 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Object Representation Learning using Translation and Rotation Group Equivariant VAE
Oct 24, 2022
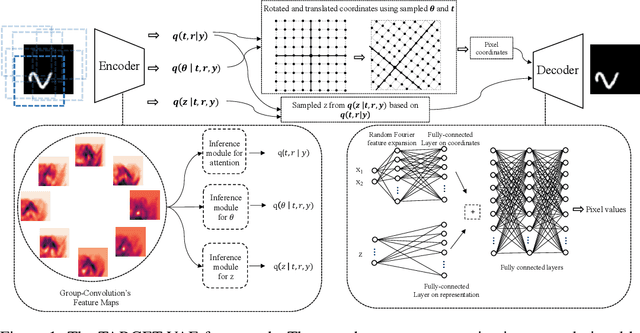
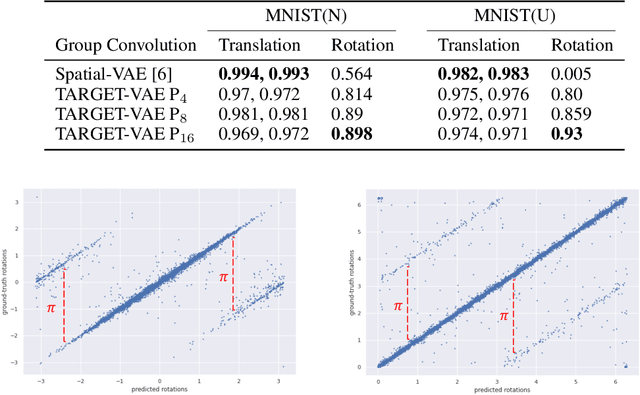
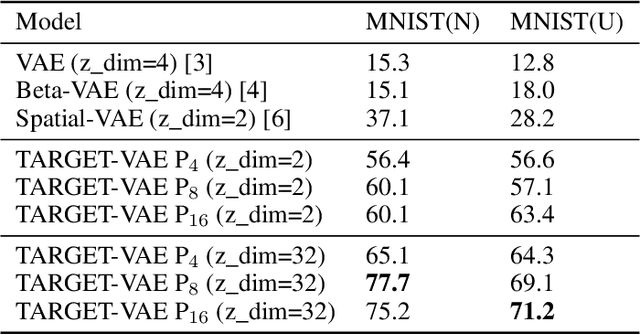
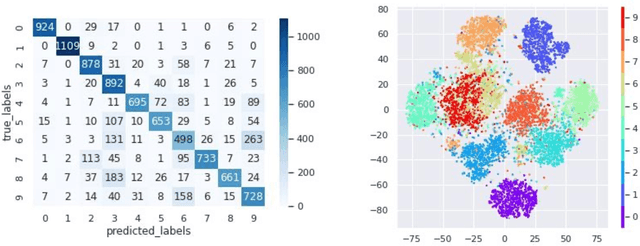
In many imaging modalities, objects of interest can occur in a variety of locations and poses (i.e. are subject to translations and rotations in 2d or 3d), but the location and pose of an object does not change its semantics (i.e. the object's essence). That is, the specific location and rotation of an airplane in satellite imagery, or the 3d rotation of a chair in a natural image, or the rotation of a particle in a cryo-electron micrograph, do not change the intrinsic nature of those objects. Here, we consider the problem of learning semantic representations of objects that are invariant to pose and location in a fully unsupervised manner. We address shortcomings in previous approaches to this problem by introducing TARGET-VAE, a translation and rotation group-equivariant variational autoencoder framework. TARGET-VAE combines three core innovations: 1) a rotation and translation group-equivariant encoder architecture, 2) a structurally disentangled distribution over latent rotation, translation, and a rotation-translation-invariant semantic object representation, which are jointly inferred by the approximate inference network, and 3) a spatially equivariant generator network. In comprehensive experiments, we show that TARGET-VAE learns disentangled representations without supervision that significantly improve upon, and avoid the pathologies of, previous methods. When trained on images highly corrupted by rotation and translation, the semantic representations learned by TARGET-VAE are similar to those learned on consistently posed objects, dramatically improving clustering in the semantic latent space. Furthermore, TARGET-VAE is able to perform remarkably accurate unsupervised pose and location inference. We expect methods like TARGET-VAE will underpin future approaches for unsupervised object generation, pose prediction, and object detection.
