 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image Data collection and implementation of deep learning-based model in detecting Monkeypox disease using modified VGG16
Jun 04, 2022
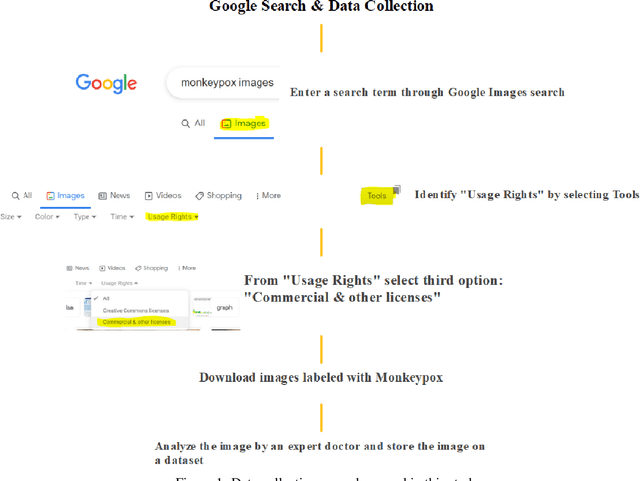
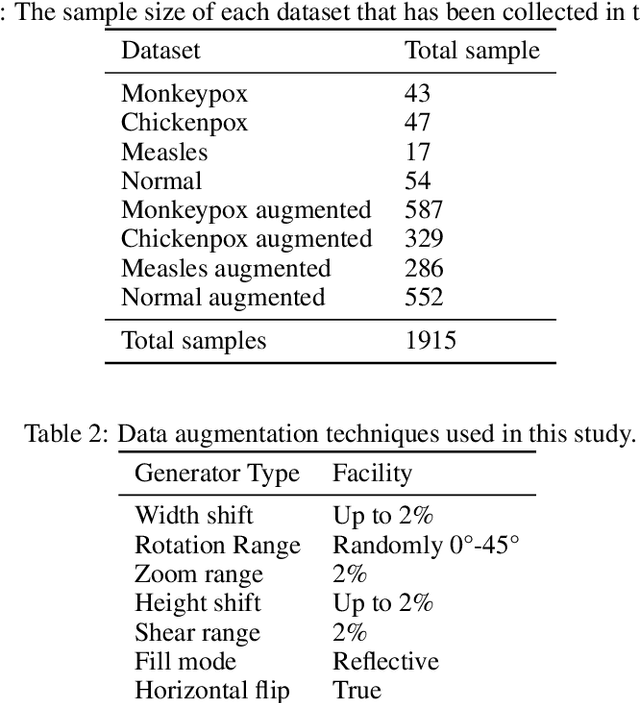
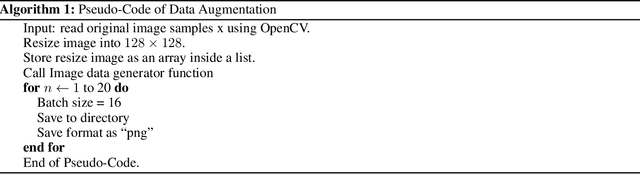
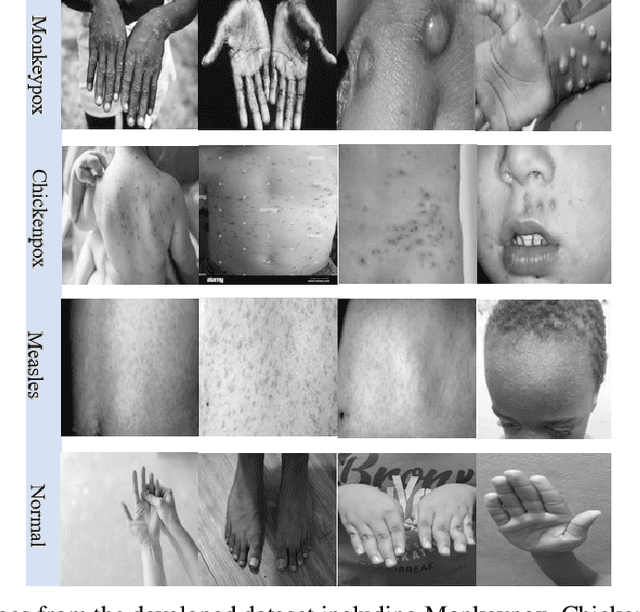
While the world is still attempting to recover from the damage caused by the broad spread of COVID-19, the Monkeypox virus poses a new threat of becoming a global pandemic. Although the Monkeypox virus itself is not deadly and contagious as COVID-19, still every day, new patients case has been reported from many nations. Therefore, it will be no surprise if the world ever faces another global pandemic due to the lack of proper precautious steps. Recently, Machine learning (ML) has demonstrated huge potential in image-based diagnoses such as cancer detection, tumor cell identification, and COVID-19 patient detection. Therefore, a similar application can be adopted to diagnose the Monkeypox-related disease as it infected the human skin, which image can be acquired and further used in diagnosing the disease. Considering this opportunity, in this work, we introduce a newly developed "Monkeypox2022" dataset that is publicly available to use and can be obtained from our shared GitHub repository. The dataset is created by collecting images from multiple open-source and online portals that do not impose any restrictions on use, even for commercial purposes, hence giving a safer path to use and disseminate such data when constructing and deploying any type of ML model. Further, we propose and evaluate a modified VGG16 model, which includes two distinct studies: Study One and Two. Our exploratory computational results indicate that our suggested model can identify Monkeypox patients with an accuracy of $97\pm1.8\%$ (AUC=97.2) and $88\pm0.8\%$ (AUC=0.867) for Study One and Two, respectively. Additionally, we explain our model's prediction and feature extraction utilizing Local Interpretable Model-Agnostic Explanations (LIME) help to a deeper insight into specific features that characterize the onset of the Monkeypox virus.
