-the-art ad-hoc heuristics-based baseline. Our perceptual grouping method creates the opportunities for improving UI-related software engineering tasks.
RCDNet: An Interpretable Rain Convolutional Dictionary Network for Single Image Deraining
Jul 14, 2021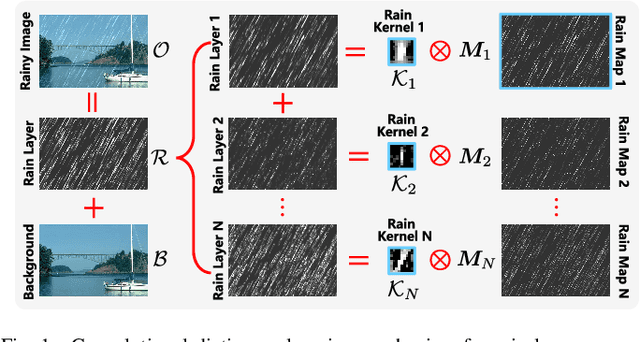
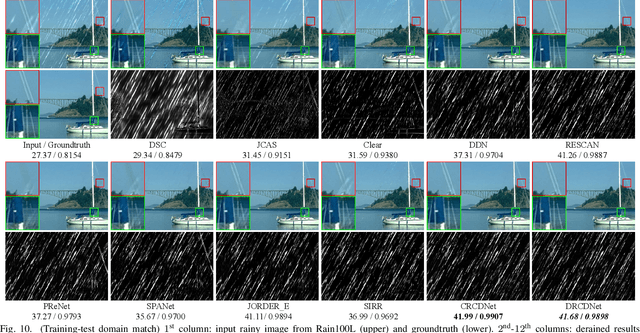

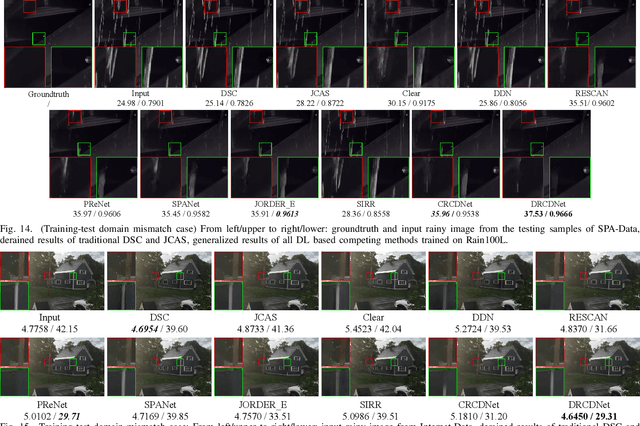
As a common weather, rain streaks adversely degrade the image quality. Hence, removing rains from an image has become an important issue in the field. To handle such an ill-posed single image deraining task, in this paper, we specifically build a novel deep architecture, called rain convolutional dictionary network (RCDNet), which embeds the intrinsic priors of rain streaks and has clear interpretability. In specific, we first establish a RCD model for representing rain streaks and utilize the proximal gradient descent technique to design an iterative algorithm only containing simple operators for solving the model. By unfolding it, we then build the RCDNet in which every network module has clear physical meanings and corresponds to each operation involved in the algorithm. This good interpretability greatly facilitates an easy visualization and analysis on what happens inside the network and why it works well in inference process. Moreover, taking into account the domain gap issue in real scenarios, we further design a novel dynamic RCDNet, where the rain kernels can be dynamically inferred corresponding to input rainy images and then help shrink the space for rain layer estimation with few rain maps so as to ensure a fine generalization performance in the inconsistent scenarios of rain types between training and testing data. By end-to-end training such an interpretable network, all involved rain kernels and proximal operators can be automatically extracted, faithfully characterizing the features of both rain and clean background layers, and thus naturally lead to better deraining performance. Comprehensive experiments substantiate the superiority of our method, especially on its well generality to diverse testing scenarios and good interpretability for all its modules. Code is available in \emph{\url{https://github.com/hongwang01/DRCDNet}}.
