 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Eight Years of Face Recognition Research: Reproducibility, Achievements and Open Issues
Aug 08, 2022
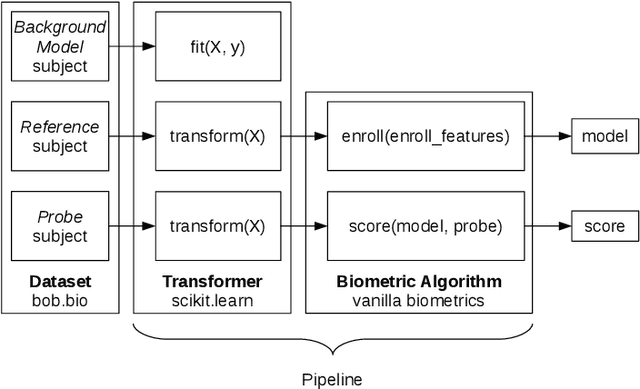
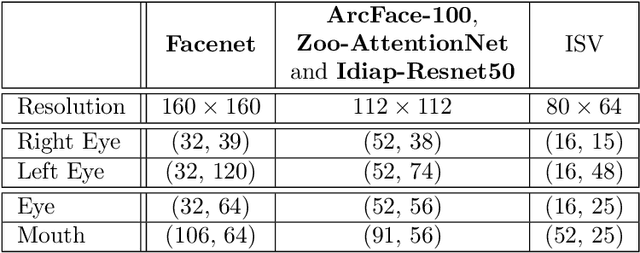

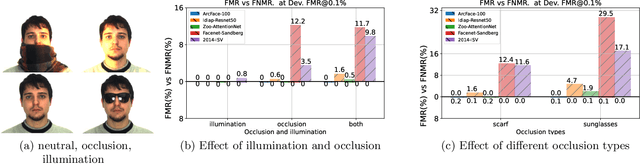
Automatic face recognition is a research area with high popularity. Many different face recognition algorithms have been proposed in the last thirty years of intensive research in the field. With the popularity of deep learning and its capability to solve a huge variety of different problems, face recognition researchers have concentrated effort on creating better models under this paradigm. From the year 2015, state-of-the-art face recognition has been rooted in deep learning models. Despite the availability of large-scale and diverse datasets for evaluating the performance of face recognition algorithms, many of the modern datasets just combine different factors that influence face recognition, such as face pose, occlusion, illumination, facial expression and image quality. When algorithms produce errors on these datasets, it is not clear which of the factors has caused this error and, hence, there is no guidance in which direction more research is required. This work is a followup from our previous works developed in 2014 and eventually published in 2016, showing the impact of various facial aspects on face recognition algorithms. By comparing the current state-of-the-art with the best systems from the past, we demonstrate that faces under strong occlusions, some types of illumination, and strong expressions are problems mastered by deep learning algorithms, whereas recognition with low-resolution images, extreme pose variations, and open-set recognition is still an open problem. To show this, we run a sequence of experiments using six different datasets and five different face recognition algorithms in an open-source and reproducible manner. We provide the source code to run all of our experiments, which is easily extensible so that utilizing your own deep network in our evaluation is just a few minutes away.