Accurate Ground-Truth Depth Image Generation via Overfit Training of Point Cloud Registration using Local Frame Sets
Jul 14, 2022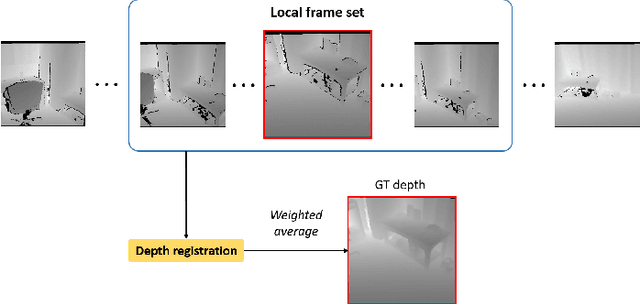
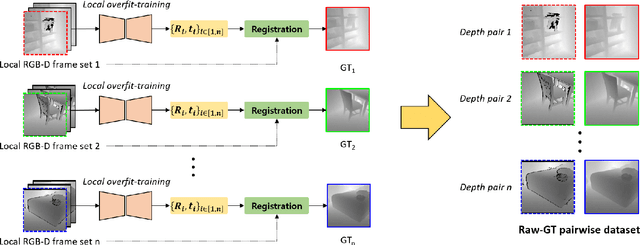


Accurate three-dimensional perception is a fundamental task in several computer vision applications. Recently, commercial RGB-depth (RGB-D) cameras have been widely adopted as single-view depth-sensing devices owing to their efficient depth-sensing abilities. However, the depth quality of most RGB-D sensors remains insufficient owing to the inherent noise from a single-view environment. Recently, several studies have focused on the single-view depth enhancement of RGB-D cameras. Recent research has proposed deep-learning-based approaches that typically train networks using high-quality supervised depth datasets, which indicates that the quality of the ground-truth (GT) depth dataset is a top-most important factor for accurate system; however, such high-quality GT datasets are difficult to obtain. In this study, we developed a novel method for high-quality GT depth generation based on an RGB-D stream dataset. First, we defined consecutive depth frames in a local spatial region as a local frame set. Then, the depth frames were aligned to a certain frame in the local frame set using an unsupervised point cloud registration scheme. The registration parameters were trained based on an overfit-training scheme, which was primarily used to construct a single GT depth image for each frame set. The final GT depth dataset was constructed using several local frame sets, and each local frame set was trained independently. The primary advantage of this study is that a high-quality GT depth dataset can be constructed under various scanning environments using only the RGB-D stream dataset. Moreover, our proposed method can be used as a new benchmark GT dataset for accurate performance evaluations. We evaluated our GT dataset on previously benchmarked GT depth datasets and demonstrated that our method is superior to state-of-the-art depth enhancement frameworks.
