 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Regularized directional representations for medical image registration
Nov 30, 2021
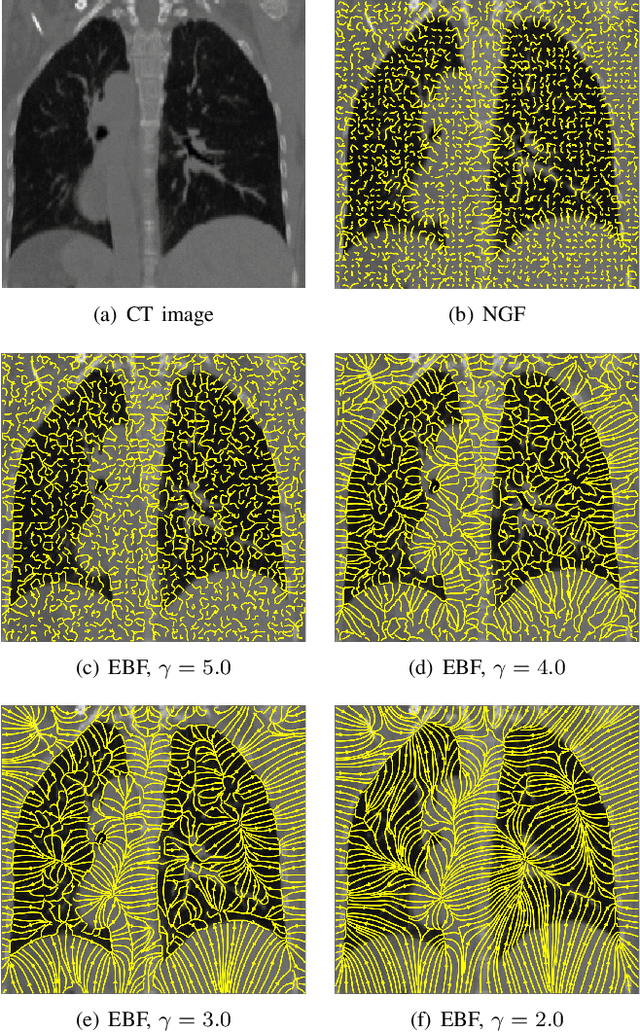
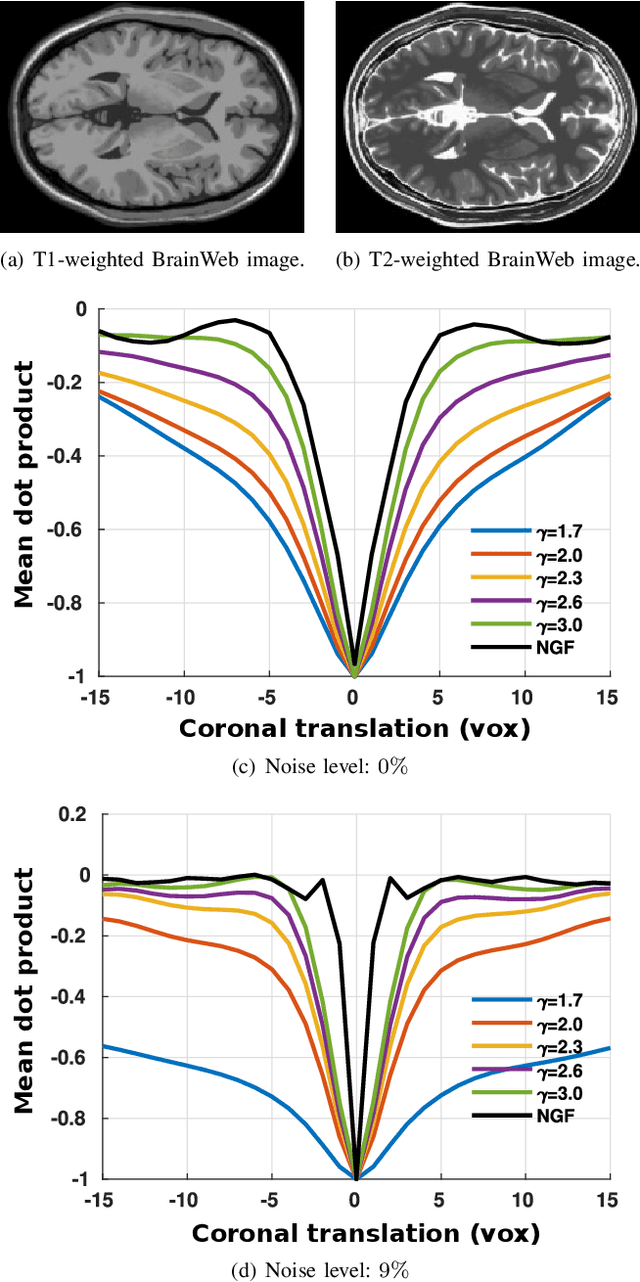
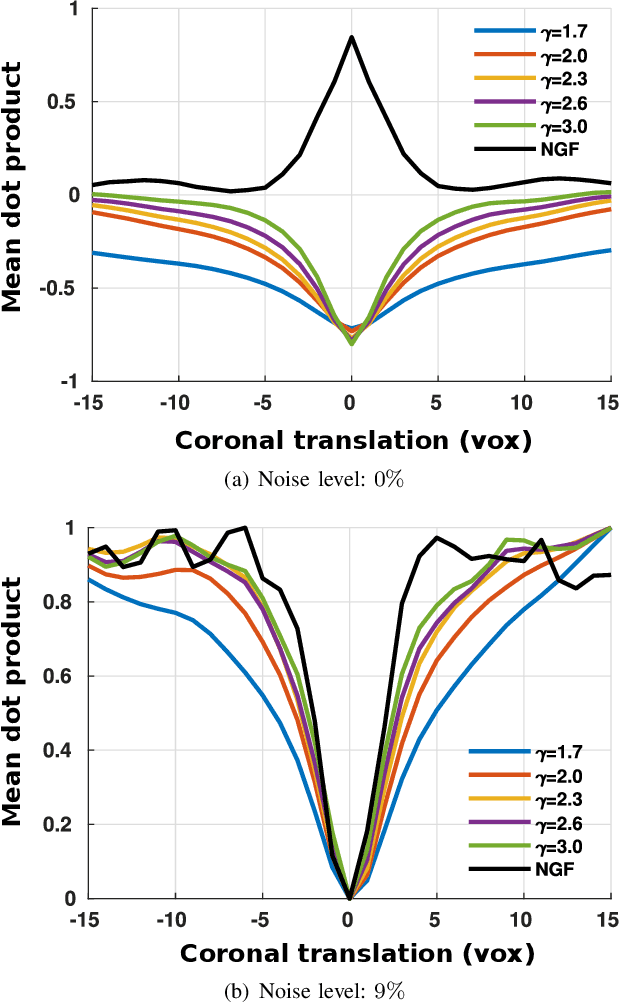
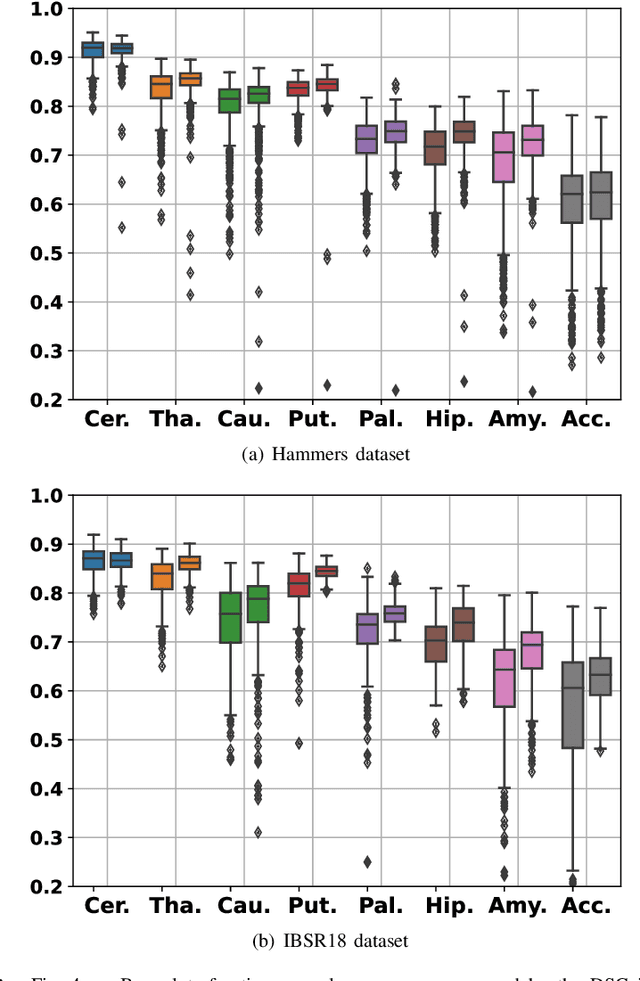
In image registration, many efforts have been devoted to the development of alternatives to the popular normalized mutual information criterion. Concurrently to these efforts, an increasing number of works have demonstrated that substantial gains in registration accuracy can also be achieved by aligning structural representations of images rather than images themselves. Following this research path, we propose a new method for mono- and multimodal image registration based on the alignment of regularized vector fields derived from structural information such as gradient vector flow fields, a technique we call \textit{vector field similarity}. Our approach can be combined in a straightforward fashion with any existing registration framework by substituting vector field similarity to intensity-based registration. In our experiments, we show that the proposed approach compares favourably with conventional image alignment on several public image datasets using a diversity of imaging modalities and anatomical locations.