Intrusion Detection: Machine Learning Baseline Calculations for Image Classification
Nov 03, 2021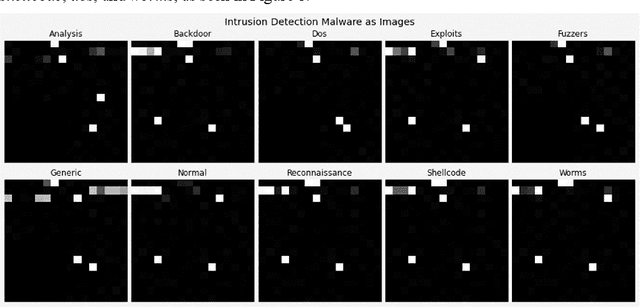
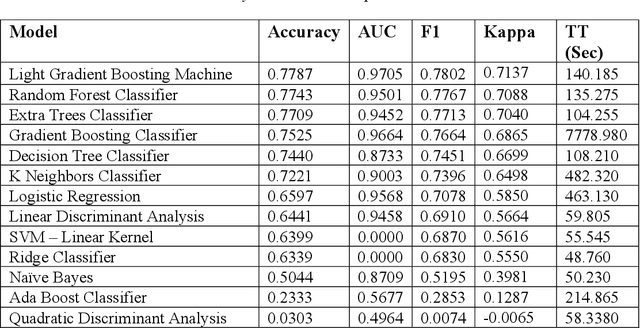
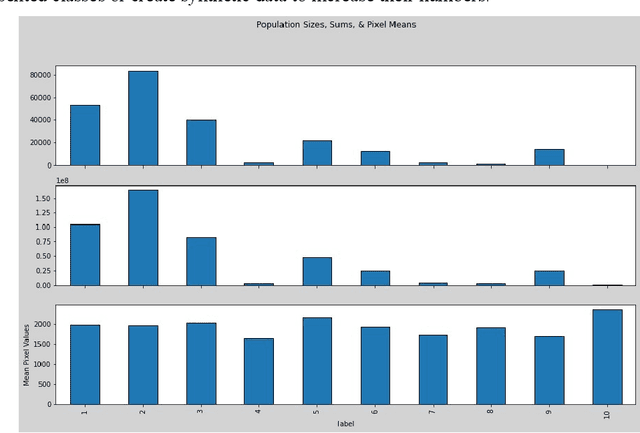

Cyber security can be enhanced through application of machine learning by recasting network attack data into an image format, then applying supervised computer vision and other machine learning techniques to detect malicious specimens. Exploratory data analysis reveals little correlation and few distinguishing characteristics between the ten classes of malware used in this study. A general model comparison demonstrates that the most promising candidates for consideration are Light Gradient Boosting Machine, Random Forest Classifier, and Extra Trees Classifier. Convolutional networks fail to deliver their outstanding classification ability, being surpassed by a simple, fully connected architecture. Most tests fail to break 80% categorical accuracy and present low F1 scores, indicating more sophisticated approaches (e.g., bootstrapping, random samples, and feature selection) may be required to maximize performance.
Omni3D: A Large Benchmark and Model for 3D Object Detection in the Wild
Jul 21, 2022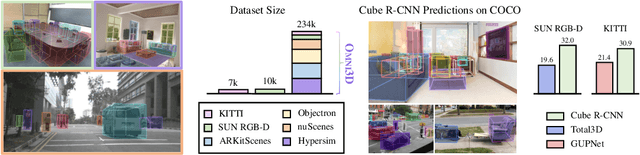
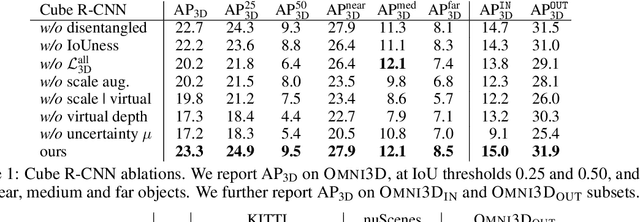
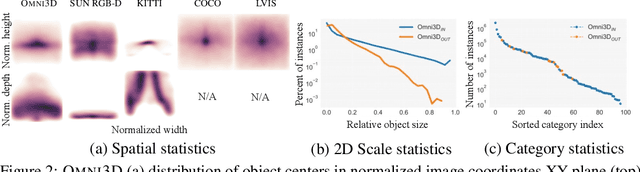
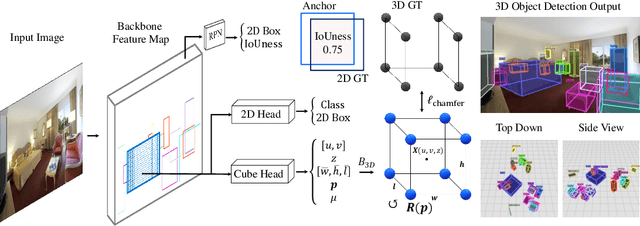
Recognizing scenes and objects in 3D from a single image is a longstanding goal of computer vision with applications in robotics and AR/VR. For 2D recognition, large datasets and scalable solutions have led to unprecedented advances. In 3D, existing benchmarks are small in size and approaches specialize in few object categories and specific domains, e.g. urban driving scenes. Motivated by the success of 2D recognition, we revisit the task of 3D object detection by introducing a large benchmark, called Omni3D. Omni3D re-purposes and combines existing datasets resulting in 234k images annotated with more than 3 million instances and 97 categories.3D detection at such scale is challenging due to variations in camera intrinsics and the rich diversity of scene and object types. We propose a model, called Cube R-CNN, designed to generalize across camera and scene types with a unified approach. We show that Cube R-CNN outperforms prior works on the larger Omni3D and existing benchmarks. Finally, we prove that Omni3D is a powerful dataset for 3D object recognition, show that it improves single-dataset performance and can accelerate learning on new smaller datasets via pre-training.