RAWtoBit: A Fully End-to-end Camera ISP Network
Aug 16, 2022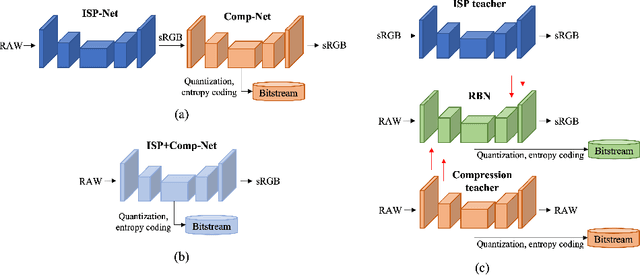
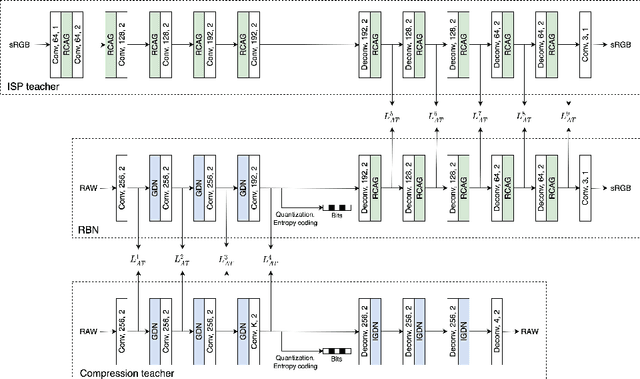
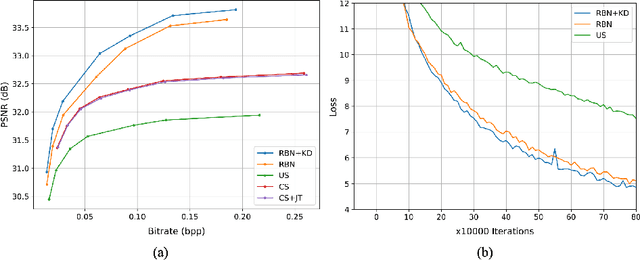

Image compression is an essential and last processing unit in the camera image signal processing (ISP) pipeline. While many studies have been made to replace the conventional ISP pipeline with a single end-to-end optimized deep learning model, image compression is barely considered as a part of the model. In this paper, we investigate the designing of a fully end-to-end optimized camera ISP incorporating image compression. To this end, we propose RAWtoBit network (RBN) that can effectively perform both tasks simultaneously. RBN is further improved with a novel knowledge distillation scheme by introducing two teacher networks specialized in each task. Extensive experiments demonstrate that our proposed method significantly outperforms alternative approaches in terms of rate-distortion trade-off.
OptGAN: Optimizing and Interpreting the Latent Space of the Conditional Text-to-Image GANs
Feb 25, 2022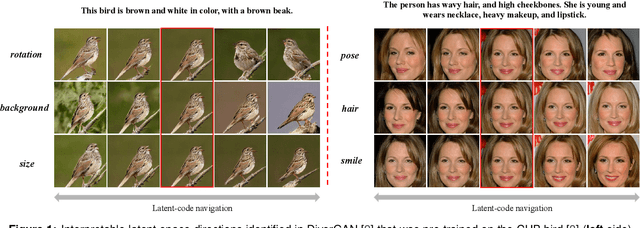

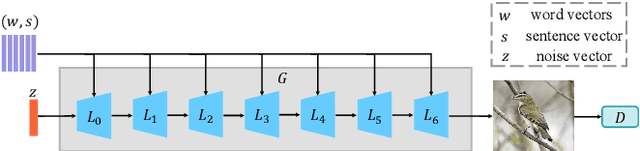
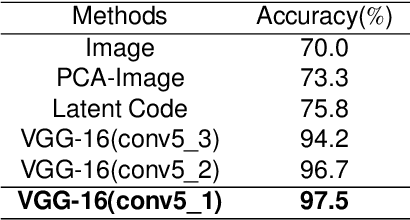
Text-to-image generation intends to automatically produce a photo-realistic image, conditioned on a textual description. It can be potentially employed in the field of art creation, data augmentation, photo-editing, etc. Although many efforts have been dedicated to this task, it remains particularly challenging to generate believable, natural scenes. To facilitate the real-world applications of text-to-image synthesis, we focus on studying the following three issues: 1) How to ensure that generated samples are believable, realistic or natural? 2) How to exploit the latent space of the generator to edit a synthesized image? 3) How to improve the explainability of a text-to-image generation framework? In this work, we constructed two novel data sets (i.e., the Good & Bad bird and face data sets) consisting of successful as well as unsuccessful generated samples, according to strict criteria. To effectively and efficiently acquire high-quality images by increasing the probability of generating Good latent codes, we use a dedicated Good/Bad classifier for generated images. It is based on a pre-trained front end and fine-tuned on the basis of the proposed Good & Bad data set. After that, we present a novel algorithm which identifies semantically-understandable directions in the latent space of a conditional text-to-image GAN architecture by performing independent component analysis on the pre-trained weight values of the generator. Furthermore, we develop a background-flattening loss (BFL), to improve the background appearance in the edited image. Subsequently, we introduce linear interpolation analysis between pairs of keywords. This is extended into a similar triangular `linguistic' interpolation in order to take a deep look into what a text-to-image synthesis model has learned within the linguistic embeddings. Our data set is available at https://zenodo.org/record/6283798#.YhkN_ujMI2w.
