 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Contrastive Hashing for Cross-Modal Retrieval in Remote Sensing
Apr 19, 2022
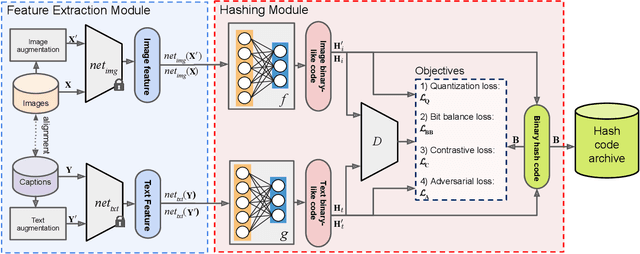
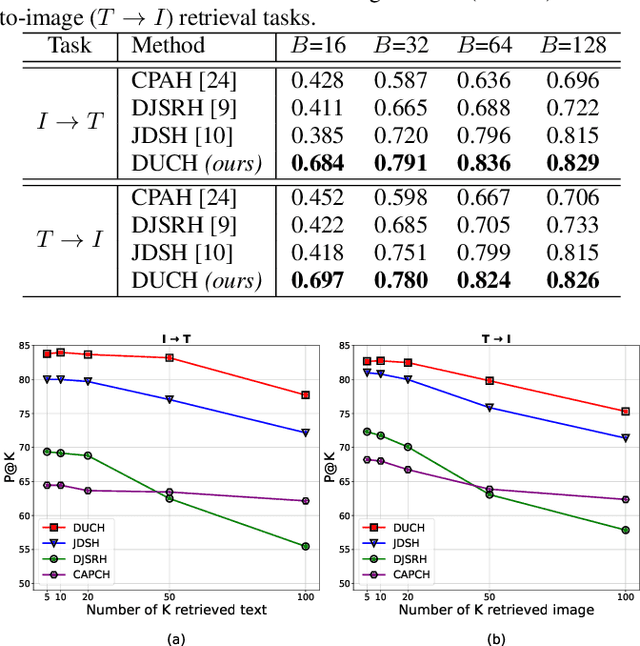

The development of cross-modal retrieval systems that can search and retrieve semantically relevant data across different modalities based on a query in any modality has attracted great attention in remote sensing (RS). In this paper, we focus our attention on cross-modal text-image retrieval, where queries from one modality (e.g., text) can be matched to archive entries from another (e.g., image). Most of the existing cross-modal text-image retrieval systems in RS require a high number of labeled training samples and also do not allow fast and memory-efficient retrieval. These issues limit the applicability of the existing cross-modal retrieval systems for large-scale applications in RS. To address this problem, in this paper we introduce a novel unsupervised cross-modal contrastive hashing (DUCH) method for text-image retrieval in RS. To this end, the proposed DUCH is made up of two main modules: 1) feature extraction module, which extracts deep representations of two modalities; 2) hashing module that learns to generate cross-modal binary hash codes from the extracted representations. We introduce a novel multi-objective loss function including: i) contrastive objectives that enable similarity preservation in intra- and inter-modal similarities; ii) an adversarial objective that is enforced across two modalities for cross-modal representation consistency; and iii) binarization objectives for generating hash codes. Experimental results show that the proposed DUCH outperforms state-of-the-art methods. Our code is publicly available at https://git.tu-berlin.de/rsim/duch.
