 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Rigidity Preserving Image Transformations and Equivariance in Perspective
Jan 31, 2022




We characterize the class of image plane transformations which realize rigid camera motions and call these transformations `rigidity preserving'. In particular, 2D translations of pinhole images are not rigidity preserving. Hence, when using CNNs for 3D inference tasks, it can be beneficial to modify the inductive bias from equivariance towards translations to equivariance towards rigidity preserving transformations. We investigate how equivariance with respect to rigidity preserving transformations can be approximated in CNNs, and test our ideas on both 6D object pose estimation and visual localization. Experimentally, we improve on several competitive baselines.
A Few Shot Multi-Representation Approach for N-gram Spotting in Historical Manuscripts
Sep 21, 2022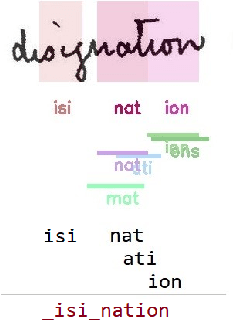
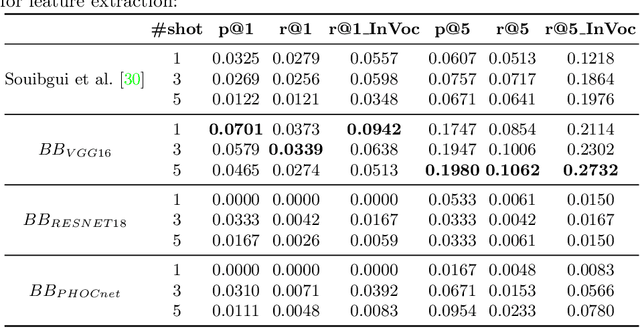
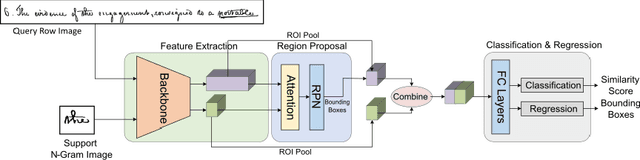
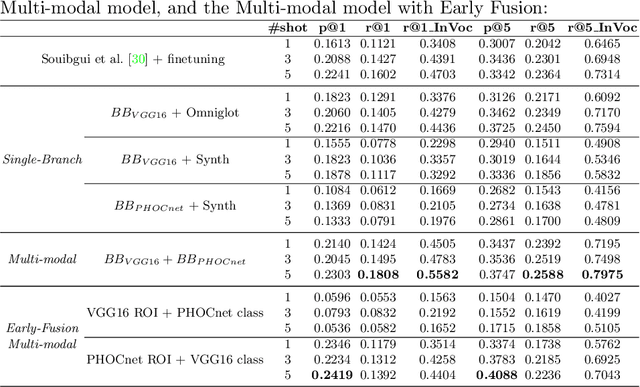
Despite recent advances in automatic text recognition, the performance remains moderate when it comes to historical manuscripts. This is mainly because of the scarcity of available labelled data to train the data-hungry Handwritten Text Recognition (HTR) models. The Keyword Spotting System (KWS) provides a valid alternative to HTR due to the reduction in error rate, but it is usually limited to a closed reference vocabulary. In this paper, we propose a few-shot learning paradigm for spotting sequences of a few characters (N-gram) that requires a small amount of labelled training data. We exhibit that recognition of important n-grams could reduce the system's dependency on vocabulary. In this case, an out-of-vocabulary (OOV) word in an input handwritten line image could be a sequence of n-grams that belong to the lexicon. An extensive experimental evaluation of our proposed multi-representation approach was carried out on a subset of Bentham's historical manuscript collections to obtain some really promising results in this direction.
