 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Causality-inspired Single-source Domain Generalization for Medical Image Segmentation
Dec 06, 2021
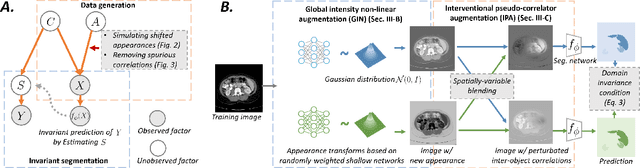
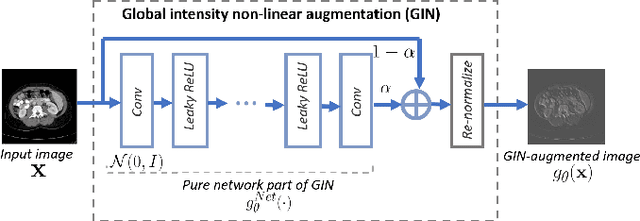
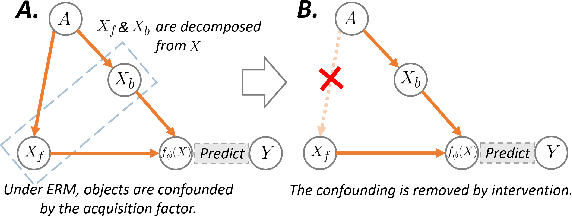
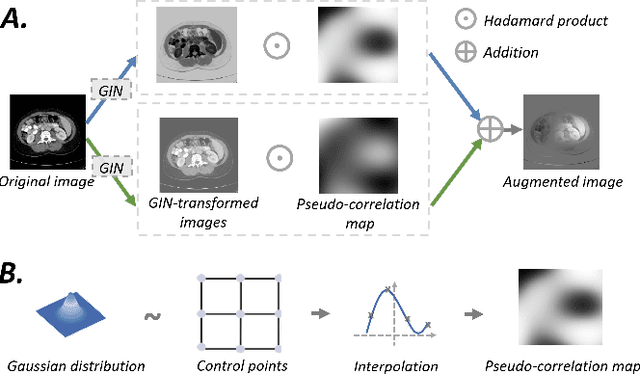
Deep learning models usually suffer from domain shift issues, where models trained on one source domain do not generalize well to other unseen domains. In this work, we investigate the single-source domain generalization problem: training a deep network that is robust to unseen domains, under the condition that training data is only available from one source domain, which is common in medical imaging applications. We tackle this problem in the context of cross-domain medical image segmentation. Under this scenario, domain shifts are mainly caused by different acquisition processes. We propose a simple causality-inspired data augmentation approach to expose a segmentation model to synthesized domain-shifted training examples. Specifically, 1) to make the deep model robust to discrepancies in image intensities and textures, we employ a family of randomly-weighted shallow networks. They augment training images using diverse appearance transformations. 2) Further we show that spurious correlations among objects in an image are detrimental to domain robustness. These correlations might be taken by the network as domain-specific clues for making predictions, and they may break on unseen domains. We remove these spurious correlations via causal intervention. This is achieved by resampling the appearances of potentially correlated objects independently. The proposed approach is validated on three cross-domain segmentation tasks: cross-modality (CT-MRI) abdominal image segmentation, cross-sequence (bSSFP-LGE) cardiac MRI segmentation, and cross-center prostate MRI segmentation. The proposed approach yields consistent performance gains compared with competitive methods when tested on unseen domains.