Underwater Ranker: Learn Which Is Better and How to Be Better
Aug 14, 2022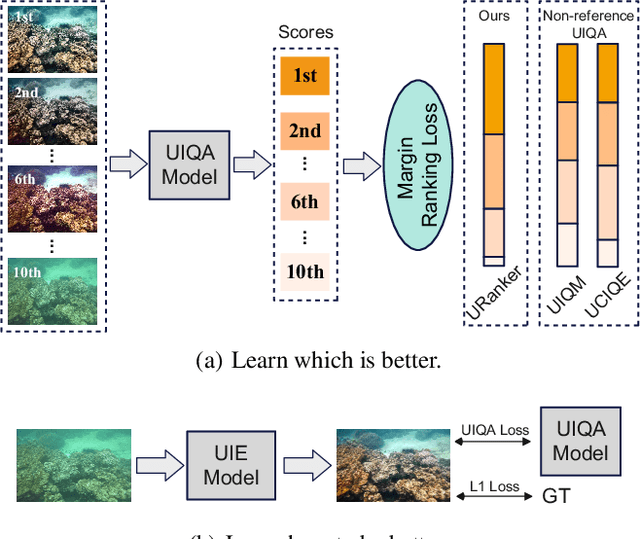
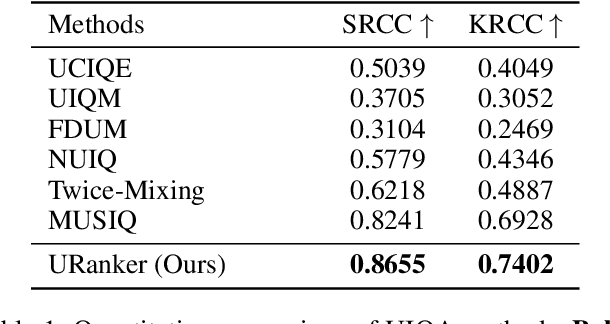

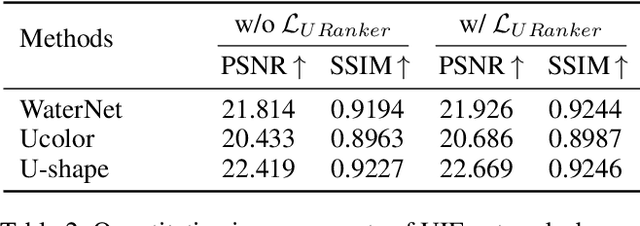
In this paper, we present a ranking-based underwater image quality assessment (UIQA) method, abbreviated as URanker. The URanker is built on the efficient conv-attentional image Transformer. In terms of underwater images, we specially devise (1) the histogram prior that embeds the color distribution of an underwater image as histogram token to attend global degradation and (2) the dynamic cross-scale correspondence to model local degradation. The final prediction depends on the class tokens from different scales, which comprehensively considers multi-scale dependencies. With the margin ranking loss, our URanker can accurately rank the order of underwater images of the same scene enhanced by different underwater image enhancement (UIE) algorithms according to their visual quality. To achieve that, we also contribute a dataset, URankerSet, containing sufficient results enhanced by different UIE algorithms and the corresponding perceptual rankings, to train our URanker. Apart from the good performance of URanker, we found that a simple U-shape UIE network can obtain promising performance when it is coupled with our pre-trained URanker as additional supervision. In addition, we also propose a normalization tail that can significantly improve the performance of UIE networks. Extensive experiments demonstrate the state-of-the-art performance of our method. The key designs of our method are discussed. We will release our dataset and code.
