 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
PatchCleanser: Certifiably Robust Defense against Adversarial Patches for Any Image Classifier
Aug 20, 2021
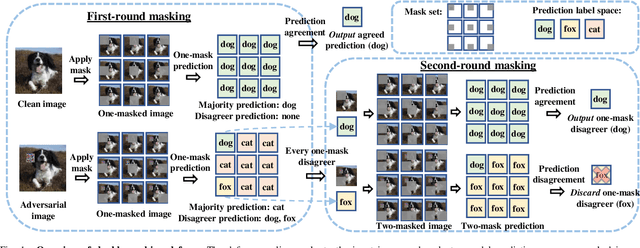
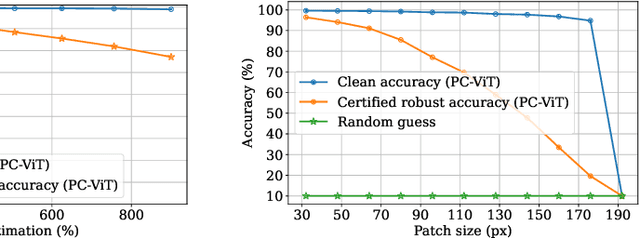
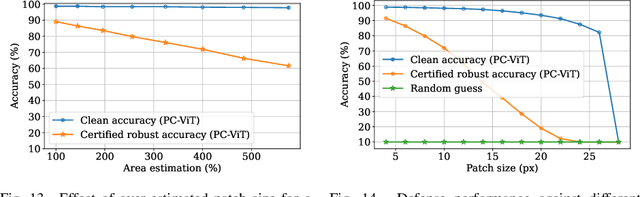
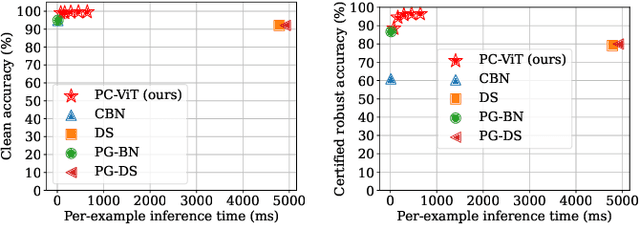
The adversarial patch attack against image classification models aims to inject adversarially crafted pixels within a localized restricted image region (i.e., a patch) for inducing model misclassification. This attack can be realized in the physical world by printing and attaching the patch to the victim object and thus imposes a real-world threat to computer vision systems. To counter this threat, we propose PatchCleanser as a certifiably robust defense against adversarial patches that is compatible with any image classifier. In PatchCleanser, we perform two rounds of pixel masking on the input image to neutralize the effect of the adversarial patch. In the first round of masking, we apply a set of carefully generated masks to the input image and evaluate the model prediction on every masked image. If model predictions on all one-masked images reach a unanimous agreement, we output the agreed prediction label. Otherwise, we perform a second round of masking to settle the disagreement, in which we evaluate model predictions on two-masked images to robustly recover the correct prediction label. Notably, we can prove that our defense will always make correct predictions on certain images against any adaptive white-box attacker within our threat model, achieving certified robustness. We extensively evaluate our defense on the ImageNet, ImageNette, CIFAR-10, CIFAR-100, SVHN, and Flowers-102 datasets and demonstrate that our defense achieves similar clean accuracy as state-of-the-art classification models and also significantly improves certified robustness from prior works. Notably, our defense can achieve 83.8% top-1 clean accuracy and 60.4% top-1 certified robust accuracy against a 2%-pixel square patch anywhere on the 1000-class ImageNet dataset.