Attention Spiking Neural Networks
Sep 28, 2022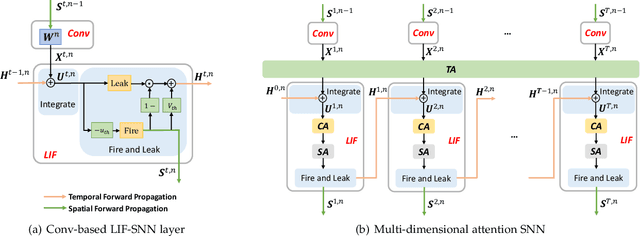
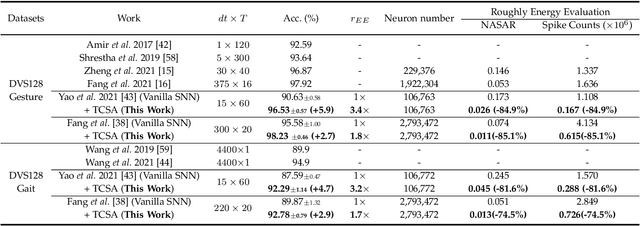
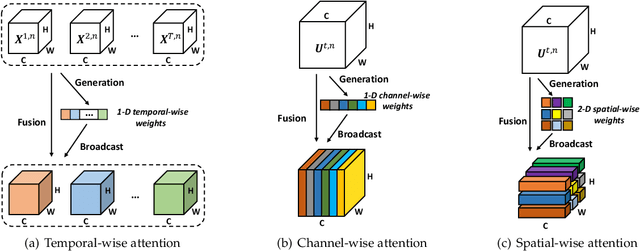
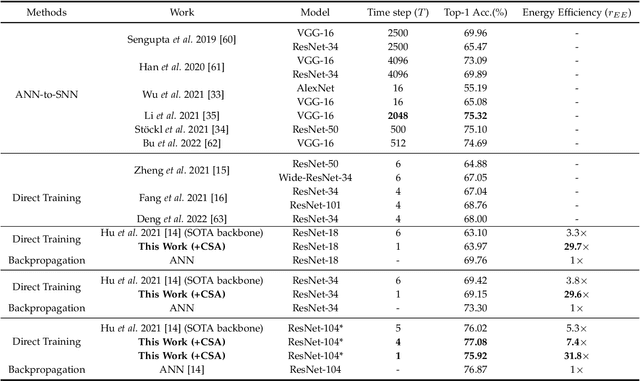
Benefiting from the event-driven and sparse spiking characteristics of the brain, spiking neural networks (SNNs) are becoming an energy-efficient alternative to artificial neural networks (ANNs). However, the performance gap between SNNs and ANNs has been a great hindrance to deploying SNNs ubiquitously for a long time. To leverage the full potential of SNNs, we study the effect of attention mechanisms in SNNs. We first present our idea of attention with a plug-and-play kit, termed the Multi-dimensional Attention (MA). Then, a new attention SNN architecture with end-to-end training called "MA-SNN" is proposed, which infers attention weights along the temporal, channel, as well as spatial dimensions separately or simultaneously. Based on the existing neuroscience theories, we exploit the attention weights to optimize membrane potentials, which in turn regulate the spiking response in a data-dependent way. At the cost of negligible additional parameters, MA facilitates vanilla SNNs to achieve sparser spiking activity, better performance, and energy efficiency concurrently. Experiments are conducted in event-based DVS128 Gesture/Gait action recognition and ImageNet-1k image classification. On Gesture/Gait, the spike counts are reduced by 84.9%/81.6%, and the task accuracy and energy efficiency are improved by 5.9%/4.7% and 3.4$\times$/3.2$\times$. On ImageNet-1K, we achieve top-1 accuracy of 75.92% and 77.08% on single/4-step Res-SNN-104, which are state-of-the-art results in SNNs. To our best knowledge, this is for the first time, that the SNN community achieves comparable or even better performance compared with its ANN counterpart in the large-scale dataset. Our work lights up SNN's potential as a general backbone to support various applications for SNNs, with a great balance between effectiveness and efficiency.
