 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEAR$^2$: A Nested Embedding Approach to Efficient Product Retrieval and Ranking
Jun 24, 2025E-commerce information retrieval (IR) systems struggle to simultaneously achieve high accuracy in interpreting complex user queries and maintain efficient processing of vast product catalogs. The dual challenge lies in precisely matching user intent with relevant products while managing the computational demands of real-time search across massive inventories. In this paper, we propose a Nested Embedding Approach to product Retrieval and Ranking, called NEAR$^2$, which can achieve up to $12$ times efficiency in embedding size at inference time while introducing no extra cost in training and improving performance in accuracy for various encoder-based Transformer models. We validate our approach using different loss functions for the retrieval and ranking task, including multiple negative ranking loss and online contrastive loss, on four different test sets with various IR challenges such as short and implicit queries. Our approach achieves an improved performance over a smaller embedding dimension, compared to any existing models.
3D Audio-Visual Segmentation
Nov 04, 2024



Recognizing the sounding objects in scenes is a longstanding objective in embodied AI, with diverse applications in robotics and AR/VR/MR. To that end, Audio-Visual Segmentation (AVS), taking as condition an audio signal to identify the masks of the target sounding objects in an input image with synchronous camera and microphone sensors, has been recently advanced. However, this paradigm is still insufficient for real-world operation, as the mapping from 2D images to 3D scenes is missing. To address this fundamental limitation, we introduce a novel research problem, 3D Audio-Visual Segmentation, extending the existing AVS to the 3D output space. This problem poses more challenges due to variations in camera extrinsics, audio scattering, occlusions, and diverse acoustics across sounding object categories. To facilitate this research, we create the very first simulation based benchmark, 3DAVS-S34-O7, providing photorealistic 3D scene environments with grounded spatial audio under single-instance and multi-instance settings, across 34 scenes and 7 object categories. This is made possible by re-purposing the Habitat simulator to generate comprehensive annotations of sounding object locations and corresponding 3D masks. Subsequently, we propose a new approach, EchoSegnet, characterized by integrating the ready-to-use knowledge from pretrained 2D audio-visual foundation models synergistically with 3D visual scene representation through spatial audio-aware mask alignment and refinement. Extensive experiments demonstrate that EchoSegnet can effectively segment sounding objects in 3D space on our new benchmark, representing a significant advancement in the field of embodied AI. Project page: https://surrey-uplab.github.io/research/3d-audio-visual-segmentation/
Centrality-aware Product Retrieval and Ranking
Oct 21, 2024This paper addresses the challenge of improving user experience on e-commerce platforms by enhancing product ranking relevant to users' search queries. Ambiguity and complexity of user queries often lead to a mismatch between the user's intent and retrieved product titles or documents. Recent approaches have proposed the use of Transformer-based models, which need millions of annotated query-title pairs during the pre-training stage, and this data often does not take user intent into account. To tackle this, we curate samples from existing datasets at eBay, manually annotated with buyer-centric relevance scores and centrality scores, which reflect how well the product title matches the users' intent. We introduce a User-intent Centrality Optimization (UCO) approach for existing models, which optimises for the user intent in semantic product search. To that end, we propose a dual-loss based optimisation to handle hard negatives, i.e., product titles that are semantically relevant but do not reflect the user's intent. Our contributions include curating challenging evaluation sets and implementing UCO, resulting in significant product ranking efficiency improvements observed for different evaluation metrics. Our work aims to ensure that the most buyer-centric titles for a query are ranked higher, thereby, enhancing the user experience on e-commerce platforms.
AV-GS: Learning Material and Geometry Aware Priors for Novel View Acoustic Synthesis
Jun 14, 2024



Novel view acoustic synthesis (NVAS) aims to render binaural audio at any target viewpoint, given a mono audio emitted by a sound source at a 3D scene. Existing methods have proposed NeRF-based implicit models to exploit visual cues as a condition for synthesizing binaural audio. However, in addition to low efficiency originating from heavy NeRF rendering, these methods all have a limited ability of characterizing the entire scene environment such as room geometry, material properties, and the spatial relation between the listener and sound source. To address these issues, we propose a novel Audio-Visual Gaussian Splatting (AV-GS) model. To obtain a material-aware and geometry-aware condition for audio synthesis, we learn an explicit point-based scene representation with an audio-guidance parameter on locally initialized Gaussian points, taking into account the space relation from the listener and sound source. To make the visual scene model audio adaptive, we propose a point densification and pruning strategy to optimally distribute the Gaussian points, with the per-point contribution in sound propagation (e.g., more points needed for texture-less wall surfaces as they affect sound path diversion). Extensive experiments validate the superiority of our AV-GS over existing alternatives on the real-world RWAS and simulation-based SoundSpaces datasets.
Unsupervised Audio-Visual Segmentation with Modality Alignment
Mar 21, 2024



