 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Instability of Safety: How Random Seeds and Temperature Expose Inconsistent LLM Refusal Behavior
Dec 16, 2025



Current safety evaluations of large language models rely on single-shot testing, implicitly assuming that model responses are deterministic and representative of the model's safety alignment. We challenge this assumption by investigating the stability of safety refusal decisions across random seeds and temperature settings. Testing four instruction-tuned models from three families (Llama 3.1 8B, Qwen 2.5 7B, Qwen 3 8B, Gemma 3 12B) on 876 harmful prompts across 20 different sampling configurations (4 temperatures x 5 random seeds), we find that 18-28% of prompts exhibit decision flips--the model refuses in some configurations but complies in others--depending on the model. Our Safety Stability Index (SSI) reveals that higher temperatures significantly reduce decision stability (Friedman chi-squared = 396.81, p < 0.001), with mean within-temperature SSI dropping from 0.977 at temperature 0.0 to 0.942 at temperature 1.0. We validate our findings across all model families using Claude 3.5 Haiku as a unified external judge, achieving 89.0% inter-judge agreement with our primary Llama 70B judge (Cohen's kappa = 0.62). Within each model, prompts with higher compliance rates exhibit lower stability (Spearman rho = -0.47 to -0.70, all p < 0.001), indicating that models "waver" more on borderline requests. These findings demonstrate that single-shot safety evaluations are insufficient for reliable safety assessment and that evaluation protocols must account for stochastic variation in model behavior. We show that single-shot evaluation agrees with multi-sample ground truth only 92.4% of the time when pooling across temperatures (94.2-97.7% at fixed temperature depending on setting), and recommend using at least 3 samples per prompt for reliable safety assessment.
A Survey of Machine Learning Algorithms for Detecting Malware in IoT Firmware
Nov 03, 2021
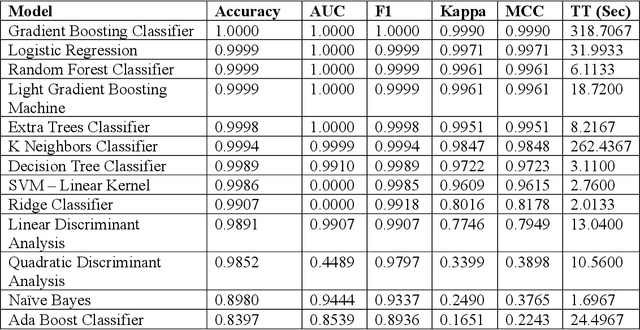

This work explores the use of machine learning techniques on an Internet-of-Things firmware dataset to detect malicious attempts to infect edge devices or subsequently corrupt an entire network. Firmware updates are uncommon in IoT devices; hence, they abound with vulnerabilities. Attacks against such devices can go unnoticed, and users can become a weak point in security. Malware can cause DDoS attacks and even spy on sensitive areas like peoples' homes. To help mitigate this threat, this paper employs a number of machine learning algorithms to classify IoT firmware and the best performing models are reported. In a general comparison, the top three algorithms are Gradient Boosting, Logistic Regression, and Random Forest classifiers. Deep learning approaches including Convolutional and Fully Connected Neural Networks with both experimental and proven successful architectures are also explored.