A deep learning network with differentiable dynamic programming for retina OCT surface segmentation
Oct 08, 2022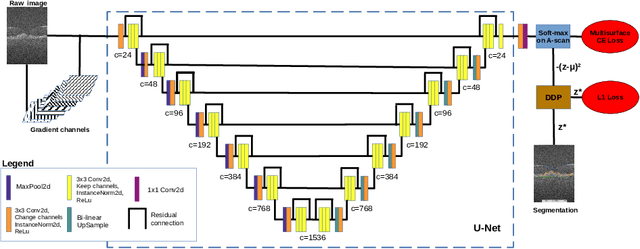
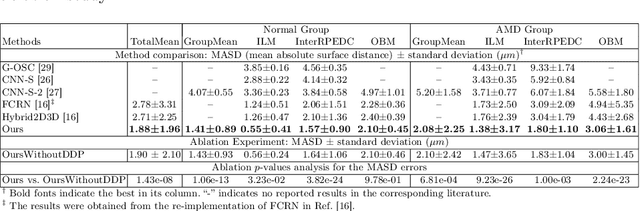
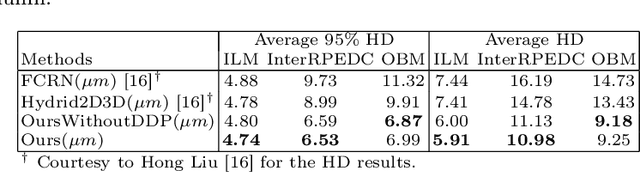
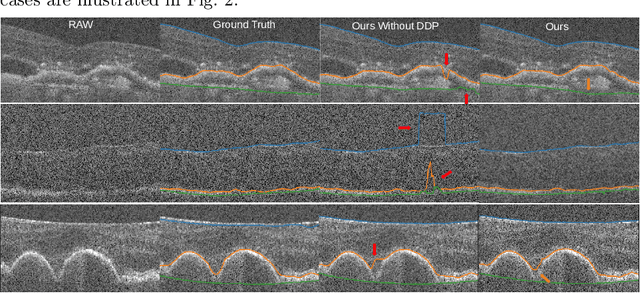
Multiple-surface segmentation in Optical Coherence Tomography (OCT) images is a challenge problem, further complicated by the frequent presence of weak image boundaries. Recently, many deep learning (DL) based methods have been developed for this task and yield remarkable performance. Unfortunately, due to the scarcity of training data in medical imaging, it is challenging for DL networks to learn the global structure of the target surfaces, including surface smoothness. To bridge this gap, this study proposes to seamlessly unify a U-Net for feature learning with a constrained differentiable dynamic programming module to achieve an end-to-end learning for retina OCT surface segmentation to explicitly enforce surface smoothness. It effectively utilizes the feedback from the downstream model optimization module to guide feature learning, yielding a better enforcement of global structures of the target surfaces. Experiments on Duke AMD (age-related macular degeneration) and JHU MS (multiple sclerosis) OCT datasets for retinal layer segmentation demonstrated very promising segmentation accuracy.
