 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Text-to-Audio Grounding Based Novel Metric for Evaluating Audio Caption Similarity
Oct 03, 2022

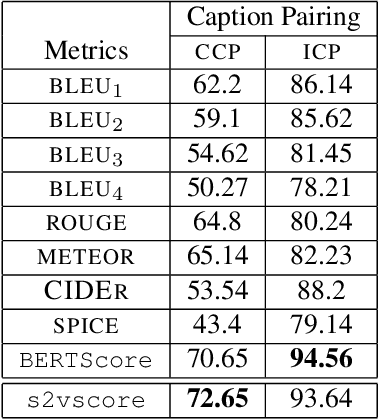
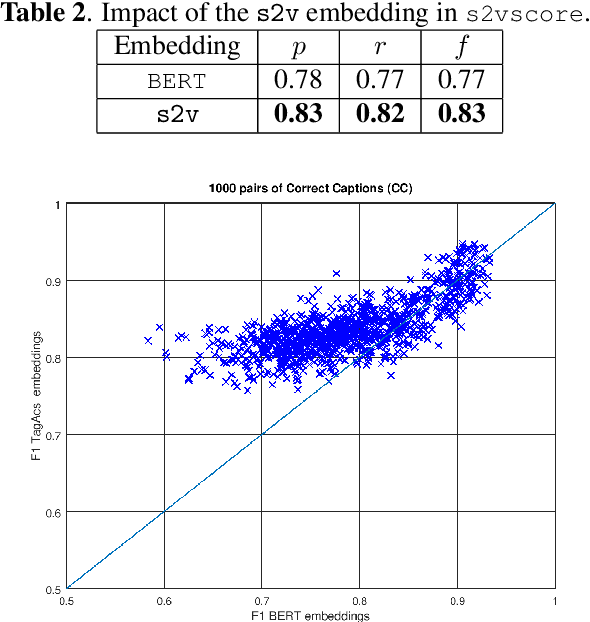
Automatic Audio Captioning (AAC) refers to the task of translating an audio sample into a natural language (NL) text that describes the audio events, source of the events and their relationships. Unlike NL text generation tasks, which rely on metrics like BLEU, ROUGE, METEOR based on lexical semantics for evaluation, the AAC evaluation metric requires an ability to map NL text (phrases) that correspond to similar sounds in addition lexical semantics. Current metrics used for evaluation of AAC tasks lack an understanding of the perceived properties of sound represented by text. In this paper, wepropose a novel metric based on Text-to-Audio Grounding (TAG), which is, useful for evaluating cross modal tasks like AAC. Experiments on publicly available AAC data-set shows our evaluation metric to perform better compared to existing metrics used in NL text and image captioning literature.
Feature Embedding by Template Matching as a ResNet Block
Oct 03, 2022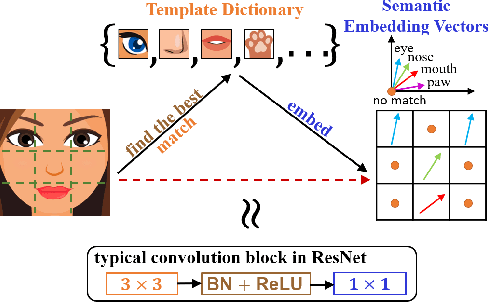
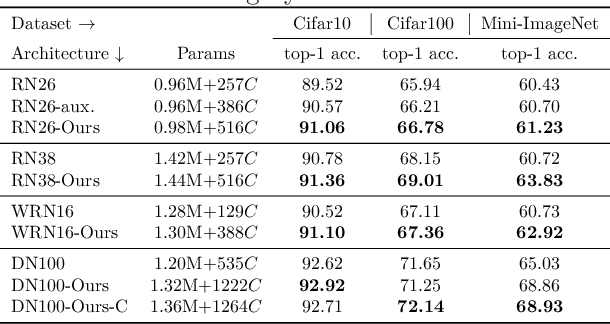
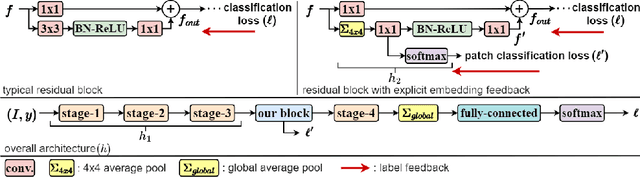
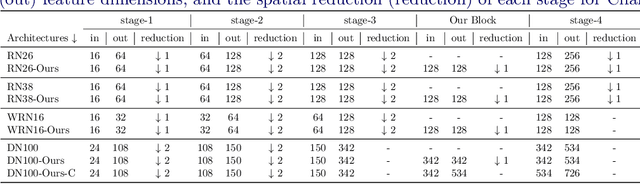
Convolution blocks serve as local feature extractors and are the key to success of the neural networks. To make local semantic feature embedding rather explicit, we reformulate convolution blocks as feature selection according to the best matching kernel. In this manner, we show that typical ResNet blocks indeed perform local feature embedding via template matching once batch normalization (BN) followed by a rectified linear unit (ReLU) is interpreted as arg-max optimizer. Following this perspective, we tailor a residual block that explicitly forces semantically meaningful local feature embedding through using label information. Specifically, we assign a feature vector to each local region according to the classes that the corresponding region matches. We evaluate our method on three popular benchmark datasets with several architectures for image classification and consistently show that our approach substantially improves the performance of the baseline architectures.