Incremental Learning in Semantic Segmentation from Image Labels
Dec 03, 2021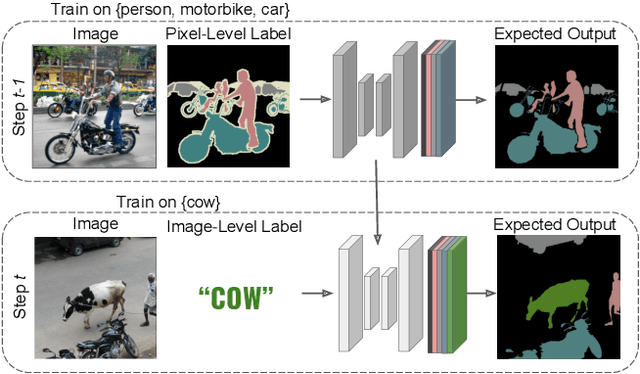
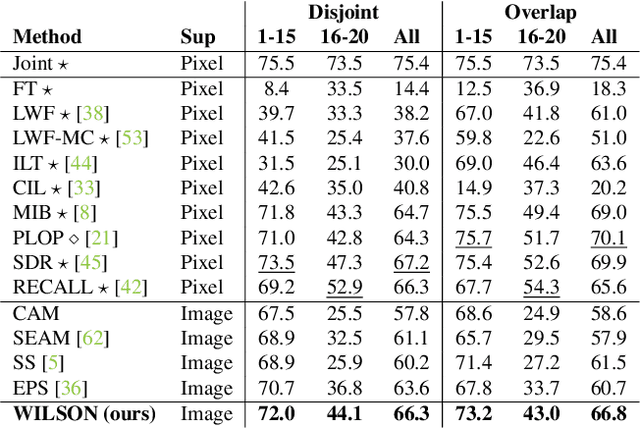
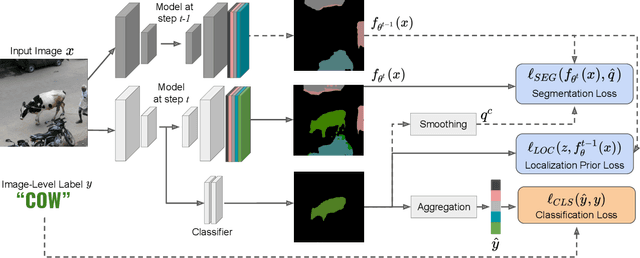
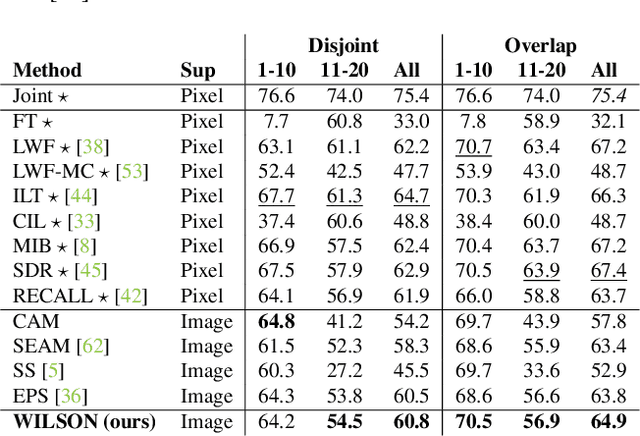
Although existing semantic segmentation approaches achieve impressive results, they still struggle to update their models incrementally as new categories are uncovered. Furthermore, pixel-by-pixel annotations are expensive and time-consuming. This paper proposes a novel framework for Weakly Incremental Learning for Semantic Segmentation, that aims at learning to segment new classes from cheap and largely available image-level labels. As opposed to existing approaches, that need to generate pseudo-labels offline, we use an auxiliary classifier, trained with image-level labels and regularized by the segmentation model, to obtain pseudo-supervision online and update the model incrementally. We cope with the inherent noise in the process by using soft-labels generated by the auxiliary classifier. We demonstrate the effectiveness of our approach on the Pascal VOC and COCO datasets, outperforming offline weakly-supervised methods and obtaining results comparable with incremental learning methods with full supervision.
Fuse and Attend: Generalized Embedding Learning for Art and Sketches
Aug 20, 2022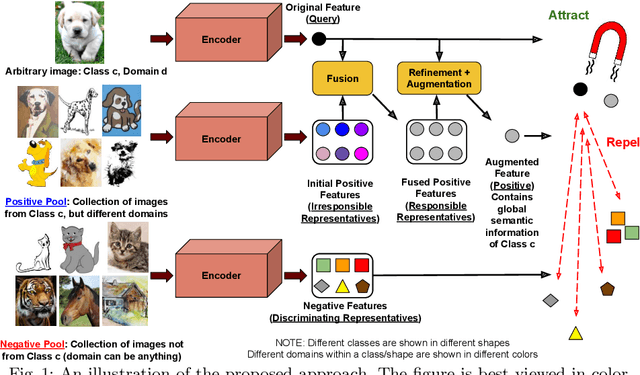
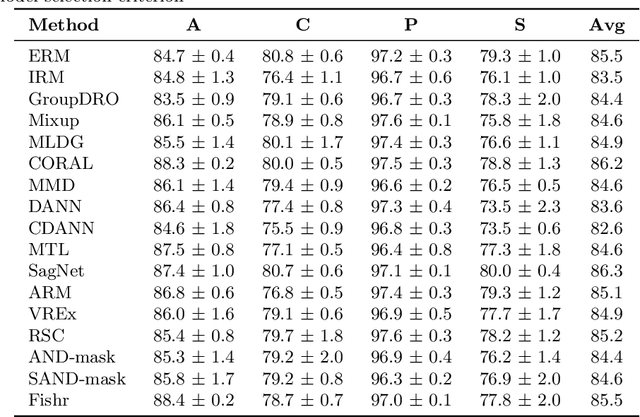
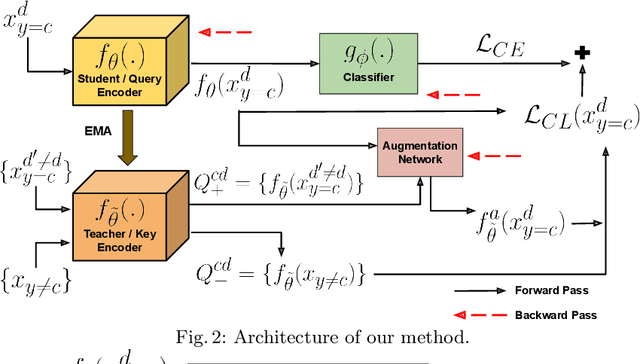
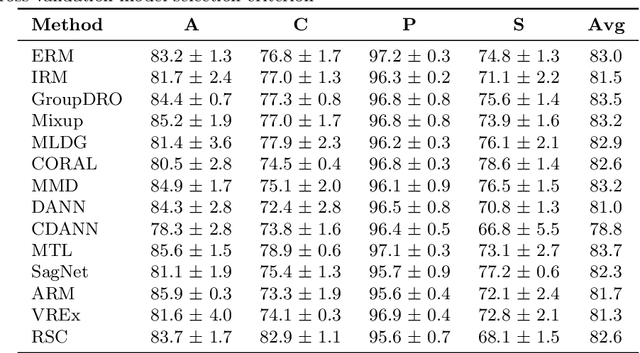
While deep Embedding Learning approaches have witnessed widespread success in multiple computer vision tasks, the state-of-the-art methods for representing natural images need not necessarily perform well on images from other domains, such as paintings, cartoons, and sketch. This is because of the huge shift in the distribution of data from across these domains, as compared to natural images. Domains like sketch often contain sparse informative pixels. However, recognizing objects in