Any-resolution Training for High-resolution Image Synthesis
Apr 14, 2022
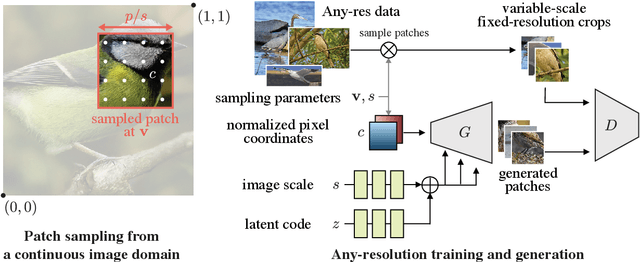
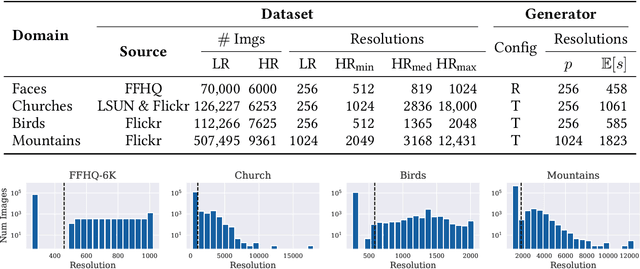
Generative models operate at fixed resolution, even though natural images come in a variety of sizes. As high-resolution details are downsampled away, and low-resolution images are discarded altogether, precious supervision is lost. We argue that every pixel matters and create datasets with variable-size images, collected at their native resolutions. Taking advantage of this data is challenging; high-resolution processing is costly, and current architectures can only process fixed-resolution data. We introduce continuous-scale training, a process that samples patches at random scales to train a new generator with variable output resolutions. First, conditioning the generator on a target scale allows us to generate higher resolutions images than previously possible, without adding layers to the model. Second, by conditioning on continuous coordinates, we can sample patches that still obey a consistent global layout, which also allows for scalable training at higher resolutions. Controlled FFHQ experiments show our method takes advantage of the multi-resolution training data better than discrete multi-scale approaches, achieving better FID scores and cleaner high-frequency details. We also train on other natural image domains including churches, mountains, and birds, and demonstrate arbitrary scale synthesis with both coherent global layouts and realistic local details, going beyond 2K resolution in our experiments. Our project page is available at: https://chail.github.io/anyres-gan/.
Adaptive Adversarial Training to Improve Adversarial Robustness of DNNs for Medical Image Segmentation and Detection
Jun 02, 2022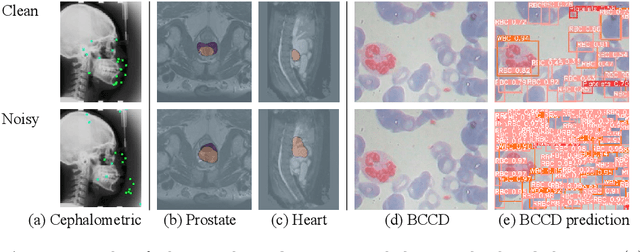
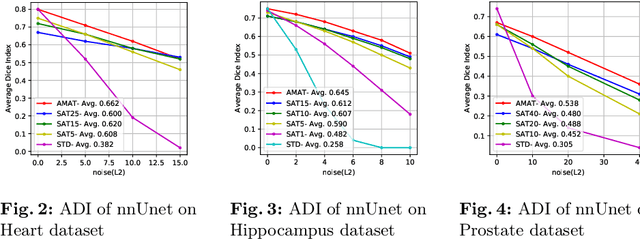
Recent methods based on Deep Neural Networks (DNNs) have reached high accuracy for medical image analysis, including the three basic tasks: segmentation, landmark detection, and object detection. It is known that DNNs are vulnerable to adversarial attacks, and the adversarial robustness of DNNs could be improved by adding adversarial noises to training data (i.e., adversarial training). In this study, we show that the standard adversarial training (SAT) method has a severe issue that limits its practical use: it generates a fixed level of noise for DNN training, and it is difficult for the user to choose an appropriate noise level, because a high noise level may lead to a large reduction in model performance, and a low noise level may have little effect. To resolve this issue, we have designed a novel adaptive-margin adversarial training (AMAT) method that generates adaptive adversarial noises for DNN training, which are dynamically tailored for each individual training sample. We have applied our AMAT method to state-of-the-art DNNs for the three basic tasks, using five publicly available datasets. The experimental results demonstrate that our AMAT method outperforms the SAT method in adversarial robustness on noisy data and prediction accuracy on clean data. Please contact the author for the source code.
