 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Out of Distribution Reasoning by Weakly-Supervised Disentangled Logic Variational Autoencoder
Oct 18, 2022
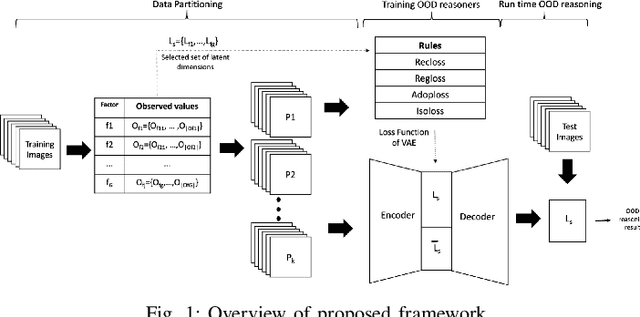
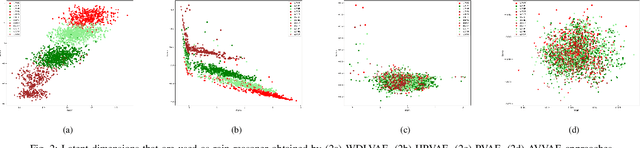
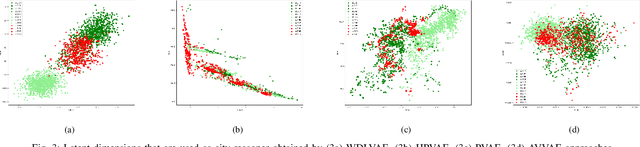
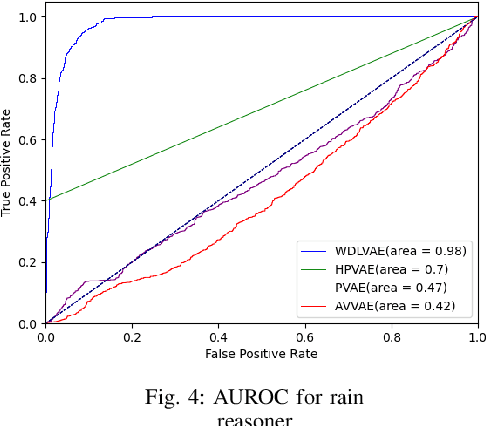
Out-of-distribution (OOD) detection, i.e., finding test samples derived from a different distribution than the training set, as well as reasoning about such samples (OOD reasoning), are necessary to ensure the safety of results generated by machine learning models. Recently there have been promising results for OOD detection in the latent space of variational autoencoders (VAEs). However, without disentanglement, VAEs cannot perform OOD reasoning. Disentanglement ensures a one- to-many mapping between generative factors of OOD (e.g., rain in image data) and the latent variables to which they are encoded. Although previous literature has focused on weakly-supervised disentanglement on simple datasets with known and independent generative factors. In practice, achieving full disentanglement through weak supervision is impossible for complex datasets, such as Carla, with unknown and abstract generative factors. As a result, we propose an OOD reasoning framework that learns a partially disentangled VAE to reason about complex datasets. Our framework consists of three steps: partitioning data based on observed generative factors, training a VAE as a logic tensor network that satisfies disentanglement rules, and run-time OOD reasoning. We evaluate our approach on the Carla dataset and compare the results against three state-of-the-art methods. We found that our framework outperformed these methods in terms of disentanglement and end-to-end OOD reasoning.
Background Invariance Testing According to Semantic Proximity
Aug 19, 2022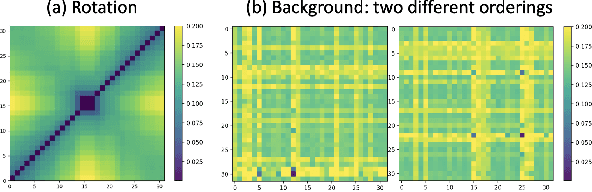
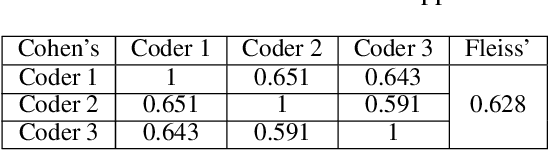
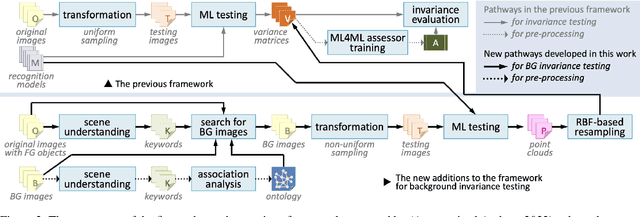

In many applications, machine learned (ML) models are required to hold some invariance qualities, such as rotation, size, intensity, and background invariance. Unlike many types of variance, the variants of background scenes cannot be ordered easily, which makes it difficult to analyze the robustness and biases of the models concerned. In this work, we present a technical solution for ordering background scenes according to their semantic proximity to a target image that contains a foreground object being tested. We make use of the results of object recognition as the semantic description of each image, and construct an ontology for storing knowledge about relationships among different objects using association analysis. This ontology enables (i) efficient and meaningful search for background scenes of different semantic distances to a target image, (ii) quantitative control of the distribution and sparsity of the sampled background scenes, and (iii) quality assurance using visual representations of invariance testing results (referred to as variance matrices). In this paper, we also report the training of an ML4ML assessor to evaluate the invariance quality of ML models automatically.
