 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeSAE: Sparse Decoding for Faithful Explanations of Black-Box Time Series Models
Jan 14, 2026As black box models and pretrained models gain traction in time series applications, understanding and explaining their predictions becomes increasingly vital, especially in high-stakes domains where interpretability and trust are essential. However, most of the existing methods involve only in-distribution explanation, and do not generalize outside the training support, which requires the learning capability of generalization. In this work, we aim to provide a framework to explain black-box models for time series data through the dual lenses of Sparse Autoencoders (SAEs) and causality. We show that many current explanation methods are sensitive to distributional shifts, limiting their effectiveness in real-world scenarios. Building on the concept of Sparse Autoencoder, we introduce TimeSAE, a framework for black-box model explanation. We conduct extensive evaluations of TimeSAE on both synthetic and real-world time series datasets, comparing it to leading baselines. The results, supported by both quantitative metrics and qualitative insights, show that TimeSAE provides more faithful and robust explanations. Our code is available in an easy-to-use library TimeSAE-Lib: https://anonymous.4open.science/w/TimeSAE-571D/.
An advanced combination of semi-supervised Normalizing Flow & Yolo (YoloNF) to detect and recognize vehicle license plates
Jul 21, 2022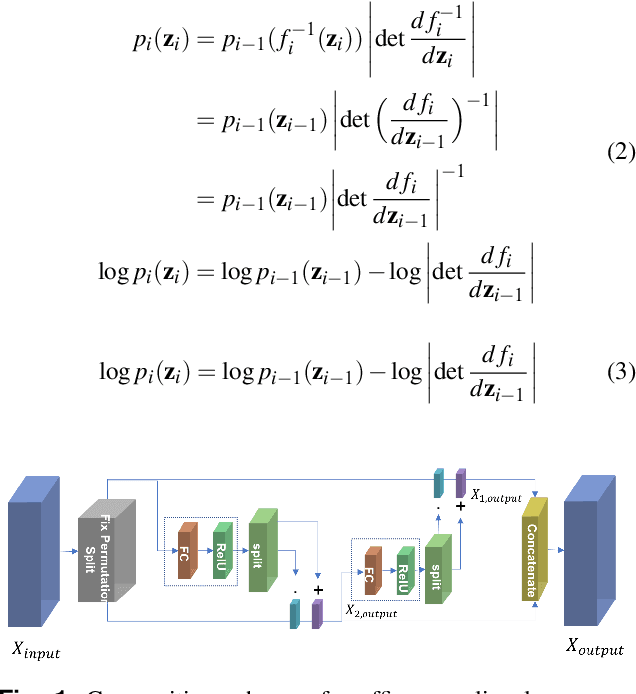
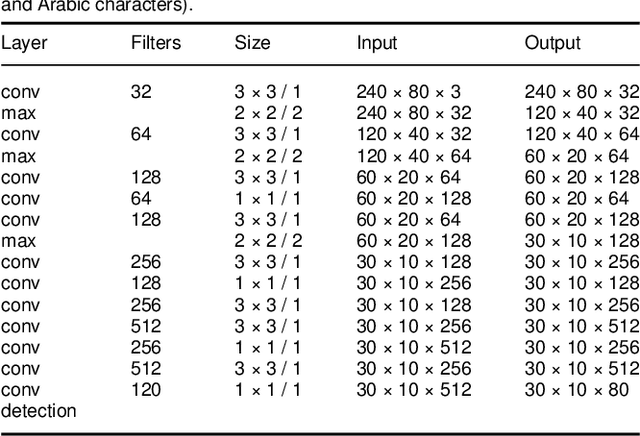
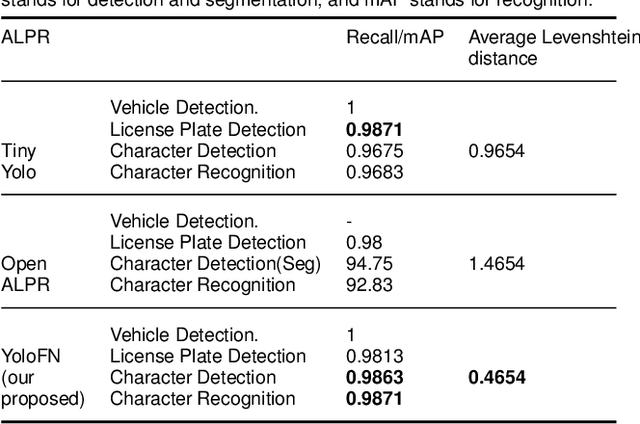
Fully Automatic License Plate Recognition (ALPR) has been a frequent research topic due to several practical applications. However, many of the current solutions are still not robust enough in real situations, commonly depending on many constraints. This paper presents a robust and efficient ALPR system based on the state-of-the-art YOLO object detector and Normalizing flows. The model uses two new strategies. Firstly, a two-stage network using YOLO and a normalization flow-based model for normalization to detect Licenses Plates (LP) and recognize the LP with numbers and Arabic characters. Secondly, Multi-scale image transformations are implemented to provide a solution to the problem of the YOLO cropped LP detection including significant background noise. Furthermore, extensive experiments are led on a new dataset with realistic scenarios, we introduce a larger public annotated dataset collected from Moroccan plates. We demonstrate that our proposed model can learn on a small number of samples free of single or multiple characters. The dataset will also be made publicly available to encourage further studies and research on plate detection and recognition.