Mutual Learning for Domain Adaptation: Self-distillation Image Dehazing Network with Sample-cycle
Mar 17, 2022
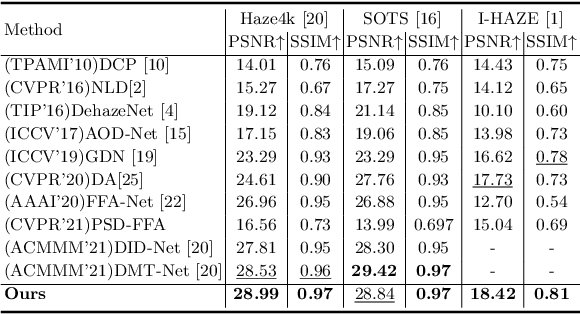
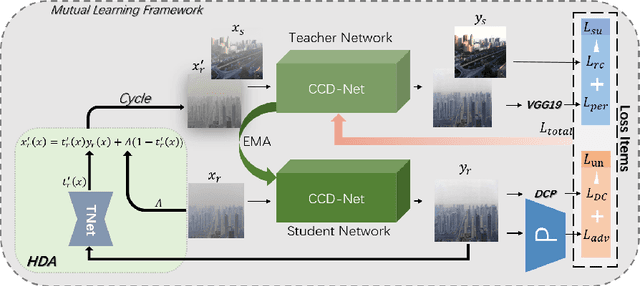

Deep learning-based methods have made significant achievements for image dehazing. However, most of existing dehazing networks are concentrated on training models using simulated hazy images, resulting in generalization performance degradation when applied on real-world hazy images because of domain shift. In this paper, we propose a mutual learning dehazing framework for domain adaption. Specifically, we first devise two siamese networks: a teacher network in the synthetic domain and a student network in the real domain, and then optimize them in a mutual learning manner by leveraging EMA and joint loss. Moreover, we design a sample-cycle strategy based on density augmentation (HDA) module to introduce pseudo real-world image pairs provided by the student network into training for further improving the generalization performance. Extensive experiments on both synthetic and real-world dataset demonstrate that the propose mutual learning framework outperforms state-of-the-art dehazing techniques in terms of subjective and objective evaluation.
Factorisation-based Image Labelling
Nov 19, 2021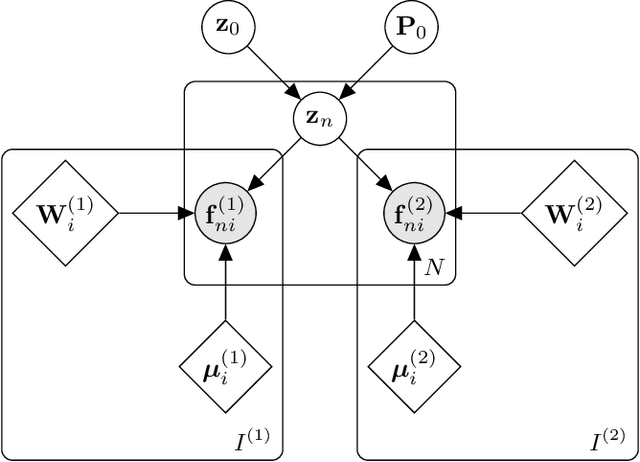
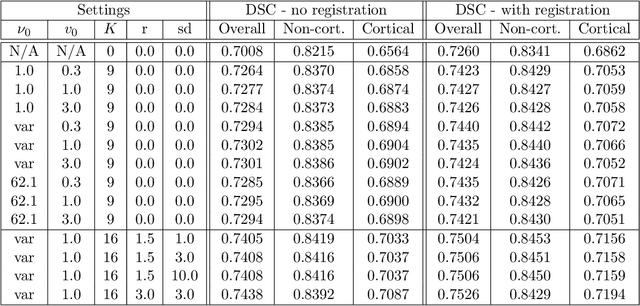
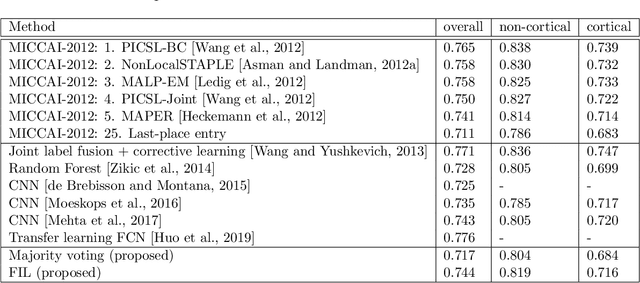
Segmentation of brain magnetic resonance images (MRI) into anatomical regions is a useful task in neuroimaging. Manual annotation is time consuming and expensive, so having a fully automated and general purpose brain segmentation algorithm is highly desirable. To this end, we propose a patched-based