How does fake news use a thumbnail? CLIP-based Multimodal Detection on the Unrepresentative News Image
Apr 12, 2022
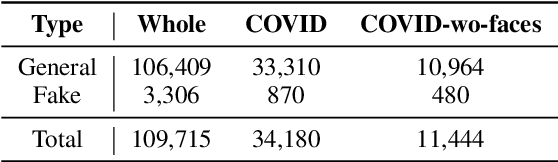
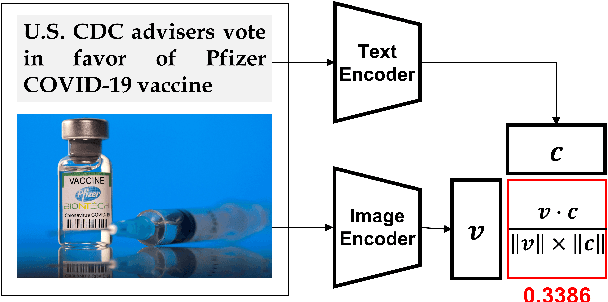
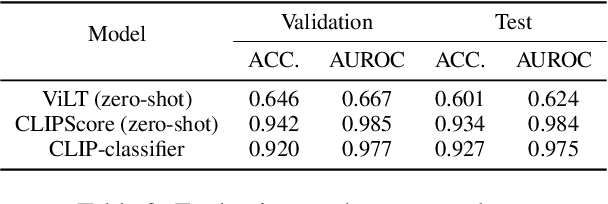
This study investigates how fake news uses a thumbnail for a news article with a focus on whether a news article's thumbnail represents the news content correctly. A news article shared with an irrelevant thumbnail can mislead readers into having a wrong impression of the issue, especially in social media environments where users are less likely to click the link and consume the entire content. We propose to capture the degree of semantic incongruity in the multimodal relation by using the pretrained CLIP representation. From a source-level analysis, we found that fake news employs a more incongruous image to the main content than general news. Going further, we attempted to detect news articles with image-text incongruity. Evaluation experiments suggest that CLIP-based methods can successfully detect news articles in which the thumbnail is semantically irrelevant to news text. This study contributes to the research by providing a novel view on tackling online fake news and misinformation. Code and datasets are available at https://github.com/ssu-humane/fake-news-thumbnail.