Pix2NeRF: Unsupervised Conditional $π$-GAN for Single Image to Neural Radiance Fields Translation
Feb 26, 2022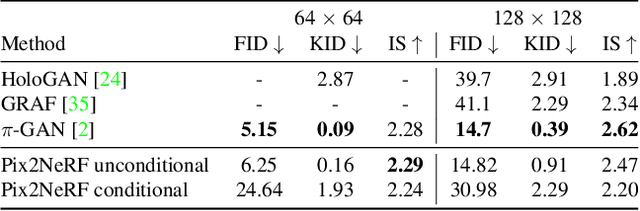
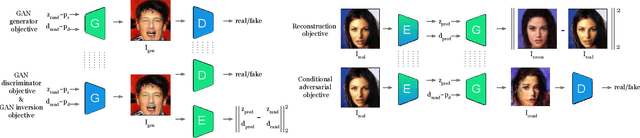
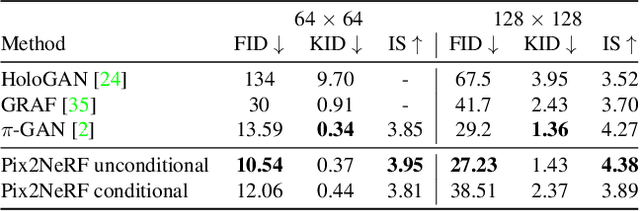

We propose a pipeline to generate Neural Radiance Fields~(NeRF) of an object or a scene of a specific class, conditioned on a single input image. This is a challenging task, as training NeRF requires multiple views of the same scene, coupled with corresponding poses, which are hard to obtain. Our method is based on $\pi$-GAN, a generative model for unconditional 3D-aware image synthesis, which maps random latent codes to radiance fields of a class of objects. We jointly optimize (1) the $\pi$-GAN objective to utilize its high-fidelity 3D-aware generation and (2) a carefully designed reconstruction objective. The latter includes an encoder coupled with $\pi$-GAN generator to form an auto-encoder. Unlike previous few-shot NeRF approaches, our pipeline is unsupervised, capable of being trained with independent images without 3D, multi-view, or pose supervision. Applications of our pipeline include 3d avatar generation, object-centric novel view synthesis with a single input image, and 3d-aware super-resolution, to name a few.
