 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Probing Multimodal Large Language Models for Global and Local Semantic Representation
Feb 27, 2024
The success of large language models has inspired researchers to transfer their exceptional representing ability to other modalities. Several recent works leverage image-caption alignment datasets to train multimodal large language models (MLLMs), which achieve state-of-the-art performance on image-to-text tasks. However, there are very few studies exploring whether MLLMs truly understand the complete image information, i.e., global information, or if they can only capture some local object information. In this study, we find that the intermediate layers of models can encode more global semantic information, whose representation vectors perform better on visual-language entailment tasks, rather than the topmost layers. We further probe models for local semantic representation through object detection tasks. And we draw a conclusion that the topmost layers may excessively focus on local information, leading to a diminished ability to encode global information.
Physics-Informed Learning for Time-Resolved Angiographic Contrast Agent Concentration Reconstruction
Mar 04, 2024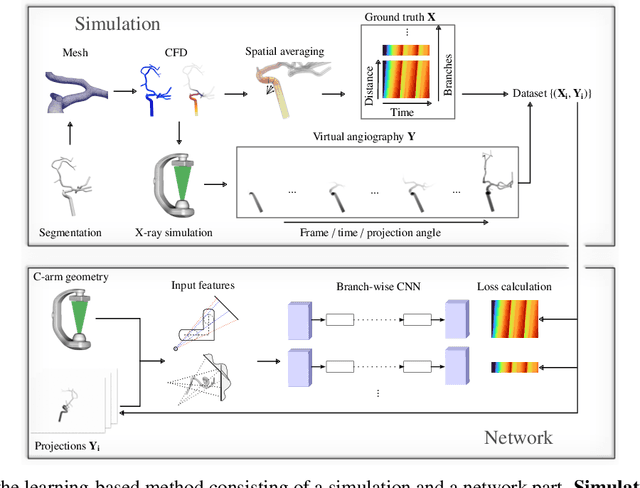
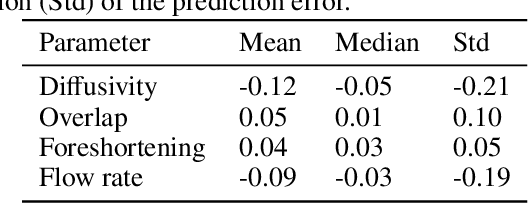
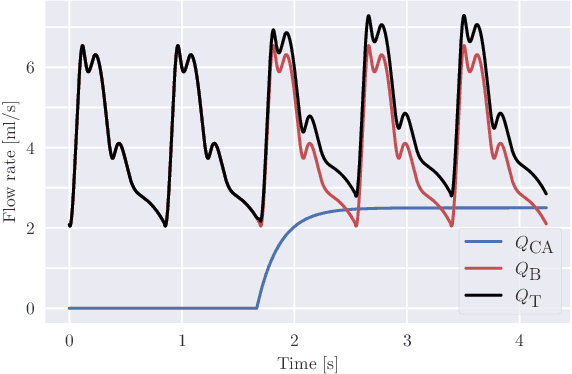
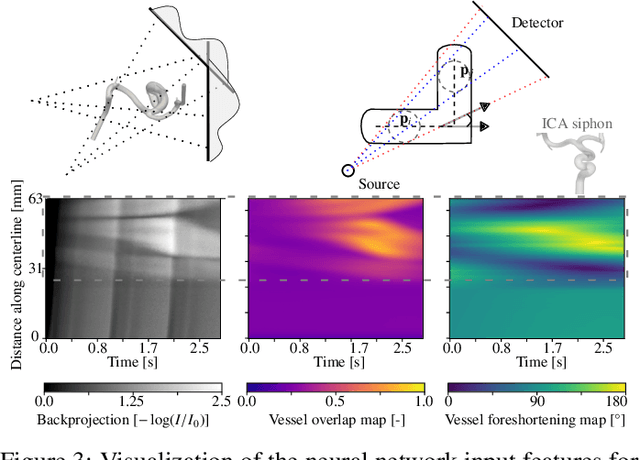
Three-dimensional Digital Subtraction Angiography (3D-DSA) is a well-established X-ray-based technique for visualizing vascular anatomy. Recently, four-dimensional DSA (4D-DSA) reconstruction algorithms have been developed to enable the visualization of volumetric contrast flow dynamics through time-series of volumes. . This reconstruction problem is ill-posed mainly due to vessel overlap in the projection direction and geometric vessel foreshortening, which leads to information loss in the recorded projection images. However, knowledge about the underlying fluid dynamics can be leveraged to constrain the solution space. In our work, we implicitly include this information in a neural network-based model that is trained on a dataset of image-based blood flow simulations. The model predicts the spatially averaged contrast agent concentration for each centerline point of the vasculature over time, lowering the overall computational demand. The trained network enables the reconstruction of relative contrast agent concentrations with a mean absolute error of 0.02 $\pm$ 0.02 and a mean absolute percentage error of 5.31 % $\pm$ 9.25 %. Moreover, the network is robust to varying degrees of vessel overlap and vessel foreshortening. Our approach demonstrates the potential of the integration of machine learning and blood flow simulations in time-resolved angiographic flow reconstruction.