LAFFNet: A Lightweight Adaptive Feature Fusion Network for Underwater Image Enhancement
May 04, 2021
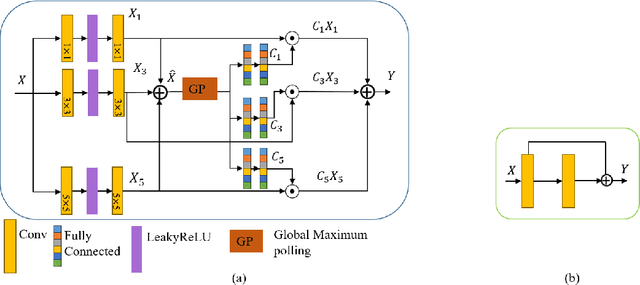
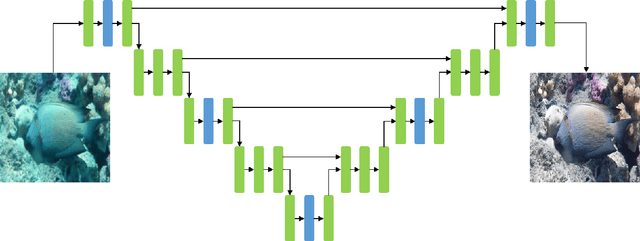

Underwater image enhancement is an important low-level computer vision task for autonomous underwater vehicles and remotely operated vehicles to explore and understand the underwater environments. Recently, deep convolutional neural networks (CNNs) have been successfully used in many computer vision problems, and so does underwater image enhancement. There are many deep-learning-based methods with impressive performance for underwater image enhancement, but their memory and model parameter costs are hindrances in practical application. To address this issue, we propose a lightweight adaptive feature fusion network (LAFFNet). The model is the encoder-decoder model with multiple adaptive feature fusion (AAF) modules. AAF subsumes multiple branches with different kernel sizes to generate multi-scale feature maps. Furthermore, channel attention is used to merge these feature maps adaptively. Our method reduces the number of parameters from 2.5M to 0.15M (around 94% reduction) but outperforms state-of-the-art algorithms by extensive experiments. Furthermore, we demonstrate our LAFFNet effectively improves high-level vision tasks like salience object detection and single image depth estimation.
Towards True Detail Restoration for Super-Resolution: A Benchmark and a Quality Metric
Mar 16, 2022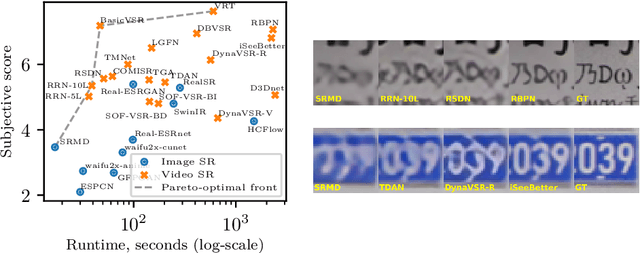
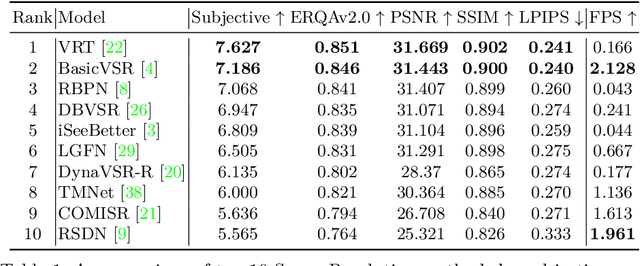

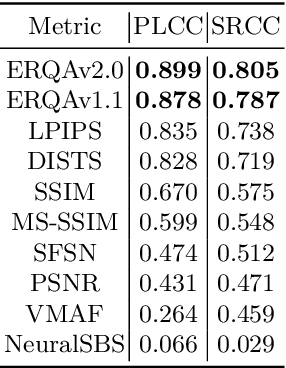
Super-resolution (SR) has become a widely researched topic in recent years. SR methods can improve overall image and video quality and create new possibilities for further content analysis. But the SR mainstream focuses primarily on increasing the naturalness of the resulting image despite potentially losing context accuracy. Such methods may produce an incorrect digit, character, face, or other structural object even though they otherwise yield good visual quality. Incorrect detail restoration can cause errors when detecting and identifying objects both manually and automatically. To analyze the detail-restoration capabilities of image and video SR models, we developed a benchmark based on our own video dataset, which contains complex patterns that SR models generally fail to correctly restore. We assessed 32 recent SR models using our benchmark and compared their ability to preserve scene context. We also conducted a crowd-sourced comparison of restored details and developed an objective assessment metric that outperforms other quality metrics by correlation with subjective scores for this task. In conclusion, we provide a deep analysis of benchmark results that yields insights for future SR-based work.