Experimenting with Self-Supervision using Rotation Prediction for Image Captioning
Jul 28, 2021

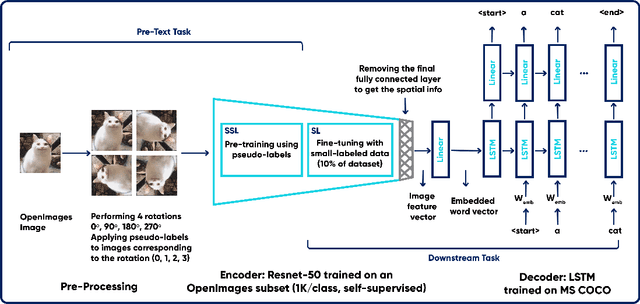

Image captioning is a task in the field of Artificial Intelligence that merges between computer vision and natural language processing. It is responsible for generating legends that describe images, and has various applications like descriptions used by assistive technology or indexing images (for search engines for instance). This makes it a crucial topic in AI that is undergoing a lot of research. This task however, like many others, is trained on large images labeled via human annotation, which can be very cumbersome: it needs manual effort, both financial and temporal costs, it is error-prone and potentially difficult to execute in some cases (e.g. medical images). To mitigate the need for labels, we attempt to use self-supervised learning, a type of learning where models use the data contained within the images themselves as labels. It is challenging to accomplish though, since the task is two-fold: the images and captions come from two different modalities and usually handled by different types of networks. It is thus not obvious what a completely self-supervised solution would look like. How it would achieve captioning in a comparable way to how self-supervision is applied today on image recognition tasks is still an ongoing research topic. In this project, we are using an encoder-decoder architecture where the encoder is a convolutional neural network (CNN) trained on OpenImages dataset and learns image features in a self-supervised fashion using the rotation pretext task. The decoder is a Long Short-Term Memory (LSTM), and it is trained, along within the image captioning model, on MS COCO dataset and is responsible of generating captions. Our GitHub repository can be found: https://github.com/elhagry1/SSL_ImageCaptioning_RotationPrediction
A Feature Consistency Driven Attention Erasing Network for Fine-Grained Image Retrieval
Oct 09, 2021
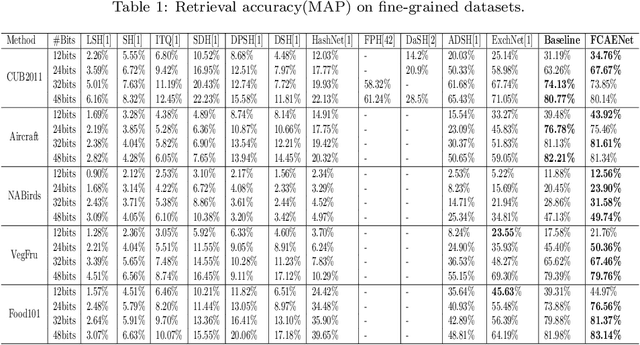
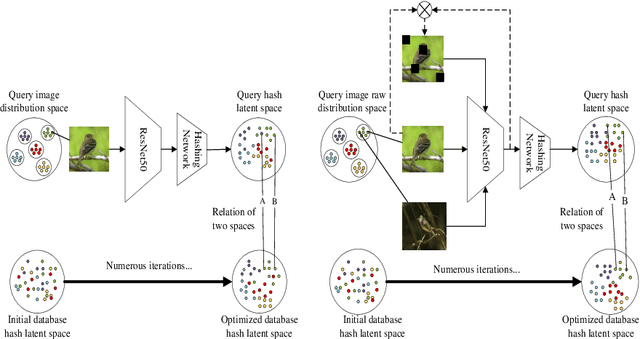
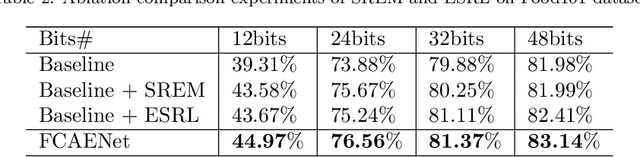
Large-scale fine-grained image retrieval has two main problems. First, low dimensional feature embedding can fasten the retrieval process but bring accuracy reduce due to overlooking the feature of significant attention regions of images in fine-grained datasets. Second, fine-grained images lead to the same category query hash codes mapping into the different cluster in database hash latent space. To handle these two issues, we propose a feature consistency driven attention erasing network (FCAENet) for fine-grained image retrieval. For the first issue, we propose an adaptive augmentation module in FCAENet, which is selective region erasing module (SREM). SREM makes the network more robust on subtle differences of fine-grained task by adaptively covering some regions of raw images. The feature extractor and hash layer can learn more representative hash code for fine-grained images by SREM. With regard to the second issue, we fully exploit the pair-wise similarity information and add the enhancing space relation loss (ESRL) in FCAENet to make the vulnerable relation stabler between the query hash code and database hash code. We conduct extensive experiments on five fine-grained benchmark datasets (CUB2011, Aircraft, NABirds, VegFru, Food101) for 12bits, 24bits, 32bits, 48bits hash code. The results show that FCAENet achieves the state-of-the-art (SOTA) fine-grained retrieval performance compared with other methods.