U-shaped Vision Mamba for Single Image Dehazing
Feb 08, 2024Currently, Transformer is the most popular architecture for image dehazing, but due to its large computational complexity, its ability to handle long-range dependency is limited on resource-constrained devices. To tackle this challenge, we introduce the U-shaped Vision Mamba (UVM-Net), an efficient single-image dehazing network. Inspired by the State Space Sequence Models (SSMs), a new deep sequence model known for its power to handle long sequences, we design a Bi-SSM block that integrates the local feature extraction ability of the convolutional layer with the ability of the SSM to capture long-range dependencies. Extensive experimental results demonstrate the effectiveness of our method. Our method provides a more highly efficient idea of long-range dependency modeling for image dehazing as well as other image restoration tasks. The URL of the code is \url{https://github.com/zzr-idam/UVM-Net}. Our method takes only \textbf{0.009} seconds to infer a $325 \times 325$ resolution image (100FPS) without I/O handling time.
MovieLLM: Enhancing Long Video Understanding with AI-Generated Movies
Mar 03, 2024
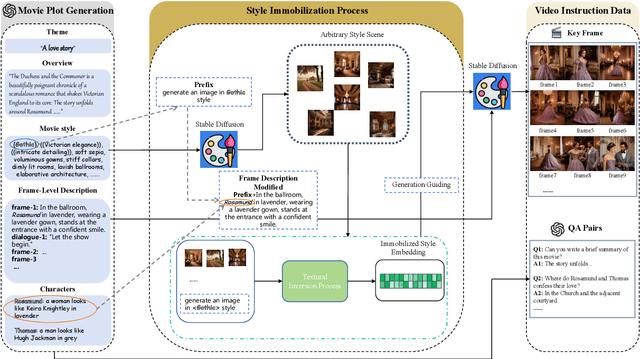
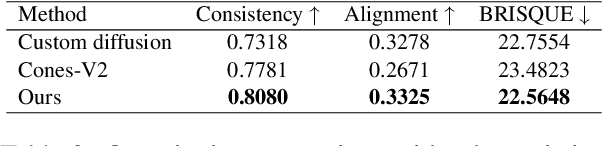
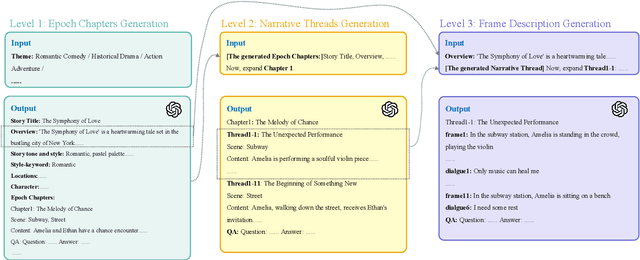
The development of multimodal models has marked a significant step forward in how machines understand videos. These models have shown promise in analyzing short video clips. However, when it comes to longer formats like movies, they often fall short. The main hurdles are the lack of high-quality, diverse video data and the intensive work required to collect or annotate such data. In the face of these challenges, we propose MovieLLM, a novel framework designed to create synthetic, high-quality data for long videos. This framework leverages the power of GPT-4 and text-to-image models to generate detailed scripts and corresponding visuals. Our approach stands out for its flexibility and scalability, making it a superior alternative to traditional data collection methods. Our extensive experiments validate that the data produced by MovieLLM significantly improves the performance of multimodal models in understanding complex video narratives, overcoming the limitations of existing datasets regarding scarcity and bias.