VALHALLA: Visual Hallucination for Machine Translation
May 31, 2022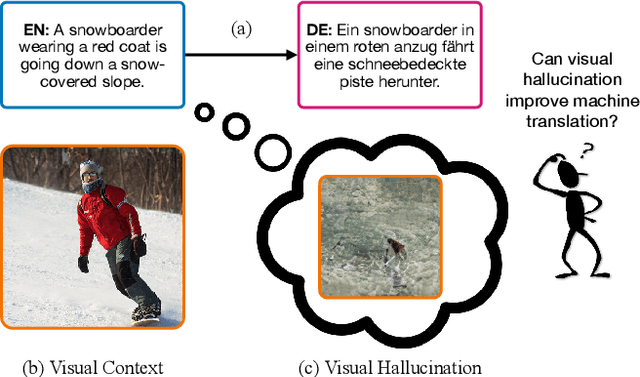
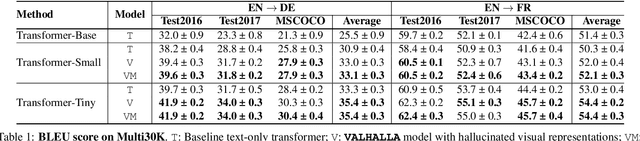
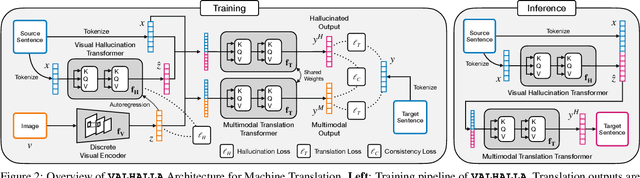
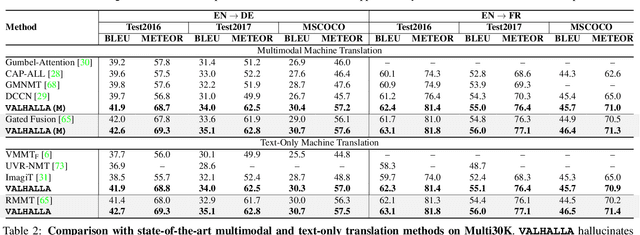
Designing better machine translation systems by considering auxiliary inputs such as images has attracted much attention in recent years. While existing methods show promising performance over the conventional text-only translation systems, they typically require paired text and image as input during inference, which limits their applicability to real-world scenarios. In this paper, we introduce a visual hallucination framework, called VALHALLA, which requires only source sentences at inference time and instead uses hallucinated visual representations for multimodal machine translation. In particular, given a source sentence an autoregressive hallucination transformer is used to predict a discrete visual representation from the input text, and the combined text and hallucinated representations are utilized to obtain the target translation. We train the hallucination transformer jointly with the translation transformer using standard backpropagation with cross-entropy losses while being guided by an additional loss that encourages consistency between predictions using either ground-truth or hallucinated visual representations. Extensive experiments on three standard translation datasets with a diverse set of language pairs demonstrate the effectiveness of our approach over both text-only baselines and state-of-the-art methods. Project page: http://www.svcl.ucsd.edu/projects/valhalla.
