 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage Similarity using An Ensemble of Context-Sensitive Models
Jan 15, 2024Image similarity has been extensively studied in computer vision. In recently years, machine-learned models have shown their ability to encode more semantics than traditional multivariate metrics. However, in labelling similarity, assigning a numerical score to a pair of images is less intuitive than determining if an image A is closer to a reference image R than another image B. In this work, we present a novel approach for building an image similarity model based on labelled data in the form of A:R vs B:R. We address the challenges of sparse sampling in the image space (R, A, B) and biases in the models trained with context-based data by using an ensemble model. In particular, we employed two ML techniques to construct such an ensemble model, namely dimensionality reduction and MLP regressors. Our testing results show that the ensemble model constructed performs ~5% better than the best individual context-sensitive models. They also performed better than the model trained with mixed imagery data as well as existing similarity models, e.g., CLIP and DINO. This work demonstrate that context-based labelling and model training can be effective when an appropriate ensemble approach is used to alleviate the limitation due to sparse sampling.
Background Invariance Testing According to Semantic Proximity
Aug 19, 2022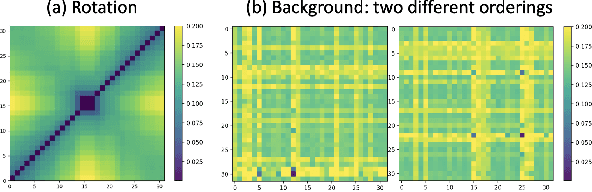
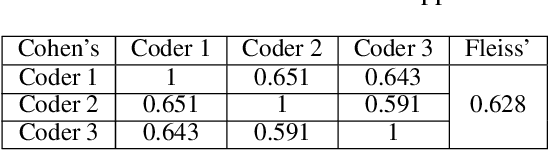
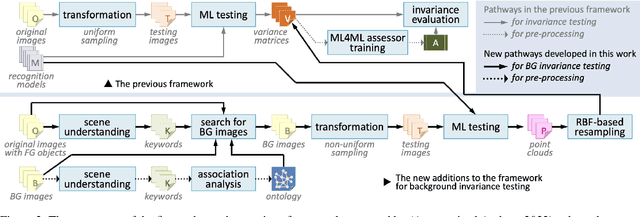

In many applications, machine learned (ML) models are required to hold some invariance qualities, such as rotation, size, intensity, and background invariance. Unlike many types of variance, the variants of background scenes cannot be ordered easily, which makes it difficult to analyze the robustness and biases of the models concerned. In this work, we present a technical solution for ordering background scenes according to their semantic proximity to a target image that contains a foreground object being tested. We make use of the results of object recognition as the semantic description of each image, and construct an ontology for storing knowledge about relationships among different objects using association analysis. This ontology enables (i) efficient and meaningful search for background scenes of different semantic distances to a target image, (ii) quantitative control of the distribution and sparsity of the sampled background scenes, and (iii) quality assurance using visual representations of invariance testing results (referred to as variance matrices). In this paper, we also report the training of an ML4ML assessor to evaluate the invariance quality of ML models automatically.
ML4ML: Automated Invariance Testing for Machine Learning Models
Sep 27, 2021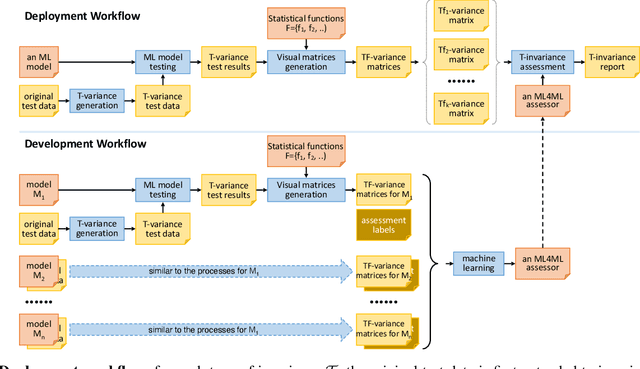