Supervised laser-speckle image sampling of skin tissue to detect very early stage of diabetes by its effects on skin subcellular properties
Dec 18, 2021
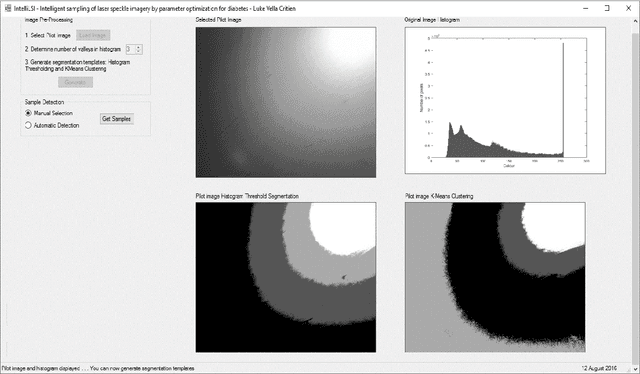
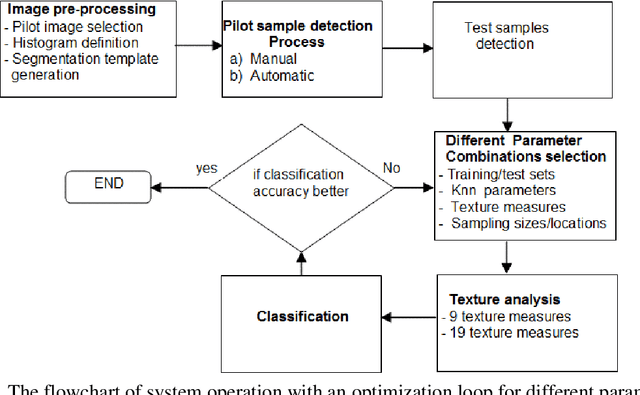
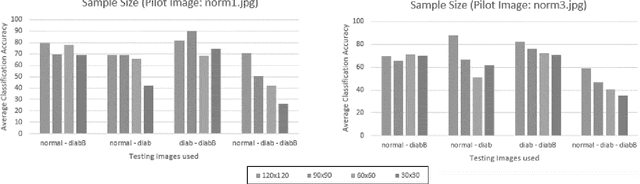
This paper investigates the effectiveness of an expert system based on K-nearest neighbors algorithm for laser speckle image sampling applied to the early detection of diabetes. With the latest developments in artificial intelligent guided laser speckle imaging technologies, it may be possible to optimise laser parameters, such as wavelength, energy level and image texture measures in association with a suitable AI technique to interact effectively with the subcellular properties of a skin tissue to detect early signs of diabetes. The new approach is potentially more effective than the classical skin glucose level observation because of its optimised combination of laser physics and AI techniques, and additionally, it allows non-expert individuals to perform more frequent skin tissue tests for an early detection of diabetes.
