 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Practical Contrastive Learning Framework for Single Image Super-Resolution
Paper and Code

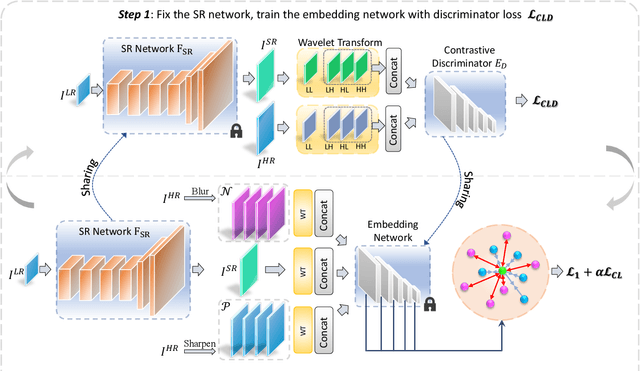

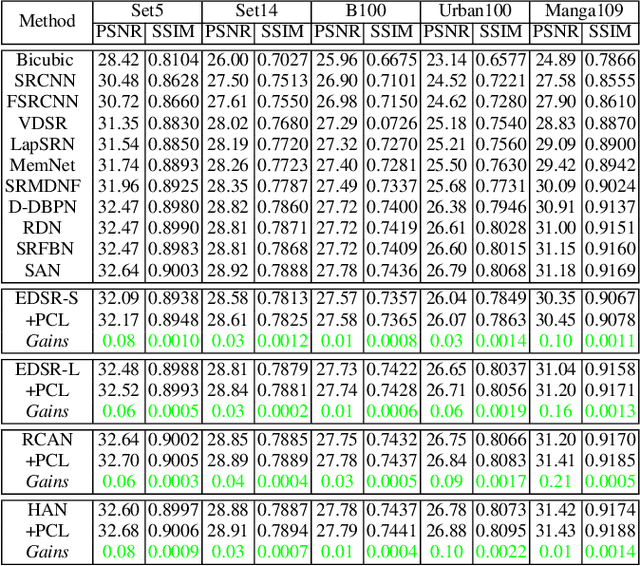
Contrastive learning has achieved remarkable success on various high-level tasks, but there are fewer methods proposed for low-level tasks. It is challenging to adopt vanilla contrastive learning technologies proposed for high-level visual tasks straight to low-level visual tasks since the acquired global visual representations are insufficient for low-level tasks requiring rich texture and context information. In this paper, we propose a novel contrastive learning framework for single image super-resolution (SISR). We investigate the contrastive learning-based SISR from two perspectives: sample construction and feature embedding. The existing methods propose some naive sample construction approaches (e.g., considering the low-quality input as a negative sample and the ground truth as a positive sample) and they adopt a prior model (e.g., pre-trained VGG model) to obtain the feature embedding instead of exploring a task-friendly one. To this end, we propose a practical contrastive learning framework for SISR that involves the generation of many informative positive and hard negative samples in frequency space. Instead of utilizing an additional pre-trained network, we design a simple but effective embedding network inherited from the discriminator network and can be iteratively optimized with the primary SR network making it task-generalizable. Finally, we conduct an extensive experimental evaluation of our method compared with benchmark methods and show remarkable gains of up to 0.21 dB over the current state-of-the-art approaches for SISR.