Algorithm Development for Controlling Movement of a Robotic Platform by Digital Image Processing
May 23, 2022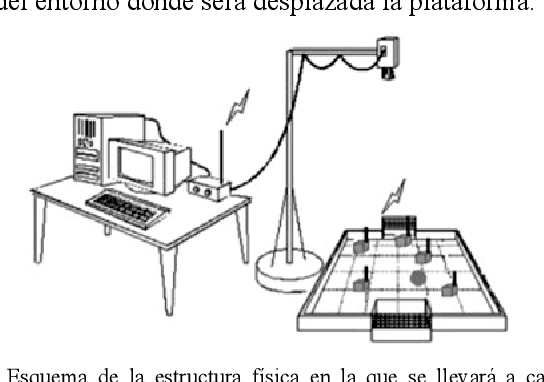

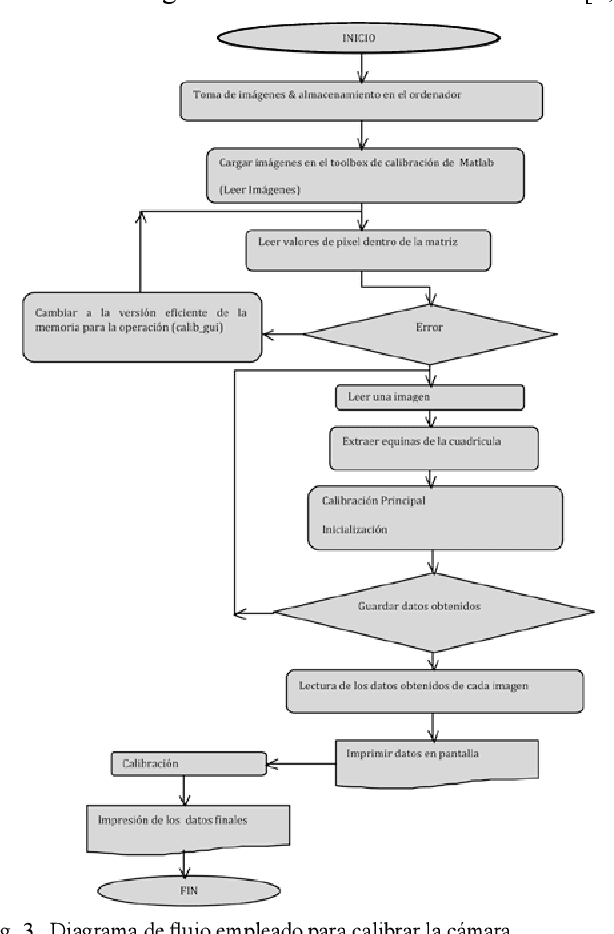
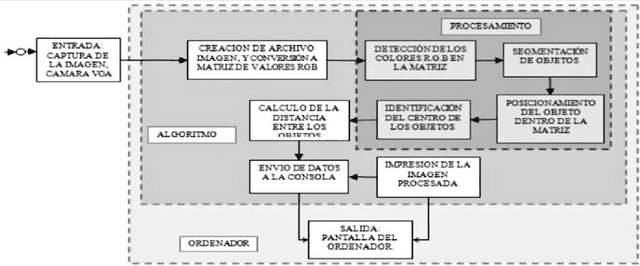
The following work shows an algorithm that can process images digitally with the goal of control the movement of a mobile robotic platform in a certain environment. The platform is identified with a specific color, and displacement environment of the platform shift has identified obstacles with different colors, for both cases it worked with the RGB color scale. To obtain the control's movement of the robotic platform, the algorithm was developed in C programming language, and used the Open CV libraries for processing images captured by a video camera on the Dev-platform C + +. The video camera was previously calibrated using ZHANG technique where parameters were obtained focal length and tilt focal pixel. In the algorithm histogram analysis and segmentation of the image were developed, allowing to determine exactly the relative position of the platform with respect to the obstacles and movement strategy to follow.