Two Dimensional Sparse-Regularization-Based InSAR Imaging with Back-Projection Embedding
Sep 21, 2022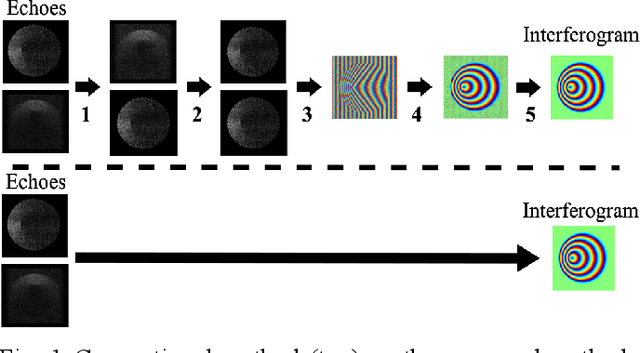
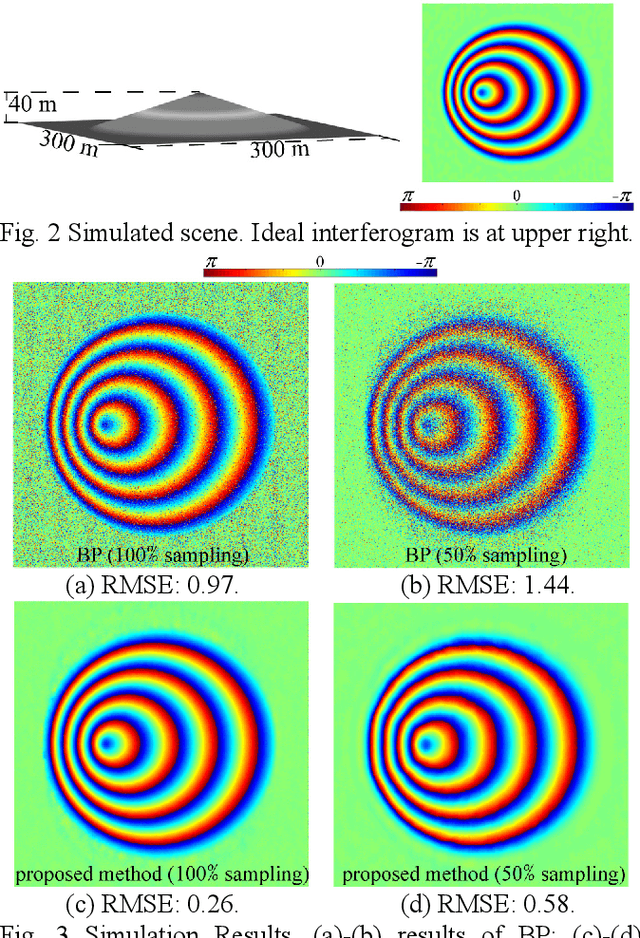
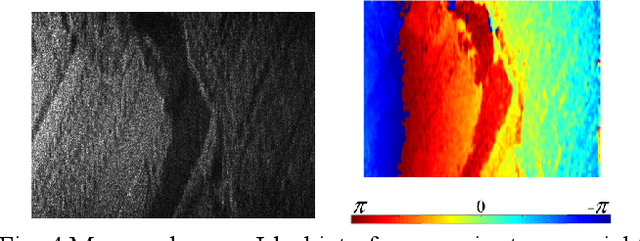
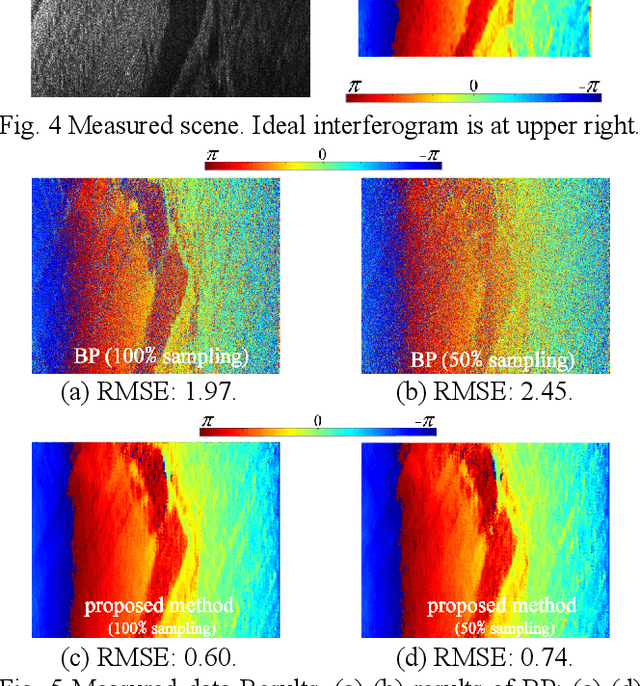
Interferometric Synthetic Aperture Radar (InSAR) Imaging methods are usually based on algorithms of match-filtering type, without considering the scene's characteristic, which causes limited imaging quality. Besides, post-processing steps are inevitable, like image registration, flat-earth phase removing and phase noise filtering. To solve these problems, we propose a new InSAR imaging method. First, to enhance the imaging quality, we propose a new imaging framework base on 2D sparse regularization, where the characteristic of scene is embedded. Second, to avoid the post processing steps, we establish a new forward observation process, where the back-projection imaging method is embedded. Third, a forward and backward iterative solution method is proposed based on proximal gradient descent algorithm. Experiments on simulated and measured data reveal the effectiveness of the proposed method. Compared with the conventional method, higher quality interferogram can be obtained directly from raw echoes without post-processing. Besides, in the under-sampling situation, it's also applicable.
Transformer-CNN Cohort: Semi-supervised Semantic Segmentation by the Best of Both Students
