 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
From Heatmaps to Structural Explanations of Image Classifiers
Sep 13, 2021
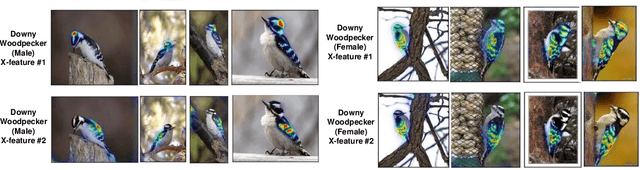
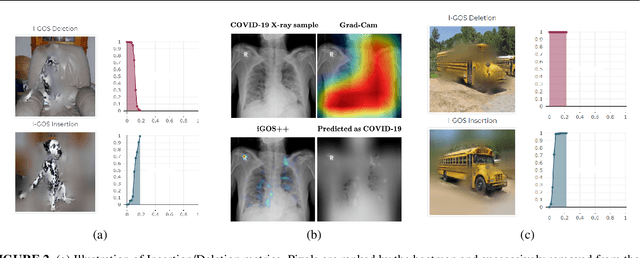

This paper summarizes our endeavors in the past few years in terms of explaining image classifiers, with the aim of including negative results and insights we have gained. The paper starts with describing the explainable neural network (XNN), which attempts to extract and visualize several high-level concepts purely from the deep network, without relying on human linguistic concepts. This helps users understand network classifications that are less intuitive and substantially improves user performance on a difficult fine-grained classification task of discriminating among different species of seagulls. Realizing that an important missing piece is a reliable heatmap visualization tool, we have developed I-GOS and iGOS++ utilizing integrated gradients to avoid local optima in heatmap generation, which improved the performance across all resolutions. During the development of those visualizations, we realized that for a significant number of images, the classifier has multiple different paths to reach a confident prediction. This has lead to our recent development of structured attention graphs (SAGs), an approach that utilizes beam search to locate multiple coarse heatmaps for a single image, and compactly visualizes a set of heatmaps by capturing how different combinations of image regions impact the confidence of a classifier. Through the research process, we have learned much about insights in building deep network explanations, the existence and frequency of multiple explanations, and various tricks of the trade that make explanations work. In this paper, we attempt to share those insights and opinions with the readers with the hope that some of them will be informative for future researchers on explainable deep learning.
FA-GAN: Feature-Aware GAN for Text to Image Synthesis
Sep 02, 2021

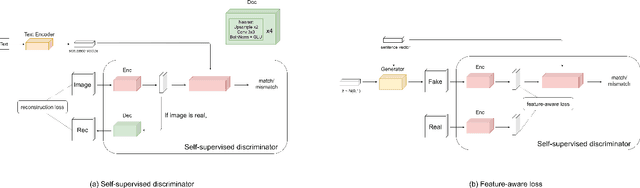

Text-to-image synthesis aims to generate a photo-realistic image from a given natural language description. Previous works have made significant progress with Generative Adversarial Networks (GANs). Nonetheless, it is still hard to generate intact objects or clear textures (Fig 1). To address this issue, we propose Feature-Aware Generative Adversarial Network (FA-GAN) to synthesize a high-quality image by integrating two techniques: a self-supervised discriminator and a feature-aware loss. First, we design a self-supervised discriminator with an auxiliary decoder so that the discriminator can extract better representation. Secondly, we introduce a feature-aware loss to provide the generator more direct supervision by employing the feature representation from the self-supervised discriminator. Experiments on the MS-COCO dataset show that our proposed method significantly advances the state-of-the-art FID score from 28.92 to 24.58.