Toward Fast, Flexible, and Robust Low-Light Image Enhancement
Apr 21, 2022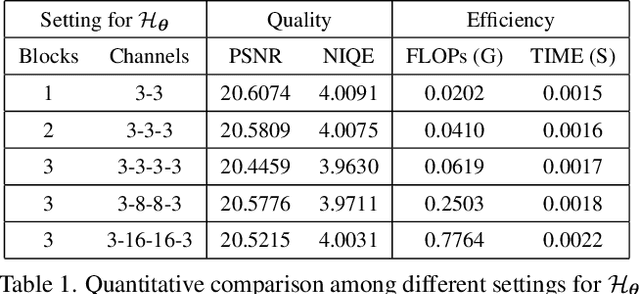
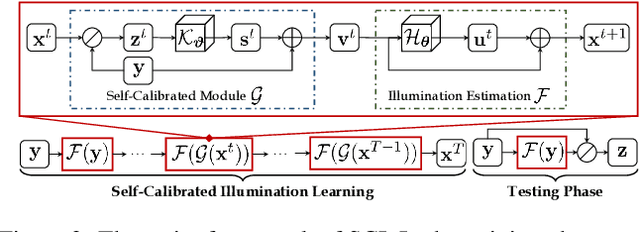
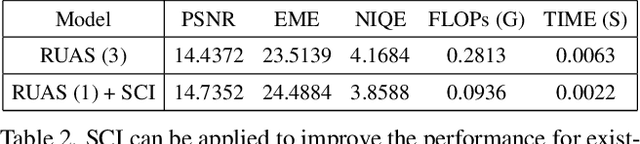

Existing low-light image enhancement techniques are mostly not only difficult to deal with both visual quality and computational efficiency but also commonly invalid in unknown complex scenarios. In this paper, we develop a new Self-Calibrated Illumination (SCI) learning framework for fast, flexible, and robust brightening images in real-world low-light scenarios. To be specific, we establish a cascaded illumination learning process with weight sharing to handle this task. Considering the computational burden of the cascaded pattern, we construct the self-calibrated module which realizes the convergence between results of each stage, producing the gains that only use the single basic block for inference (yet has not been exploited in previous works), which drastically diminishes computation cost. We then define the unsupervised training loss to elevate the model capability that can adapt to general scenes. Further, we make comprehensive explorations to excavate SCI's inherent properties (lacking in existing works) including operation-insensitive adaptability (acquiring stable performance under the settings of different simple operations) and model-irrelevant generality (can be applied to illumination-based existing works to improve performance). Finally, plenty of experiments and ablation studies fully indicate our superiority in both quality and efficiency. Applications on low-light face detection and nighttime semantic segmentation fully reveal the latent practical values for SCI. The source code is available at https://github.com/vis-opt-group/SCI.
Learning Token-based Representation for Image Retrieval
Dec 12, 2021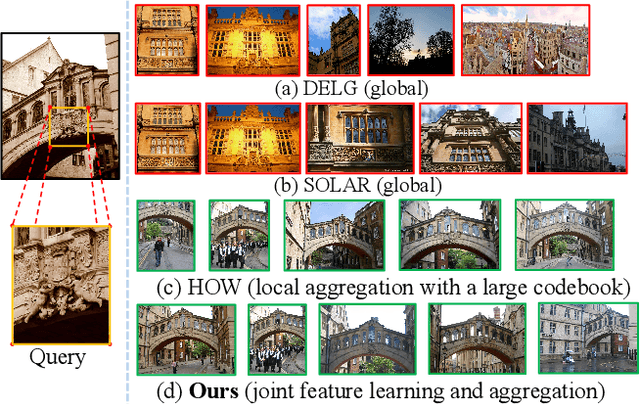
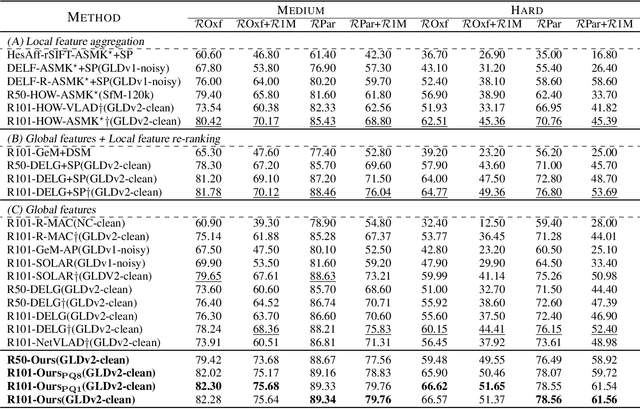
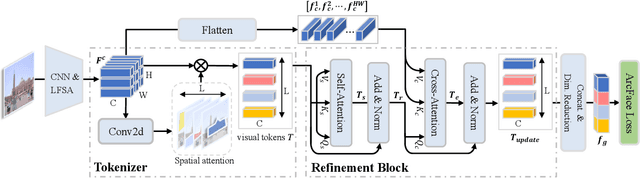
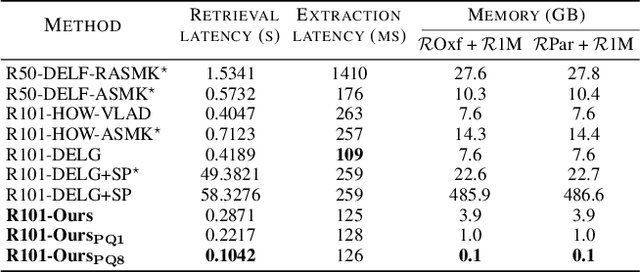
In image retrieval, deep local features learned in a data-driven manner have been demonstrated effective to improve retrieval performance. To realize efficient retrieval on large image database, some approaches quantize deep local features with a large codebook and match images with aggregated match kernel. However, the complexity of these approaches is non-trivial with large memory footprint, which limits their capability to jointly perform feature learning and aggregation. To generate compact global representations while maintaining regional matching capability, we propose a unified framework to jointly learn local feature representation and aggregation. In our framework, we first extract deep local features using CNNs. Then, we design a tokenizer module to aggregate them into a few visual tokens, each corresponding to a specific visual pattern. This helps to remove background noise, and capture more discriminative regions in the image. Next, a refinement block is introduced to enhance the visual tokens with self-attention and cross-attention. Finally, different visual tokens are concatenated to generate a compact global representation. The whole framework is trained end-to-end with image-level labels. Extensive experiments are conducted to evaluate our approach, which outperforms the state-of-the-art methods on the Revisited Oxford and Paris datasets.