DropKey
Aug 08, 2022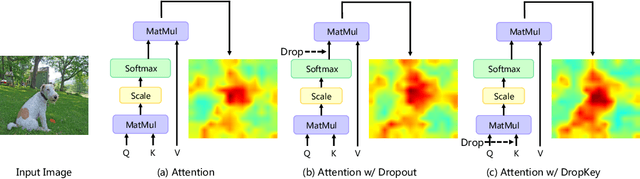

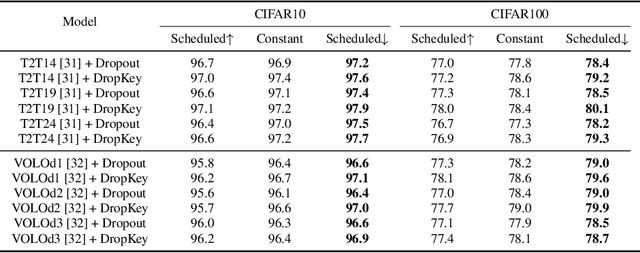
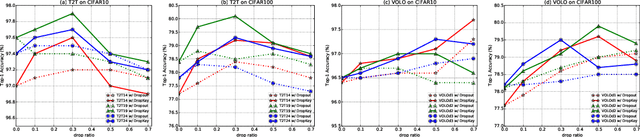
In this paper, we focus on analyzing and improving the dropout technique for self-attention layers of Vision Transformer, which is important while surprisingly ignored by prior works. In particular, we conduct researches on three core questions: First, what to drop in self-attention layers? Different from dropping attention weights in literature, we propose to move dropout operations forward ahead of attention matrix calculation and set the Key as the dropout unit, yielding a novel dropout-before-softmax scheme. We theoretically verify that this scheme helps keep both regularization and probability features of attention weights, alleviating the overfittings problem to specific patterns and enhancing the model to globally capture vital information; Second, how to schedule the drop ratio in consecutive layers? In contrast to exploit a constant drop ratio for all layers, we present a new decreasing schedule that gradually decreases the drop ratio along the stack of self-attention layers. We experimentally validate the proposed schedule can avoid overfittings in low-level features and missing in high-level semantics, thus improving the robustness and stableness of model training; Third, whether need to perform structured dropout operation as CNN? We attempt patch-based block-version of dropout operation and find that this useful trick for CNN is not essential for ViT. Given exploration on the above three questions, we present the novel DropKey method that regards Key as the drop unit and exploits decreasing schedule for drop ratio, improving ViTs in a general way. Comprehensive experiments demonstrate the effectiveness of DropKey for various ViT architectures, e.g. T2T and VOLO, as well as for various vision tasks, e.g., image classification, object detection, human-object interaction detection and human body shape recovery. Codes will be released upon acceptance.
SDTP: Semantic-aware Decoupled Transformer Pyramid for Dense Image Prediction
Sep 18, 2021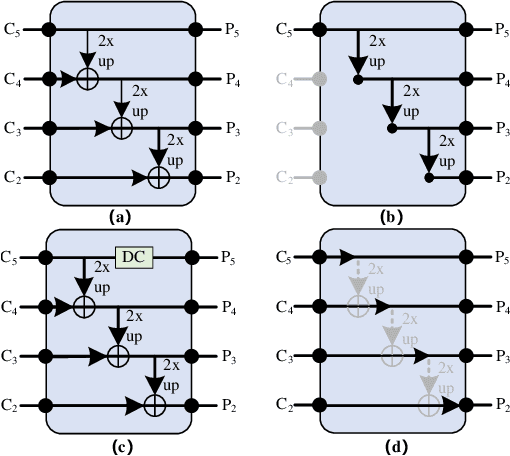
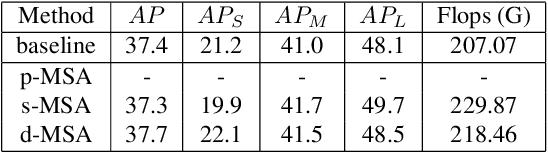
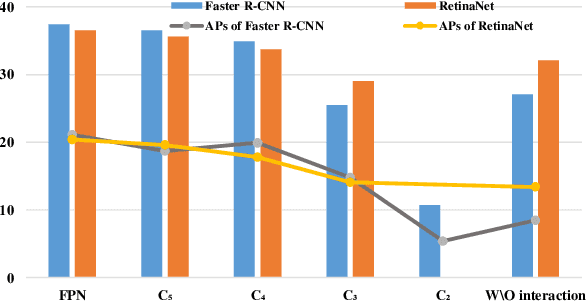
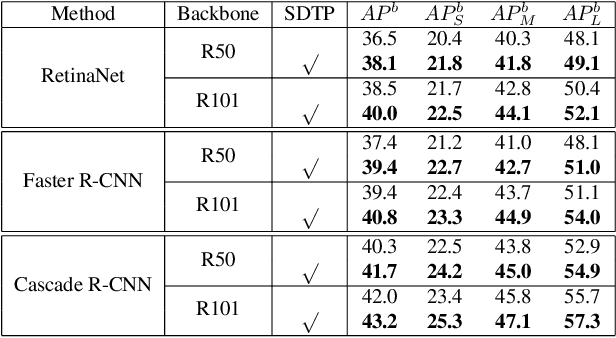