AdaDM: Enabling Normalization for Image Super-Resolution
Nov 27, 2021
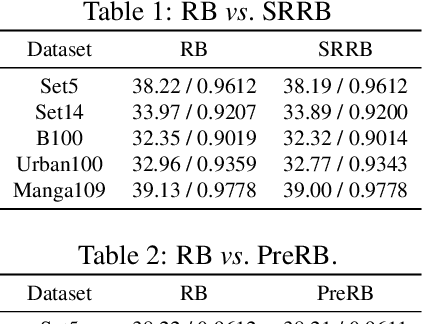
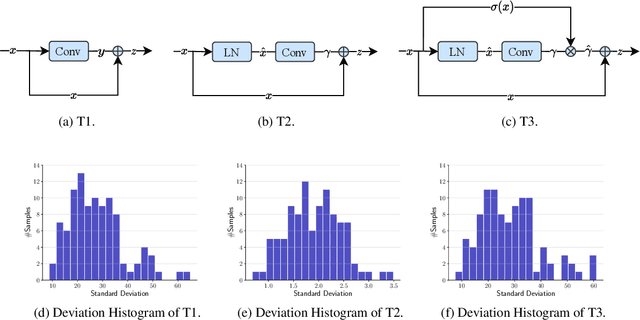
Normalization like Batch Normalization (BN) is a milestone technique to normalize the distributions of intermediate layers in deep learning, enabling faster training and better generalization accuracy. However, in fidelity image Super-Resolution (SR), it is believed that normalization layers get rid of range flexibility by normalizing the features and they are simply removed from modern SR networks. In this paper, we study this phenomenon quantitatively and qualitatively. We found that the standard deviation of the residual feature shrinks a lot after normalization layers, which causes the performance degradation in SR networks. Standard deviation reflects the amount of variation of pixel values. When the variation becomes smaller, the edges will become less discriminative for the network to resolve. To address this problem, we propose an Adaptive Deviation Modulator (AdaDM), in which a modulation factor is adaptively predicted to amplify the pixel deviation. For better generalization performance, we apply BN in state-of-the-art SR networks with the proposed AdaDM. Meanwhile, the deviation amplification strategy in AdaDM makes the edge information in the feature more distinguishable. As a consequence, SR networks with BN and our AdaDM can get substantial performance improvements on benchmark datasets. Extensive experiments have been conducted to show the effectiveness of our method.
Synthetic Dataset Generation for Adversarial Machine Learning Research
Jul 21, 2022
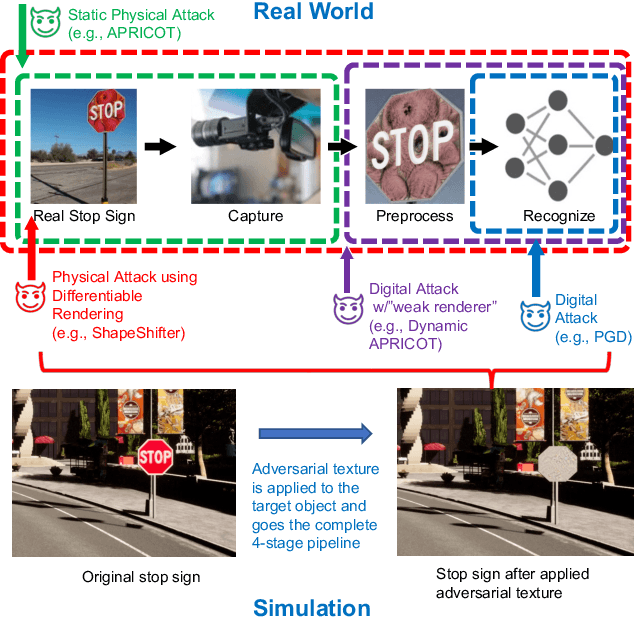


Existing adversarial example research focuses on digitally inserted perturbations on top of existing natural image datasets. This construction of adversarial examples is not realistic because it may be difficult, or even impossible, for an attacker to deploy such an attack in the real-world due to sensing and environmental effects. To better understand adversarial examples against cyber-physical systems, we propose approximating the real-world through simulation. In this paper we describe our synthetic dataset generation tool that enables scalable collection of such a synthetic dataset with realistic adversarial examples. We use the CARLA simulator to collect such a dataset and demonstrate simulated attacks that undergo the same environmental transforms and processing as real-world images. Our tools have been used to collect datasets to help evaluate the efficacy of adversarial examples, and can be found at https://github.com/carla-simulator/carla/pull/4992.