PoissonSeg: Semi-Supervised Few-Shot Medical Image Segmentation via Poisson Learning
Aug 26, 2021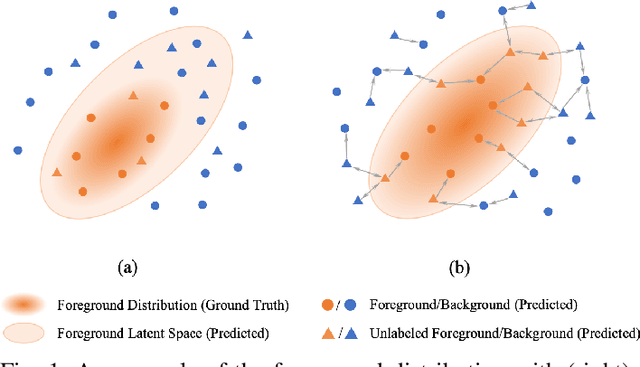
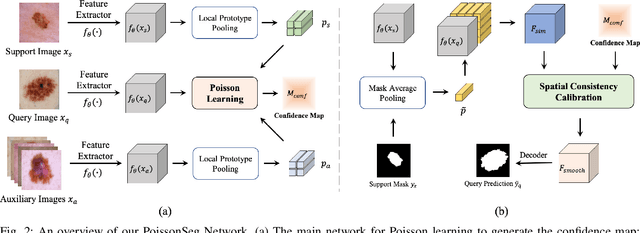
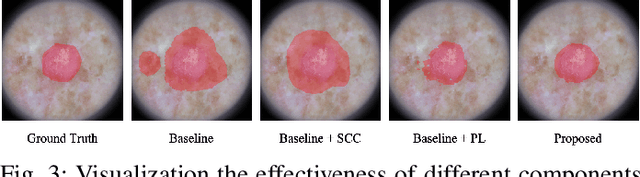
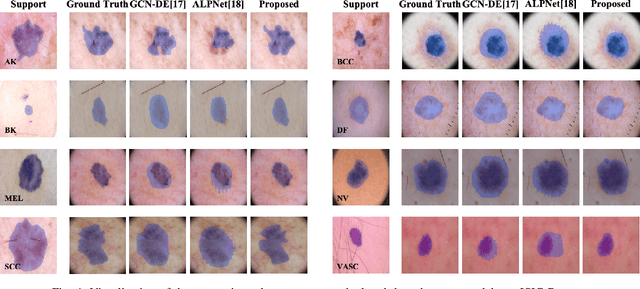
The application of deep learning to medical image segmentation has been hampered due to the lack of abundant pixel-level annotated data. Few-shot Semantic Segmentation (FSS) is a promising strategy for breaking the deadlock. However, a high-performing FSS model still requires sufficient pixel-level annotated classes for training to avoid overfitting, which leads to its performance bottleneck in medical image segmentation due to the unmet need for annotations. Thus, semi-supervised FSS for medical images is accordingly proposed to utilize unlabeled data for further performance improvement. Nevertheless, existing semi-supervised FSS methods has two obvious defects: (1) neglecting the relationship between the labeled and unlabeled data; (2) using unlabeled data directly for end-to-end training leads to degenerated representation learning. To address these problems, we propose a novel semi-supervised FSS framework for medical image segmentation. The proposed framework employs Poisson learning for modeling data relationship and propagating supervision signals, and Spatial Consistency Calibration for encouraging the model to learn more coherent representations. In this process, unlabeled samples do not involve in end-to-end training, but provide supervisory information for query image segmentation through graph-based learning. We conduct extensive experiments on three medical image segmentation datasets (i.e. ISIC skin lesion segmentation, abdominal organs segmentation for MRI and abdominal organs segmentation for CT) to demonstrate the state-of-the-art performance and broad applicability of the proposed framework.