label propagation approach based on a generative model with latent variables. Once trained, our Factorisation-based Image Labelling (FIL) model is able to label target images with a variety of image contrasts. We compare the effectiveness of our proposed model against the state-of-the-art using data from the MICCAI 2012 Grand Challenge and Workshop on Multi-Atlas Labeling. As our approach is intended to be general purpose, we also assess how well it can handle domain shift by labelling images of the same subjects acquired with different MR contrasts.
PTGCF: Printing Texture Guided Color Fusion for Impressionism Oil Painting Style Rendering
Jul 27, 2022


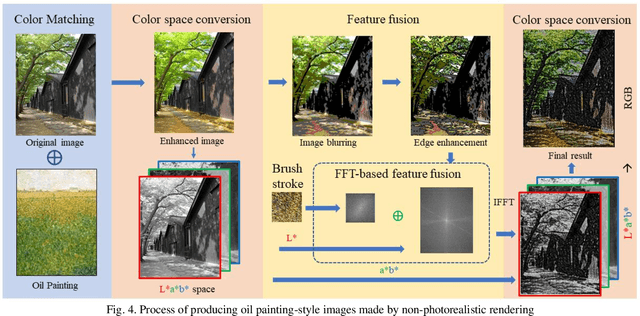
As a major branch of Non-Photorealistic Rendering (NPR), image stylization mainly uses the computer algorithms to render a photo into an artistic painting. Recent work has shown that the extraction of style information such as stroke texture and color of the target style image is the key to image stylization. Given its stroke texture and color characteristics, a new stroke rendering method is proposed, which fully considers the tonal characteristics and the representative color of the original oil painting, in order to fit the tone of the original oil painting image into the stylized image and make it close to the artist's creative effect. The experiments have validated the efficacy of the proposed model. This method would be more suitable for the works of pointillism painters with a relatively uniform sense of direction, especially for natural scenes. When the original painting brush strokes have a clearer sense of direction, using this method to simulate brushwork texture features can be less satisfactory.