Online Video Super-Resolution with Convolutional Kernel Bypass Graft
Aug 04, 2022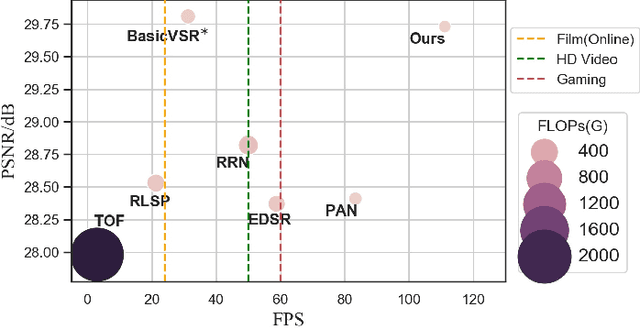

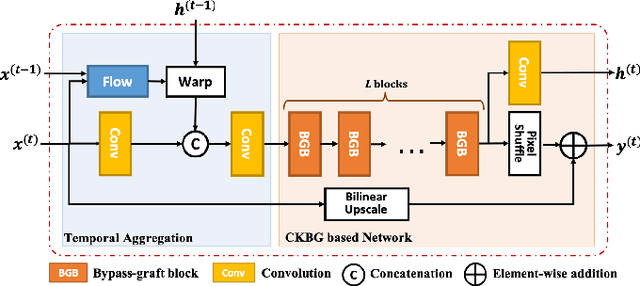
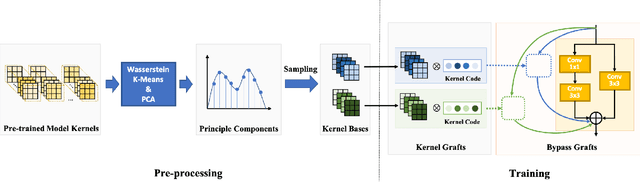
Deep learning-based models have achieved remarkable performance in video super-resolution (VSR) in recent years, but most of these models are less applicable to online video applications. These methods solely consider the distortion quality and ignore crucial requirements for online applications, e.g., low latency and low model complexity. In this paper, we focus on online video transmission, in which VSR algorithms are required to generate high-resolution video sequences frame by frame in real time. To address such challenges, we propose an extremely low-latency VSR algorithm based on a novel kernel knowledge transfer method, named convolutional kernel bypass graft (CKBG). First, we design a lightweight network structure that does not require future frames as inputs and saves extra time costs for caching these frames. Then, our proposed CKBG method enhances this lightweight base model by bypassing the original network with ``kernel grafts'', which are extra convolutional kernels containing the prior knowledge of external pretrained image SR models. In the testing phase, we further accelerate the grafted multi-branch network by converting it into a simple single-path structure. Experiment results show that our proposed method can process online video sequences up to 110 FPS, with very low model complexity and competitive SR performance.