Fluorescent wavefront shaping using incoherent iterative phase conjugation
May 15, 2022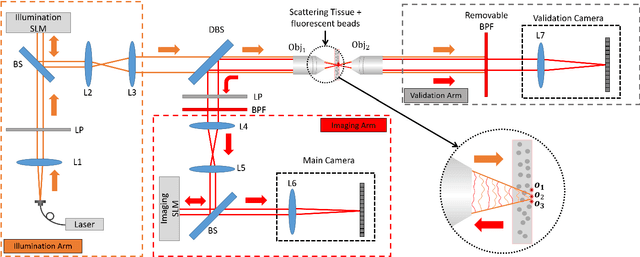
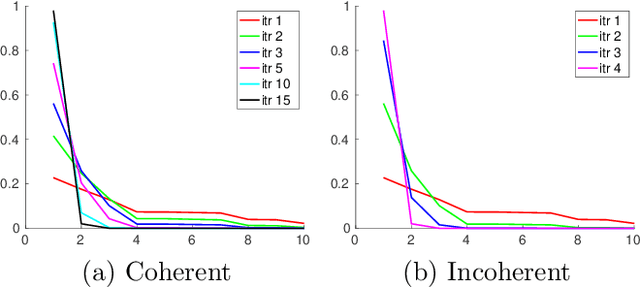


Wavefront shaping correction makes it possible to image fluorescent particles deep inside scattering tissue. This requires determining a correction mask to be placed in both excitation and emission paths. Standard approaches select correction masks by optimizing various image metrics, a process that requires capturing a prohibitively large number of images. To reduce acquisition cost, iterative phase conjugation techniques use the observation that the desired correction mask is an eigenvector of the tissue transmission operator. They then determine this eigenvector via optical implementations of the power iteration method, which require capturing orders of magnitude fewer images. Existing iterative phase conjugation techniques assume a linear model for the transmission of light through tissue, and thus only apply to fully-coherent imaging systems. We extend such techniques to the incoherent case for the first time. The fact that light emitted from different sources sums incoherently violates the linear model and makes linear transmission operators inapplicable. We show that, surprisingly, the non-linearity due to incoherent summation results in an order-of-magnitude acceleration in the convergence of the phase conjugation iteration.