Sep 06, 2022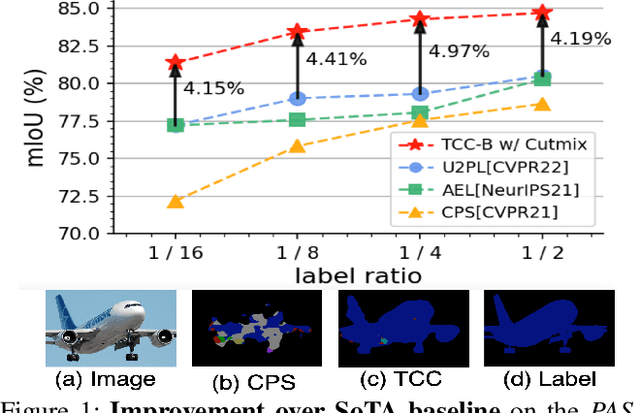
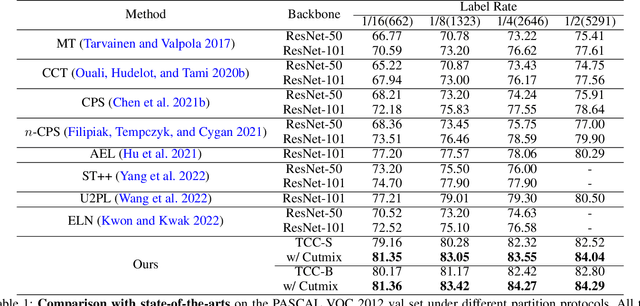
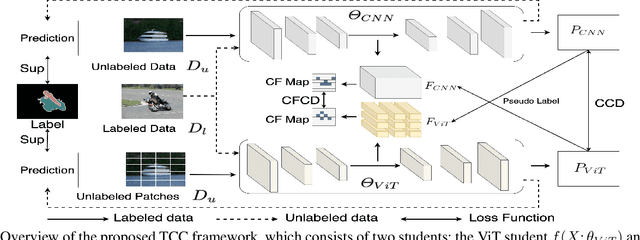
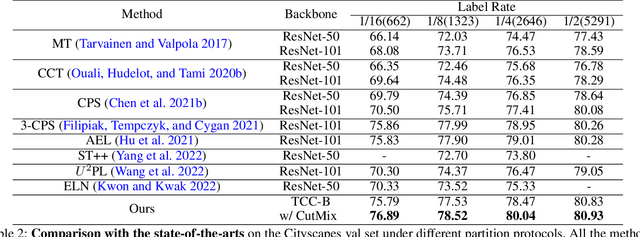
The popular methods for semi-supervised semantic segmentation mostly adopt a unitary network model using convolutional neural networks (CNNs) and enforce consistency of the model predictions over small perturbations applied to the inputs or model. However, such a learning paradigm suffers from a) limited learning capability of the CNN-based model; b) limited capacity of learning the discriminative features for the unlabeled data; c) limited learning for both global and local information from the whole image. In this paper, we propose a novel Semi-supervised Learning approach, called Transformer-CNN Cohort (TCC), that consists of two students with one based on the vision transformer (ViT) and the other based on the CNN. Our method subtly incorporates the multi-level consistency regularization on the predictions and the heterogeneous feature spaces via pseudo labeling for the unlabeled data. First, as the inputs of the ViT student are image patches, the feature maps extracted encode crucial class-wise statistics. To this end, we propose class-aware feature consistency distillation (CFCD) that first leverages the outputs of each student as the pseudo labels and generates class-aware feature (CF) maps. It then transfers knowledge via the CF maps between the students. Second, as the ViT student has more uniform