Deep Joint Source-Channel Coding for Wireless Image Transmission with Adaptive Rate Control
Oct 09, 2021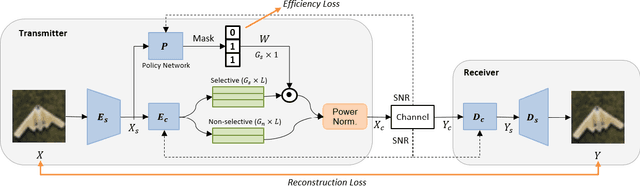
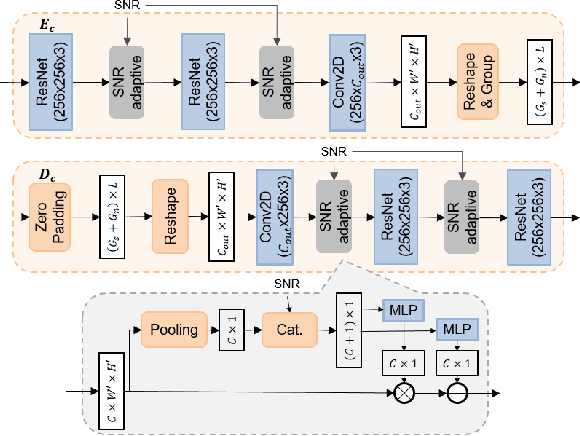
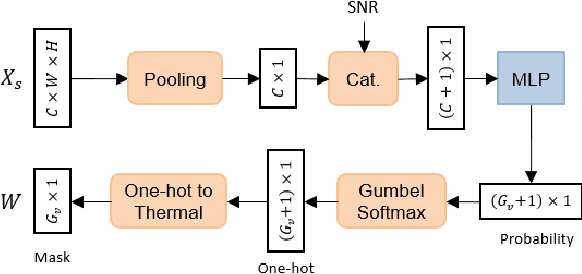
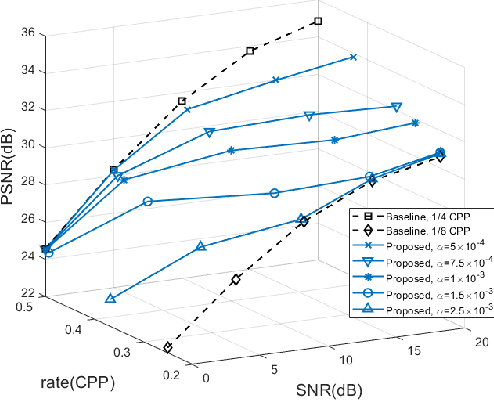
We present a novel adaptive deep joint source-channel coding (JSCC) scheme for wireless image transmission. The proposed scheme supports multiple rates using a single deep neural network (DNN) model and learns to dynamically control the rate based on the channel condition and image contents. Specifically, a policy network is introduced to exploit the tradeoff space between the rate and signal quality. To train the policy network, the Gumbel-Softmax trick is adopted to make the policy network differentiable and hence the whole JSCC scheme can be trained end-to-end. To the best of our knowledge, this is the first deep JSCC scheme that can automatically adjust its rate using a single network model. Experiments show that our scheme successfully learns a reasonable policy that decreases channel bandwidth utilization for high SNR scenarios or simple image contents. For an arbitrary target rate, our rate-adaptive scheme using a single model achieves similar performance compared to an optimized model specifically trained for that fixed target rate. To reproduce our results, we make the source code publicly available at https://github.com/mingyuyng/Dynamic_JSCC.
Generate and Edit Your Own Character in a Canonical View
May 06, 2022

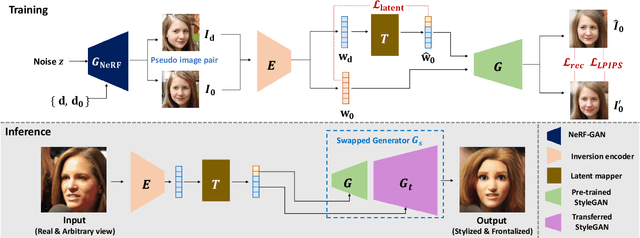

Recently, synthesizing personalized characters from a single user-given portrait has received remarkable attention as a drastic popularization of social media and the metaverse. The input image is not always in frontal view, thus it is important to acquire or predict canonical view for 3D modeling or other applications. Although the progress of generative models enables the stylization of a portrait, obtaining the stylized image in canonical view is still a challenging task. There have been several studies on face frontalization but their performance significantly decreases when input is not in the real image domain, e.g., cartoon or painting. Stylizing after frontalization also results in degenerated output. In this paper, we propose a novel and unified framework which generates stylized portraits in canonical view. With a proposed latent mapper, we analyze and discover frontalization mapping in a latent space of StyleGAN to stylize and frontalize at once. In addition, our model can be trained with unlabelled 2D image sets, without any 3D supervision. The effectiveness of our method is demonstrated by experimental results.