A Semantic Indexing Structure for Image Retrieval
Sep 14, 2021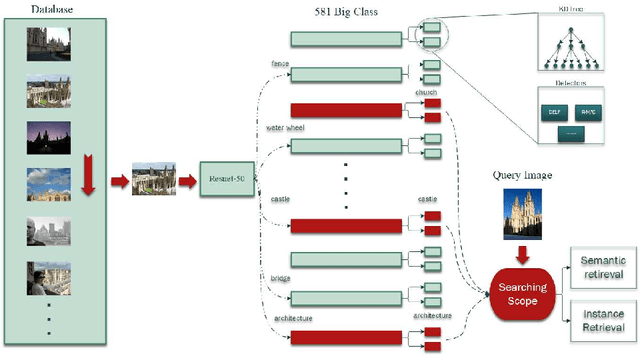
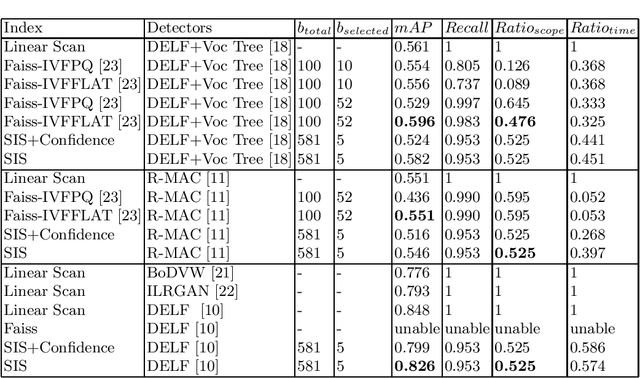
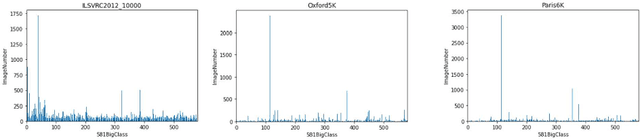

In large-scale image retrieval, many indexing methods have been proposed to narrow down the searching scope of retrieval. The features extracted from images usually are of high dimensions or unfixed sizes due to the existence of key points. Most of existing index structures suffer from the dimension curse, the unfixed feature size and/or the loss of semantic similarity. In this paper a new classification-based indexing structure, called Semantic Indexing Structure (SIS), is proposed, in which we utilize the semantic categories rather than clustering centers to create database partitions, such that the proposed index SIS can be combined with feature extractors without the restriction of dimensions. Besides, it is observed that the size of each semantic partition is positively correlated with the semantic distribution of database. Along this way, we found that when the partition number is normalized to five, the proposed algorithm performed very well in all the tests. Compared with state-of-the-art models, SIS achieves outstanding performance.
Incremental Learning Meets Transfer Learning: Application to Multi-site Prostate MRI Segmentation
Jun 03, 2022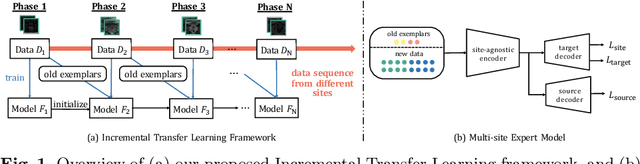

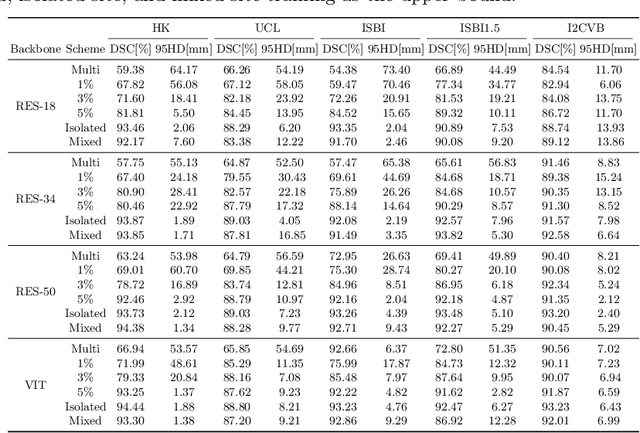
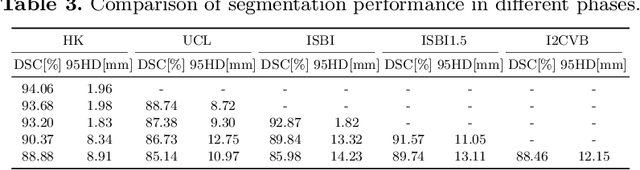
Many medical datasets have recently been created for medical image segmentation tasks, and it is natural to question whether we can use them to sequentially train a single model that (1) performs better on all these datasets, and (2) generalizes well and transfers better to the unknown target site domain. Prior works have achieved this goal by jointly training one model on multi-site datasets, which achieve competitive performance on average but such methods rely on the assumption about the availability of all training data, thus limiting its effectiveness in practical deployment. In this paper, we propose a novel multi-site segmentation framework called incremental-transfer learning (ITL), which learns a model from multi-site datasets in an end-to-end sequential fashion. Specifically, "incremental" refers to training sequentially constructed datasets, and "transfer" is achieved by leveraging useful information from the linear combination of embedding features on each dataset. In addition, we introduce our ITL framework, where we train the network including a site-agnostic encoder with pre-trained weights and at most two segmentation decoder heads. We also design a novel site-level incremental loss in order to generalize well on the target domain. Second, we show for the first time that leveraging our ITL training scheme is able to alleviate challenging catastrophic forgetting problems in incremental learning. We conduct experiments using five challenging benchmark datasets to validate the effectiveness of our incremental-transfer learning approach. Our approach makes minimal assumptions on computation resources and domain-specific expertise, and hence constitutes a strong starting point in multi-site medical image segmentation.