Audio-Visual Segmentation (AVS) aims to identify, at the pixel level, the object in a visual scene that produces a given sound. Current AVS methods rely on costly fine-grained annotations of mask-audio pairs, making them impractical for scalability. To address this, we introduce unsupervised AVS, eliminating the need for such expensive annotation. To tackle this more challenging problem, we propose an unsupervised learning method, named Modality Correspondence Alignment (MoCA), which seamlessly integrates off-the-shelf foundation models like DINO, SAM, and ImageBind. This approach leverages their knowledge complementarity and optimizes their joint usage for multi-modality association. Initially, we estimate positive and negative image pairs in the feature space. For pixel-level association, we introduce an audio-visual adapter and a novel pixel matching aggregation strategy within the image-level contrastive learning framework. This allows for a flexible connection between object appearance and audio signal at the pixel level, with tolerance to imaging variations such as translation and rotation. Extensive experiments on the AVSBench (single and multi-object splits) and AVSS datasets demonstrate that our MoCA outperforms strongly designed baseline methods and approaches supervised counterparts, particularly in complex scenarios with multiple auditory objects. Notably when comparing mIoU, MoCA achieves a substantial improvement over baselines in both the AVSBench (S4: +17.24%; MS3: +67.64%) and AVSS (+19.23%) audio-visual segmentation challenges.
Sarcasm in Sight and Sound: Benchmarking and Expansion to Improve Multimodal Sarcasm Detection
Sep 29, 2023



