 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBankerToolBench: Evaluating AI Agents in End-to-End Investment Banking Workflows
Apr 13, 2026Existing AI benchmarks lack the fidelity to assess economically meaningful progress on professional workflows. To evaluate frontier AI agents in a high-value, labor-intensive profession, we introduce BankerToolBench (BTB): an open-source benchmark of end-to-end analytical workflows routinely performed by junior investment bankers. To develop an ecologically valid benchmark grounded in representative work environments, we collaborated with 502 investment bankers from leading firms. BTB requires agents to execute senior banker requests by navigating data rooms, using industry tools (market data platform, SEC filings database), and generating multi-file deliverables--including Excel financial models, PowerPoint pitch decks, and PDF/Word reports. Completing a BTB task takes bankers up to 21 hours, underscoring the economic stakes of successfully delegating this work to AI. BTB enables automated evaluation of any LLM or agent, scoring deliverables against 100+ rubric criteria defined by veteran investment bankers to capture stakeholder utility. Testing 9 frontier models, we find that even the best-performing model (GPT-5.4) fails nearly half of the rubric criteria and bankers rate 0% of its outputs as client-ready. Our failure analysis reveals key obstacles (such as breakdowns in cross-artifact consistency) and improvement directions for agentic AI in high-stakes professional workflows.
ActiveLab: Active Learning with Re-Labeling by Multiple Annotators
Jan 27, 2023In real-world data labeling applications, annotators often provide imperfect labels. It is thus common to employ multiple annotators to label data with some overlap between their examples. We study active learning in such settings, aiming to train an accurate classifier by collecting a dataset with the fewest total annotations. Here we propose ActiveLab, a practical method to decide what to label next that works with any classifier model and can be used in pool-based batch active learning with one or multiple annotators. ActiveLab automatically estimates when it is more informative to re-label examples vs. labeling entirely new ones. This is a key aspect of producing high quality labels and trained models within a limited annotation budget. In experiments on image and tabular data, ActiveLab reliably trains more accurate classifiers with far fewer annotations than a wide variety of popular active learning methods.
Utilizing supervised models to infer consensus labels and their quality from data with multiple annotators
Oct 13, 2022
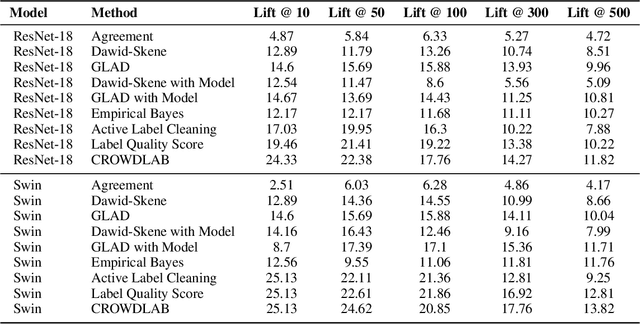
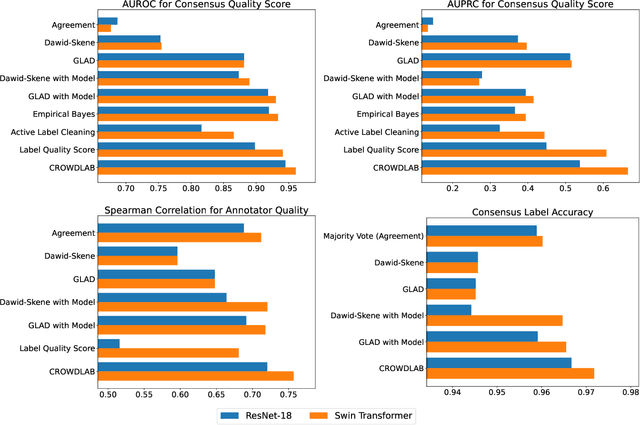
Real-world data for classification is often labeled by multiple annotators. For analyzing such data, we introduce CROWDLAB, a straightforward approach to estimate: (1) A consensus label for each example that aggregates the individual annotations (more accurately than aggregation via majority-vote or other algorithms used in crowdsourcing); (2) A confidence score for how likely each consensus label is correct (via well-calibrated estimates that account for the number of annotations for each example and their agreement, prediction-confidence from a trained classifier, and trustworthiness of each annotator vs. the classifier); (3) A rating for each annotator quantifying the overall correctness of their labels. While many algorithms have been proposed to estimate related quantities in crowdsourcing, these often rely on sophisticated generative models with iterative inference schemes, whereas CROWDLAB is based on simple weighted ensembling. Many algorithms also rely solely on annotator statistics, ignoring the features of the examples from which the annotations derive. CROWDLAB in contrast utilizes any classifier model trained on these features, which can generalize between examples with similar features. In evaluations on real-world multi-annotator image data, our proposed method provides superior estimates for (1)-(3) than many alternative algorithms.