SPICE: Self-Supervised Learning for MRI with Automatic Coil Sensitivity Estimation
Oct 05, 2022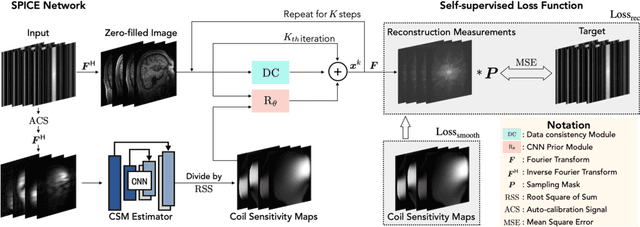
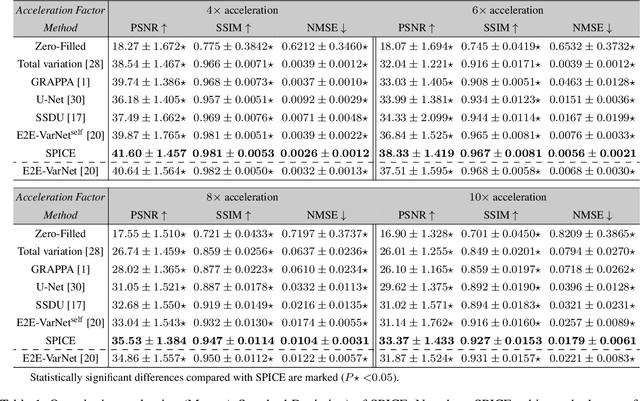
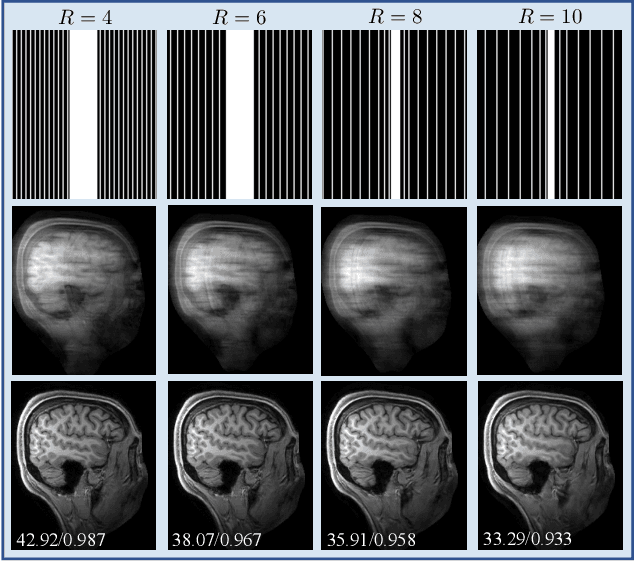
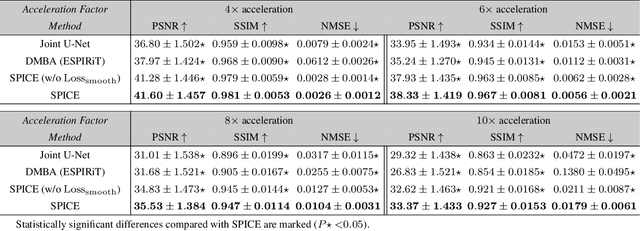
Deep model-based architectures (DMBAs) integrating physical measurement models and learned image regularizers are widely used in parallel magnetic resonance imaging (PMRI). Traditional DMBAs for PMRI rely on pre-estimated coil sensitivity maps (CSMs) as a component of the measurement model. However, estimation of accurate CSMs is a challenging problem when measurements are highly undersampled. Additionally, traditional training of DMBAs requires high-quality groundtruth images, limiting their use in applications where groundtruth is difficult to obtain. This paper addresses these issues by presenting SPICE as a new method that integrates self-supervised learning and automatic coil sensitivity estimation. Instead of using pre-estimated CSMs, SPICE simultaneously reconstructs accurate MR images and estimates high-quality CSMs. SPICE also enables learning from undersampled noisy measurements without any groundtruth. We validate SPICE on experimentally collected data, showing that it can achieve state-of-the-art performance in highly accelerated data acquisition settings (up to 10x).