Improving Semantic Image Segmentation via Label Fusion in Semantically Textured Meshes
Nov 22, 2021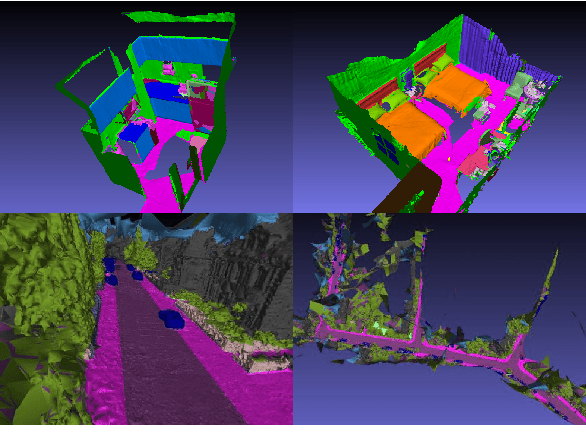

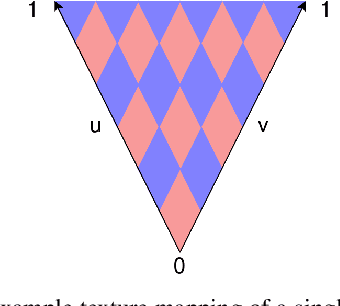
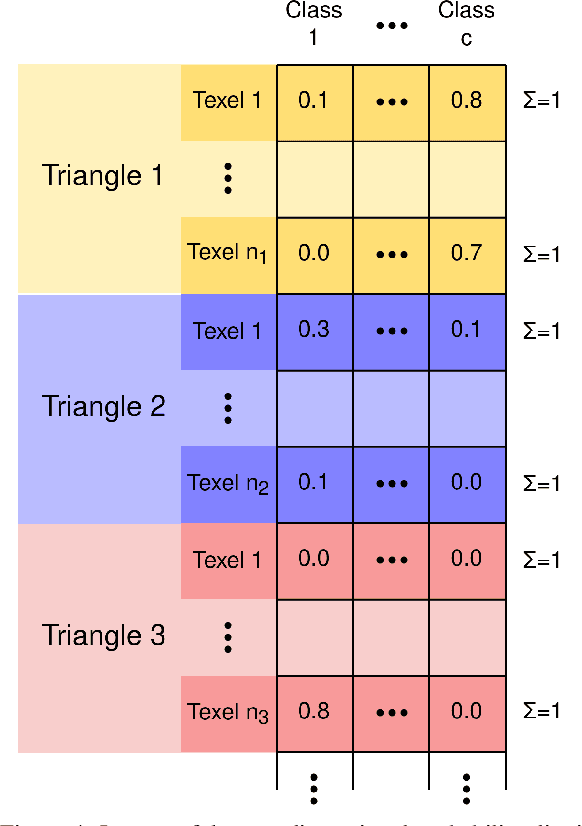
Models for semantic segmentation require a large amount of hand-labeled training data which is costly and time-consuming to produce. For this purpose, we present a label fusion framework that is capable of improving semantic pixel labels of video sequences in an unsupervised manner. We make use of a 3D mesh representation of the environment and fuse the predictions of different frames into a consistent representation using semantic mesh textures. Rendering the semantic mesh using the original intrinsic and extrinsic camera parameters yields a set of improved semantic segmentation images. Due to our optimized CUDA implementation, we are able to exploit the entire $c$-dimensional probability distribution of annotations over $c$ classes in an uncertainty-aware manner. We evaluate our method on the Scannet dataset where we improve annotations produced by the state-of-the-art segmentation network ESANet from $52.05 \%$ to $58.25 \%$ pixel accuracy. We publish the source code of our framework online to foster future research in this area (\url{https://github.com/fferflo/semantic-meshes}). To the best of our knowledge, this is the first publicly available label fusion framework for semantic image segmentation based on meshes with semantic textures.