GTAV-NightRain: Photometric Realistic Large-scale Dataset for Night-time Rain Streak Removal
Oct 10, 2022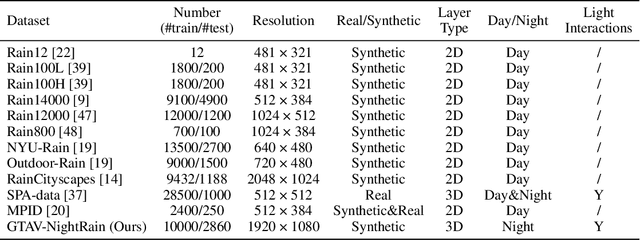
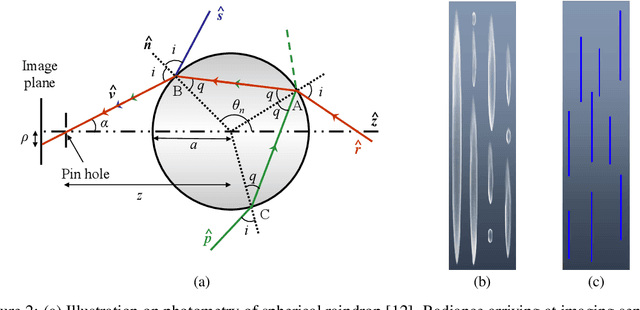
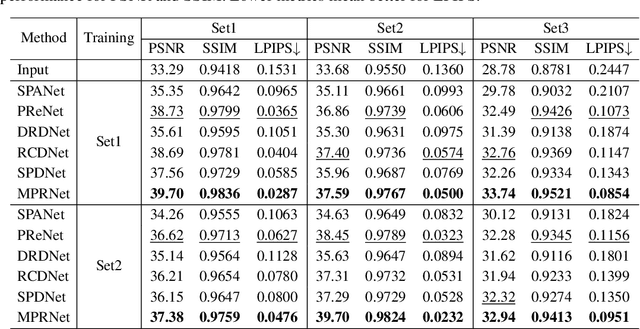
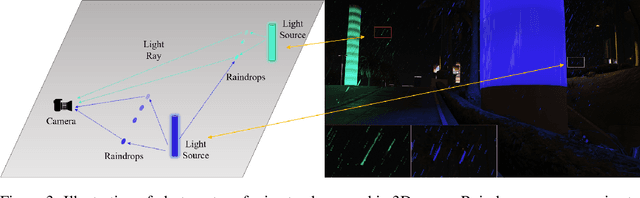
Rain is transparent, which reflects and refracts light in the scene to the camera. In outdoor vision, rain, especially rain streaks degrade visibility and therefore need to be removed. In existing rain streak removal datasets, although density, scale, direction and intensity have been considered, transparency is not fully taken into account. This problem is particularly serious in night scenes, where the appearance of rain largely depends on the interaction with scene illuminations and changes drastically on different positions within the image. This is problematic, because unrealistic dataset causes serious domain bias. In this paper, we propose GTAV-NightRain dataset, which is a large-scale synthetic night-time rain streak removal dataset. Unlike existing datasets, by using 3D computer graphic platform (namely GTA V), we are allowed to infer the three dimensional interaction between rain and illuminations, which insures the photometric realness. Current release of the dataset contains 12,860 HD rainy images and 1,286 corresponding HD ground truth images in diversified night scenes. A systematic benchmark and analysis are provided along with the dataset to inspire further research.
Contrastive Bayesian Analysis for Deep Metric Learning
Oct 10, 2022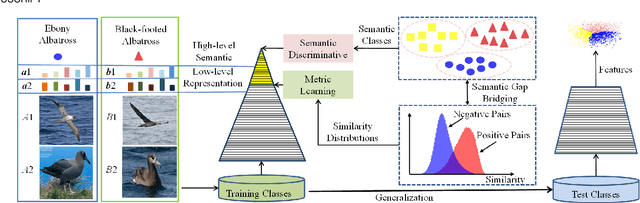
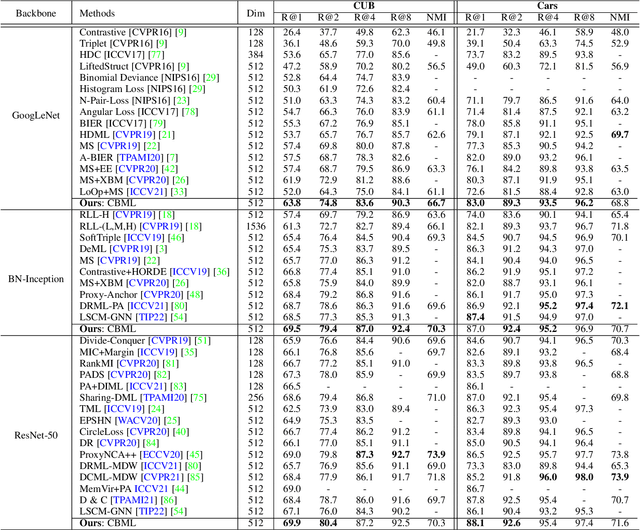
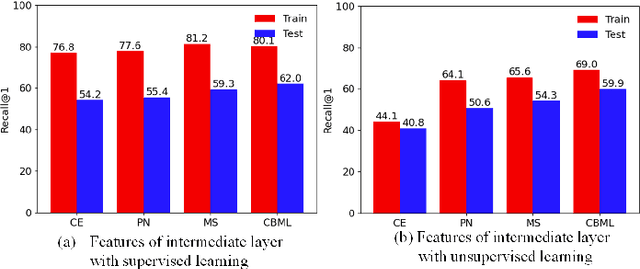
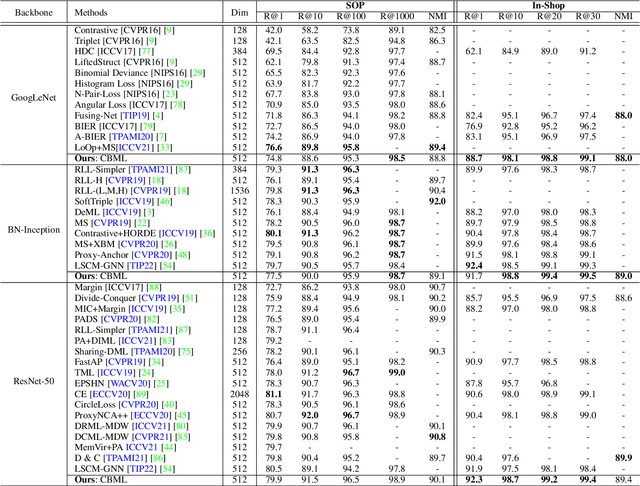
Recent methods for deep metric learning have been focusing on designing different contrastive loss functions between positive and negative pairs of samples so that the learned feature embedding is able to pull positive samples of the same class closer and push negative samples from different classes away from each other. In this work, we recognize that there is a significant semantic gap between features at the intermediate