The introduction of the MUStARD dataset, and its emotion recognition extension MUStARD++, have identified sarcasm to be a multi-modal phenomenon -- expressed not only in natural language text, but also through manners of speech (like tonality and intonation) and visual cues (facial expression). With this work, we aim to perform a rigorous benchmarking of the MUStARD++ dataset by considering state-of-the-art language, speech, and visual encoders, for fully utilizing the totality of the multi-modal richness that it has to offer, achieving a 2\% improvement in macro-F1 over the existing benchmark. Additionally, to cure the imbalance in the `sarcasm type' category in MUStARD++, we propose an extension, which we call \emph{MUStARD++ Balanced}, benchmarking the same with instances from the extension split across both train and test sets, achieving a further 2.4\% macro-F1 boost. The new clips were taken from a novel source -- the TV show, House MD, which adds to the diversity of the dataset, and were manually annotated by multiple annotators with substantial inter-annotator agreement in terms of Cohen's kappa and Krippendorf's alpha. Our code, extended data, and SOTA benchmark models are made public.
Leveraging Foundation models for Unsupervised Audio-Visual Segmentation
Sep 13, 2023Audio-Visual Segmentation (AVS) aims to precisely outline audible objects in a visual scene at the pixel level. Existing AVS methods require fine-grained annotations of audio-mask pairs in supervised learning fashion. This limits their scalability since it is time consuming and tedious to acquire such cross-modality pixel level labels. To overcome this obstacle, in this work we introduce unsupervised audio-visual segmentation with no need for task-specific data annotations and model training. For tackling this newly proposed problem, we formulate a novel Cross-Modality Semantic Filtering (CMSF) approach to accurately associate the underlying audio-mask pairs by leveraging the off-the-shelf multi-modal foundation models (e.g., detection [1], open-world segmentation [2] and multi-modal alignment [3]). Guiding the proposal generation by either audio or visual cues, we design two training-free variants: AT-GDINO-SAM and OWOD-BIND. Extensive experiments on the AVS-Bench dataset show that our unsupervised approach can perform well in comparison to prior art supervised counterparts across complex scenarios with multiple auditory objects. Particularly, in situations where existing supervised AVS methods struggle with overlapping foreground objects, our models still excel in accurately segmenting overlapped auditory objects. Our code will be publicly released.
DiffSED: Sound Event Detection with Denoising Diffusion
Aug 16, 2023Sound Event Detection (SED) aims to predict the temporal boundaries of all the events of interest and their class labels, given an unconstrained audio sample. Taking either the splitand-classify (i.e., frame-level) strategy or the more principled event-level modeling approach, all existing methods consider the SED problem from the discriminative learning perspective. In this work, we reformulate the SED problem by taking a generative learning perspective. Specifically, we aim to generate sound temporal boundaries from noisy proposals in a denoising diffusion process, conditioned on a target audio sample. During training, our model learns to reverse the noising process by converting noisy latent queries to the groundtruth versions in the elegant Transformer decoder framework. Doing so enables the model generate accurate event boundaries from even noisy queries during inference. Extensive experiments on the Urban-SED and EPIC-Sounds datasets demonstrate that our model significantly outperforms existing alternatives, with 40+% faster convergence in training.
Text-to-Audio Grounding Based Novel Metric for Evaluating Audio Caption Similarity
Oct 03, 2022
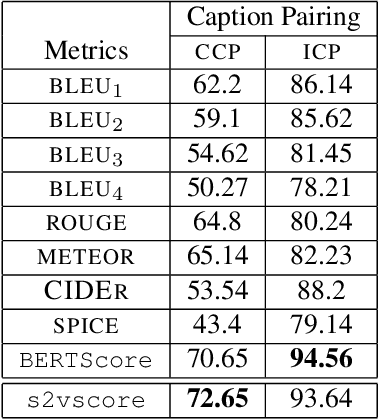
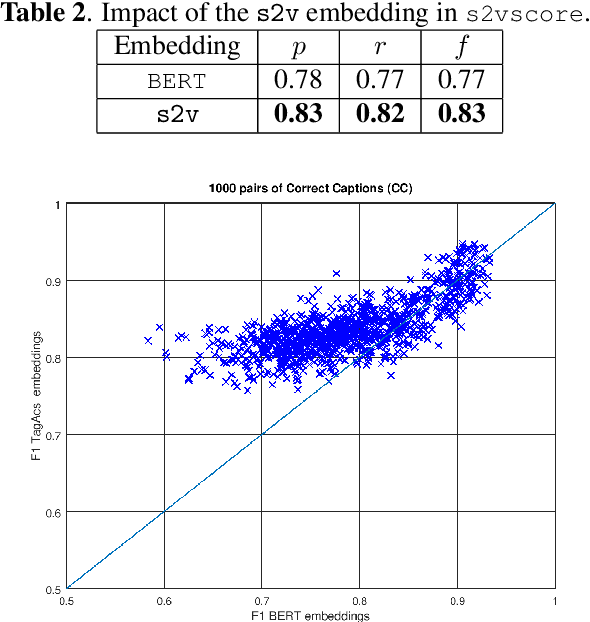
Automatic Audio Captioning (AAC) refers to the task of translating an audio sample into a natural language (NL) text that describes the audio events, source of the events and their relationships. Unlike NL text generation tasks, which rely on metrics like BLEU, ROUGE, METEOR based on lexical semantics for evaluation, the AAC evaluation metric requires an ability to map NL text (phrases) that correspond to similar sounds in addition lexical semantics. Current metrics used for evaluation of AAC tasks lack an understanding of the perceived properties of sound represented by text. In this paper, wepropose a novel metric based on Text-to-Audio Grounding (TAG), which is, useful for evaluating cross modal tasks like AAC. Experiments on publicly available AAC data-set shows our evaluation metric to perform better compared to existing metrics used in NL text and image captioning literature.
Automatic Audio Captioning using Attention weighted Event based Embeddings
Jan 28, 2022



Automatic Audio Captioning (AAC) refers to the task of translating audio into a natural language that describes the audio events, source of the events and their relationships. The limited samples in AAC datasets at present, has set up a trend to incorporate transfer learning with Audio Event Detection (AED) as a parent task. Towards this direction, in this paper, we propose an encoder-decoder architecture with light-weight (i.e. with lesser learnable parameters) Bi-LSTM recurrent layers for AAC and compare the performance of two state-of-the-art pre-trained AED models as embedding extractors. Our results show that an efficient AED based embedding extractor combined with temporal attention and augmentation techniques is able to surpass existing literature with computationally intensive architectures. Further, we provide evidence of the ability of the non-uniform attention weighted encoding generated as a part of our model to facilitate the decoder glance over specific sections of the audio while generating each token.