Hamiltonian prior to Disentangle Content and Motion in Image Sequences
Dec 02, 2021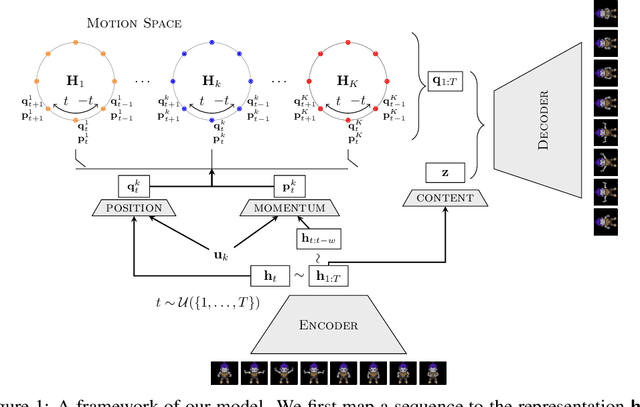
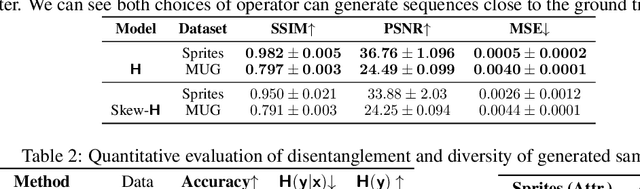


We present a deep latent variable model for high dimensional sequential data. Our model factorises the latent space into content and motion variables. To model the diverse dynamics, we split the motion space into subspaces, and introduce a unique Hamiltonian operator for each subspace. The Hamiltonian formulation provides reversible dynamics that learn to constrain the motion path to conserve invariant properties. The explicit split of the motion space decomposes the Hamiltonian into symmetry groups and gives long-term separability of the dynamics. This split also means representations can be learnt that are easy to interpret and control. We demonstrate the utility of our model for swapping the motion of two videos, generating sequences of various actions from a given image and unconditional sequence generation.
VPIT: Real-time Embedded Single Object 3D Tracking Using Voxel Pseudo Images
Jun 06, 2022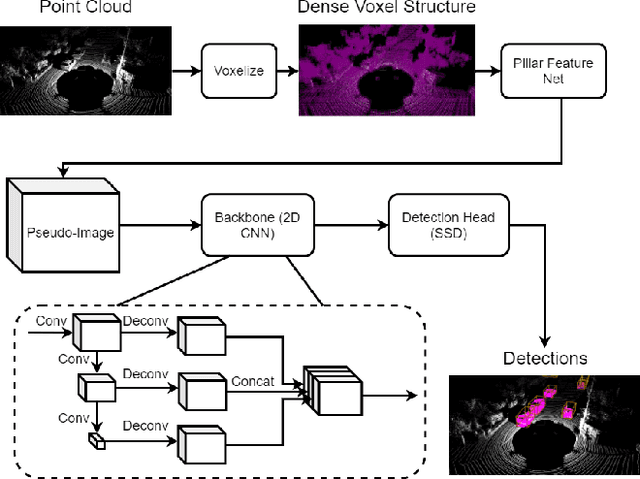
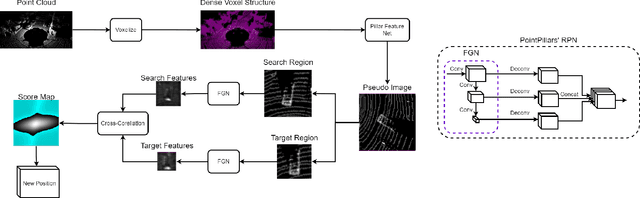


In this paper, we propose a novel voxel-based 3D single object tracking (3D SOT) method called Voxel Pseudo Image Tracking (VPIT). VPIT is the first method that uses voxel pseudo images for 3D SOT. The input point cloud is structured by pillar-based voxelization, and the resulting pseudo image is used as an input to a 2D-like Siamese SOT method. The pseudo image is created in the Bird's-eye View (BEV) coordinates, and therefore the objects in it have constant size. Thus, only the object rotation can change in the new coordinate system and not the object scale. For this reason, we replace multi-scale search with a multi-rotation search, where differently rotated search regions are compared against a single target representation to predict both position and rotation of the object. Experiments on KITTI Tracking dataset show that VPIT is the fastest 3D SOT method and maintains competitive Success and Precision values. Application of a SOT method in a real-world scenario meets with limitations such as lower computational capabilities of embedded devices and a latency-unforgiving environment, where the method is forced to skip certain data frames if the inference speed is not high enough. We implement a real-time evaluation protocol and show that other methods lose most of their performance on embedded devices, while VPIT maintains its ability to track the object.