Inconsistency-aware Uncertainty Estimation for Semi-supervised Medical Image Segmentation
Oct 17, 2021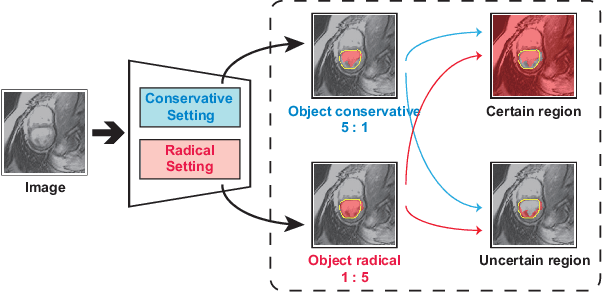
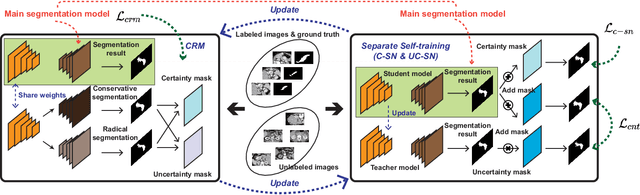
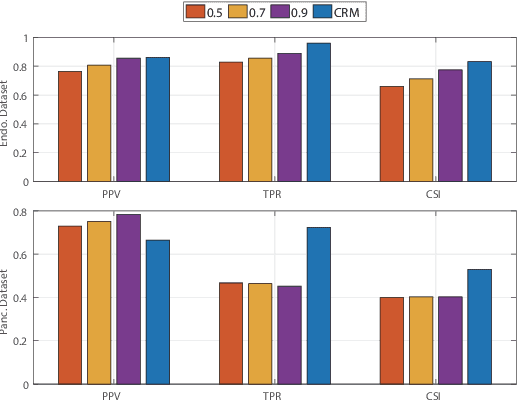

In semi-supervised medical image segmentation, most previous works draw on the common assumption that higher entropy means higher uncertainty. In this paper, we investigate a novel method of estimating uncertainty. We observe that, when assigned different misclassification costs in a certain degree, if the segmentation result of a pixel becomes inconsistent, this pixel shows a relative uncertainty in its segmentation. Therefore, we present a new semi-supervised segmentation model, namely, conservative-radical network (CoraNet in short) based on our uncertainty estimation and separate self-training strategy. In particular, our CoraNet model consists of three major components: a conservative-radical module (CRM), a certain region segmentation network (C-SN), and an uncertain region segmentation network (UC-SN) that could be alternatively trained in an end-to-end manner. We have extensively evaluated our method on various segmentation tasks with publicly available benchmark datasets, including CT pancreas, MR endocardium, and MR multi-structures segmentation on the ACDC dataset. Compared with the current state of the art, our CoraNet has demonstrated superior performance. In addition, we have also analyzed its connection with and difference from conventional methods of uncertainty estimation in semi-supervised medical image segmentation.
Structure First Detail Next: Image Inpainting with Pyramid Generator
Jun 16, 2021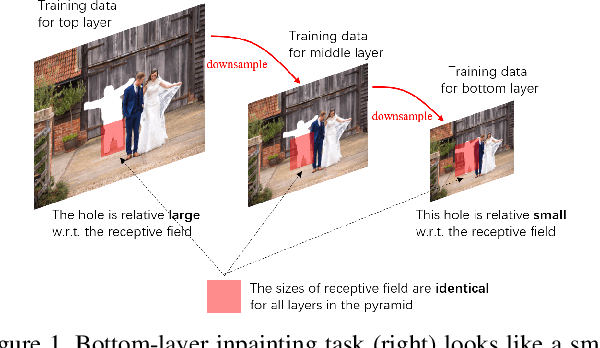

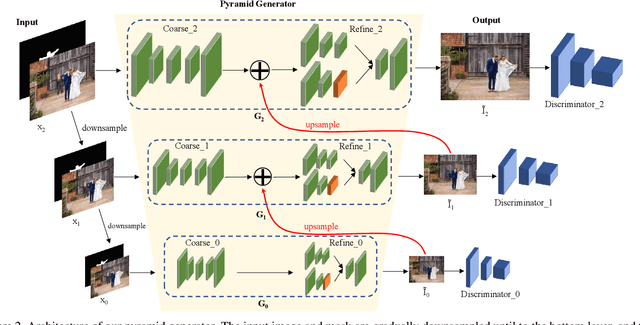
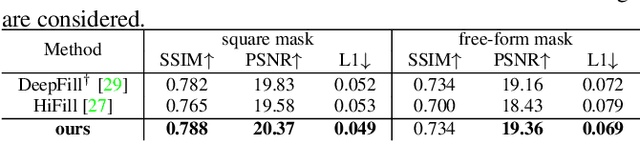
Recent deep generative models have achieved promising performance in image inpainting. However, it is still very challenging for a neural network to generate realistic image details and textures, due to its inherent spectral bias. By our understanding of how artists work, we suggest to adopt a `structure first detail next' workflow for image inpainting. To this end, we propose to build a Pyramid Generator by stacking several sub-generators, where lower-layer sub-generators focus on restoring image structures while the higher-layer sub-generators emphasize image details. Given an input image, it will be gradually restored by going through the entire pyramid in a bottom-up fashion. Particularly, our approach has a learning scheme of progressively increasing hole size, which allows it to restore large-hole images. In addition, our method could fully exploit the benefits of learning with high-resolution images, and hence is suitable for high-resolution image inpainting. Extensive experimental results on benchmark datasets have validated the effectiveness of our approach compared with state-of-the-art methods.