such domains is crucial, given multiple relevant applications leveraging such data, for instance, sketch to image retrieval. Thus, achieving an Embedding Learning model that could perform well across multiple domains is not only challenging, but plays a pivotal role in computer vision. To this end, in this paper, we propose a novel Embedding Learning approach with the goal of generalizing across different domains. During training, given a query image from a domain, we employ gated fusion and attention to generate a positive example, which carries a broad notion of the semantics of the query object category (from across multiple domains). By virtue of Contrastive Learning, we pull the embeddings of the query and positive, in order to learn a representation which is robust across domains. At the same time, to teach the model to be discriminative against examples from different semantic categories (across domains), we also maintain a pool of negative embeddings (from different categories). We show the prowess of our method using the DomainBed framework, on the popular PACS (Photo, Art painting, Cartoon, and Sketch) dataset.
Adaptive 3D Localization of 2D Freehand Ultrasound Brain Images
Sep 12, 2022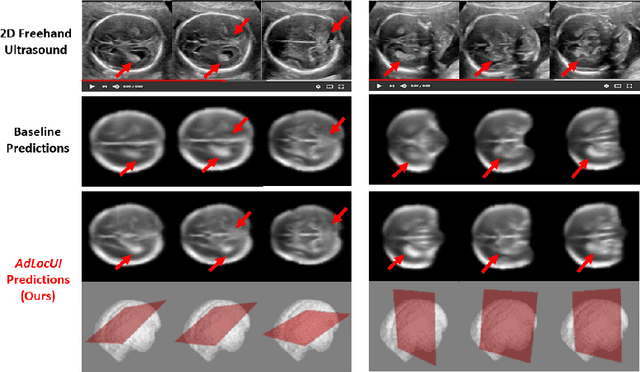
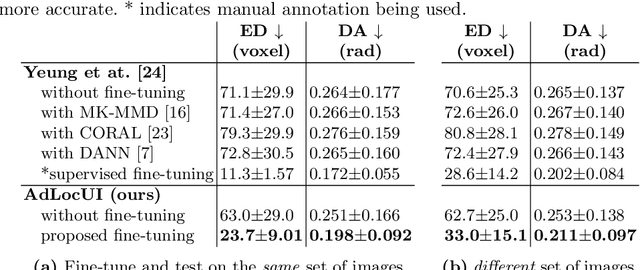
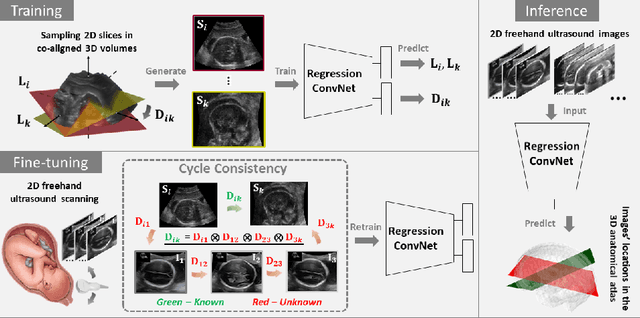
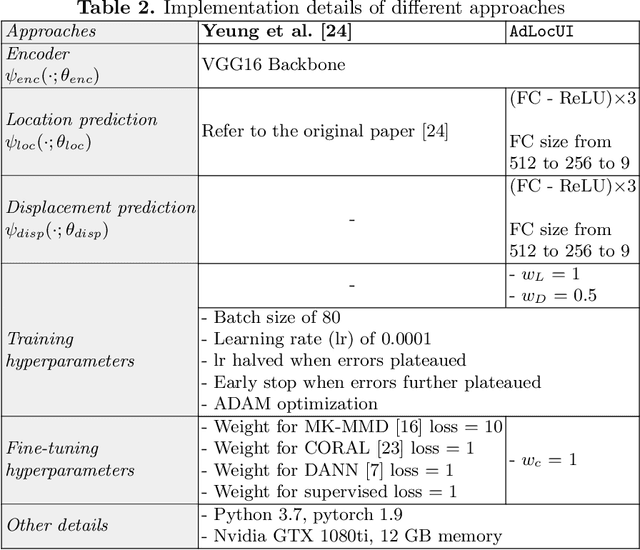
Two-dimensional (2D) freehand ultrasound is the mainstay in prenatal care and fetal growth monitoring. The task of matching corresponding cross-sectional planes in the 3D anatomy for a given 2D ultrasound brain scan is essential in freehand scanning, but challenging. We propose AdLocUI, a framework that Adaptively Localizes 2D Ultrasound Images in the 3D anatomical atlas without using any external tracking sensor.. We first train a convolutional neural network with 2D slices sampled from co-aligned 3D ultrasound volumes to predict their locations in the 3D anatomical atlas. Next, we fine-tune it with 2D freehand ultrasound images using a novel