 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSink-Token-Aware Pruning for Fine-Grained Video Understanding in Efficient Video LLMs
Apr 22, 2026Video Large Language Models (Video LLMs) incur high inference latency due to a large number of visual tokens provided to LLMs. To address this, training-free visual token pruning has emerged as a solution to reduce computational costs; however, existing methods are primarily validated on Multiple-Choice Question Answering (MCQA) benchmarks, where coarse-grained cues often suffice. In this work, we reveal that these methods suffer a sharp performance collapse on fine-grained understanding tasks requiring precise visual grounding, such as hallucination evaluation. To explore this gap, we conduct a systematic analysis and identify sink tokens--semantically uninformative tokens that attract excessive attention--as a key obstacle to fine-grained video understanding. When these sink tokens survive pruning, they distort the model's visual evidence and hinder fine-grained understanding. Motivated by these insights, we propose Sink-Token-aware Pruning (SToP), a simple yet effective plug-and-play method that introduces a sink score to quantify each token's tendency to behave as a sink and applies this score to existing spatial and temporal pruning methods to suppress them, thereby enhancing video understanding. To validate the effectiveness of SToP, we apply it to state-of-the-art pruning methods (VisionZip, FastVid, and Holitom) and evaluate it across diverse benchmarks covering hallucination, open-ended generation, compositional reasoning, and MCQA. Our results demonstrate that SToP significantly boosts performance, even when pruning up to 90% of visual tokens.
Why and When Visual Token Pruning Fails? A Study on Relevant Visual Information Shift in MLLMs Decoding
Apr 14, 2026Recently, visual token pruning has been studied to handle the vast number of visual tokens in Multimodal Large Language Models. However, we observe that while existing pruning methods perform reliably on simple visual understanding, they struggle to effectively generalize to complex visual reasoning tasks, a critical gap underexplored in previous studies. Through a systematic analysis, we identify Relevant Visual Information Shift (RVIS) during decoding as the primary failure driver. To address this, we propose Decoding-stage Shift-aware Token Pruning (DSTP), a training-free add-on framework that enables existing pruning methods to align visual tokens with shifting reasoning requirements during the decoding stage. Extensive experiments demonstrate that DSTP significantly mitigates performance degradation of pruning methods in complex reasoning tasks, while consistently yielding performance gains even across visual understanding benchmarks. Furthermore, DSTP demonstrates effectiveness across diverse state-of-the-art architectures, highlighting its generalizability and efficiency with minimal computational overhead.
Adaptive Graph Rewiring to Mitigate Over-Squashing in Mesh-Based GNNs for Fluid Dynamics Simulations
Nov 16, 2025Mesh-based simulation using Graph Neural Networks (GNNs) has been recognized as a promising approach for modeling fluid dynamics. However, the mesh refinement techniques which allocate finer resolution to regions with steep gradients can induce the over-squashing problem in mesh-based GNNs, which prevents the capture of long-range physical interactions. Conventional graph rewiring methods attempt to alleviate this issue by adding new edges, but they typically complete all rewiring operations before applying them to the GNN. These approaches are physically unrealistic, as they assume instantaneous interactions between distant nodes and disregard the distance information between particles. To address these limitations, we propose a novel framework, called Adaptive Graph Rewiring in Mesh-Based Graph Neural Networks (AdaMeshNet), that introduces an adaptive rewiring process into the message-passing procedure to model the gradual propagation of physical interactions. Our method computes a rewiring delay score for bottleneck nodes in the mesh graph, based on the shortest-path distance and the velocity difference. Using this score, it dynamically selects the message-passing layer at which new edges are rewired, which can lead to adaptive rewiring in a mesh graph. Extensive experiments on mesh-based fluid simulations demonstrate that AdaMeshNet outperforms conventional rewiring methods, effectively modeling the sequential nature of physical interactions and enabling more accurate predictions.
Disentangling and Generating Modalities for Recommendation in Missing Modality Scenarios
Apr 23, 2025Multi-modal recommender systems (MRSs) have achieved notable success in improving personalization by leveraging diverse modalities such as images, text, and audio. However, two key challenges remain insufficiently addressed: (1) Insufficient consideration of missing modality scenarios and (2) the overlooking of unique characteristics of modality features. These challenges result in significant performance degradation in realistic situations where modalities are missing. To address these issues, we propose Disentangling and Generating Modality Recommender (DGMRec), a novel framework tailored for missing modality scenarios. DGMRec disentangles modality features into general and specific modality features from an information-based perspective, enabling richer representations for recommendation. Building on this, it generates missing modality features by integrating aligned features from other modalities and leveraging user modality preferences. Extensive experiments show that DGMRec consistently outperforms state-of-the-art MRSs in challenging scenarios, including missing modalities and new item settings as well as diverse missing ratios and varying levels of missing modalities. Moreover, DGMRec's generation-based approach enables cross-modal retrieval, a task inapplicable for existing MRSs, highlighting its adaptability and potential for real-world applications. Our code is available at https://github.com/ptkjw1997/DGMRec.