Random Weight Factorization Improves the Training of Continuous Neural Representations
Oct 05, 2022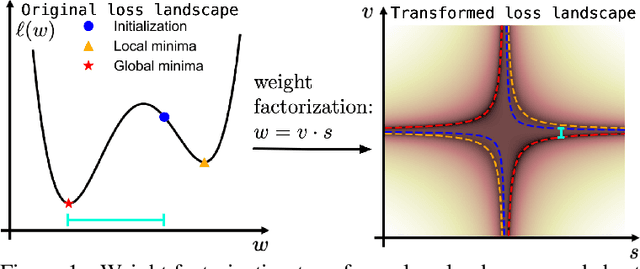
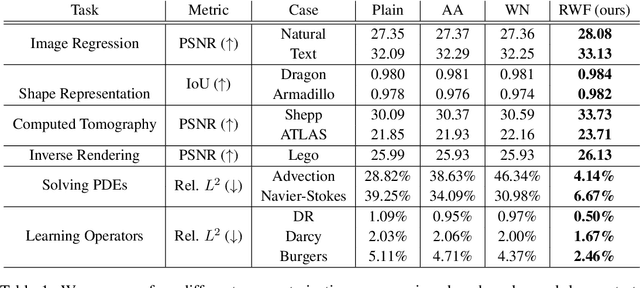
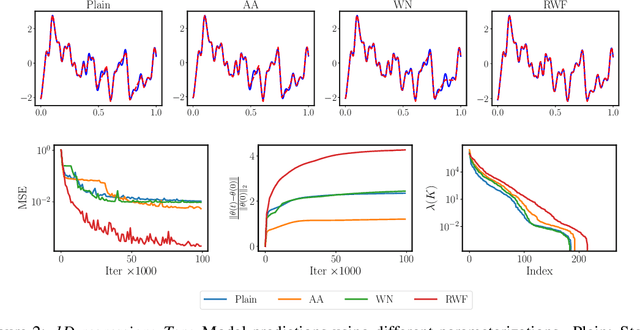
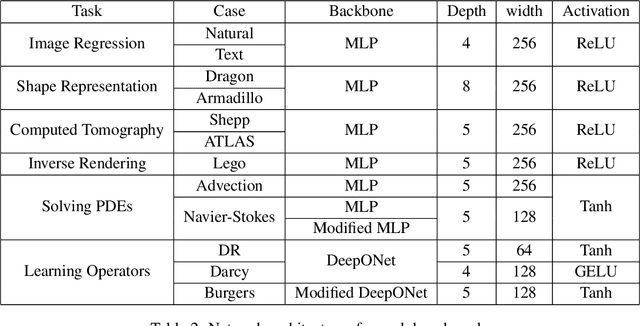
Continuous neural representations have recently emerged as a powerful and flexible alternative to classical discretized representations of signals. However, training them to capture fine details in multi-scale signals is difficult and computationally expensive. Here we propose random weight factorization as a simple drop-in replacement for parameterizing and initializing conventional linear layers in coordinate-based multi-layer perceptrons (MLPs) that significantly accelerates and improves their training. We show how this factorization alters the underlying loss landscape and effectively enables each neuron in the network to learn using its own self-adaptive learning rate. This not only helps with mitigating spectral bias, but also allows networks to quickly recover from poor initializations and reach better local minima. We demonstrate how random weight factorization can be leveraged to improve the training of neural representations on a variety of tasks, including image regression, shape representation, computed tomography, inverse rendering, solving partial differential equations, and learning operators between function spaces.