representations for all layers, we propose consistency-aware cross distillation to transfer knowledge between the pixel-wise predictions from the cohort. We validate the TCC framework on Cityscapes and Pascal VOC 2012 datasets, which significantly outperforms existing semi-supervised methods by a large margin.
Multilayer deep feature extraction for visual texture recognition
Aug 22, 2022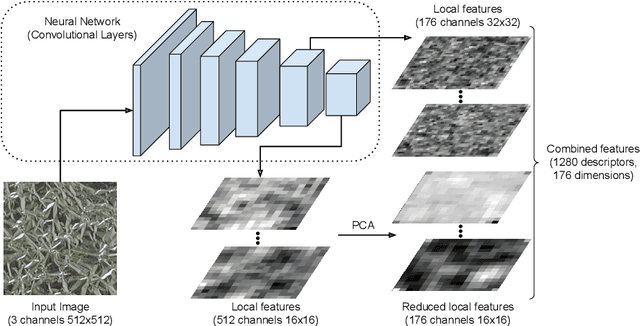
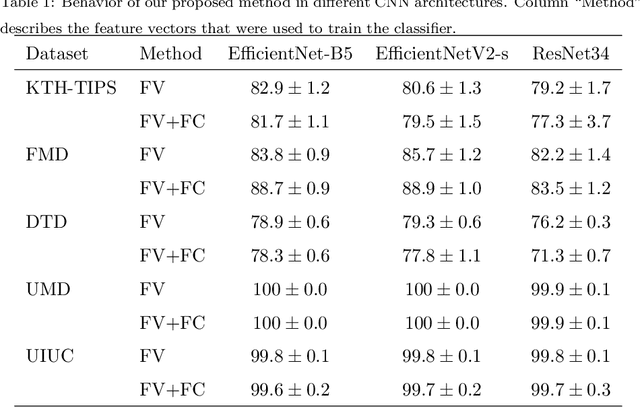
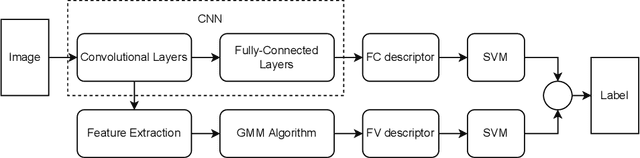
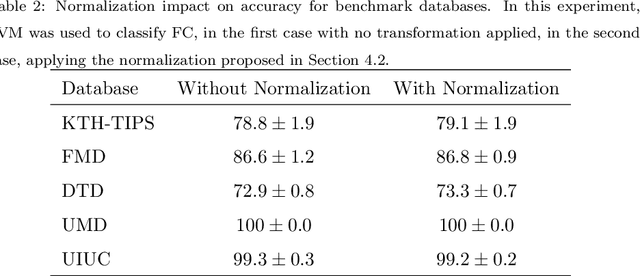
Convolutional neural networks have shown successful results in image classification achieving real-time results superior to the human level. However, texture images still pose some challenge to these models due, for example, to the limited availability of data for training in several problems where these images appear, high inter-class similarity, the absence of a global viewpoint of the object represented, and others. In this context, the present paper is focused on improving the accuracy of convolutional neural networks in texture classification. This is done by extracting features from multiple convolutional layers of a pretrained neural network and aggregating such features using Fisher vector. The reason for using features from earlier convolutional layers is obtaining information that is less domain specific. We verify the effectiveness of our method on texture classification of benchmark datasets, as well as on