Image-to-Image Translation of Synthetic Samples for Rare Classes
Jun 23, 2021
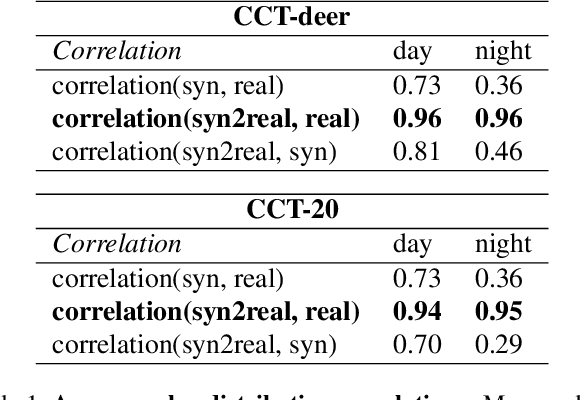
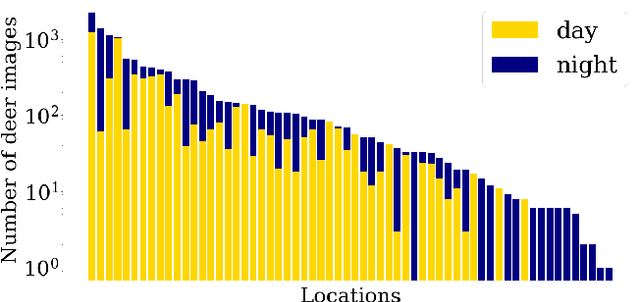
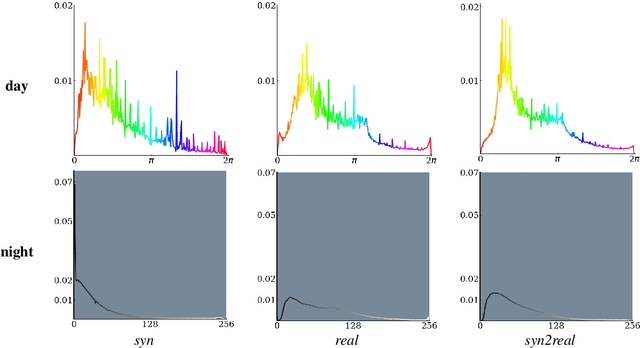
The natural world is long-tailed: rare classes are observed orders of magnitudes less frequently than common ones, leading to highly-imbalanced data where rare classes can have only handfuls of examples. Learning from few examples is a known challenge for deep learning based classification algorithms, and is the focus of the field of low-shot learning. One potential approach to increase the training data for these rare classes is to augment the limited real data with synthetic samples. This has been shown to help, but the domain shift between real and synthetic hinders the approaches' efficacy when tested on real data. We explore the use of image-to-image translation methods to close the domain gap between synthetic and real imagery for animal species classification in data collected from camera traps: motion-activated static cameras used to monitor wildlife. We use low-level feature alignment between source and target domains to make synthetic data for a rare species generated using a graphics engine more "realistic". Compared against a system augmented with unaligned synthetic data, our experiments show a considerable decrease in classification error rates on a rare species.
Is current research on adversarial robustness addressing the right problem?