Discrete Contrastive Diffusion for Cross-Modal and Conditional Generation
Jun 15, 2022
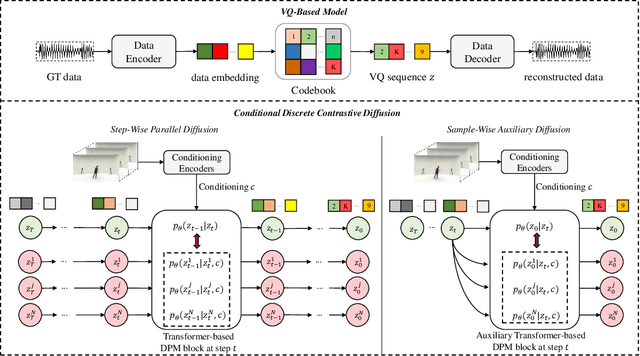

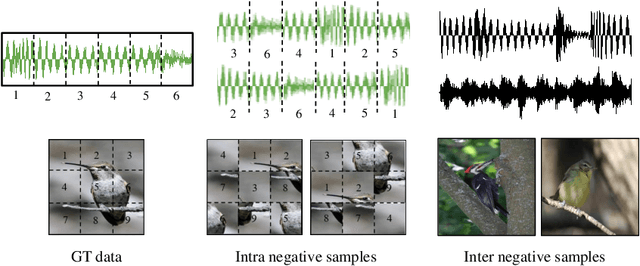
Diffusion probabilistic models (DPMs) have become a popular approach to conditional generation, due to their promising results and support for cross-modal synthesis. A key desideratum in conditional synthesis is to achieve high correspondence between the conditioning input and generated output. Most existing methods learn such relationships implicitly, by incorporating the prior into the variational lower bound. In this work, we take a different route -- we enhance input-output connections by maximizing their mutual information using contrastive learning. To this end, we introduce a Conditional Discrete Contrastive Diffusion (CDCD) loss and design two contrastive diffusion mechanisms to effectively incorporate it into the denoising process. We formulate CDCD by connecting it with the conventional variational objectives. We demonstrate the efficacy of our approach in evaluations with three diverse, multimodal conditional synthesis tasks: dance-to-music generation, text-to-image synthesis, and class-conditioned image synthesis. On each, we achieve state-of-the-art or higher synthesis quality and improve the input-output correspondence. Furthermore, the proposed approach improves the convergence of diffusion models, reducing the number of required diffusion steps by more than 35% on two benchmarks, significantly increasing the inference speed.