feature layer and class labels at the final output layer. To bridge this gap, we develop a contrastive Bayesian analysis to characterize and model the posterior probabilities of image labels conditioned by their features similarity in a contrastive learning setting. This contrastive Bayesian analysis leads to a new loss function for deep metric learning. To improve the generalization capability of the proposed method onto new classes, we further extend the contrastive Bayesian loss with a metric variance constraint. Our experimental results and ablation studies demonstrate that the proposed contrastive Bayesian metric learning method significantly improves the performance of deep metric learning in both supervised and pseudo-supervised scenarios, outperforming existing methods by a large margin.
Floorplan-Aware Camera Poses Refinement
Oct 10, 2022
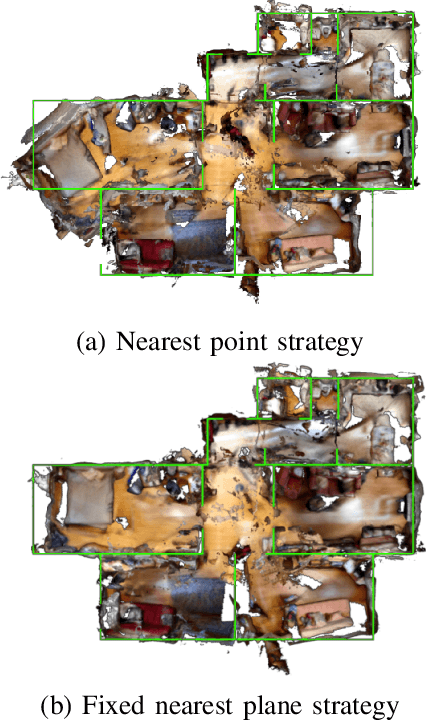
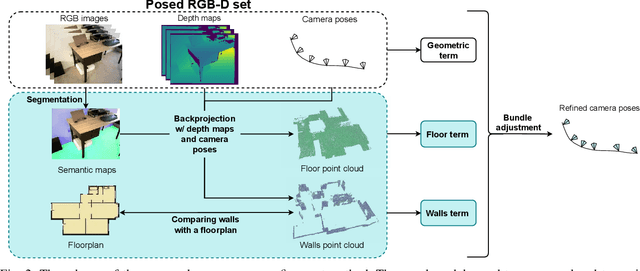

Processing large indoor scenes is a challenging task, as scan registration and camera trajectory estimation methods accumulate errors across time. As a result, the quality of reconstructed scans is insufficient for some applications, such as visual-based localization and navigation, where the correct position of walls is crucial. For many indoor scenes, there exists an image of a technical floorplan that contains information about the geometry and main structural elements of the scene, such as walls, partitions, and doors. We argue that such a floorplan is a useful source of spatial information, which can guide a 3D model optimization. The standard RGB-D 3D reconstruction pipeline consists of a tracking module applied to an RGB-D sequence and a bundle adjustment (BA) module that takes the posed RGB-D sequence and corrects the camera poses to improve consistency. We propose a novel optimization algorithm expanding conventional BA that leverages the prior knowledge about the scene structure in the form of a floorplan. Our experiments on the Redwood dataset and our self-captured data demonstrate that utilizing floorplan improves accuracy of 3D reconstructions.