Aug 04, 2022
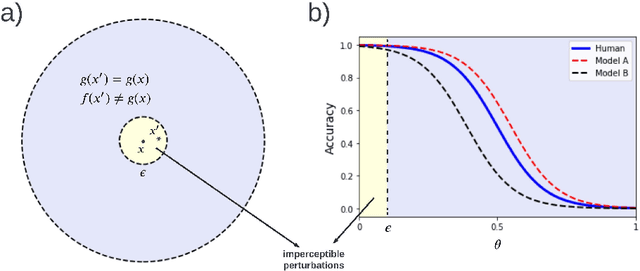
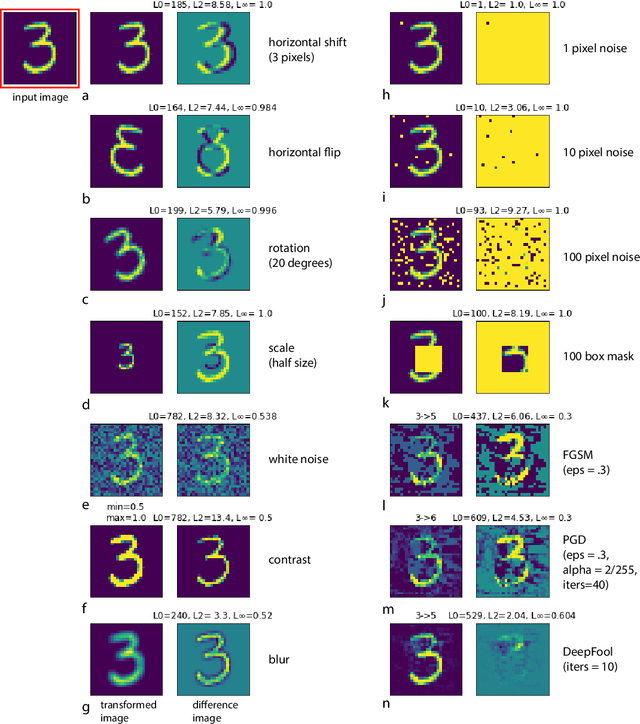
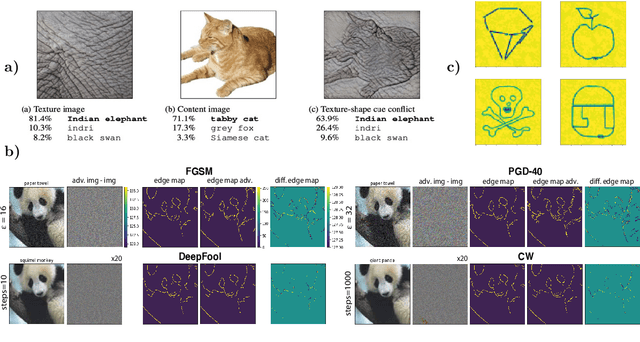
Short answer: Yes, Long answer: No! Indeed, research on adversarial robustness has led to invaluable insights helping us understand and explore different aspects of the problem. Many attacks and defenses have been proposed over the last couple of years. The problem, however, remains largely unsolved and poorly understood. Here, I argue that the current formulation of the problem serves short term goals, and needs to be revised for us to achieve bigger gains. Specifically, the bound on perturbation has created a somewhat contrived setting and needs to be relaxed. This has misled us to focus on model classes that are not expressive enough to begin with. Instead, inspired by human vision and the fact that we rely more on robust features such as shape, vertices, and foreground objects than non-robust features such as texture, efforts should be steered towards looking for significantly different classes of models. Maybe instead of narrowing down on imperceptible adversarial perturbations, we should attack a more general problem which is finding architectures that are simultaneously robust to perceptible perturbations, geometric transformations (e.g. rotation, scaling), image distortions (lighting, blur), and more (e.g. occlusion, shadow). Only then we may be able to solve the problem of adversarial vulnerability.