Mask CycleGAN: Unpaired Multi-modal Domain Translation with Interpretable Latent Variable
May 14, 2022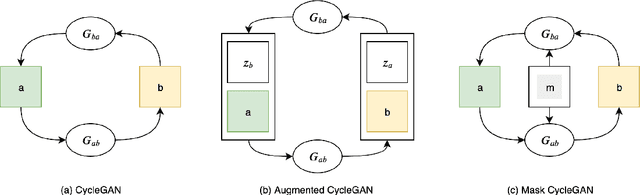
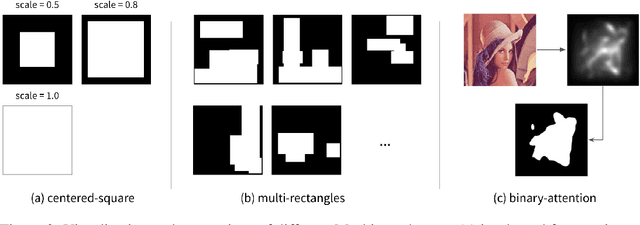
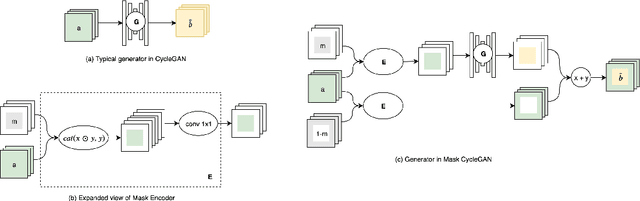
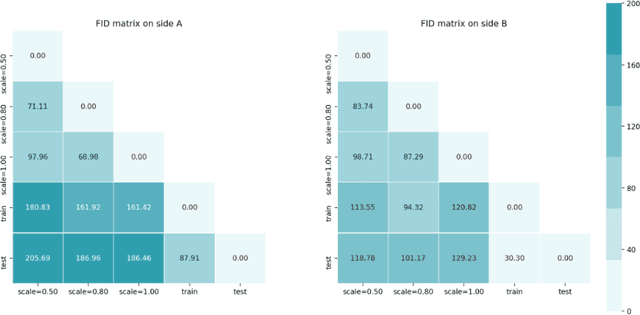
We propose Mask CycleGAN, a novel architecture for unpaired image domain translation built based on CycleGAN, with an aim to address two issues: 1) unimodality in image translation and 2) lack of interpretability of latent variables. Our innovation in the technical approach is comprised of three key components: masking scheme, generator and objective. Experimental results demonstrate that this architecture is capable of bringing variations to generated images in a controllable manner and is reasonably robust to different masks.
An advanced combination of semi-supervised Normalizing Flow & Yolo (YoloNF) to detect and recognize vehicle license plates
Jul 21, 2022
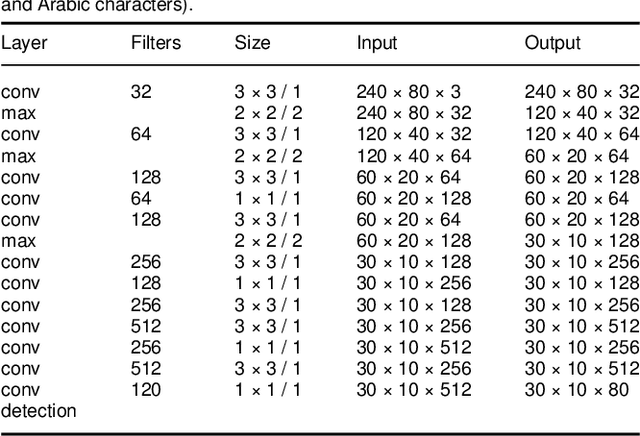
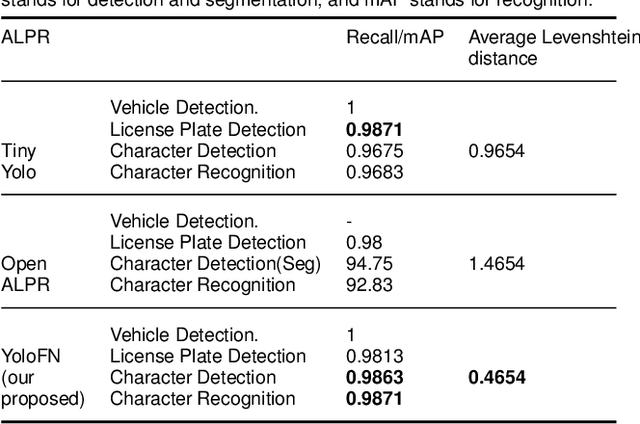
Fully Automatic License Plate Recognition (ALPR) has been a frequent research topic due to several practical applications. However, many of the current solutions are still not robust enough in real situations, commonly depending on many constraints. This paper presents a robust and efficient ALPR system based on the state-of-the-art YOLO object detector and Normalizing flows. The model uses two new strategies. Firstly, a two-stage network using YOLO and a normalization flow-based model for normalization to detect Licenses Plates (LP) and recognize the LP with numbers and Arabic characters. Secondly, Multi-scale image transformations are implemented to provide a solution to the problem of the YOLO cropped LP detection including significant background noise. Furthermore, extensive experiments are led on a new dataset with realistic scenarios, we introduce a larger public annotated dataset collected from Moroccan plates. We demonstrate that our proposed model can learn on a small number of samples free of single or multiple characters. The dataset will also be made publicly available to encourage further studies and research on plate detection and recognition.