What Is Missing in Multilingual Visual Reasoning and How to Fix It
Mar 03, 2024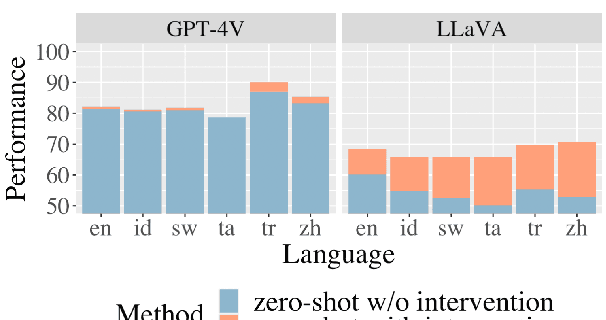
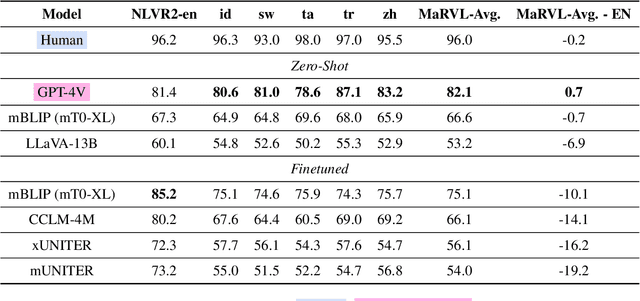

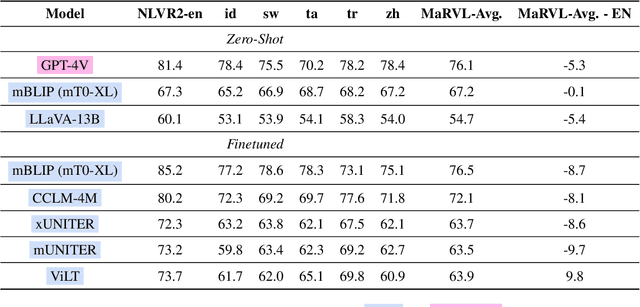
NLP models today strive for supporting multiple languages and modalities, improving accessibility for diverse users. In this paper, we evaluate their multilingual, multimodal capabilities by testing on a visual reasoning task. We observe that proprietary systems like GPT-4V obtain the best performance on this task now, but open models lag in comparison. Surprisingly, GPT-4V exhibits similar performance between English and other languages, indicating the potential for equitable system development across languages. Our analysis on model failures reveals three key aspects that make this task challenging: multilinguality, complex reasoning, and multimodality. To address these challenges, we propose three targeted interventions including a translate-test approach to tackle multilinguality, a visual programming approach to break down complex reasoning, and a novel method that leverages image captioning to address multimodality. Our interventions achieve the best open performance on this task in a zero-shot setting, boosting open model LLaVA by 13.4%, while also minorly improving GPT-4V's performance.
LUM-ViT: Learnable Under-sampling Mask Vision Transformer for Bandwidth Limited Optical Signal Acquisition
Mar 03, 2024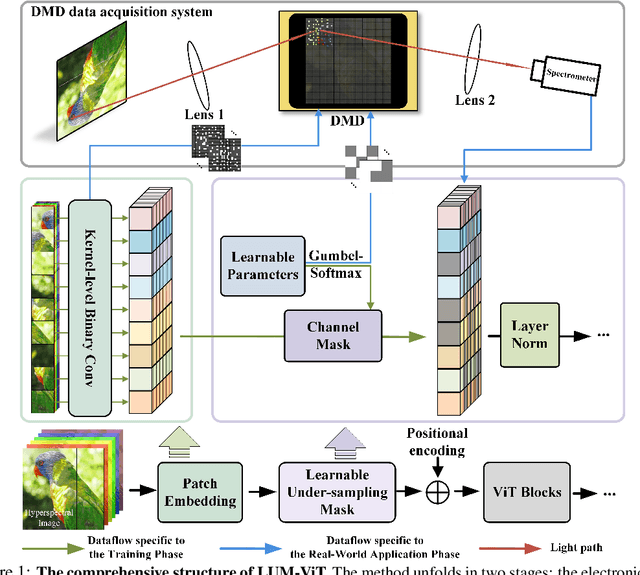

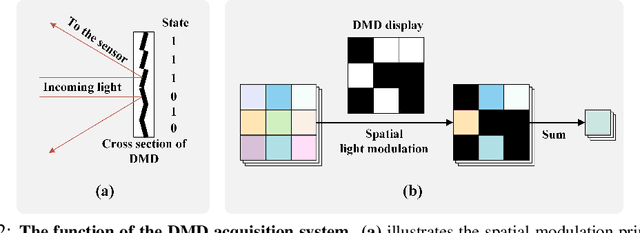
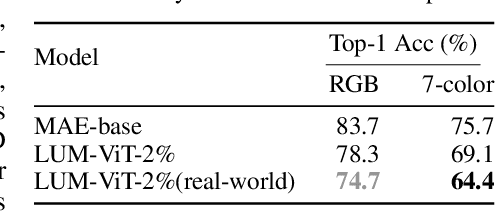
Bandwidth constraints during signal acquisition frequently impede real-time detection applications. Hyperspectral data is a notable example, whose vast volume compromises real-time hyperspectral detection. To tackle this hurdle, we introduce a novel approach leveraging pre-acquisition modulation to reduce the acquisition volume. This modulation process is governed by a deep learning model, utilizing prior information. Central to our approach is LUM-ViT, a Vision Transformer variant. Uniquely, LUM-ViT incorporates a learnable under-sampling mask tailored for pre-acquisition modulation. To further optimize for optical calculations, we propose a kernel-level weight binarization technique and a three-stage fine-tuning strategy. Our evaluations reveal that, by sampling a mere 10% of the original image pixels, LUM-ViT maintains the accuracy loss within 1.8% on the ImageNet classification task. The method sustains near-original accuracy when implemented on real-world optical hardware, demonstrating its practicality. Code will be available at https://github.com/MaxLLF/LUM-ViT.