A Practical Contrastive Learning Framework for Single Image Super-Resolution
Nov 27, 2021
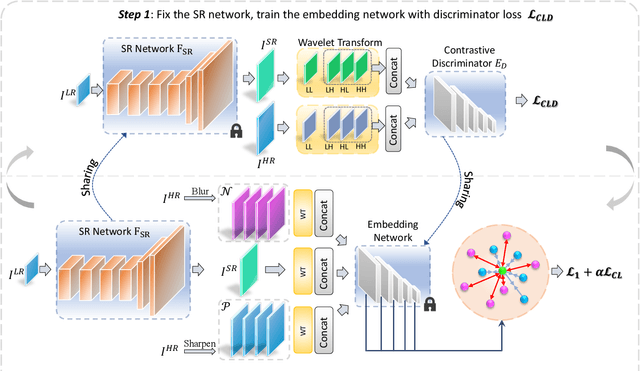

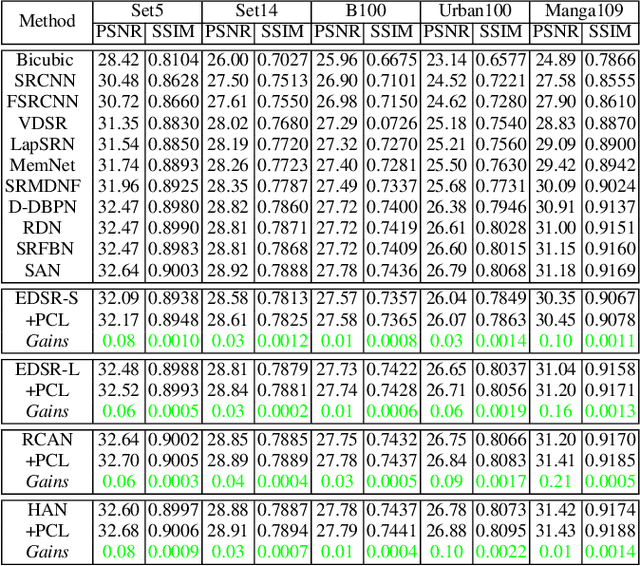
Contrastive learning has achieved remarkable success on various high-level tasks, but there are fewer methods proposed for low-level tasks. It is challenging to adopt vanilla contrastive learning technologies proposed for high-level visual tasks straight to low-level visual tasks since the acquired global visual representations are insufficient for low-level tasks requiring rich texture and context information. In this paper, we propose a novel contrastive learning framework for single image super-resolution (SISR). We investigate the contrastive learning-based SISR from two perspectives: sample construction and feature embedding. The existing methods propose some naive sample construction approaches (e.g., considering the low-quality input as a negative sample and the ground truth as a positive sample) and they adopt a prior model (e.g., pre-trained VGG model) to obtain the feature embedding instead of exploring a task-friendly one. To this end, we propose a practical contrastive learning framework for SISR that involves the generation of many informative positive and hard negative samples in frequency space. Instead of utilizing an additional pre-trained network, we design a simple but effective embedding network inherited from the discriminator network and can be iteratively optimized with the primary SR network making it task-generalizable. Finally, we conduct an extensive experimental evaluation of our method compared with benchmark methods and show remarkable gains of up to 0.21 dB over the current state-of-the-art approaches for SISR.