unsupervised cycle consistency, which utilizes the fact that the overall displacement of a sequence of images in the 3D anatomical atlas is equal to the displacement from the first image to the last in that sequence. We demonstrate that AdLocUI can adapt to three different ultrasound datasets, acquired with different machines and protocols, and achieves significantly better localization accuracy than the baselines. AdLocUI can be used for sensorless 2D freehand ultrasound guidance by the bedside. The source code is available at https://github.com/pakheiyeung/AdLocUI.
Artifact- and content-specific quality assessment for MRI with image rulers
Nov 06, 2021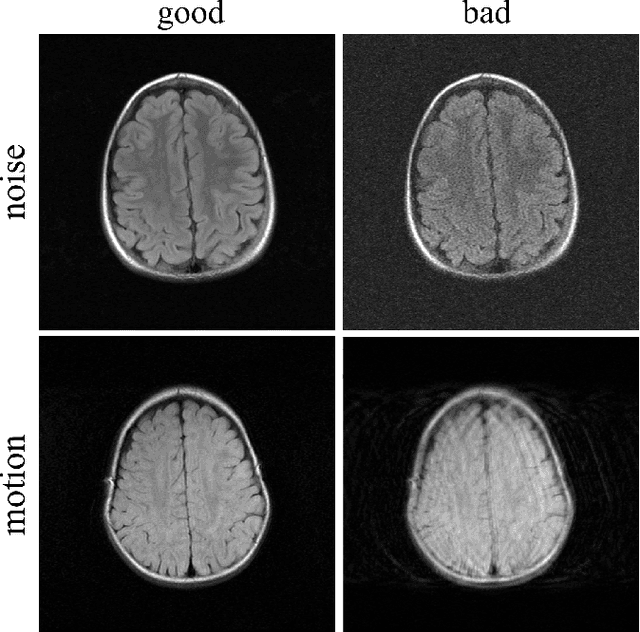

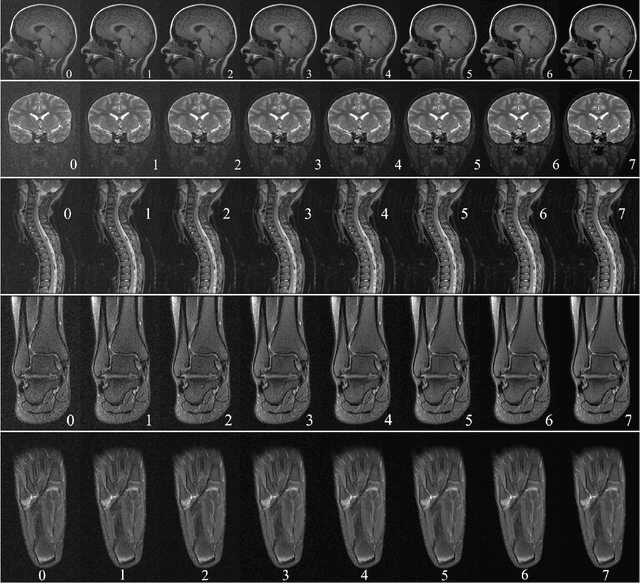

In clinical practice MR images are often first seen by radiologists long after the scan. If image quality is inadequate either patients have to return for an additional scan, or a suboptimal interpretation is rendered. An automatic image quality assessment (IQA) would enable real-time remediation. Existing IQA works for MRI give only a general quality score, agnostic to the cause of and solution to low-quality scans. Furthermore, radiologists' image quality requirements vary with the scan type and diagnostic task. Therefore, the same score may have different implications for different scans. We propose a framework with multi-task CNN model trained with calibrated labels and inferenced with image rulers. Labels calibrated by human inputs follow a well-defined and efficient labeling task. Image rulers address varying quality standards and provide a concrete way of interpreting raw scores from the CNN. The model supports assessments of two of the most common artifacts in MRI: noise and motion. It achieves accuracies of around 90%, 6% better than the best previous method examined, and 3% better than human experts on noise assessment. Our experiments show that label calibration, image rulers, and multi-task training improve the model's performance and generalizability.