MACAB: Model-Agnostic Clean-Annotation Backdoor to Object Detection with Natural Trigger in Real-World
Sep 06, 2022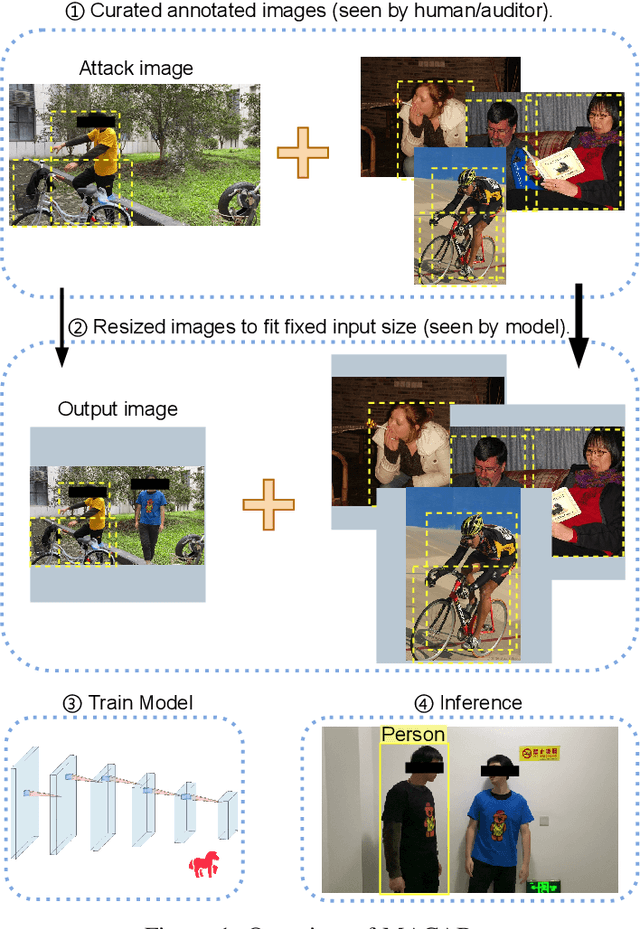
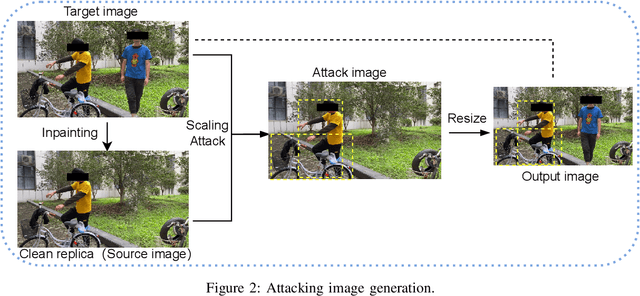


Object detection is the foundation of various critical computer-vision tasks such as segmentation, object tracking, and event detection. To train an object detector with satisfactory accuracy, a large amount of data is required. However, due to the intensive workforce involved with annotating large datasets, such a data curation task is often outsourced to a third party or relied on volunteers. This work reveals severe vulnerabilities of such data curation pipeline. We propose MACAB that crafts clean-annotated images to stealthily implant the backdoor into the object detectors trained on them even when the data curator can manually audit the images. We observe that the backdoor effect of both misclassification and the cloaking are robustly achieved in the wild when the backdoor is activated with inconspicuously natural physical triggers. Backdooring non-classification object detection with clean-annotation is challenging compared to backdooring existing image classification tasks with clean-label, owing to the complexity of having multiple objects within each frame, including victim and non-victim objects. The efficacy of the MACAB is ensured by constructively i abusing the image-scaling function used by the deep learning framework, ii incorporating the proposed adversarial clean image replica technique, and iii combining poison data selection criteria given constrained attacking budget. Extensive experiments demonstrate that MACAB exhibits more than 90% attack success rate under various real-world scenes. This includes both cloaking and misclassification backdoor effect even restricted with a small attack budget. The poisoned samples cannot be effectively identified by state-of-the-art detection techniques.The comprehensive video demo is at https://youtu.be/MA7L_LpXkp4, which is based on a poison rate of 0.14% for YOLOv4 cloaking backdoor and Faster R-CNN misclassification backdoor.