Prompt-Driven Dynamic Object-Centric Learning for Single Domain Generalization
Feb 28, 2024Single-domain generalization aims to learn a model from single source domain data to achieve generalized performance on other unseen target domains. Existing works primarily focus on improving the generalization ability of static networks. However, static networks are unable to dynamically adapt to the diverse variations in different image scenes, leading to limited generalization capability. Different scenes exhibit varying levels of complexity, and the complexity of images further varies significantly in cross-domain scenarios. In this paper, we propose a dynamic object-centric perception network based on prompt learning, aiming to adapt to the variations in image complexity. Specifically, we propose an object-centric gating module based on prompt learning to focus attention on the object-centric features guided by the various scene prompts. Then, with the object-centric gating masks, the dynamic selective module dynamically selects highly correlated feature regions in both spatial and channel dimensions enabling the model to adaptively perceive object-centric relevant features, thereby enhancing the generalization capability. Extensive experiments were conducted on single-domain generalization tasks in image classification and object detection. The experimental results demonstrate that our approach outperforms state-of-the-art methods, which validates the effectiveness and generally of our proposed method.
Impression-CLIP: Contrastive Shape-Impression Embedding for Fonts
Feb 26, 2024Fonts convey different impressions to readers. These impressions often come from the font shapes. However, the correlation between fonts and their impression is weak and unstable because impressions are subjective. To capture such weak and unstable cross-modal correlation between font shapes and their impressions, we propose Impression-CLIP, which is a novel machine-learning model based on CLIP (Contrastive Language-Image Pre-training). By using the CLIP-based model, font image features and their impression features are pulled closer, and font image features and unrelated impression features are pushed apart. This procedure realizes co-embedding between font image and their impressions. In our experiment, we perform cross-modal retrieval between fonts and impressions through co-embedding. The results indicate that Impression-CLIP achieves better retrieval accuracy than the state-of-the-art method. Additionally, our model shows the robustness to noise and missing tags.
Simulation of Muon Tomography Projections to Image the Pyramids of Giza
Feb 27, 2024Purpose: A geometric simulation of a possible two-plane detector was developed to test the abilities of the detector to generate high-resolution images of the Great Pyramid using muon tomography. Methods and Materials: Trajectory range, angular resolution, and acceptance of the detector were calculated with a simulation. Trajectories and the corresponding sinogram space covered were simulated first with one detector in one location, and then two moving detectors on adjacent sides of the pyramid. The resolution at the center slice of the pyramid was calculated using the angular resolution of the detector. Results: The simulation returned trajectory range encompassing the pyramid and peak angular resolution of .0004sr. Sinogram space covered by one position was inadequate, however two moving detectors on adjacent sides of the pyramid cover a significant portion. Resolution at the center of the pyramid is roughly 3m. Conclusions: The simulation provides a way to calculate the detector positions needed to cover an adequate amount of sinogram space for high-resolution cosmic-ray tomographic reconstruction of the Great Pyramids. Key Words: high-resolution muon tomography, one-sided tomography, sinogram simulation, detector simulation
Decompose-and-Compose: A Compositional Approach to Mitigating Spurious Correlation
Feb 29, 2024While standard Empirical Risk Minimization (ERM) training is proven effective for image classification on in-distribution data, it fails to perform well on out-of-distribution samples. One of the main sources of distribution shift for image classification is the compositional nature of images. Specifically, in addition to the main object or component(s) determining the label, some other image components usually exist, which may lead to the shift of input distribution between train and test environments. More importantly, these components may have spurious correlations with the label. To address this issue, we propose Decompose-and-Compose (DaC), which improves robustness to correlation shift by a compositional approach based on combining elements of images. Based on our observations, models trained with ERM usually highly attend to either the causal components or the components having a high spurious correlation with the label (especially in datapoints on which models have a high confidence). In fact, according to the amount of spurious correlation and the easiness of classification based on the causal or non-causal components, the model usually attends to one of these more (on samples with high confidence). Following this, we first try to identify the causal components of images using class activation maps of models trained with ERM. Afterward, we intervene on images by combining them and retraining the model on the augmented data, including the counterfactual ones. Along with its high interpretability, this work proposes a group-balancing method by intervening on images without requiring group labels or information regarding the spurious features during training. The method has an overall better worst group accuracy compared to previous methods with the same amount of supervision on the group labels in correlation shift.