gSwin: Gated MLP Vision Model with Hierarchical Structure of Shifted Window
Aug 24, 2022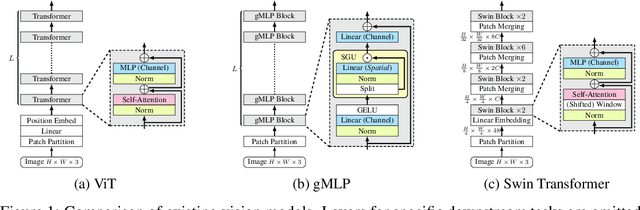
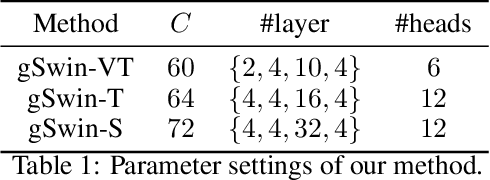
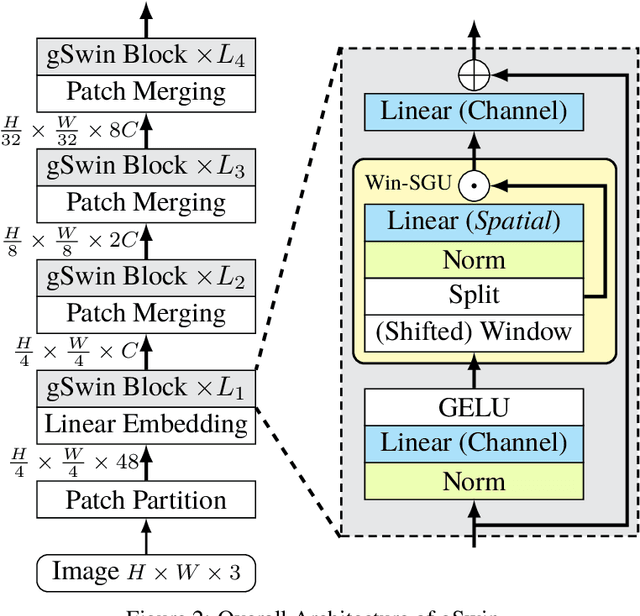
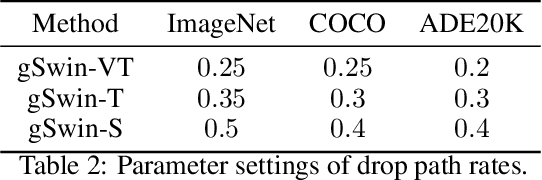
Following the success in language domain, the self-attention mechanism (transformer) is adopted in the vision domain and achieving great success recently. Additionally, as another stream, multi-layer perceptron (MLP) is also explored in the vision domain. These architectures, other than traditional CNNs, have been attracting attention recently, and many methods have been proposed. As one that combines parameter efficiency and performance with locality and hierarchy in image recognition, we propose gSwin, which merges the two streams; Swin Transformer and (multi-head) gMLP. We showed that our gSwin can achieve better accuracy on three vision tasks, image classification, object detection and semantic segmentation, than Swin Transformer, with smaller model size.
Challenges of Adversarial Image Augmentations
Dec 03, 2021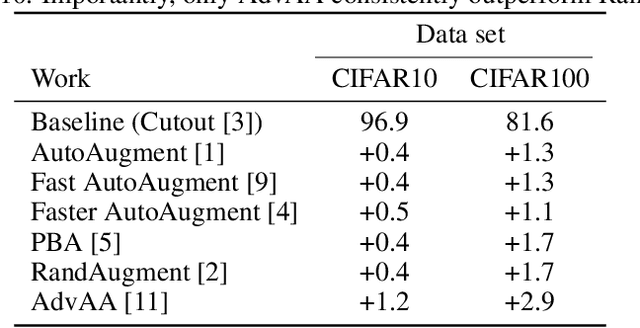


Image augmentations applied during training are crucial for the generalization performance of image classifiers. Therefore, a large body of research has focused on finding the optimal augmentation policy for a given task. Yet, RandAugment [2], a simple random augmentation policy, has recently been shown to outperform existing sophisticated policies. Only Adversarial AutoAugment (AdvAA) [11], an approach based on the idea of adversarial training, has shown to be better than RandAugment. In this paper, we show that random augmentations are still competitive compared to an optimal adversarial approach, as well as to simple curricula, and conjecture that the success of AdvAA is due to the stochasticity of the policy controller network, which introduces a mild form of curriculum.
