 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARHN: Answer-Centric Relabeling of Hard Negatives with Open-Source LLMs for Dense Retrieval
Apr 13, 2026Neural retrievers are often trained on large-scale triplet data comprising a query, a positive passage, and a set of hard negatives. In practice, hard-negative mining can introduce false negatives and other ambiguous negatives, including passages that are relevant or contain partial answers to the query. Such label noise yields inconsistent supervision and can degrade retrieval effectiveness. We propose ARHN (Answer-centric Relabeling of Hard Negatives), a two-stage framework that leverages open-source LLMs to refine hard negative samples using answer-centric relevance signals. In the first stage, for each query-passage pair, ARHN prompts the LLM to generate a passage-grounded answer snippet or to indicate that the passage does not support an answer. In the second stage, ARHN applies an LLM-based listwise ranking over the candidate set to order passages by direct answerability to the query. Passages ranked above the original positive are relabeled to additional positives. Among passages ranked below the positive, ARHN excludes any that contain an answer snippet from the negative set to avoid ambiguous supervision. We evaluated ARHN on the BEIR benchmark under three configurations: relabeling only, filtering only, and their combination. Across datasets, the combined strategy consistently improves over either step in isolation, indicating that jointly relabeling false negatives and filtering ambiguous negatives yields cleaner supervision for training neural retrieval models. By relying strictly on open-source models, ARHN establishes a cost-effective and scalable refinement pipeline suitable for large-scale training.
LG-ANNA-Embedding technical report
Jun 09, 2025This report presents a unified instruction-based framework for learning generalized text embeddings optimized for both information retrieval (IR) and non-IR tasks. Built upon a decoder-only large language model (Mistral-7B), our approach combines in-context learning, soft supervision, and adaptive hard-negative mining to generate context-aware embeddings without task-specific fine-tuning. Structured instructions and few-shot examples are used to guide the model across diverse tasks, enabling strong performance on classification, semantic similarity, clustering, and reranking benchmarks. To improve semantic discrimination, we employ a soft labeling framework where continuous relevance scores, distilled from a high-performance dense retriever and reranker, serve as fine-grained supervision signals. In addition, we introduce adaptive margin-based hard-negative mining, which filters out semantically ambiguous negatives based on their similarity to positive examples, thereby enhancing training stability and retrieval robustness. Our model is evaluated on the newly introduced MTEB (English, v2) benchmark, covering 41 tasks across seven categories. Results show that our method achieves strong generalization and ranks among the top-performing models by Borda score, outperforming several larger or fully fine-tuned baselines. These findings highlight the effectiveness of combining in-context prompting, soft supervision, and adaptive sampling for scalable, high-quality embedding generation.
How does fake news use a thumbnail? CLIP-based Multimodal Detection on the Unrepresentative News Image
Apr 27, 2022
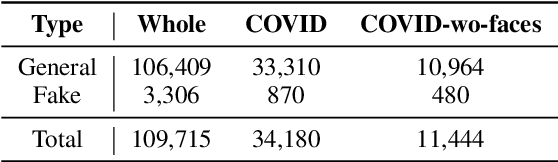
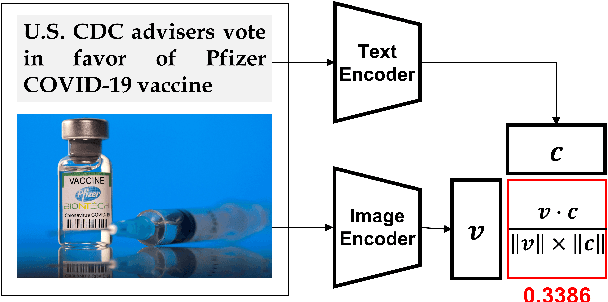
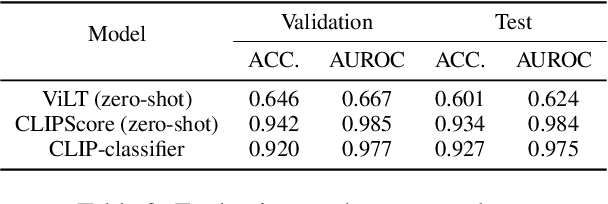
This study investigates how fake news uses a thumbnail for a news article with a focus on whether a news article's thumbnail represents the news content correctly. A news article shared with an irrelevant thumbnail can mislead readers into having a wrong impression of the issue, especially in social media environments where users are less likely to click the link and consume the entire content. We propose to capture the degree of semantic incongruity in the multimodal relation by using the pretrained CLIP representation. From a source-level analysis, we found that fake news employs a more incongruous image to the main content than general news. Going further, we attempted to detect news articles with image-text incongruity. Evaluation experiments suggest that CLIP-based methods can successfully detect news articles in which the thumbnail is semantically irrelevant to news text. This study contributes to the research by providing a novel view on tackling online fake news and misinformation. Code and datasets are available at https://github.com/ssu-humane/fake-news-thumbnail.