TL-GAN: Improving Traffic Light Recognition via Data Synthesis for Autonomous Driving
Mar 28, 2022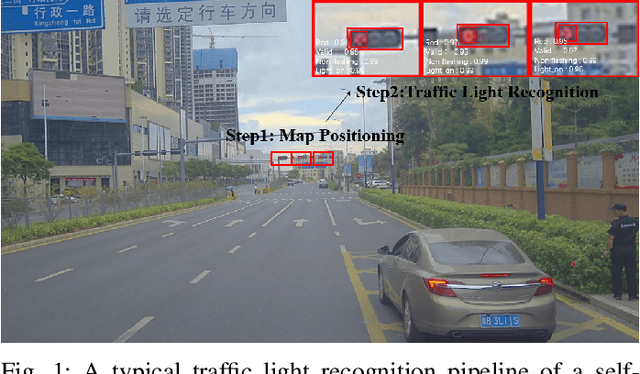
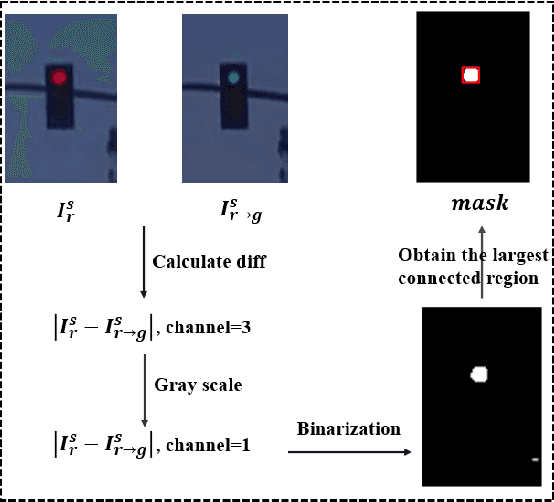


Traffic light recognition, as a critical component of the perception module of self-driving vehicles, plays a vital role in the intelligent transportation systems. The prevalent deep learning based traffic light recognition methods heavily hinge on the large quantity and rich diversity of training data. However, it is quite challenging to collect data in various rare scenarios such as flashing, blackout or extreme weather, thus resulting in the imbalanced distribution of training data and consequently the degraded performance in recognizing rare classes. In this paper, we seek to improve traffic light recognition by leveraging data synthesis. Inspired by the generative adversarial networks (GANs), we propose a novel traffic light generation approach TL-GAN to synthesize the data of rare classes to improve traffic light recognition for autonomous driving. TL-GAN disentangles traffic light sequence generation into image synthesis and sequence assembling. In the image synthesis stage, our approach enables conditional generation to allow full control of the color of the generated traffic light images. In the sequence assembling stage, we design the style mixing and adaptive template to synthesize realistic and diverse traffic light sequences. Extensive experiments show that the proposed TL-GAN renders remarkable improvement over the baseline without using the generated data, leading to the state-of-the-art performance in comparison with the competing algorithms that are used for general image synthesis and data imbalance tackling.
3DILG: Irregular Latent Grids for 3D Generative Modeling
May 27, 2022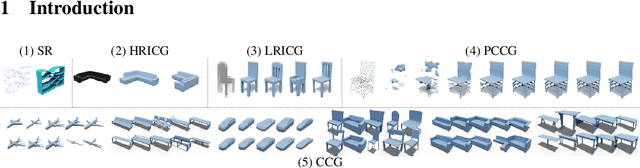

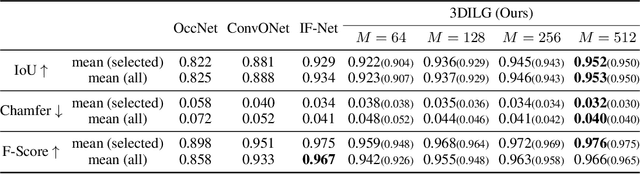
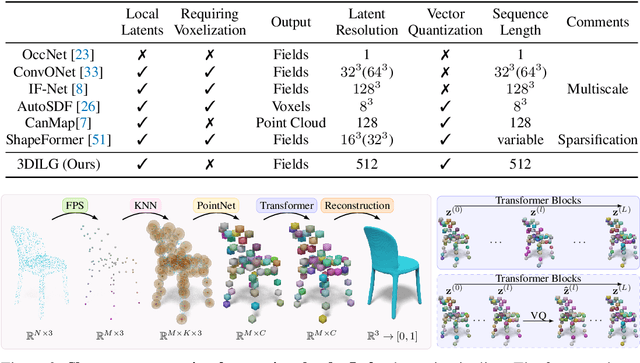
We propose a new representation for encoding 3D shapes as neural fields. The representation is designed to be compatible with the transformer architecture and to benefit both shape reconstruction and shape generation. Existing works on neural fields are grid-based representations with latents defined on a regular grid. In contrast, we define latents on irregular grids, enabling our representation to be sparse and adaptive. In the context of shape reconstruction from point clouds, our shape representation built on irregular grids improves upon grid-based methods in terms of reconstruction accuracy. For shape generation, our representation promotes high-quality shape generation using auto-regressive probabilistic models. We show different applications that improve over the current state of the art. First, we show results for probabilistic shape reconstruction from a single higher resolution image. Second, we train a probabilistic model conditioned on very low resolution images. Third, we apply our model to category-conditioned generation. All probabilistic experiments confirm that we are able to generate detailed and high quality shapes to yield the new state of the art in generative 3D shape modeling.