Deep Reinforcement Learning for Task Offloading in UAV-Aided Smart Farm Networks
Sep 15, 2022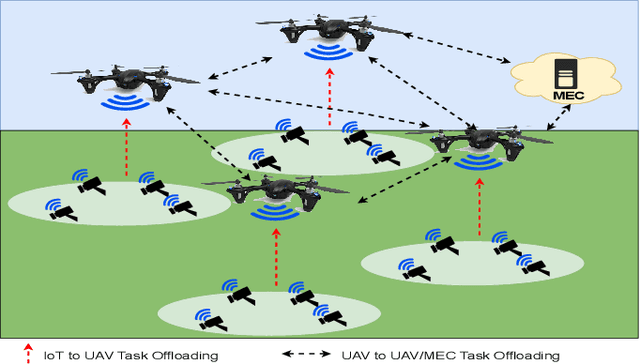
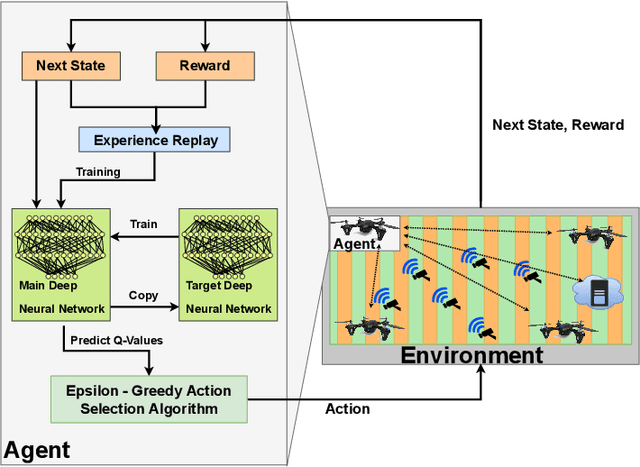
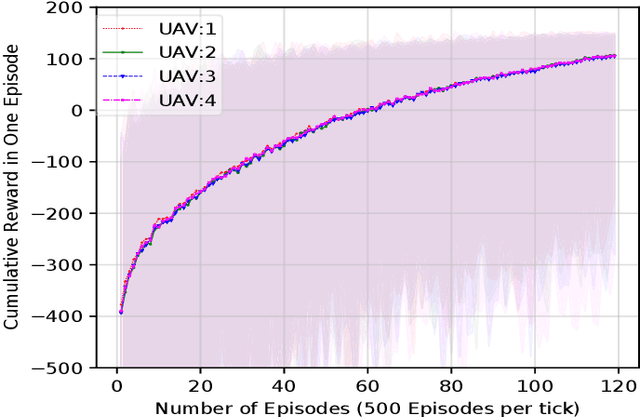
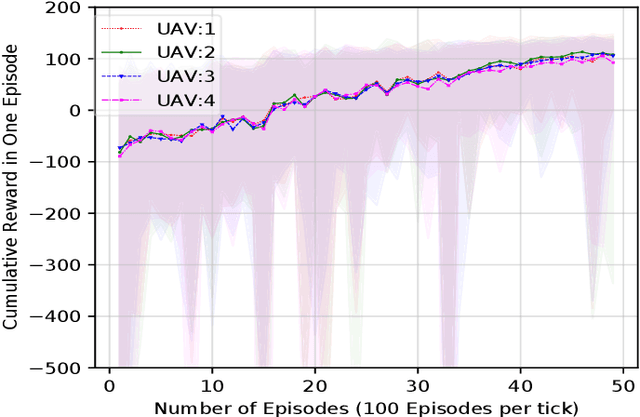
The fifth and sixth generations of wireless communication networks are enabling tools such as internet of things devices, unmanned aerial vehicles (UAVs), and artificial intelligence, to improve the agricultural landscape using a network of devices to automatically monitor farmlands. Surveying a large area requires performing a lot of image classification tasks within a specific period of time in order to prevent damage to the farm in case of an incident, such as fire or flood. UAVs have limited energy and computing power, and may not be able to perform all of the intense image classification tasks locally and within an appropriate amount of time. Hence, it is assumed that the UAVs are able to partially offload their workload to nearby multi-access edge computing devices. The UAVs need a decision-making algorithm that will decide where the tasks will be performed, while also considering the time constraints and energy level of the other UAVs in the network. In this paper, we introduce a Deep Q-Learning (DQL) approach to solve this multi-objective problem. The proposed method is compared with Q-Learning and three heuristic baselines, and the simulation results show that our proposed DQL-based method achieves comparable results when it comes to the UAVs' remaining battery levels and percentage of deadline violations. In addition, our method is able to reach convergence 13 times faster than Q-Learning.