a practical task of Brazilian plant species identification. In both scenarios, Fisher vectors calculated on multiple layers outperform state-of-art methods, confirming that early convolutional layers provide important information about the texture image for classification.
FNeVR: Neural Volume Rendering for Face Animation
Sep 21, 2022
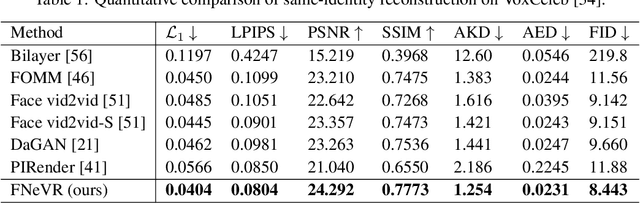
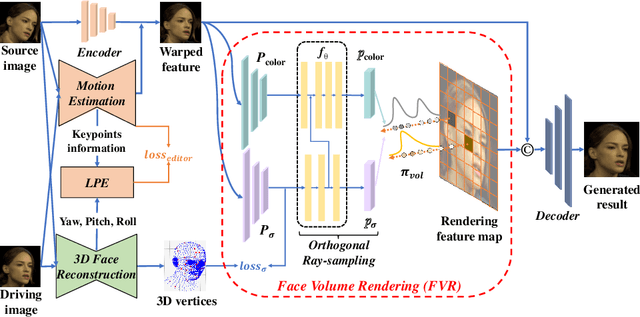
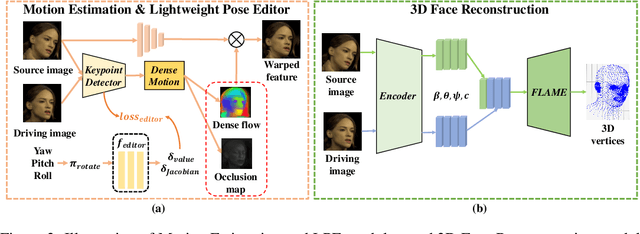
Face animation, one of the hottest topics in computer vision, has achieved a promising performance with the help of generative models. However, it remains a critical challenge to generate identity preserving and photo-realistic images due to the sophisticated motion deformation and complex facial detail modeling. To address these problems, we propose a Face Neural Volume Rendering (FNeVR) network to fully explore the potential of 2D motion warping and 3D volume rendering in a unified framework. In FNeVR, we design a 3D Face Volume Rendering (FVR) module to enhance the facial details for image rendering. Specifically, we first extract 3D information with a well-designed architecture, and then introduce an orthogonal adaptive ray-sampling module for efficient rendering. We also design a lightweight pose editor, enabling FNeVR to edit the facial pose in a simple yet effective way. Extensive experiments show that our FNeVR obtains the best overall quality and performance on widely used talking-head benchmarks.