Memory-Based Label-Text Tuning for Few-Shot Class-Incremental Learning
Jul 03, 2022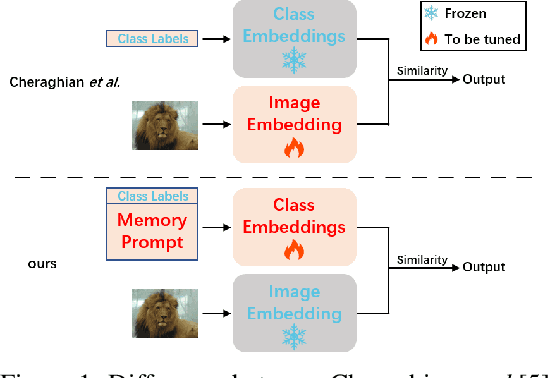
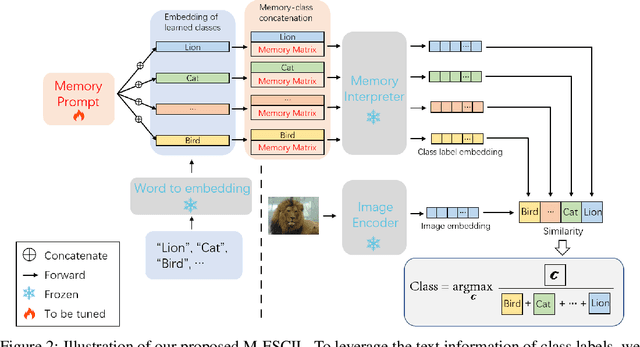
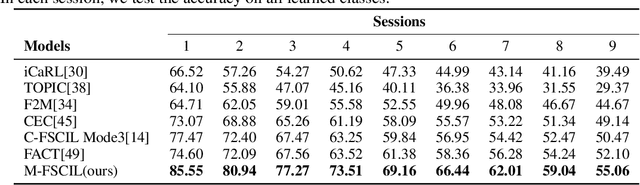
Few-shot class-incremental learning(FSCIL) focuses on designing learning algorithms that can continually learn a sequence of new tasks from a few samples without forgetting old ones. The difficulties are that training on a sequence of limited data from new tasks leads to severe overfitting issues and causes the well-known catastrophic forgetting problem. Existing researches mainly utilize the image information, such as storing the image knowledge of previous tasks or limiting classifiers updating. However, they ignore analyzing the informative and less noisy text information of class labels. In this work, we propose leveraging the label-text information by adopting the memory prompt. The memory prompt can learn new data sequentially, and meanwhile store the previous knowledge. Furthermore, to optimize the memory prompt without undermining the stored knowledge, we propose a stimulation-based training strategy. It optimizes the memory prompt depending on the image embedding stimulation, which is the distribution of the image embedding elements. Experiments show that our proposed method outperforms all prior state-of-the-art approaches, significantly mitigating the catastrophic forgetting and overfitting problems.