Intrusion Detection: Machine Learning Baseline Calculations for Image Classification
Nov 03, 2021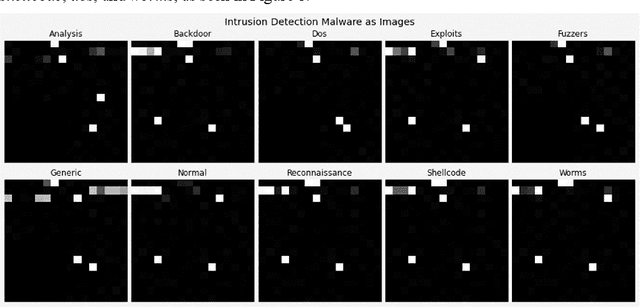
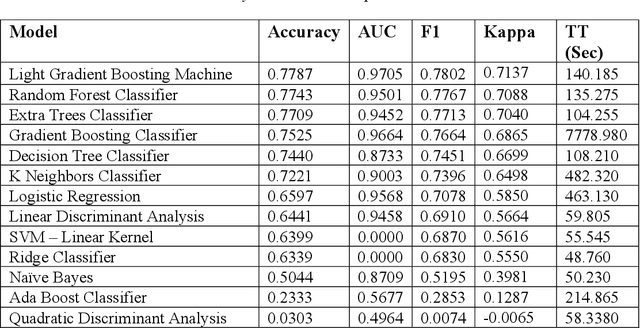
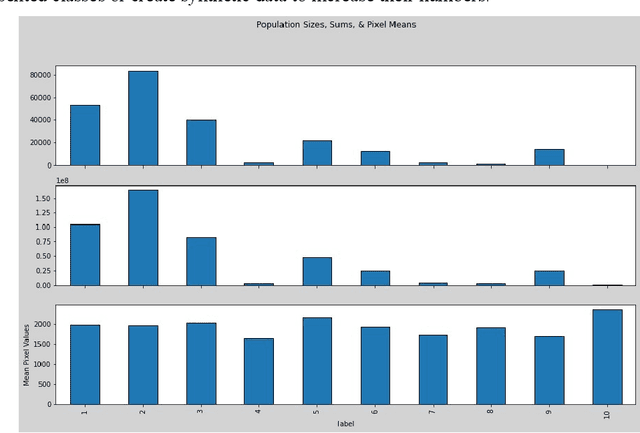

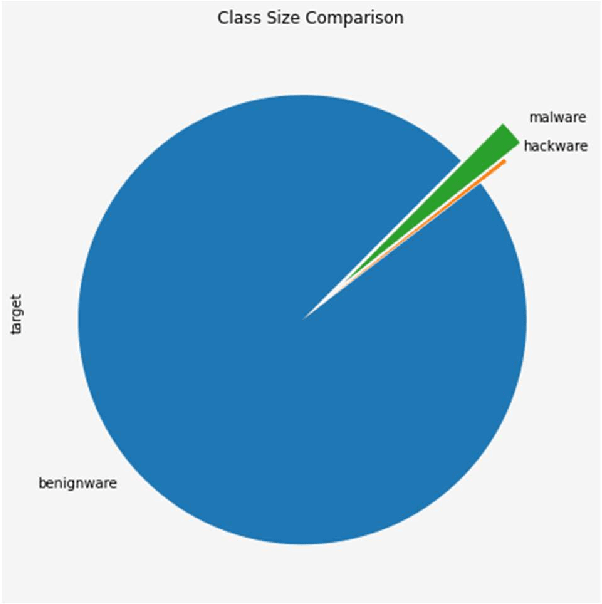
Cyber security can be enhanced through application of machine learning by recasting network attack data into an image format, then applying supervised computer vision and other machine learning techniques to detect malicious specimens. Exploratory data analysis reveals little correlation and few distinguishing characteristics between the ten classes of malware used in this study. A general model comparison demonstrates that the most promising candidates for consideration are Light Gradient Boosting Machine, Random Forest Classifier, and Extra Trees Classifier. Convolutional networks fail to deliver their outstanding classification ability, being surpassed by a simple, fully connected architecture. Most tests fail to break 80% categorical accuracy and present low F1 scores, indicating more sophisticated approaches (e.g., bootstrapping, random samples, and feature selection) may be required to maximize performance.
Virus-MNIST: Machine Learning Baseline Calculations for Image Classification
Nov 03, 2021
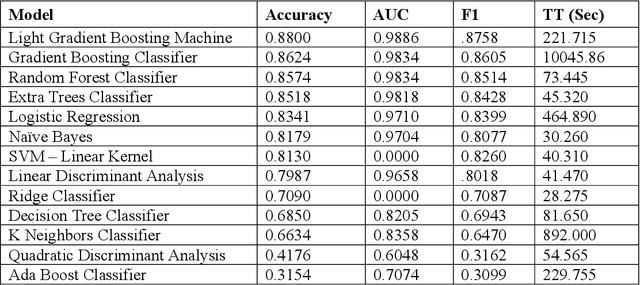
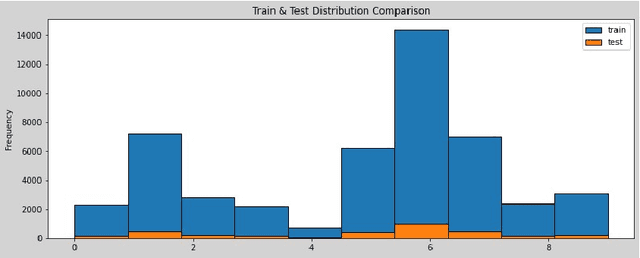

The Virus-MNIST data set is a collection of thumbnail images that is similar in style to the ubiquitous MNIST hand-written digits. These, however, are cast by reshaping possible malware code into an image array. Naturally, it is poised to take on a role in benchmarking progress of virus classifier model training. Ten types are present: nine classified as malware and one benign. Cursory examination reveals unequal class populations and other key aspects that must be considered when selecting classification and pre-processing methods. Exploratory analyses show possible identifiable characteristics from aggregate metrics (e.g., the pixel median values), and ways to reduce the number of features by identifying strong correlations. A model comparison shows that Light Gradient Boosting Machine, Gradient Boosting Classifier, and Random Forest algorithms produced the highest accuracy scores, thus showing promise for deeper scrutiny.