* 6 figures,5 pages, in Spanish language
MALUNet: A Multi-Attention and Light-weight UNet for Skin Lesion Segmentation
Nov 03, 2022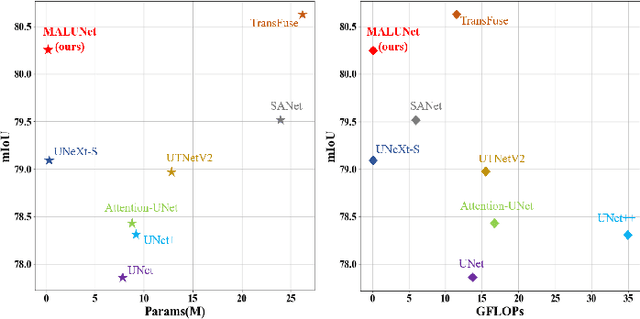
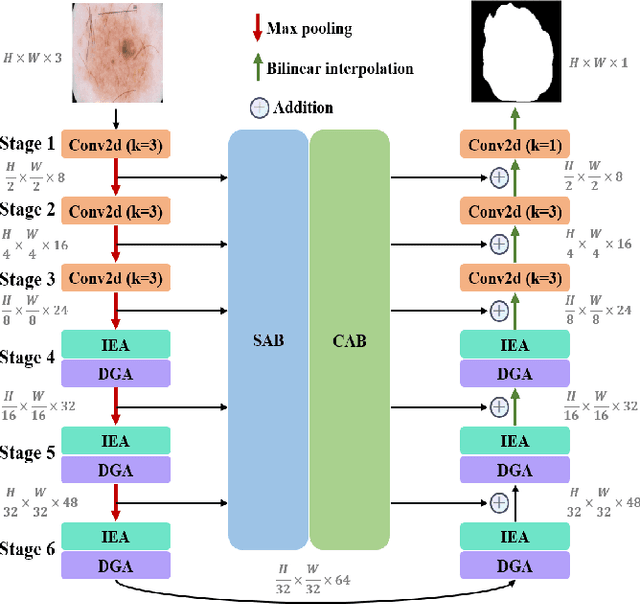
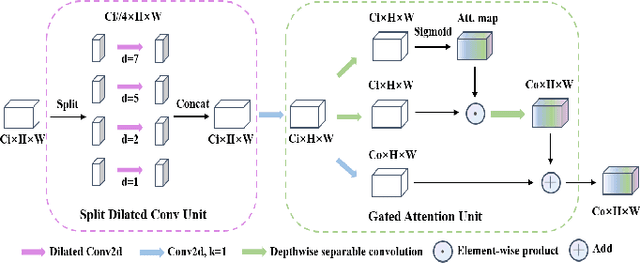
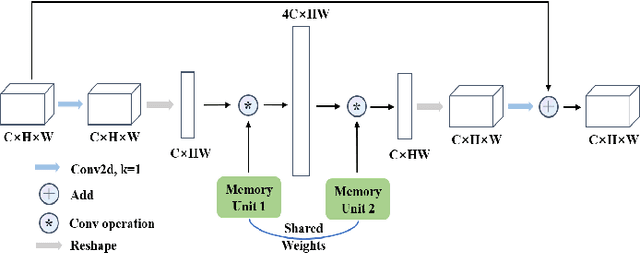
Recently, some pioneering works have preferred applying more complex modules to improve segmentation performances. However, it is not friendly for actual clinical environments due to limited computing resources. To address this challenge, we propose a light-weight model to achieve competitive performances for skin lesion segmentation at the lowest cost of parameters and computational complexity so far. Briefly, we propose four modules: (1) DGA consists of dilated convolution and gated attention mechanisms to extract global and local feature information; (2) IEA, which is based on external attention to characterize the overall datasets and enhance the connection between samples; (3) CAB is composed of 1D convolution and fully connected layers to perform a global and local fusion of multi-stage features to generate attention maps at channel axis; (4) SAB, which operates on multi-stage features by a shared 2D convolution to generate attention maps at spatial axis. We combine four modules with our U-shape architecture and obtain a light-weight medical image segmentation model dubbed as MALUNet. Compared with UNet, our model improves the mIoU and DSC metrics by 2.39% and 1.49%, respectively, with a 44x and 166x reduction in the number of parameters and computational complexity. In addition, we conduct comparison experiments on two skin lesion segmentation datasets (ISIC2017 and ISIC2018). Experimental results show that our model achieves state-of-the-art in balancing the number of parameters, computational complexity and segmentation performances. Code is available at https://github.com/JCruan519/MALUNet.