Model-Based Image Signal Processors via Learnable Dictionaries
Jan 10, 2022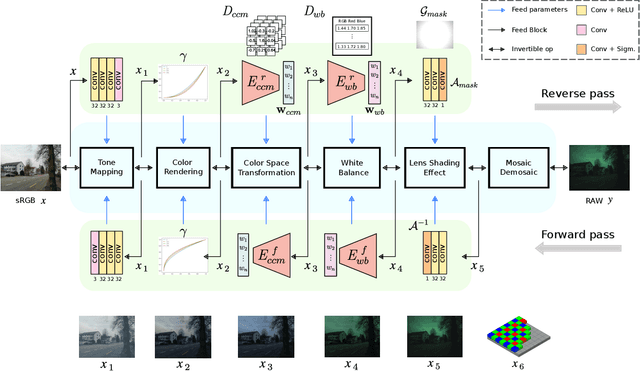
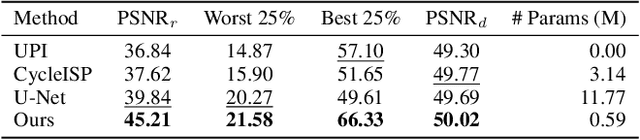
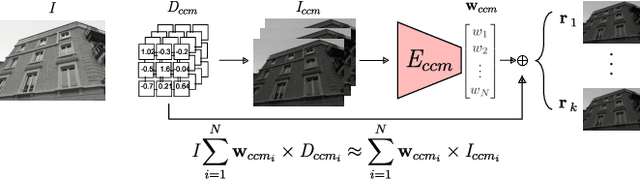
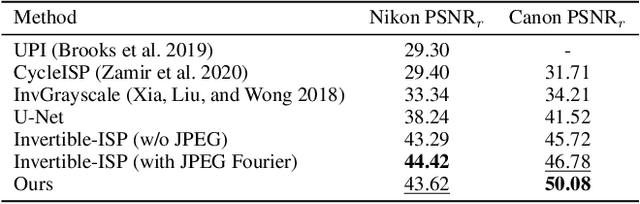
Digital cameras transform sensor RAW readings into RGB images by means of their Image Signal Processor (ISP). Computational photography tasks such as image denoising and colour constancy are commonly performed in the RAW domain, in part due to the inherent hardware design, but also due to the appealing simplicity of noise statistics that result from the direct sensor readings. Despite this, the availability of RAW images is limited in comparison with the abundance and diversity of available RGB data. Recent approaches have attempted to bridge this gap by estimating the RGB to RAW mapping: handcrafted model-based methods that are interpretable and controllable usually require manual parameter fine-tuning, while end-to-end learnable neural networks require large amounts of training data, at times with complex training procedures, and generally lack interpretability and parametric control. Towards addressing these existing limitations, we present a novel hybrid model-based and data-driven ISP that builds on canonical ISP operations and is both learnable and interpretable. Our proposed invertible model, capable of bidirectional mapping between RAW and RGB domains, employs end-to-end learning of rich parameter representations, i.e. dictionaries, that are free from direct parametric supervision and additionally enable simple and plausible data augmentation. We evidence the value of our data generation process by extensive experiments under both RAW image reconstruction and RAW image denoising tasks, obtaining state-of-the-art performance in both. Additionally, we show that our ISP can learn meaningful mappings from few data samples, and that denoising models trained with our dictionary-based data augmentation are competitive despite having only few or zero ground-truth labels.