Towards Diverse and Faithful One-shot Adaption of Generative Adversarial Networks
Jul 18, 2022

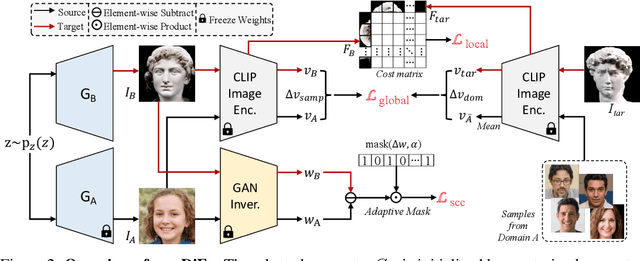

One-shot generative domain adaption aims to transfer a pre-trained generator on one domain to a new domain using one reference image only. However, it remains very challenging for the adapted generator (i) to generate diverse images inherited from the pre-trained generator while (ii) faithfully acquiring the domain-specific attributes and styles of the reference image. In this paper, we present a novel one-shot generative domain adaption method, i.e., DiFa, for diverse generation and faithful adaptation. For global-level adaptation, we leverage the difference between the CLIP embedding of reference image and the mean embedding of source images to constrain the target generator. For local-level adaptation, we introduce an attentive style loss which aligns each intermediate token of adapted image with its corresponding token of the reference image. To facilitate diverse generation, selective cross-domain consistency is introduced to select and retain the domain-sharing attributes in the editing latent $\mathcal{W}+$ space to inherit the diversity of pre-trained generator. Extensive experiments show that our method outperforms the state-of-the-arts both quantitatively and qualitatively, especially for the cases of large domain gaps. Moreover, our DiFa can easily be extended to zero-shot generative domain adaption with appealing results. Code is available at https://github.com/1170300521/DiFa.
Adaptive Weighted Guided Image Filtering for Depth Enhancement in Shape-From-Focus
Jan 18, 2022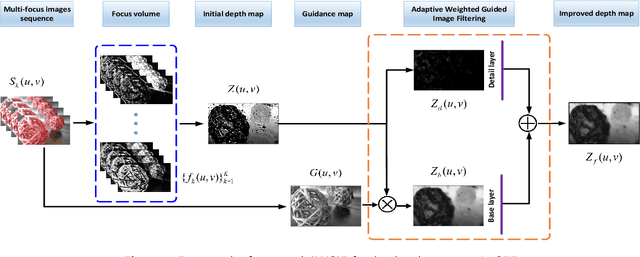



Existing shape from focus (SFF) techniques cannot preserve depth edges and fine structural details from a sequence of multi-focus images. Moreover, noise in the sequence of multi-focus images affects the accuracy of the depth map. In this paper, a novel depth enhancement algorithm for the SFF based on an adaptive weighted guided image filtering (AWGIF) is proposed to address the above issues. The AWGIF is applied to decompose an initial depth map which is estimated by the traditional SFF into a base layer and a detail layer. In order to preserve the edges accurately in the refined depth map, the guidance image is constructed from the multi-focus image sequence, and the coefficient of the AWGIF is utilized to suppress the noise while enhancing the fine depth details. Experiments on real and synthetic objects demonstrate the superiority of the proposed algorithm in terms of anti-noise, and the ability to preserve depth edges and fine structural details compared to existing methods.