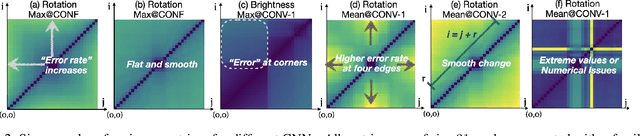

In machine learning workflows, determining invariance qualities of a model is a common testing procedure. In this paper, we propose an automatic testing framework that is applicable to a variety of invariance qualities. We draw an analogy between invariance testing and medical image analysis and propose to use variance matrices as ``imagery'' testing data. This enables us to employ machine learning techniques for analysing such ``imagery'' testing data automatically, hence facilitating ML4ML (machine learning for machine learning). We demonstrate the effectiveness and feasibility of the proposed framework by developing ML4ML models (assessors) for determining rotation-, brightness-, and size-variances of a collection of neural networks. Our testing results show that the trained ML4ML assessors can perform such analytical tasks with sufficient accuracy.
Simultaneous Adversarial Training - Learn from Others Mistakes
Sep 10, 2018
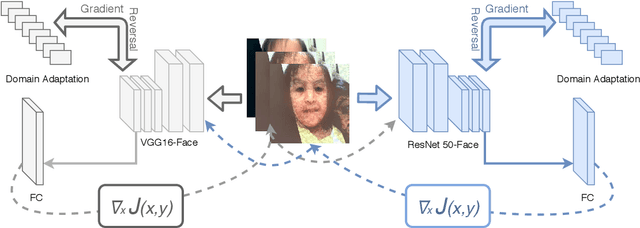
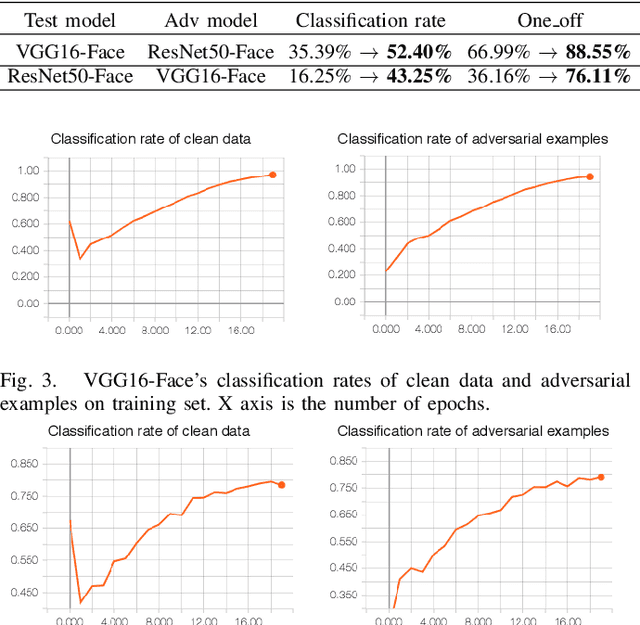