AnyFace: Free-style Text-to-Face Synthesis and Manipulation
Mar 29, 2022
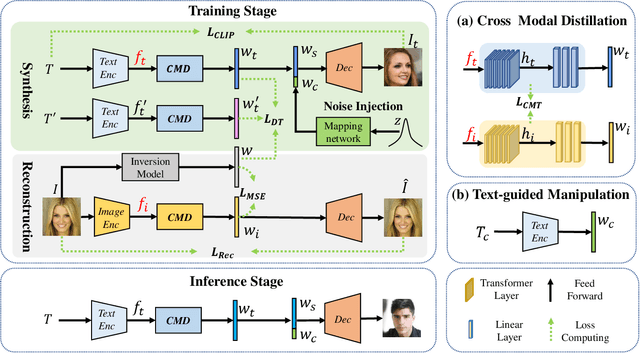
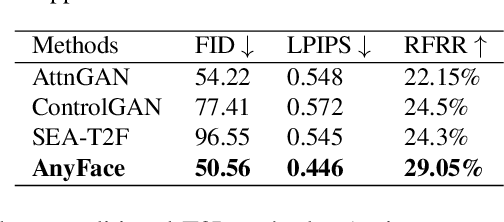
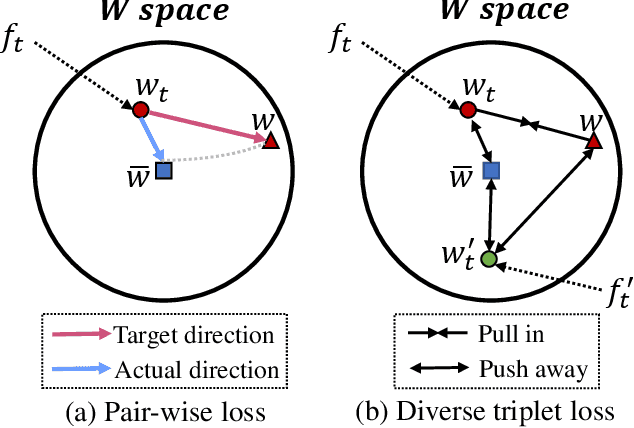
Existing text-to-image synthesis methods generally are only applicable to words in the training dataset. However, human faces are so variable to be described with limited words. So this paper proposes the first free-style text-to-face method namely AnyFace enabling much wider open world applications such as metaverse, social media, cosmetics, forensics, etc. AnyFace has a novel two-stream framework for face image synthesis and manipulation given arbitrary descriptions of the human face. Specifically, one stream performs text-to-face generation and the other conducts face image reconstruction. Facial text and image features are extracted using the CLIP (Contrastive Language-Image Pre-training) encoders. And a collaborative Cross Modal Distillation (CMD) module is designed to align the linguistic and visual features across these two streams. Furthermore, a Diverse Triplet Loss (DT loss) is developed to model fine-grained features and improve facial diversity. Extensive experiments on Multi-modal CelebA-HQ and CelebAText-HQ demonstrate significant advantages of AnyFace over state-of-the-art methods. AnyFace can achieve high-quality, high-resolution, and high-diversity face synthesis and manipulation results without any constraints on the number and content of input captions.