C3-STISR: Scene Text Image Super-resolution with Triple Clues
Apr 29, 2022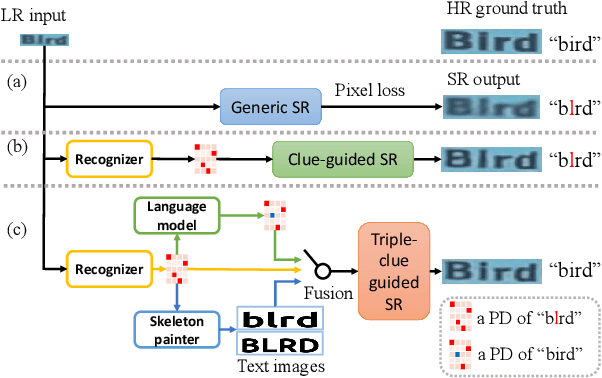
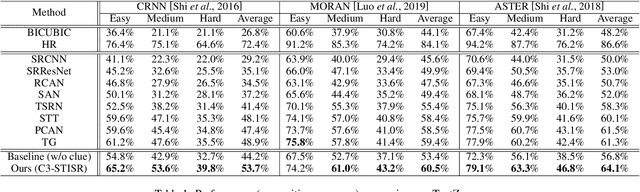
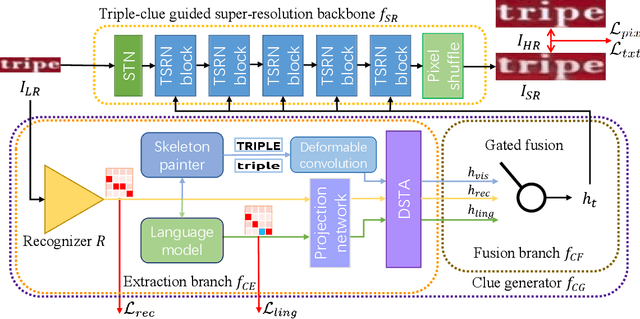
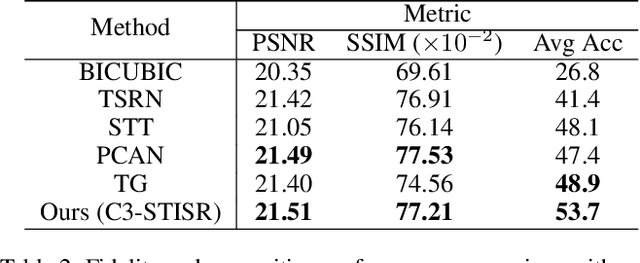
Scene text image super-resolution (STISR) has been regarded as an important pre-processing task for text recognition from low-resolution scene text images. Most recent approaches use the recognizer's feedback as clues to guide super-resolution. However, directly using recognition clue has two problems: 1) Compatibility. It is in the form of probability distribution, has an obvious modal gap with STISR - a pixel-level task; 2) Inaccuracy. it usually contains wrong information, thus will mislead the main task and degrade super-resolution performance. In this paper, we present a novel method C3-STISR that jointly exploits the recognizer's feedback, visual and linguistical information as clues to guide super-resolution. Here, visual clue is from the images of texts predicted by the recognizer, which is informative and more compatible with the STISR task; while linguistical clue is generated by a pre-trained character-level language model, which is able to correct the predicted texts. We design effective extraction and fusion mechanisms for the triple cross-modal clues to generate a comprehensive and unified guidance for super-resolution. Extensive experiments on TextZoom show that C3-STISR outperforms the SOTA methods in fidelity and recognition performance. Code is available in https://github.com/zhaominyiz/C3-STISR.