Cooperative Self-Training for Multi-Target Adaptive Semantic Segmentation
Oct 04, 2022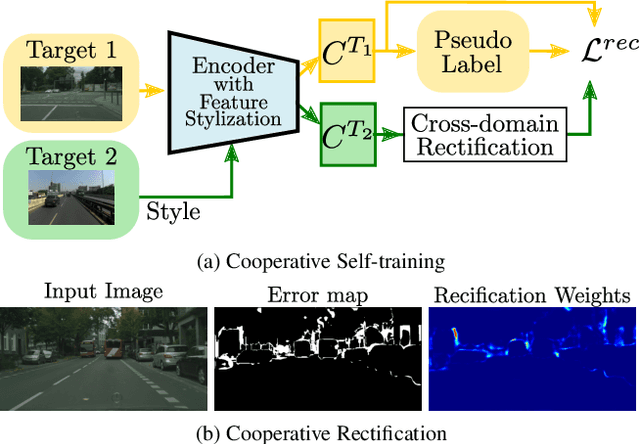
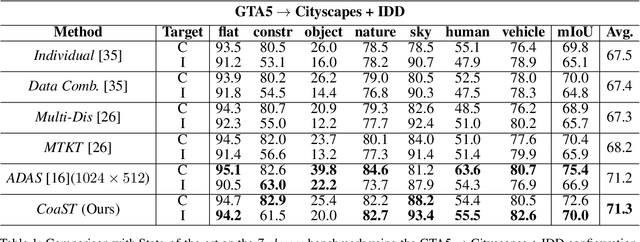
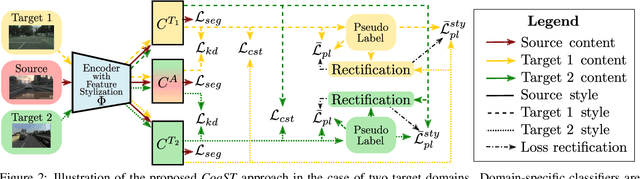
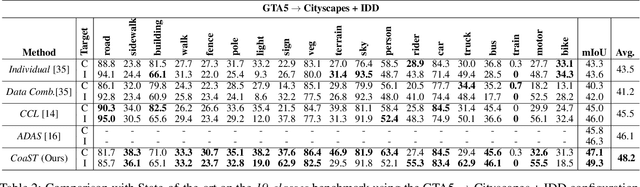
In this work we address multi-target domain adaptation (MTDA) in semantic segmentation, which consists in adapting a single model from an annotated source dataset to multiple unannotated target datasets that differ in their underlying data distributions. To address MTDA, we propose a self-training strategy that employs pseudo-labels to induce cooperation among multiple domain-specific classifiers. We employ feature stylization as an efficient way to generate image views that forms an integral part of self-training. Additionally, to prevent the network from overfitting to noisy pseudo-labels, we devise a rectification strategy that leverages the predictions from different classifiers to estimate the quality of pseudo-labels. Our extensive experiments on numerous settings, based on four different semantic segmentation datasets, validate the effectiveness of the proposed self-training strategy and show that our method outperforms state-of-the-art MTDA approaches. Code available at: https://github.com/Mael-zys/CoaST
Exploring the combination of deep-learning based direct segmentation and deformable image registration for cone-beam CT based auto-segmentation for adaptive radiotherapy
Jun 07, 2022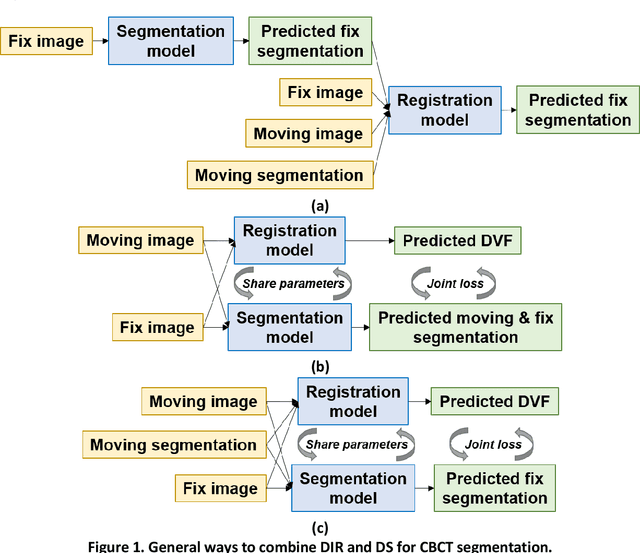
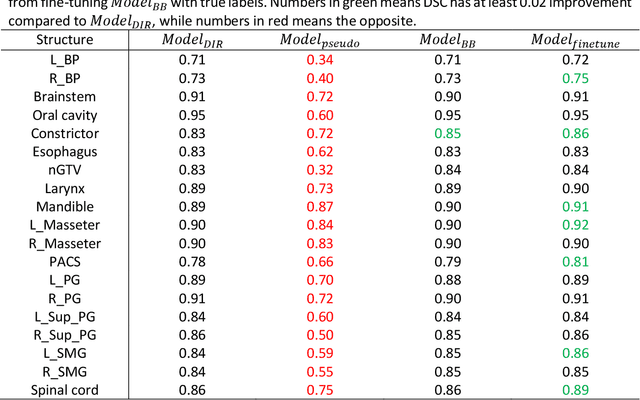
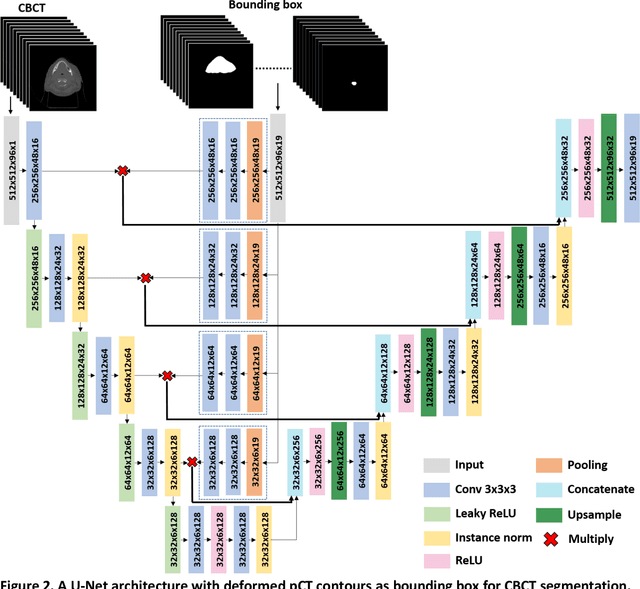
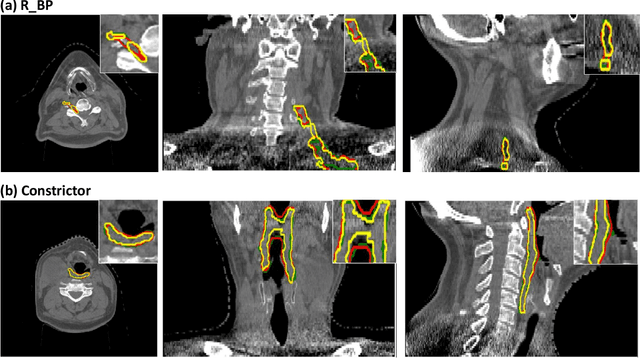