Predicting Solar Flares with Remote Sensing and Machine Learning
Oct 14, 2021
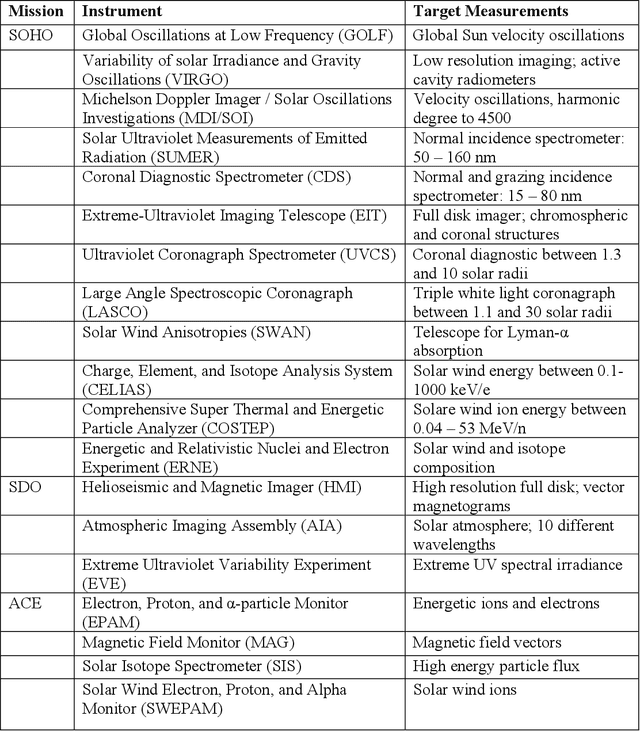
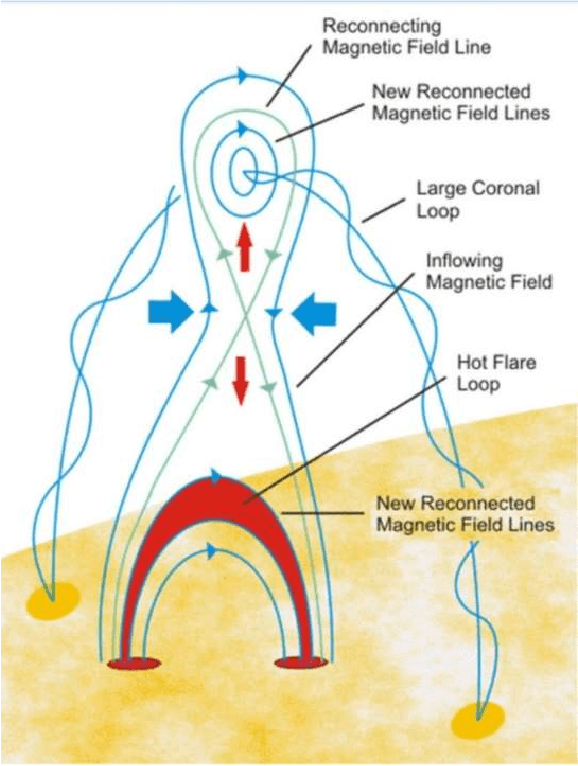

High energy solar flares and coronal mass ejections have the potential to destroy Earth's ground and satellite infrastructures, causing trillions of dollars in damage and mass human suffering. Destruction of these critical systems would disable power grids and satellites, crippling communications and transportation. This would lead to food shortages and an inability to respond to emergencies. A solution to this impending problem is proposed herein using satellites in solar orbit that continuously monitor the Sun, use artificial intelligence and machine learning to calculate the probability of massive solar explosions from this sensed data, and then signal defense mechanisms that will mitigate the threat. With modern technology there may be only safeguards that can be implemented with enough warning, which is why the best algorithm must be identified and continuously trained with existing and new data to maximize true positive rates while minimizing false negatives. This paper conducts a survey of current machine learning models using open source solar flare prediction data. The rise of edge computing allows machine learning hardware to be placed on the same satellites as the sensor arrays, saving critical time by not having to transmit remote sensing data across the vast distances of space. A system of systems approach will allow enough warning for safety measures to be put into place mitigating the risk of disaster.