Nonparametric clustering for image segmentation
Jan 20, 2021
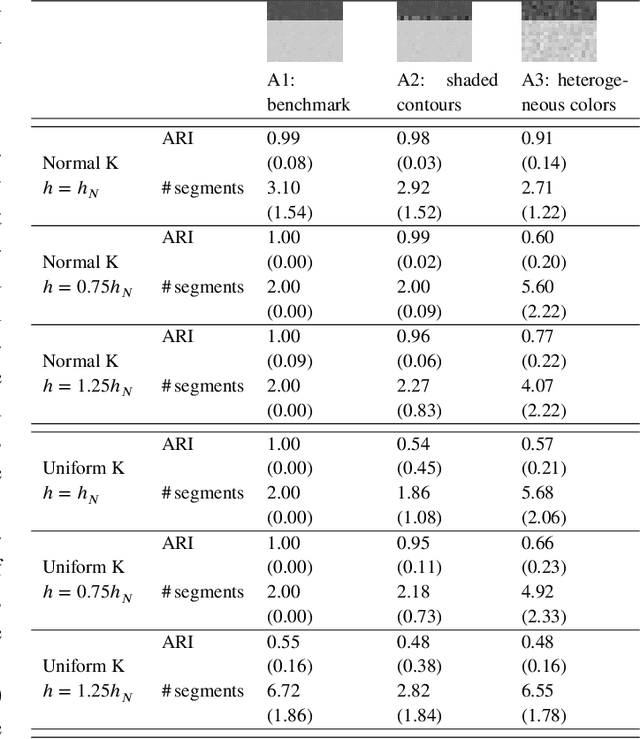

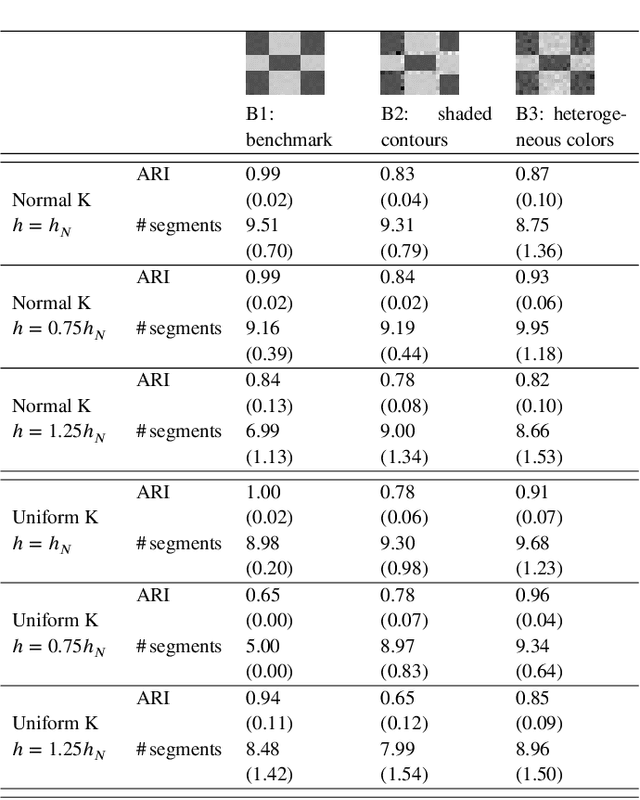
Image segmentation aims at identifying regions of interest within an image, by grouping pixels according to their properties. This task resembles the statistical one of clustering, yet many standard clustering methods fail to meet the basic requirements of image segmentation: segment shapes are often biased toward predetermined shapes and their number is rarely determined automatically. Nonparametric clustering is, in principle, free from these limitations and turns out to be particularly suitable for the task of image segmentation. This is also witnessed by several operational analogies, as, for instance, the resort to topological data analysis and spatial tessellation in both the frameworks. We discuss the application of nonparametric clustering to image segmentation and provide an algorithm specific for this task. Pixel similarity is evaluated in terms of density of the color representation and the adjacency structure of the pixels is exploited to introduce a simple, yet effective method to identify image segments as disconnected high-density regions. The proposed method works both to segment an image and to detect its boundaries and can be seen as a generalization to color images of the class of thresholding methods.