Quantification of Pollen Viability in Lantana camara By Digital Holographic Microscopy
Oct 10, 2022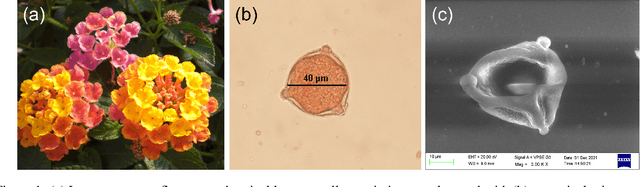

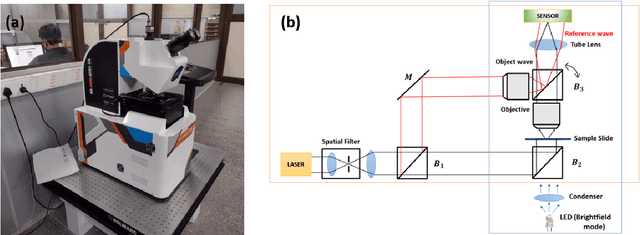
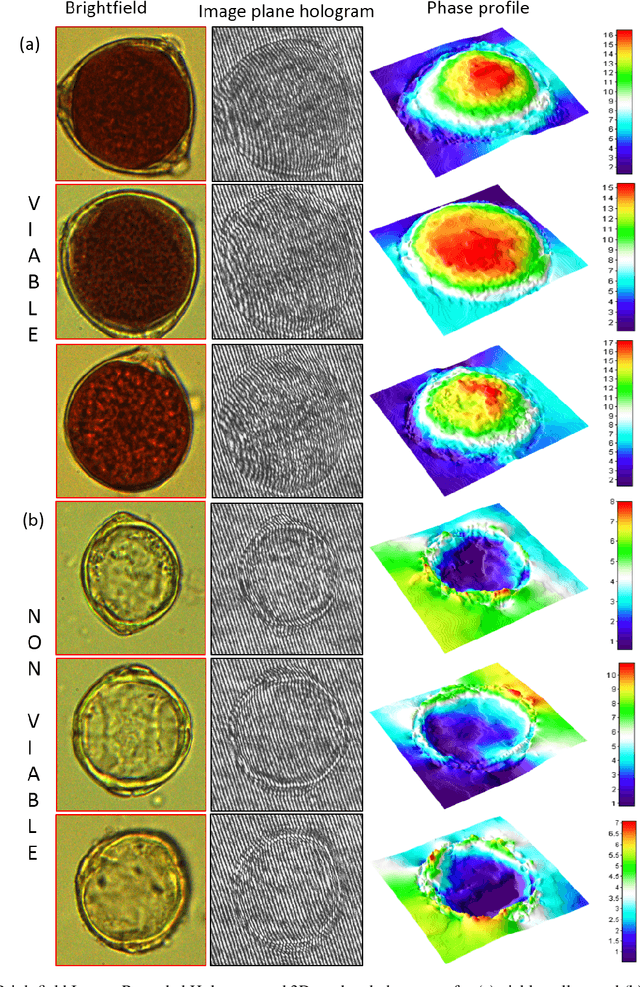
Pollen grains represent the male gametes of seed plants and their viability is critical for efficient sexual reproduction in the plant life cycle. Pollen analysis is used in diverse research thematics to address a range of botanical, ecological and geological questions. More recently it has been recognized that pollen may also be a vector for transgene escape from genetically modified crops, and the importance of pollen viability in invasion biology has also been emphasized. In this work, we analyse and report an efficient visual method for assessing the viability of pollen using digital holographic microscopy (DHM). We test this method on pollen grains of the invasive Lantana camara, a well known plant invader known to most of the tropical world. We image pollen grains and show that the quantitative phase information provided by the DHM technique can be readily related to the chromatin content of the individual cells and thereby to pollen viability. Our results offer a new technique for pollen viability assessment that does not require staining, and can be applied to a number of emerging areas in plant science.