CBCT-based online adaptive radiotherapy (ART) calls for accurate auto-segmentation models to reduce the time cost for physicians to edit contours, since the patient is immobilized on the treatment table waiting for treatment to start. However, auto-segmentation of CBCT images is a difficult task, majorly due to low image quality and lack of true labels for training a deep learning (DL) model. Meanwhile CBCT auto-segmentation in ART is a unique task compared to other segmentation problems, where manual contours on planning CT (pCT) are available. To make use of this prior knowledge, we propose to combine deformable image registration (DIR) and direct segmentation (DS) on CBCT for head and neck patients. First, we use deformed pCT contours derived from multiple DIR methods between pCT and CBCT as pseudo labels for training. Second, we use deformed pCT contours as bounding box to constrain the region of interest for DS. Meanwhile deformed pCT contours are used as pseudo labels for training, but are generated from different DIR algorithms from bounding box. Third, we fine-tune the model with bounding box on true labels. We found that DS on CBCT trained with pseudo labels and without utilizing any prior knowledge has very poor segmentation performance compared to DIR-only segmentation. However, adding deformed pCT contours as bounding box in the DS network can dramatically improve segmentation performance, comparable to DIR-only segmentation. The DS model with bounding box can be further improved by fine-tuning it with some real labels. Experiments showed that 7 out of 19 structures have at least 0.2 dice similarity coefficient increase compared to DIR-only segmentation. Utilizing deformed pCT contours as pseudo labels for training and as bounding box for shape and location feature extraction in a DS model is a good way to combine DIR and DS.