Rapid model transfer for medical image segmentation via iterative human-in-the-loop update: from labelled public to unlabelled clinical datasets for multi-organ segmentation in CT
Apr 13, 2022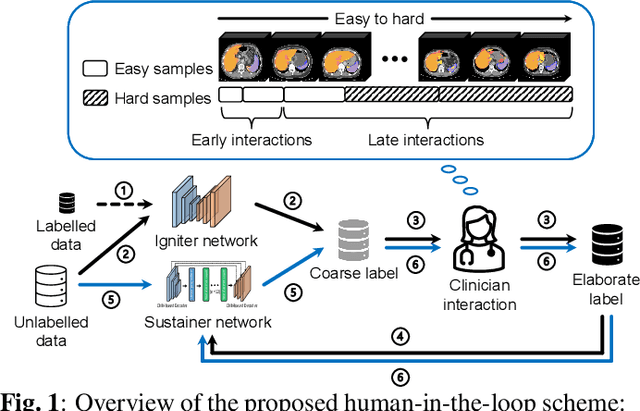
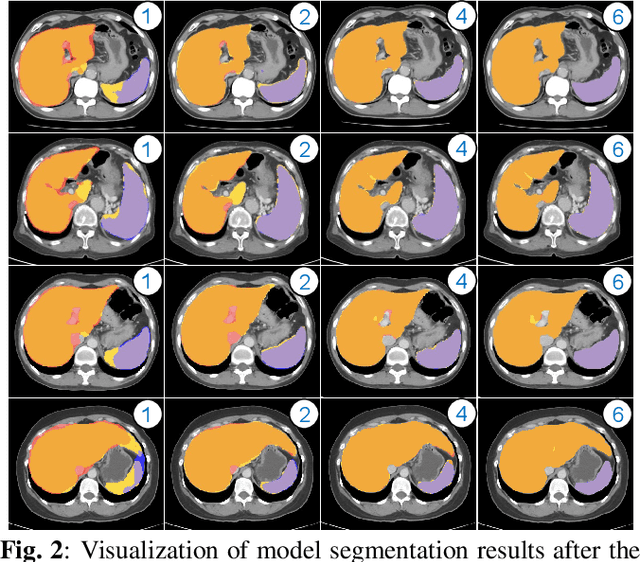
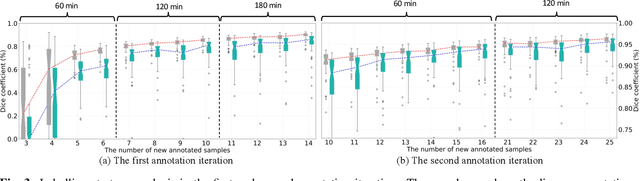
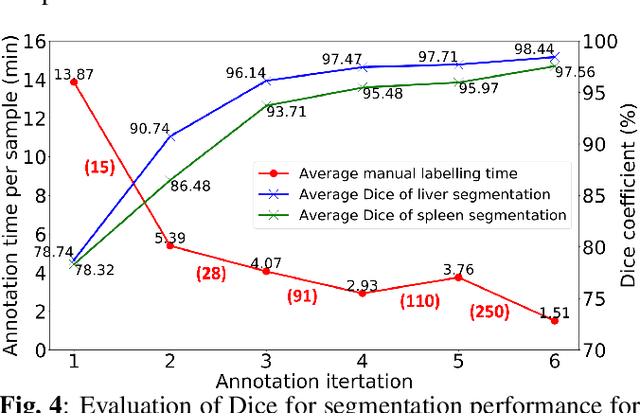
Despite the remarkable success on medical image analysis with deep learning, it is still under exploration regarding how to rapidly transfer AI models from one dataset to another for clinical applications. This paper presents a novel and generic human-in-the-loop scheme for efficiently transferring a segmentation model from a small-scale labelled dataset to a larger-scale unlabelled dataset for multi-organ segmentation in CT. To achieve this, we propose to use an igniter network which can learn from a small-scale labelled dataset and generate coarse annotations to start the process of human-machine interaction. Then, we use a sustainer network for our larger-scale dataset, and iteratively updated it on the new annotated data. Moreover, we propose a flexible labelling strategy for the annotator to reduce the initial annotation workload. The model performance and the time cost of annotation in each subject evaluated on our private dataset are reported and analysed. The results show that our scheme can not only improve the performance by 19.7% on Dice, but also expedite the cost time of manual labelling from 13.87 min to 1.51 min per CT volume during the model transfer, demonstrating the clinical usefulness with promising potentials.