Self-supervised Sequential Information Bottleneck for Robust Exploration in Deep Reinforcement Learning
Sep 12, 2022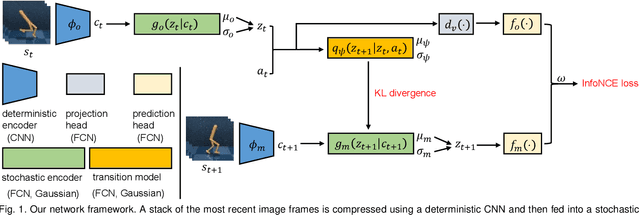
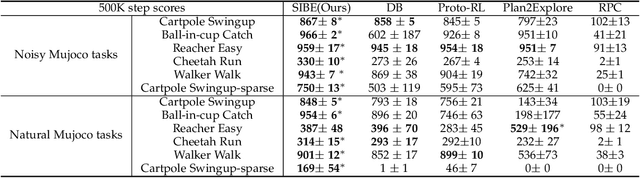
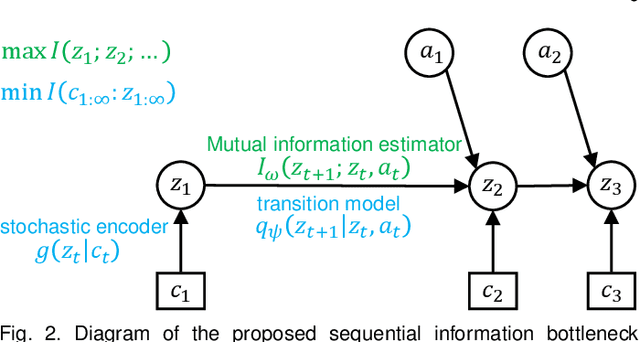

Effective exploration is critical for reinforcement learning agents in environments with sparse rewards or high-dimensional state-action spaces. Recent works based on state-visitation counts, curiosity and entropy-maximization generate intrinsic reward signals to motivate the agent to visit novel states for exploration. However, the agent can get distracted by perturbations to sensor inputs that contain novel but task-irrelevant information, e.g. due to sensor noise or changing background. In this work, we introduce the sequential information bottleneck objective for learning compressed and temporally coherent representations by modelling and compressing sequential predictive information in time-series observations. For efficient exploration in noisy environments, we further construct intrinsic rewards that capture task-relevant state novelty based on the learned representations. We derive a variational upper bound of our sequential information bottleneck objective for practical optimization and provide an information-theoretic interpretation of the derived upper bound. Our experiments on a set of challenging image-based simulated control tasks show that our method achieves better sample efficiency, and robustness to both white noise and natural video backgrounds compared to state-of-art methods based on curiosity, entropy maximization and information-gain.
An Access Control Method with Secret Key for Semantic Segmentation Models
Aug 28, 2022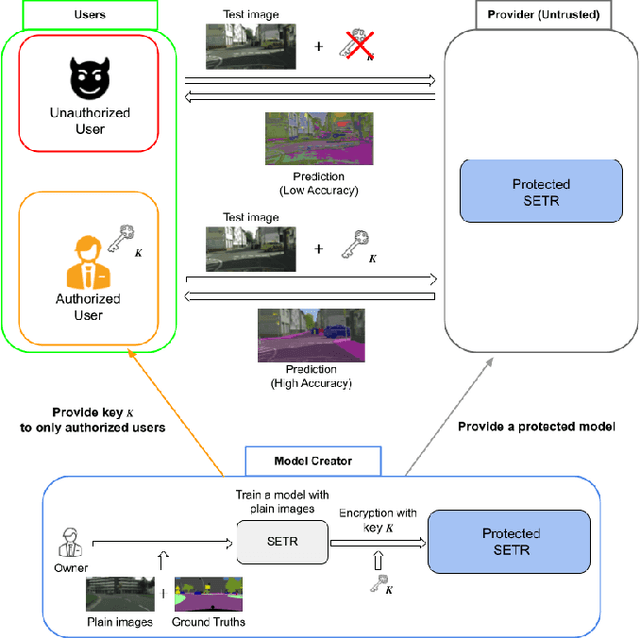
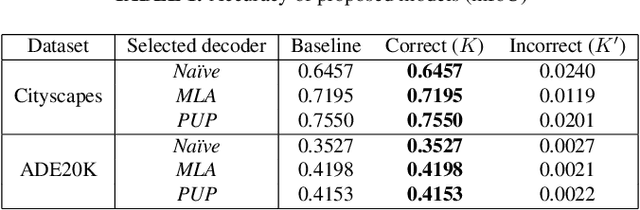

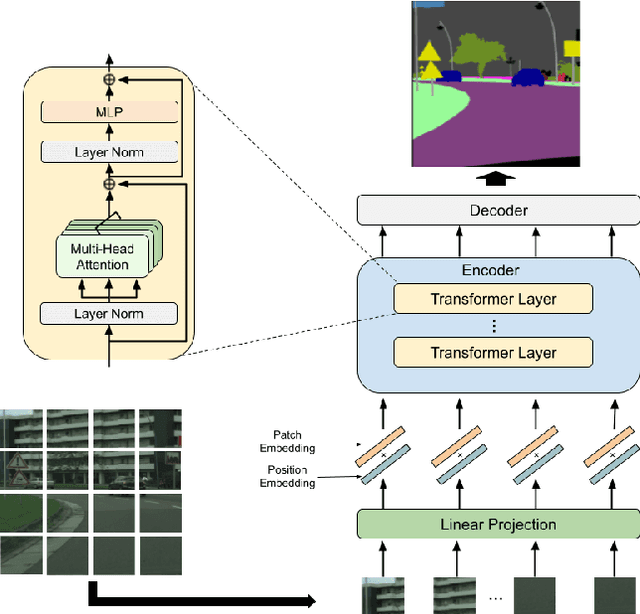
A novel method for access control with a secret key is proposed to protect models from unauthorized access in this paper. We focus on semantic segmentation models with the vision transformer (ViT), called segmentation transformer (SETR). Most existing access control methods focus on image classification tasks, or they are limited to CNNs. By using a patch embedding structure that ViT has, trained models and test images can be efficiently encrypted with a secret key, and then semantic segmentation tasks are carried out in the encrypted domain. In an experiment, the method is confirmed to provide the same accuracy as that of using plain images without any encryption to authorized users with a correct key and also to provide an extremely degraded accuracy to unauthorized users.