Although transformer has achieved great progress on computer vision tasks, the scale variation in dense image prediction is still the key challenge. Few effective multi-scale techniques are applied in transformer and there are two main limitations in the current methods. On one hand, self-attention module in vanilla transformer fails to sufficiently exploit the diversity of semantic information because of its rigid mechanism. On the other hand, it is hard to build attention and interaction among different levels due to the heavy computational burden. To alleviate this problem, we first revisit multi-scale problem in dense prediction, verifying the significance of diverse semantic representation and multi-scale interaction, and exploring the adaptation of transformer to pyramidal structure. Inspired by these findings, we propose a novel Semantic-aware Decoupled Transformer Pyramid (SDTP) for dense image prediction, consisting of Intra-level Semantic Promotion (ISP), Cross-level Decoupled Interaction (CDI) and Attention Refinement Function (ARF). ISP explores the semantic diversity in different receptive space. CDI builds the global attention and interaction among different levels in decoupled space which also solves the problem of heavy computation. Besides, ARF is further added to refine the attention in transformer. Experimental results demonstrate the validity and generality of the proposed method, which outperforms the state-of-the-art by a significant margin in dense image prediction tasks. Furthermore, the proposed components are all plug-and-play, which can be embedded in other methods.
A Comprehensive Study of Image Classification Model Sensitivity to Foregrounds, Backgrounds, and Visual Attributes
Jan 26, 2022
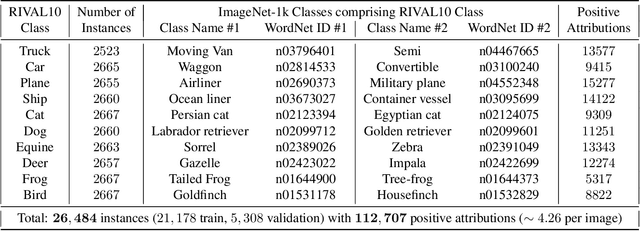
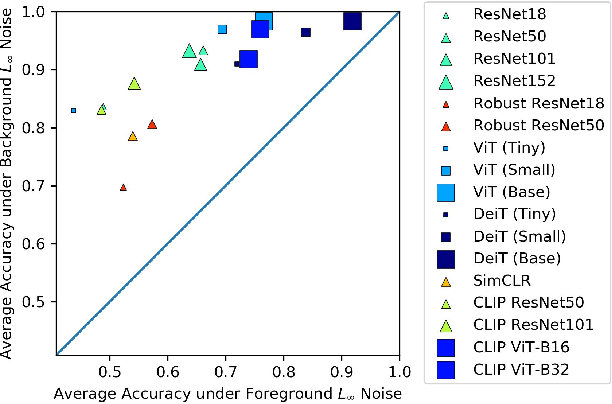
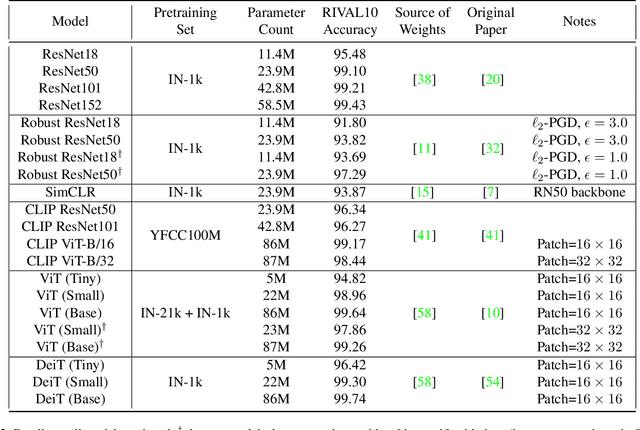
While datasets with single-label supervision have propelled rapid advances in image classification, additional annotations are necessary in order to quantitatively assess how models make predictions. To this end, for a subset of ImageNet samples, we collect segmentation masks for the entire object and $18$ informative attributes. We call this dataset RIVAL10 (RIch Visual Attributes with Localization), consisting of roughly $26k$ instances over $10$ classes. Using RIVAL10, we evaluate the sensitivity of a broad set of models to noise