Visual Language Maps for Robot Navigation
Oct 17, 2022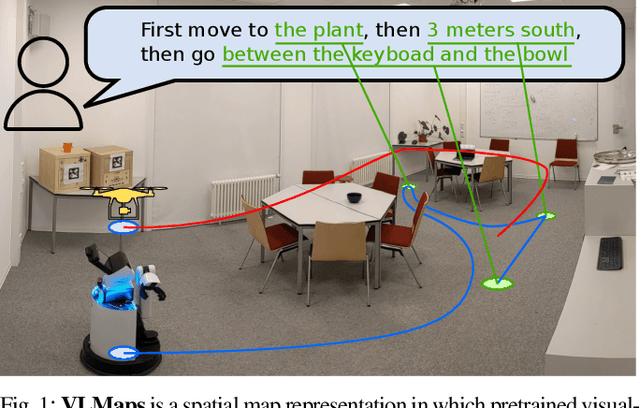

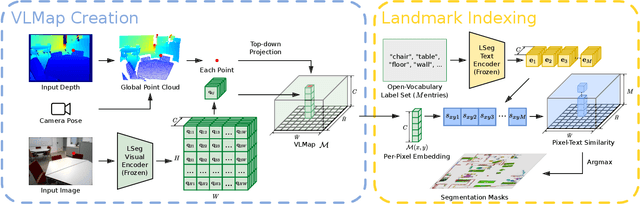

Grounding language to the visual observations of a navigating agent can be performed using off-the-shelf visual-language models pretrained on Internet-scale data (e.g., image captions). While this is useful for matching images to natural language descriptions of object goals, it remains disjoint from the process of mapping the environment, so that it lacks the spatial precision of classic geometric maps. To address this problem, we propose VLMaps, a spatial map representation that directly fuses pretrained visual-language features with a 3D reconstruction of the physical world. VLMaps can be autonomously built from video feed on robots using standard exploration approaches and enables natural language indexing of the map without additional labeled data. Specifically, when combined with large language models (LLMs), VLMaps can be used to (i) translate natural language commands into a sequence of open-vocabulary navigation goals (which, beyond prior work, can be spatial by construction, e.g., "in between the sofa and TV" or "three meters to the right of the chair") directly localized in the map, and (ii) can be shared among multiple robots with different embodiments to generate new obstacle maps on-the-fly (by using a list of obstacle categories). Extensive experiments carried out in simulated and real world environments show that VLMaps enable navigation according to more complex language instructions than existing methods. Videos are available at https://vlmaps.github.io.
Unsupervised Object-Centric Learning with Bi-Level Optimized Query Slot Attention
Oct 17, 2022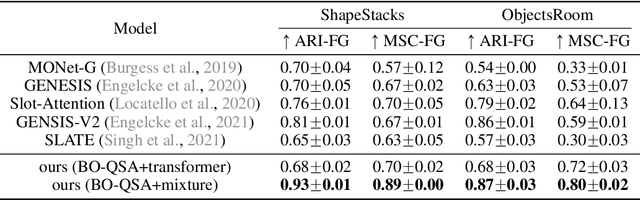

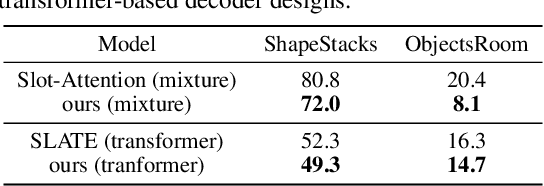
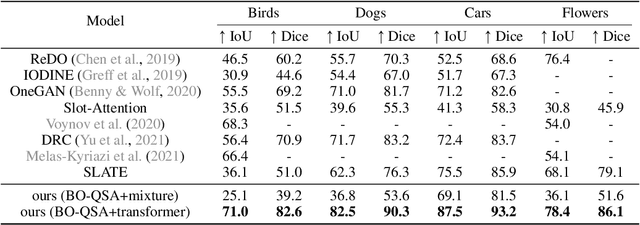
The ability to decompose complex natural scenes into meaningful object-centric abstractions lies at the core of human perception and reasoning. In the recent culmination of unsupervised object-centric learning, the Slot-Attention module has played an important role with its simple yet effective design and fostered many powerful variants. These methods, however, have been exceedingly difficult to train without supervision and are ambiguous in the notion of object, especially for complex natural scenes. In this paper, we propose to address these issues by (1) initializing Slot-Attention modules with learnable queries and (2) optimizing the model with bi-level optimization. With simple code adjustments on the vanilla Slot-Attention, our model, Bi-level Optimized Query Slot Attention, achieves state-of-the-art results on both synthetic and complex real-world datasets in unsupervised image segmentation and reconstruction, outperforming previous baselines by a large margin (~10%). We provide thorough ablative studies to validate the necessity and effectiveness of our design. Additionally, our model exhibits excellent potential for concept binding and zero-shot learning. We hope our effort could provide a single home for the design and learning of slot-based models and pave the way for more challenging tasks in object-centric learning. Our implementation is publicly available at https://github.com/Wall-Facer-liuyu/BO-QSA.