Surgical Fine-Tuning Improves Adaptation to Distribution Shifts
Oct 20, 2022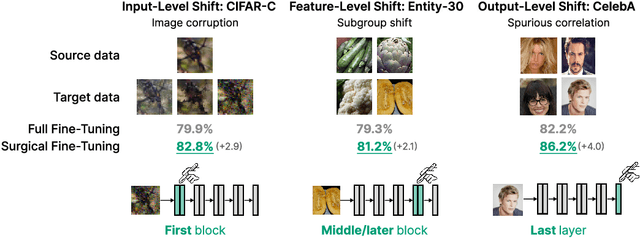
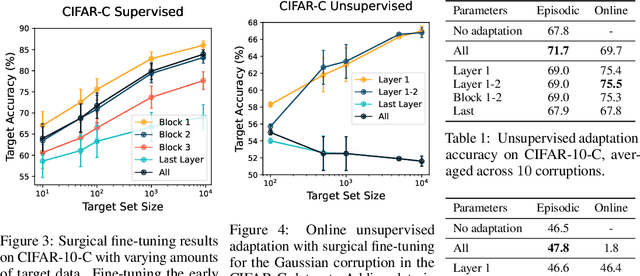
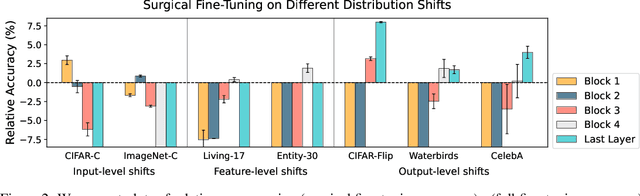
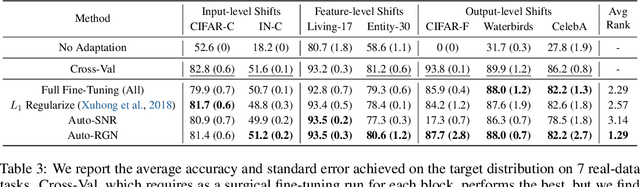
A common approach to transfer learning under distribution shift is to fine-tune the last few layers of a pre-trained model, preserving learned features while also adapting to the new task. This paper shows that in such settings, selectively fine-tuning a subset of layers (which we term surgical fine-tuning) matches or outperforms commonly used fine-tuning approaches. Moreover, the type of distribution shift influences which subset is more effective to tune: for example, for image corruptions, fine-tuning only the first few layers works best. We validate our findings systematically across seven real-world data tasks spanning three types of distribution shifts. Theoretically, we prove that for two-layer neural networks in an idealized setting, first-layer tuning can outperform fine-tuning all layers. Intuitively, fine-tuning more parameters on a small target dataset can cause information learned during pre-training to be forgotten, and the relevant information depends on the type of shift.