corruptions in foregrounds, backgrounds and attributes. In our analysis, we consider diverse state-of-the-art architectures (ResNets, Transformers) and training procedures (CLIP, SimCLR, DeiT, Adversarial Training). We find that, somewhat surprisingly, in ResNets, adversarial training makes models more sensitive to the background compared to foreground than standard training. Similarly, contrastively-trained models also have lower relative foreground sensitivity in both transformers and ResNets. Lastly, we observe intriguing adaptive abilities of transformers to increase relative foreground sensitivity as corruption level increases. Using saliency methods, we automatically discover spurious features that drive the background sensitivity of models and assess alignment of saliency maps with foregrounds. Finally, we quantitatively study the attribution problem for neural features by comparing feature saliency with ground-truth localization of semantic attributes.
Deep Learning Based Image Retrieval in the JPEG Compressed Domain
Jul 08, 2021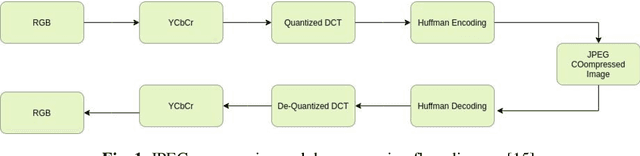

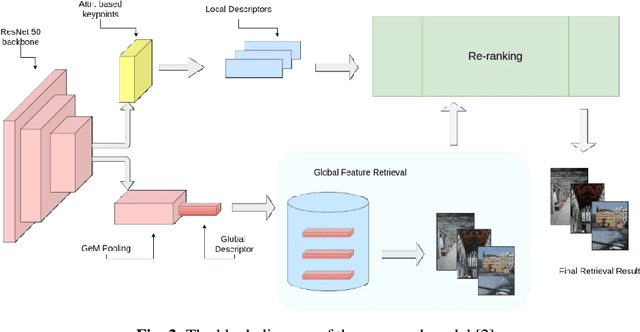

Content-based image retrieval (CBIR) systems on pixel domain use low-level features, such as colour, texture and shape, to retrieve images. In this context, two types of image representations i.e. local and global image features have been studied in the literature. Extracting these features from pixel images and comparing them with images from the database is very time-consuming. Therefore, in recent years, there has been some effort to accomplish image analysis directly in the compressed domain with lesser computations. Furthermore, most of the images in our daily transactions are stored in the JPEG compressed format. Therefore, it would be ideal if we could retrieve features directly from the partially decoded or compressed data and use them for retrieval. Here, we propose a unified model for image retrieval which takes DCT coefficients as input and efficiently extracts global and local features directly in the JPEG compressed domain for accurate image retrieval. The experimental findings indicate that our proposed model performed similarly to the current DELG model which takes RGB features as an input with reference to mean average precision while having a faster training and retrieval speed.