Image is All You Need: Towards Efficient and Effective Large Language Model-Based Recommender Systems
Mar 08, 2025Large Language Models (LLMs) have recently emerged as a powerful backbone for recommender systems. Existing LLM-based recommender systems take two different approaches for representing items in natural language, i.e., Attribute-based Representation and Description-based Representation. In this work, we aim to address the trade-off between efficiency and effectiveness that these two approaches encounter, when representing items consumed by users. Based on our interesting observation that there is a significant information overlap between images and descriptions associated with items, we propose a novel method, Image is all you need for LLM-based Recommender system (I-LLMRec). Our main idea is to leverage images as an alternative to lengthy textual descriptions for representing items, aiming at reducing token usage while preserving the rich semantic information of item descriptions. Through extensive experiments, we demonstrate that I-LLMRec outperforms existing methods in both efficiency and effectiveness by leveraging images. Moreover, a further appeal of I-LLMRec is its ability to reduce sensitivity to noise in descriptions, leading to more robust recommendations.
Lost in Sequence: Do Large Language Models Understand Sequential Recommendation?
Feb 19, 2025Large Language Models (LLMs) have recently emerged as promising tools for recommendation thanks to their advanced textual understanding ability and context-awareness. Despite the current practice of training and evaluating LLM-based recommendation (LLM4Rec) models under a sequential recommendation scenario, we found that whether these models understand the sequential information inherent in users' item interaction sequences has been largely overlooked. In this paper, we first demonstrate through a series of experiments that existing LLM4Rec models do not fully capture sequential information both during training and inference. Then, we propose a simple yet effective LLM-based sequential recommender, called LLM-SRec, a method that enhances the integration of sequential information into LLMs by distilling the user representations extracted from a pre-trained CF-SRec model into LLMs. Our extensive experiments show that LLM-SRec enhances LLMs' ability to understand users' item interaction sequences, ultimately leading to improved recommendation performance. Furthermore, unlike existing LLM4Rec models that require fine-tuning of LLMs, LLM-SRec achieves state-of-the-art performance by training only a few lightweight MLPs, highlighting its practicality in real-world applications. Our code is available at https://github.com/Sein-Kim/LLM-SRec.
Accurate Ground-Truth Depth Image Generation via Overfit Training of Point Cloud Registration using Local Frame Sets
Jul 14, 2022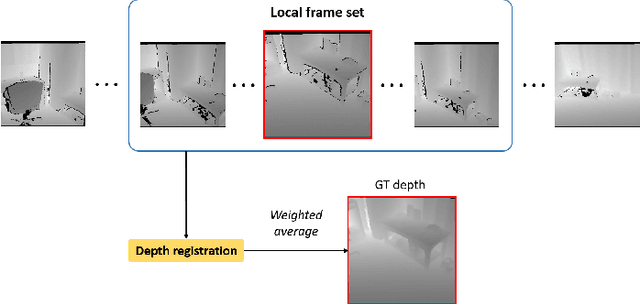
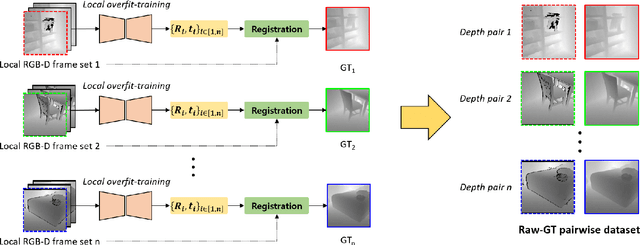


Accurate three-dimensional perception is a fundamental task in several computer vision applications. Recently, commercial RGB-depth (RGB-D) cameras have been widely adopted as single-view depth-sensing devices owing to their efficient depth-sensing abilities. However, the depth quality of most RGB-D sensors remains insufficient owing to the inherent noise from a single-view environment. Recently, several studies have focused on the single-view depth enhancement of RGB-D cameras. Recent research has proposed deep-learning-based approaches that typically train networks using high-quality supervised depth datasets, which indicates that the quality of the ground-truth (GT) depth dataset is a top-most important factor for accurate system; however, such high-quality GT datasets are difficult to obtain. In this study, we developed a novel method for high-quality GT depth generation based on an RGB-D stream dataset. First, we defined consecutive depth frames in a local spatial region as a local frame set. Then, the depth frames were aligned to a certain frame in the local frame set using an unsupervised point cloud registration scheme. The registration parameters were trained based on an overfit-training scheme, which was primarily used to construct a single GT depth image for each frame set. The final GT depth dataset was constructed using several local frame sets, and each local frame set was trained independently. The primary advantage of this study is that a high-quality GT depth dataset can be constructed under various scanning environments using only the RGB-D stream dataset. Moreover, our proposed method can be used as a new benchmark GT dataset for accurate performance evaluations. We evaluated our GT dataset on previously benchmarked GT depth datasets and demonstrated that our method is superior to state-of-the-art depth enhancement frameworks.