Single-pixel tracking and imaging of a high-speed moving object
Sep 04, 2022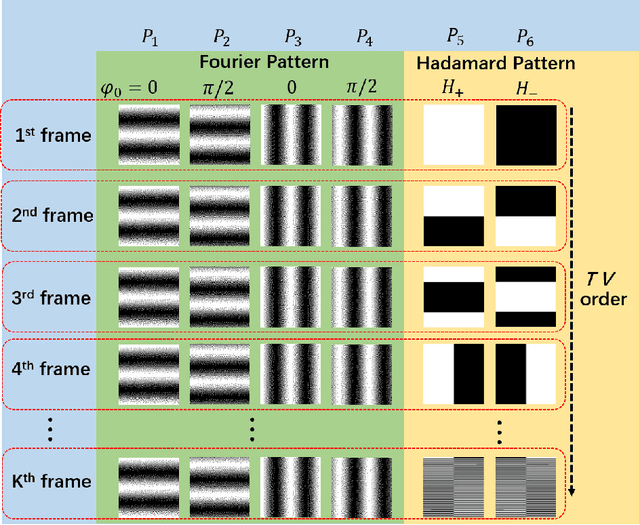
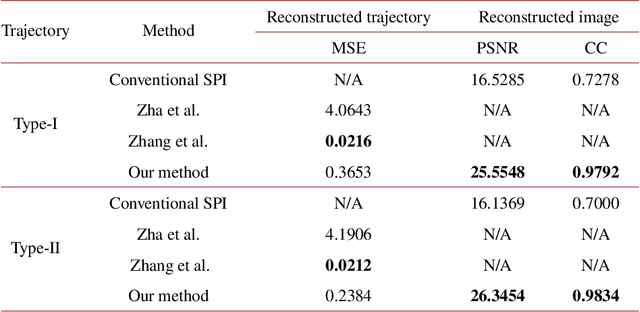
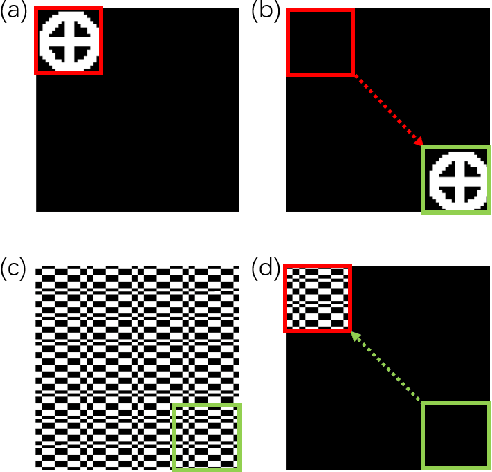
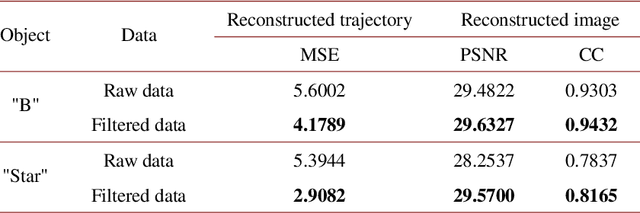
Image-free tracking methods based on single-pixel detection have been able to track a moving object at a very high frame rate, but these tracking methods can not achieve simultaneous imaging of the object. Here we report a method for simultaneously tracking and imaging a high-speed moving object. Four binary Fourier patterns and two differential Hadamard patterns are used to modulate one frame of the object, then the modulated light signals are obtained by single-pixel detection. The trajectory and the image of the moving object can be gradually obtained along with the detection. The proposed method does not need any prior knowledge of the object and its motion. It has been verified by simulations and experiments which achieves a frame rate of 3332$~\mathrm{Hz}$ at a spatial resolution of $128 \times 128$ pixels by using a 20000$~\mathrm{Hz}$ digital micromirror device. This proposed method can broaden the application of image-free tracking methods and realize the detection of spatial information of the moving object.
Unaligned Image-to-Image Translation by Learning to Reweight
Sep 24, 2021
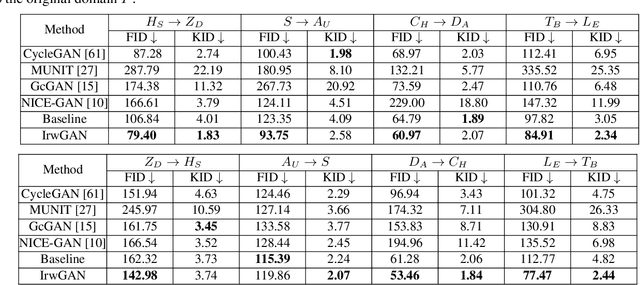
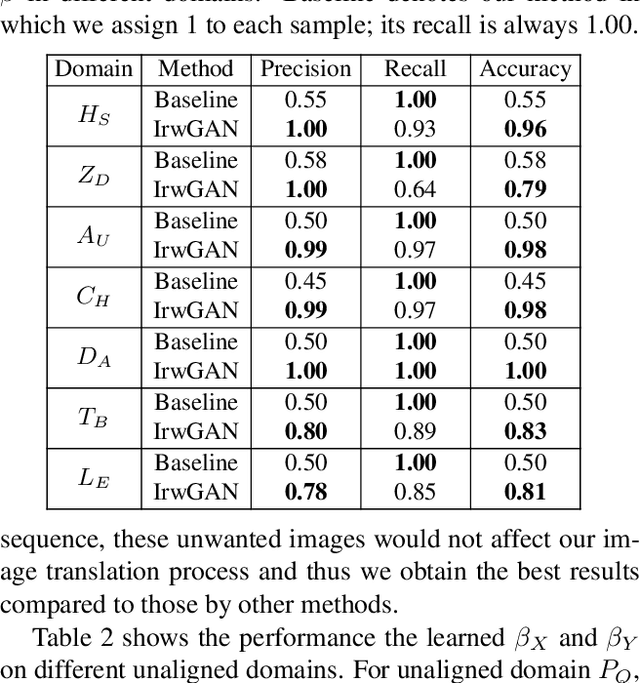
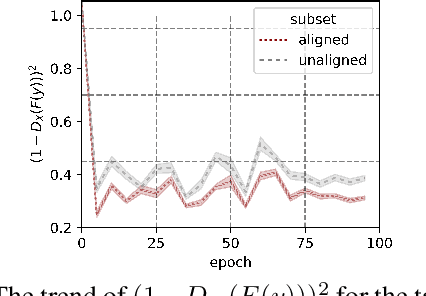
Unsupervised image-to-image translation aims at learning the mapping from the source to target domain without using paired images for training. An essential yet restrictive assumption for unsupervised image translation is that the two domains are aligned, e.g., for the selfie2anime task, the anime (selfie) domain must contain only anime (selfie) face images that can be translated to some images in the other domain. Collecting aligned