 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplications of Modular Co-Design for De Novo 3D Molecule Generation
May 23, 2025De novo 3D molecule generation is a pivotal task in drug discovery. However, many recent geometric generative models struggle to produce high-quality 3D structures, even if they maintain 2D validity and topological stability. To tackle this issue and enhance the learning of effective molecular generation dynamics, we present Megalodon-a family of scalable transformer models. These models are enhanced with basic equivariant layers and trained using a joint continuous and discrete denoising co-design objective. We assess Megalodon's performance on established molecule generation benchmarks and introduce new 3D structure benchmarks that evaluate a model's capability to generate realistic molecular structures, particularly focusing on energetics. We show that Megalodon achieves state-of-the-art results in 3D molecule generation, conditional structure generation, and structure energy benchmarks using diffusion and flow matching. Furthermore, doubling the number of parameters in Megalodon to 40M significantly enhances its performance, generating up to 49x more valid large molecules and achieving energy levels that are 2-10x lower than those of the best prior generative models.
GEOM-Drugs Revisited: Toward More Chemically Accurate Benchmarks for 3D Molecule Generation
Apr 30, 2025



Deep generative models have shown significant promise in generating valid 3D molecular structures, with the GEOM-Drugs dataset serving as a key benchmark. However, current evaluation protocols suffer from critical flaws, including incorrect valency definitions, bugs in bond order calculations, and reliance on force fields inconsistent with the reference data. In this work, we revisit GEOM-Drugs and propose a corrected evaluation framework: we identify and fix issues in data preprocessing, construct chemically accurate valency tables, and introduce a GFN2-xTB-based geometry and energy benchmark. We retrain and re-evaluate several leading models under this framework, providing updated performance metrics and practical recommendations for future benchmarking. Our results underscore the need for chemically rigorous evaluation practices in 3D molecular generation. Our recommended evaluation methods and GEOM-Drugs processing scripts are available at https://github.com/isayevlab/geom-drugs-3dgen-evaluation.
Floorplan-Aware Camera Poses Refinement
Oct 10, 2022
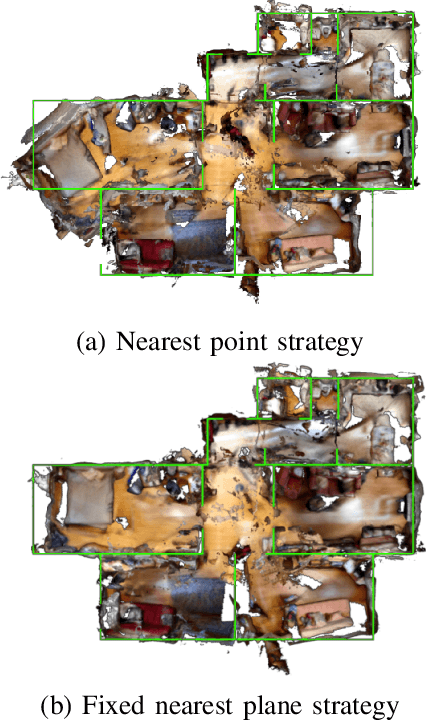
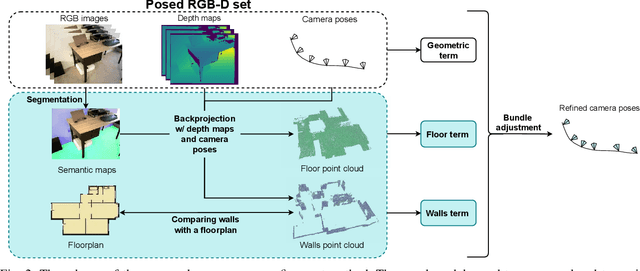

Processing large indoor scenes is a challenging task, as scan registration and camera trajectory estimation methods accumulate errors across time. As a result, the quality of reconstructed scans is insufficient for some applications, such as visual-based localization and navigation, where the correct position of walls is crucial. For many indoor scenes, there exists an image of a technical floorplan that contains information about the geometry and main structural elements of the scene, such as walls, partitions, and doors. We argue that such a floorplan is a useful source of spatial information, which can guide a 3D model optimization. The standard RGB-D 3D reconstruction pipeline consists of a tracking module applied to an RGB-D sequence and a bundle adjustment (BA) module that takes the posed RGB-D sequence and corrects the camera poses to improve consistency. We propose a novel optimization algorithm expanding conventional BA that leverages the prior knowledge about the scene structure in the form of a floorplan. Our experiments on the Redwood dataset and our self-captured data demonstrate that utilizing floorplan improves accuracy of 3D reconstructions.
DDI-100: Dataset for Text Detection and Recognition
Dec 25, 2019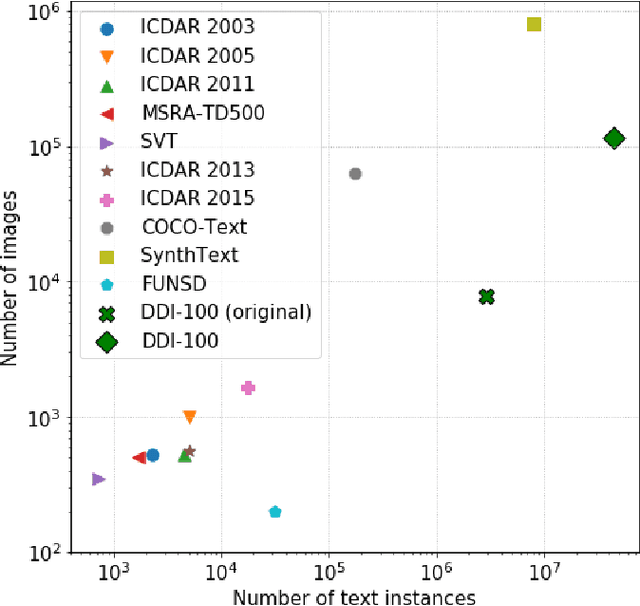
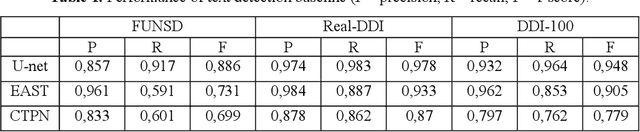

Nowadays document analysis and recognition remain challenging tasks. However, only a few datasets designed for text detection (TD) and optical character recognition (OCR) problems exist. In this paper we present Distorted Document Images dataset (DDI-100) and demonstrate its usefulness in a wide range of document analysis problems. DDI-100 dataset is a synthetic dataset based on 7000 real unique document pages and consists of more than 100000 augmented images. Ground truth comprises text and stamp masks, text and characters bounding boxes with relevant annotations. Validation of DDI-100 dataset was conducted using several TD and OCR models that show high-quality performance on real data.