Adversarial examples are maliciously tweaked images that can easily fool machine learning techniques, such as neural networks, but they are normally not visually distinguishable for human beings. One of the main approaches to solve this problem is to retrain the networks using those adversarial examples, namely adversarial training. However, standard adversarial training might not actually change the decision boundaries but cause the problem of gradient masking, resulting in a weaker ability to generate adversarial examples. Therefore, it cannot alleviate the problem of black-box attacks, where adversarial examples generated from other networks can transfer to the targeted one. In order to reduce the problem of black-box attacks, we propose a novel method that allows two networks to learn from each others' adversarial examples and become resilient to black-box attacks. We also combine this method with a simple domain adaptation to further improve the performance.
Transfer Learning for Action Unit Recognition
Jul 19, 2018
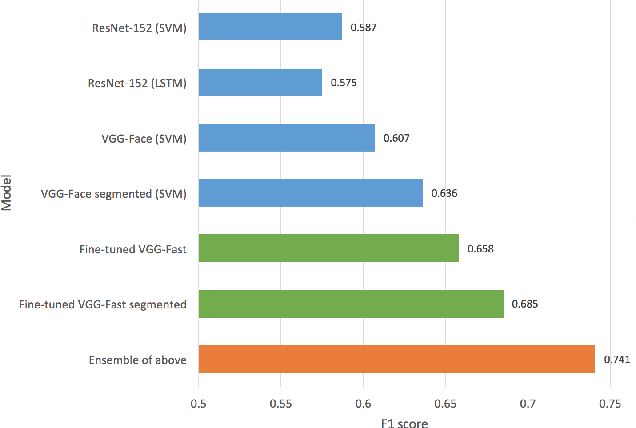
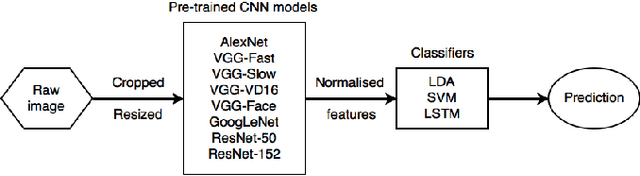
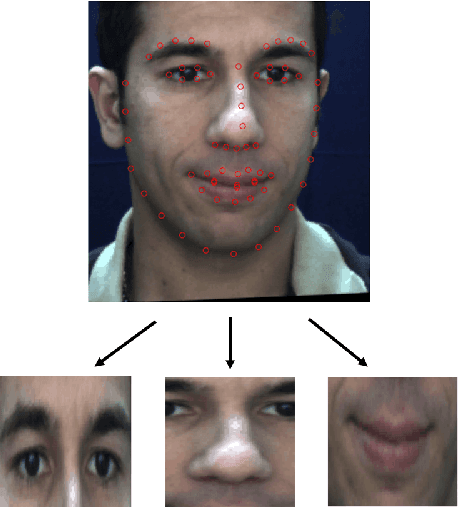
This paper presents a classifier ensemble for Facial Expression Recognition (FER) based on models derived from transfer learning. The main experimentation work is conducted for facial action unit detection using feature extraction and fine-tuning convolutional neural networks (CNNs). Several classifiers for extracted CNN codes such as Linear Discriminant Analysis (LDA), Support Vector Machines (SVMs) and Long Short-Term Memory (LSTM) are compared and evaluated. Multi-model ensembles are also used to further improve the performance. We have found that VGG-Face and ResNet are the relatively optimal pre-trained models for action unit recognition using feature extraction and the ensemble of VGG-Net variants and ResNet achieves the best result.
Local Deep Neural Networks for Age and Gender Classification
Mar 24, 2017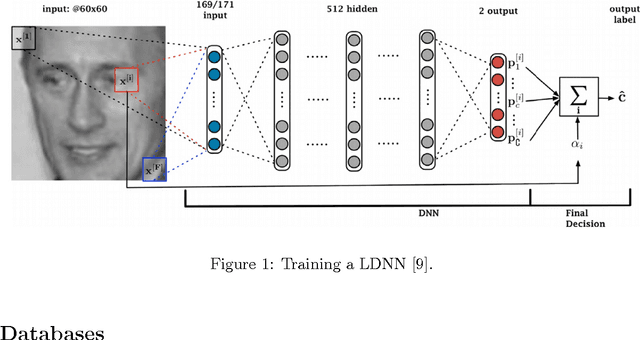


Local deep neural networks have been recently introduced for gender recognition. Although, they achieve very good performance they are very computationally expensive to train. In this work, we introduce a simplified version of local deep neural networks which significantly reduces the training time. Instead of using hundreds of patches per image, as suggested by the original method, we propose to use 9 overlapping patches per image which cover the entire face region. This results in a much reduced training time, since just 9 patches are extracted per image instead of hundreds, at the expense of a slightly reduced performance. We tested the proposed modified local deep neural networks approach on the LFW and Adience databases for the task of gender and age classification. For both tasks and both databases the performance is up to 1% lower compared to the original version of the algorithm. We have also investigated which patches are more discriminative for age and gender classification. It turns out that the mouth and eyes regions are useful for age classification, whereas just the eye region is useful for gender classification.