domains can be laborious and needs lots of attention. In this paper, we consider the task of image translation between two unaligned domains, which may arise for various possible reasons. To solve this problem, we propose to select images based on importance reweighting and develop a method to learn the weights and perform translation simultaneously and automatically. We compare the proposed method with state-of-the-art image translation approaches and present qualitative and quantitative results on different tasks with unaligned domains. Extensive empirical evidence demonstrates the usefulness of the proposed problem formulation and the superiority of our method.
PIZZA: A Powerful Image-only Zero-Shot Zero-CAD Approach to 6 DoF Tracking
Sep 15, 2022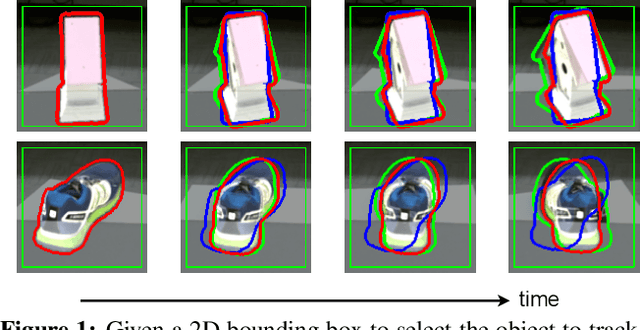
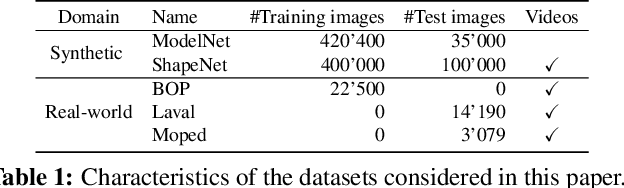
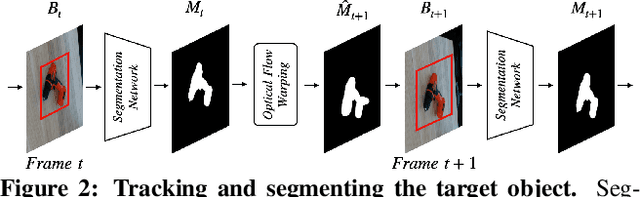
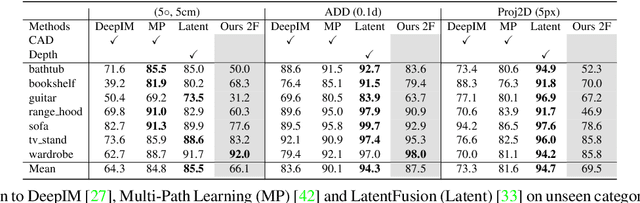
Estimating the relative pose of a new object without prior knowledge is a hard problem, while it is an ability very much needed in robotics and Augmented Reality. We present a method for tracking the 6D motion of objects in RGB video sequences when neither the training images nor the 3D geometry of the objects are available. In contrast to previous works, our method can therefore consider unknown objects in open world instantly, without requiring any prior information or a specific training phase. We consider two architectures, one based on two frames, and the other relying on a Transformer Encoder, which can exploit an arbitrary number of past frames. We train our architectures using only synthetic renderings with domain randomization. Our results on challenging datasets are on par with previous works that require much more information (training images of the target objects, 3D models, and/or depth data). Our source code is available at https://github.com/nv-nguyen/pizza