Loop Unrolled Shallow Equilibrium Regularizer (LUSER) -- A Memory-Efficient Inverse Problem Solver
Oct 10, 2022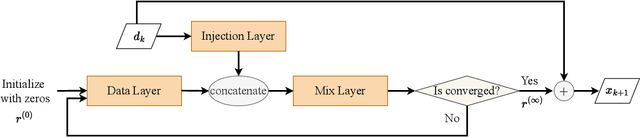

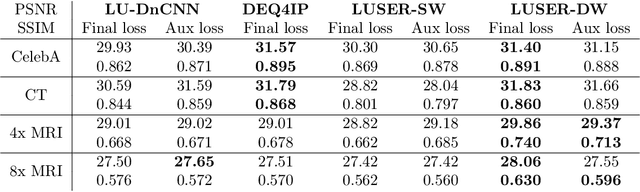
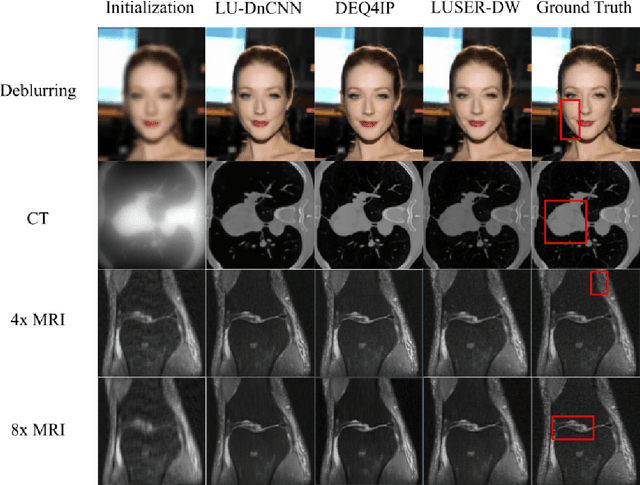
In inverse problems we aim to reconstruct some underlying signal of interest from potentially corrupted and often ill-posed measurements. Classical optimization-based techniques proceed by optimizing a data consistency metric together with a regularizer. Current state-of-the-art machine learning approaches draw inspiration from such techniques by unrolling the iterative updates for an optimization-based solver and then learning a regularizer from data. This loop unrolling (LU) method has shown tremendous success, but often requires a deep model for the best performance leading to high memory costs during training. Thus, to address the balance between computation cost and network expressiveness, we propose an LU algorithm with shallow equilibrium regularizers (LUSER). These implicit models are as expressive as deeper convolutional networks, but far more memory efficient during training. The proposed method is evaluated on image deblurring, computed tomography (CT), as well as single-coil Magnetic Resonance Imaging (MRI) tasks and shows similar, or even better, performance while requiring up to 8 times less computational resources during training when compared against a more typical LU architecture with feedforward convolutional regularizers.