A Survey of Machine Learning Algorithms for Detecting Ransomware Encryption Activity
Oct 14, 2021
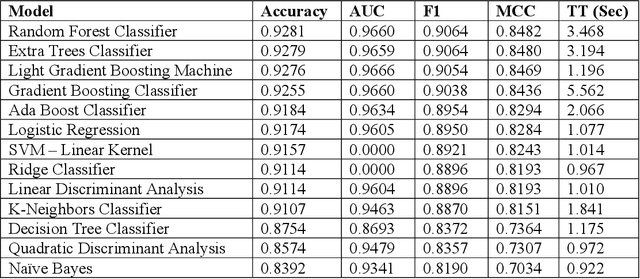
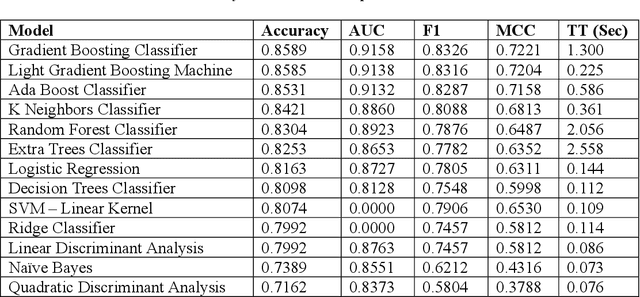
A survey of machine learning techniques trained to detect ransomware is presented. This work builds upon the efforts of Taylor et al. in using sensor-based methods that utilize data collected from built-in instruments like CPU power and temperature monitors to identify encryption activity. Exploratory data analysis (EDA) shows the features most useful from this simulated data are clock speed, temperature, and CPU load. These features are used in training multiple algorithms to determine an optimal detection approach. Performance is evaluated with accuracy, F1 score, and false-negative rate metrics. The Multilayer Perceptron with three hidden layers achieves scores of 97% in accuracy and F1 and robust data preparation. A random forest model produces scores of 93% accuracy and 92% F1, showing that sensor-based detection is currently a viable option to detect even zero-day ransomware attacks before the code fully executes.
Overhead-MNIST: Machine Learning Baselines for Image Classification
Jul 01, 2021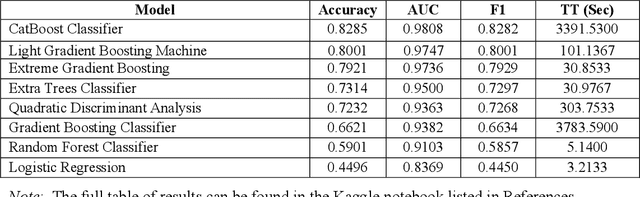
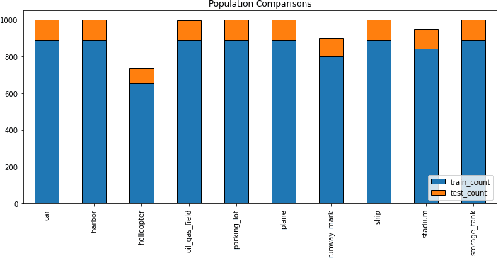

Twenty-three machine learning algorithms were trained then scored to establish baseline comparison metrics and to select an image classification algorithm worthy of embedding into mission-critical satellite imaging systems. The Overhead-MNIST dataset is a collection of satellite images similar in style to the ubiquitous MNIST hand-written digits found in the machine learning literature. The CatBoost classifier, Light Gradient Boosting Machine, and Extreme Gradient Boosting models produced the highest accuracies, Areas Under the Curve (AUC), and F1 scores in a PyCaret general comparison. Separate evaluations showed that a deep convolutional architecture was the most promising. We present results for the overall best performing algorithm as a baseline for edge deployability and future performance improvement: a convolutional neural network (CNN) scoring 0.965 categorical accuracy on unseen test data.