Boosting Entity-aware Image Captioning with Multi-modal Knowledge Graph
Jul 26, 2021
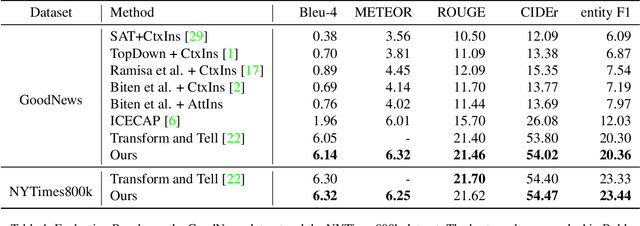
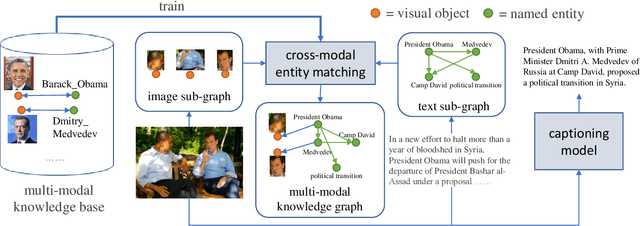
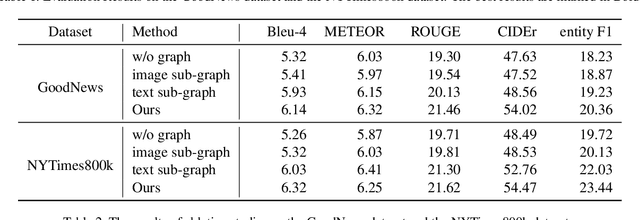
Entity-aware image captioning aims to describe named entities and events related to the image by utilizing the background knowledge in the associated article. This task remains challenging as it is difficult to learn the association between named entities and visual cues due to the long-tail distribution of named entities. Furthermore, the complexity of the article brings difficulty in extracting fine-grained relationships between entities to generate informative event descriptions about the image. To tackle these challenges, we propose a novel approach that constructs a multi-modal knowledge graph to associate the visual objects with named entities and capture the relationship between entities simultaneously with the help of external knowledge collected from the web. Specifically, we build a text sub-graph by extracting named entities and their relationships from the article, and build an image sub-graph by detecting the objects in the image. To connect these two sub-graphs, we propose a cross-modal entity matching module trained using a knowledge base that contains Wikipedia entries and the corresponding images. Finally, the multi-modal knowledge graph is integrated into the captioning model via a graph attention mechanism. Extensive experiments on both GoodNews and NYTimes800k datasets demonstrate the effectiveness of our method.
SLIDE: Single Image 3D Photography with Soft Layering and Depth-aware Inpainting
Sep 02, 2021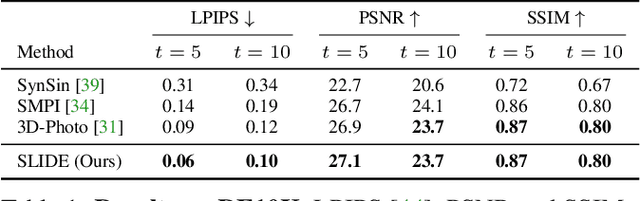
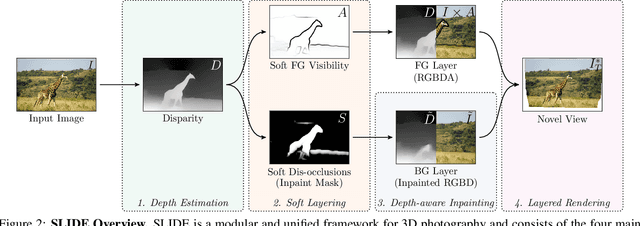
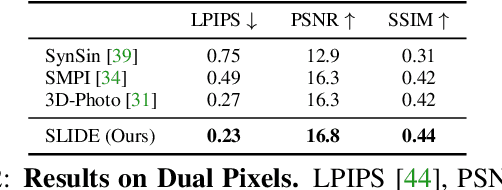

Single image 3D photography enables viewers to view a still image from novel viewpoints. Recent approaches combine monocular depth networks with inpainting networks to achieve compelling results. A drawback of these techniques is the use of hard depth layering, making them unable to model intricate appearance details such as thin hair-like structures. We present SLIDE, a modular and unified system for single image 3D photography that uses a simple yet effective soft layering strategy to better preserve appearance details in novel views. In addition, we propose a novel depth-aware training strategy for our inpainting module, better suited for the 3D photography task. The resulting SLIDE approach is modular, enabling the use of other components such as segmentation and matting for improved layering. At the same time, SLIDE uses an efficient layered depth formulation that only requires a single forward pass through the component networks to produce high quality 3D photos. Extensive experimental analysis on three view-synthesis datasets, in combination with user studies on in-the-wild image collections, demonstrate superior performance of our technique in comparison to existing strong baselines while being conceptually much simpler. Project page: https://varunjampani.github.io/slide