Self-Supervised Learning Through Efference Copies
Oct 17, 2022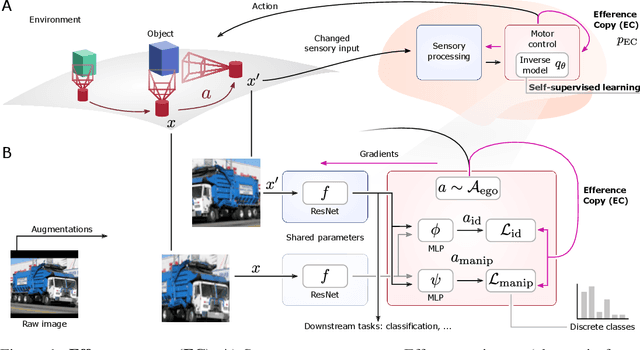
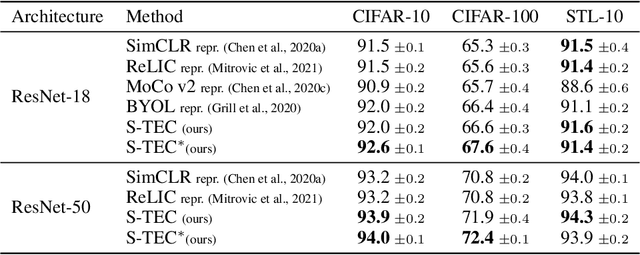
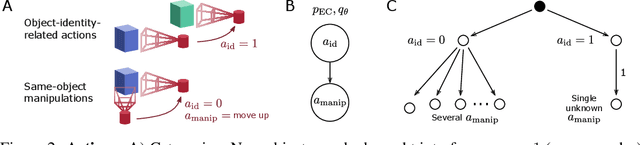
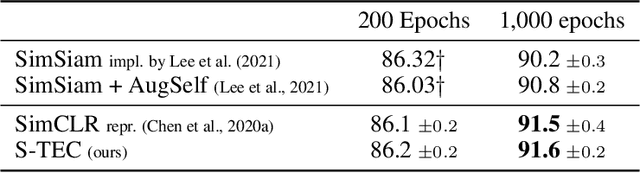
Self-supervised learning (SSL) methods aim to exploit the abundance of unlabelled data for machine learning (ML), however the underlying principles are often method-specific. An SSL framework derived from biological first principles of embodied learning could unify the various SSL methods, help elucidate learning in the brain, and possibly improve ML. SSL commonly transforms each training datapoint into a pair of views, uses the knowledge of this pairing as a positive (i.e. non-contrastive) self-supervisory sign, and potentially opposes it to unrelated, (i.e. contrastive) negative examples. Here, we show that this type of self-supervision is an incomplete implementation of a concept from neuroscience, the Efference Copy (EC). Specifically, the brain also transforms the environment through efference, i.e. motor commands, however it sends to itself an EC of the full commands, i.e. more than a mere SSL sign. In addition, its action representations are likely egocentric. From such a principled foundation we formally recover and extend SSL methods such as SimCLR, BYOL, and ReLIC under a common theoretical framework, i.e. Self-supervision Through Efference Copies (S-TEC). Empirically, S-TEC restructures meaningfully the within- and between-class representations. This manifests as improvement in recent strong SSL baselines in image classification, segmentation, object detection, and in audio. These results hypothesize a testable positive influence from the brain's motor outputs onto its sensory representations.