Revisiting Neural Scaling Laws in Language and Vision
Sep 13, 2022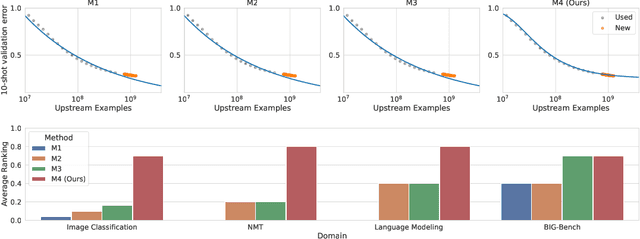
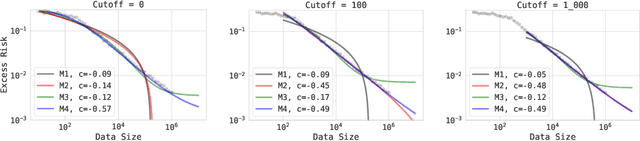
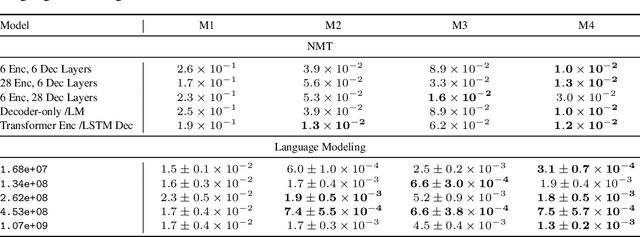
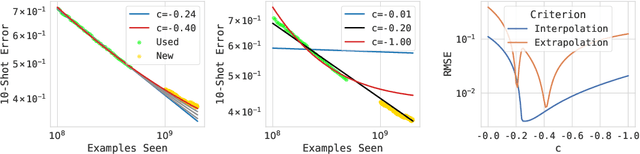
The remarkable progress in deep learning in recent years is largely driven by improvements in scale, where bigger models are trained on larger datasets for longer schedules. To predict the benefit of scale empirically, we argue for a more rigorous methodology based on the extrapolation loss, instead of reporting the best-fitting (interpolating) parameters. We then present a recipe for estimating scaling law parameters reliably from learning curves. We demonstrate that it extrapolates more accurately than previous methods in a wide range of architecture families across several domains, including image classification, neural machine translation (NMT) and language modeling, in addition to tasks from the BIG-Bench evaluation benchmark. Finally, we release a benchmark dataset comprising of 90 evaluation tasks to facilitate research in this domain.
Learning Deep Representations via Contrastive Learning for Instance Retrieval
Sep 28, 2022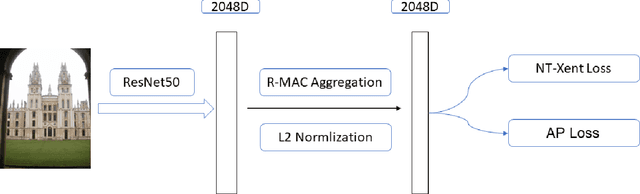
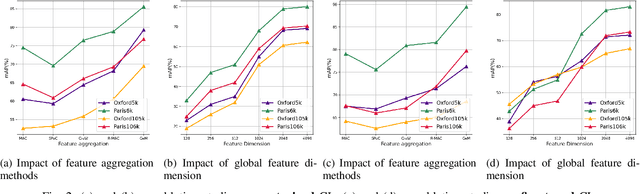


Instance-level Image Retrieval (IIR), or simply Instance Retrieval, deals with the problem of finding all the images within an dataset that contain a query instance (e.g. an object). This paper makes the first attempt that tackles this problem using instance-discrimination based contrastive learning (CL). While CL has shown impressive performance for many computer vision tasks, the similar success has never been found in the field of IIR. In this work, we approach this problem by exploring the capability of deriving discriminative representations from pre-trained and fine-tuned CL models. To begin with, we investigate the efficacy of transfer learning in IIR, by comparing off-the-shelf features learned by a pre-trained deep neural network (DNN) classifier with features learned by a CL model. The findings inspired us to propose a new training strategy that optimizes CL towards learning IIR-oriented features, by using an Average Precision (AP) loss together with a fine-tuning method to learn contrastive feature representations that are tailored to IIR. Our empirical evaluation demonstrates significant performance enhancement over the off-the-shelf features learned from a pre-trained DNN classifier on the challenging Oxford and Paris datasets.