Inflating 2D Convolution Weights for Efficient Generation of 3D Medical Images
Aug 08, 2022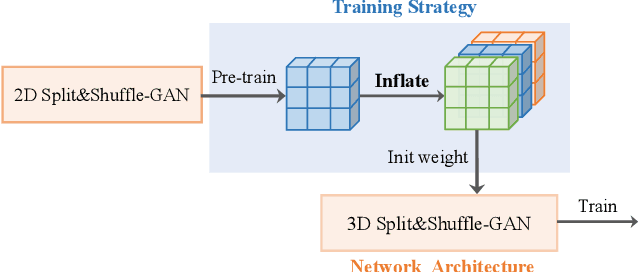
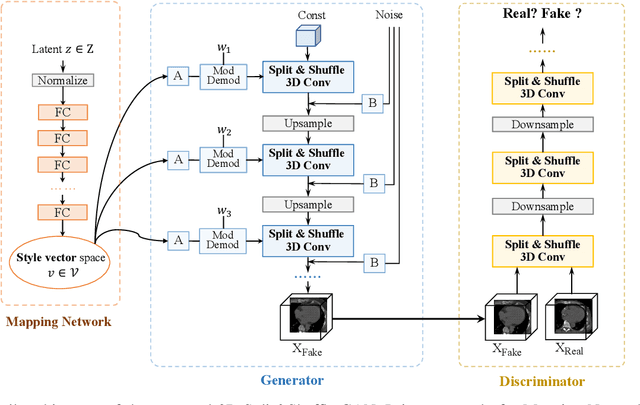
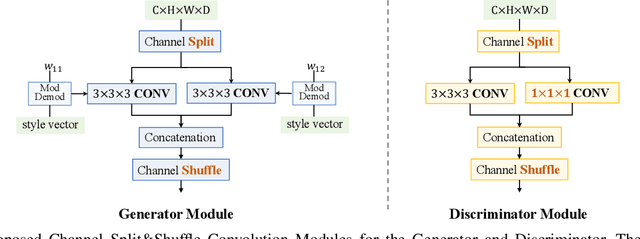
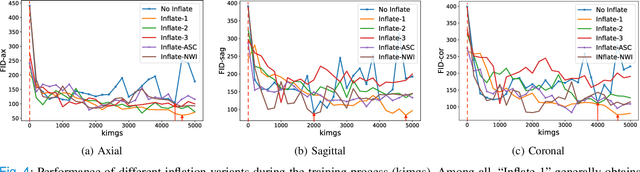
The generation of three-dimensional (3D) medical images can have great application potential since it takes into account the 3D anatomical structure. There are two problems, however, that prevent effective training of a 3D medical generative model: (1) 3D medical images are very expensive to acquire and annotate, resulting in an insufficient number of training images, (2) a large number of parameters are involved in 3D convolution. To address both problems, we propose a novel GAN model called 3D Split&Shuffle-GAN. In order to address the 3D data scarcity issue, we first pre-train a two-dimensional (2D) GAN model using abundant image slices and inflate the 2D convolution weights to improve initialization of the 3D GAN. Novel 3D network architectures are proposed for both the generator and discriminator of the GAN model to significantly reduce the number of parameters while maintaining the quality of image generation. A number of weight inflation strategies and parameter-efficient 3D architectures are investigated. Experiments on both heart (Stanford AIMI Coronary Calcium) and brain (Alzheimer's Disease Neuroimaging Initiative) datasets demonstrate that the proposed approach leads to improved 3D images generation quality with significantly fewer parameters.