Multi-image Super-resolution via Quality Map Associated Temporal Attention Network
Feb 26, 2022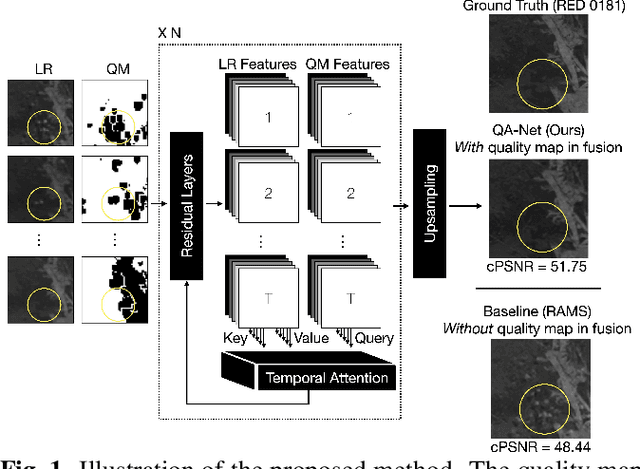
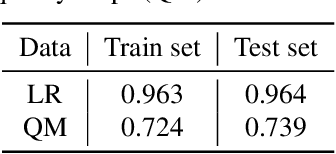

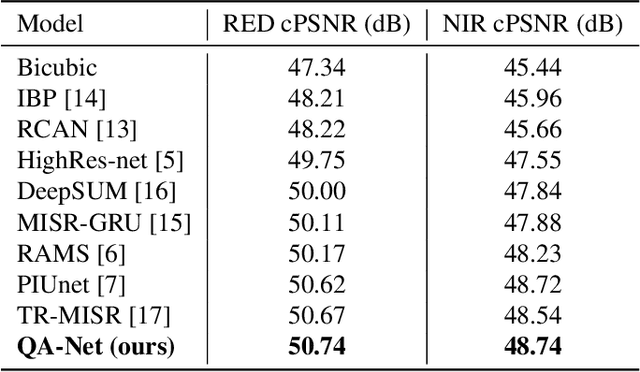
With the rising interest in deep learning-based methods in remote sensing, neural networks have made remarkable advancements in multi-image fusion and super-resolution. To fully exploit the advantages of multi-image super-resolution, temporal attention is crucial as it allows a model to focus on reliable features rather than noises. Despite the presence of quality maps (QMs) that indicate noises in images, most of the methods tested in the PROBA-V dataset have not been used QMs for temporal attention. We present a quality map associated temporal attention network (QA-Net), a novel method that incorporates QMs into both feature representation and fusion processes for the first time. Low-resolution features are temporally attended by QM features in repeated multi-head attention modules. The proposed method achieved state-of-the-art results in the PROBA-V dataset.
Utilizing supervised models to infer consensus labels and their quality from data with multiple annotators
Oct 13, 2022
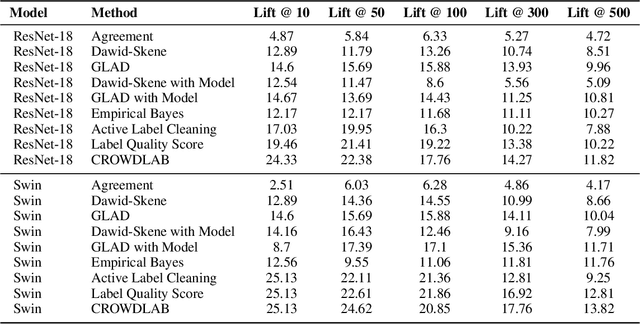
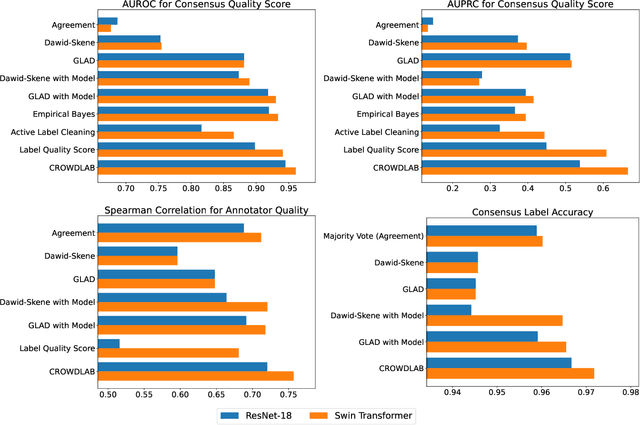
Real-world data for classification is often labeled by multiple annotators. For analyzing such data, we introduce CROWDLAB, a straightforward approach to estimate: (1) A consensus label for each example that aggregates the individual annotations (more accurately than aggregation via majority-vote or other algorithms used in crowdsourcing); (2) A confidence score for how likely each consensus label is correct (via well-calibrated estimates that account for the number of annotations for each example and their agreement, prediction-confidence from a trained classifier, and trustworthiness of each annotator vs. the classifier); (3) A rating for each annotator quantifying the overall correctness of their labels. While many algorithms have been proposed to estimate related quantities in crowdsourcing, these often rely on sophisticated generative models with iterative inference schemes, whereas CROWDLAB is based on simple weighted ensembling. Many algorithms also rely solely on annotator statistics, ignoring the features of the examples from which the annotations derive. CROWDLAB in contrast utilizes any classifier model trained on these features, which can generalize between examples with similar features. In evaluations on real-world multi-annotator image data, our proposed method provides superior estimates for (1)-(3) than many alternative algorithms.