Revisiting Weak-to-Strong Consistency in Semi-Supervised Semantic Segmentation
Aug 21, 2022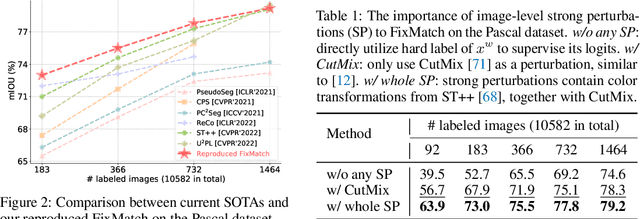
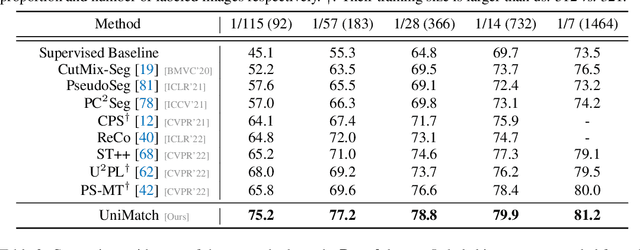

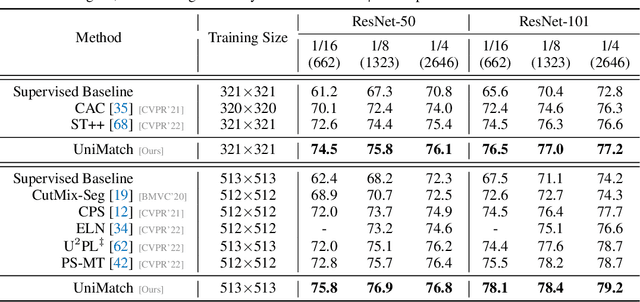
In this work, we revisit the weak-to-strong consistency framework, popularized by FixMatch from semi-supervised classification, where the prediction of a weakly perturbed image serves as supervision for its strongly perturbed version. Intriguingly, we observe that such a simple pipeline already achieves competitive results against recent advanced works, when transferred to our segmentation scenario. Its success heavily relies on the manual design of strong data augmentations, however, which may be limited and inadequate to explore a broader perturbation space. Motivated by this, we propose an auxiliary feature perturbation stream as a supplement, leading to an expanded perturbation space. On the other, to sufficiently probe original image-level augmentations, we present a dual-stream perturbation technique, enabling two strong views to be simultaneously guided by a common weak view. Consequently, our overall Unified Dual-Stream Perturbations approach (UniMatch) surpasses all existing methods significantly across all evaluation protocols on the Pascal, Cityscapes, and COCO benchmarks. We also demonstrate the superiority of our method in remote sensing interpretation and medical image analysis. Code is available at https://github.com/LiheYoung/UniMatch.
Hybrid Fusion Based Interpretable Multimodal Emotion Recognition with Insufficient Labelled Data
Aug 24, 2022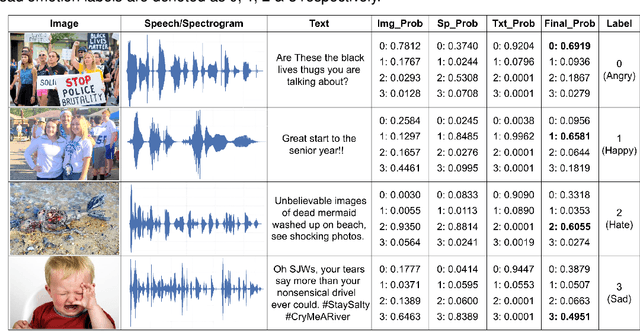
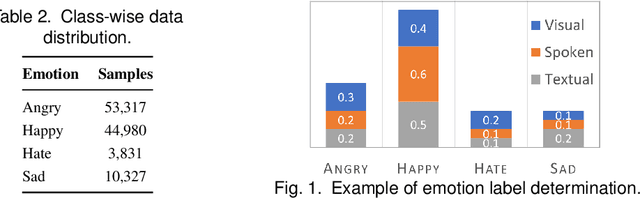
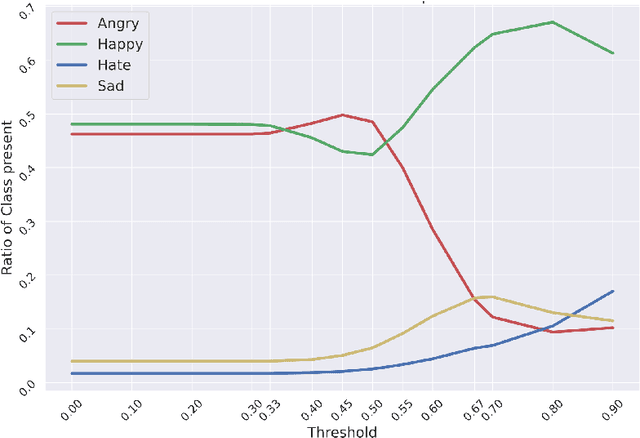
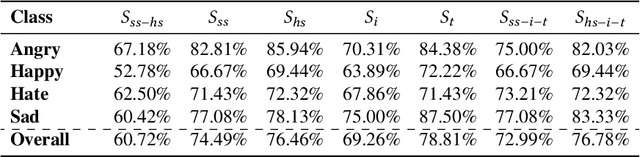
This paper proposes a multimodal emotion recognition system, VIsual Spoken Textual Additive Net (VISTA Net), to classify the emotions reflected by a multimodal input containing image, speech, and text into discrete classes. A new interpretability technique, K-Average Additive exPlanation (KAAP), has also been developed to identify the important