Controllable Data Generation by Deep Learning: A Review
Jul 25, 2022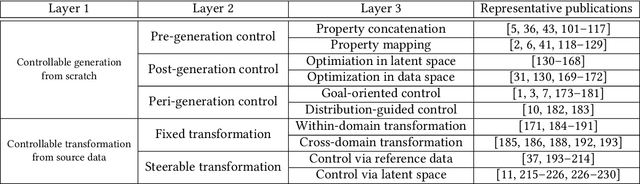
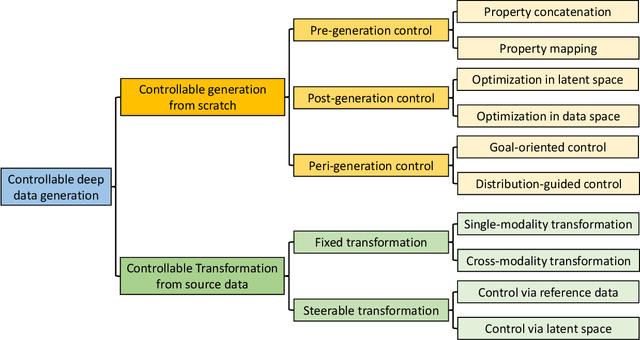
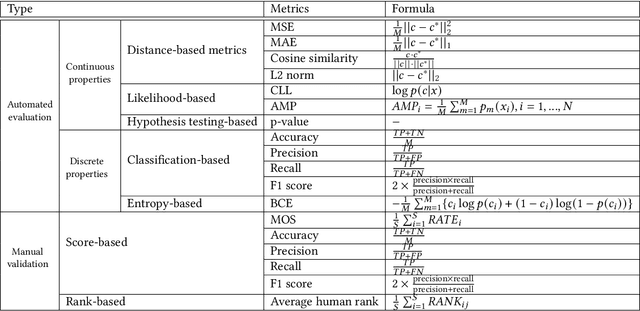
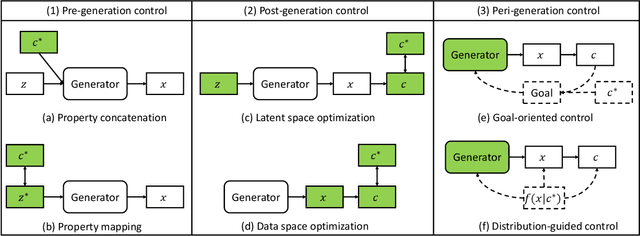
Designing and generating new data under targeted properties has been attracting various critical applications such as molecule design, image editing and speech synthesis. Traditional hand-crafted approaches heavily rely on expertise experience and intensive human efforts, yet still suffer from the insufficiency of scientific knowledge and low throughput to support effective and efficient data generation. Recently, the advancement of deep learning induces expressive methods that can learn the underlying representation and properties of data. Such capability provides new opportunities in figuring out the mutual relationship between the structural patterns and functional properties of the data and leveraging such relationship to generate structural data given the desired properties. This article provides a systematic review of this promising research area, commonly known as controllable deep data generation. Firstly, the potential challenges are raised and preliminaries are provided. Then the controllable deep data generation is formally defined, a taxonomy on various techniques is proposed and the evaluation metrics in this specific domain are summarized. After that, exciting applications of controllable deep data generation are introduced and existing works are experimentally analyzed and compared. Finally, the promising future directions of controllable deep data generation are highlighted and five potential challenges are identified.