visual, spoken, and textual features leading to predicting a particular emotion class. The VISTA Net fuses the information from image, speech & text modalities using a hybrid of early and late fusion. It automatically adjusts the weights of their intermediate outputs while computing the weighted average without human intervention. The KAAP technique computes the contribution of each modality and corresponding features toward predicting a particular emotion class. To mitigate the insufficiency of multimodal emotion datasets labeled with discrete emotion classes, we have constructed a large-scale IIT-R MMEmoRec dataset consisting of real-life images, corresponding speech & text, and emotion labels ('angry,' 'happy,' 'hate,' and 'sad.'). The VISTA Net has resulted in 95.99% emotion recognition accuracy on considering image, speech, and text modalities, which is better than the performance on considering the inputs of any one or two modalities.
Unsupervised confidence for LiDAR depth maps and applications
Oct 06, 2022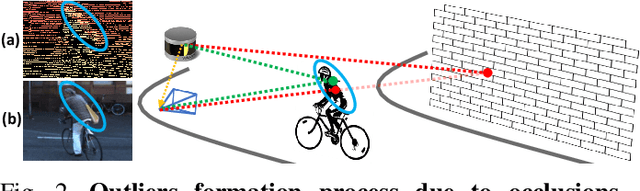
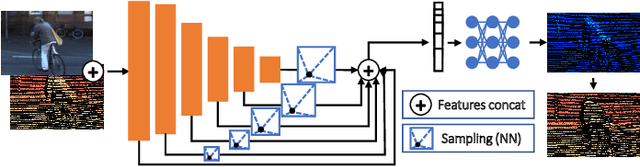

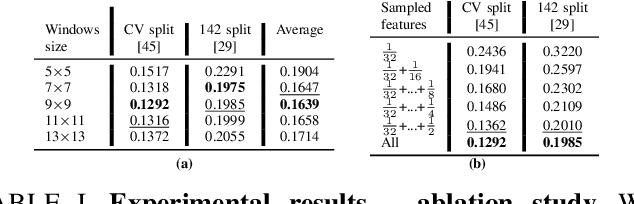
Depth perception is pivotal in many fields, such as robotics and autonomous driving, to name a few. Consequently, depth sensors such as LiDARs rapidly spread in many applications. The 3D point clouds generated by these sensors must often be coupled with an RGB camera to understand the framed scene semantically. Usually, the former is projected over the camera image plane, leading to a sparse depth map. Unfortunately, this process, coupled with the intrinsic issues affecting all the depth sensors, yields noise and gross outliers in the final output. Purposely, in this paper, we propose an effective unsupervised framework aimed at explicitly addressing this issue by learning to estimate the confidence of the LiDAR sparse depth map and thus allowing for filtering out the outliers. Experimental results on the KITTI dataset highlight that our framework excels for this purpose. Moreover, we demonstrate how this achievement can improve a wide range of tasks.