 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Deraining: Where Asymmetric Contrastive Learning Meets Self-similarity
Nov 02, 2022

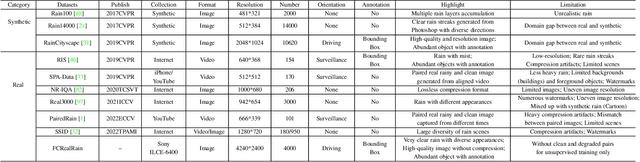

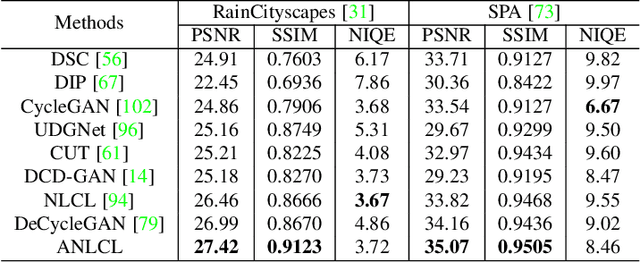
Most of the existing learning-based deraining methods are supervisedly trained on synthetic rainy-clean pairs. The domain gap between the synthetic and real rain makes them less generalized to complex real rainy scenes. Moreover, the existing methods mainly utilize the property of the image or rain layers independently, while few of them have considered their mutually exclusive relationship. To solve above dilemma, we explore the intrinsic intra-similarity within each layer and inter-exclusiveness between two layers and propose an unsupervised non-local contrastive learning (NLCL) deraining method. The non-local self-similarity image patches as the positives are tightly pulled together, rain patches as the negatives are remarkably pushed away, and vice versa. On one hand, the intrinsic self-similarity knowledge within positive/negative samples of each layer benefits us to discover more compact representation; on the other hand, the mutually exclusive property between the two layers enriches the discriminative decomposition. Thus, the internal self-similarity within each layer (similarity) and the external exclusive relationship of the two layers (dissimilarity) serving as a generic image prior jointly facilitate us to unsupervisedly differentiate the rain from clean image. We further discover that the intrinsic dimension of the non-local image patches is generally higher than that of the rain patches. This motivates us to design an asymmetric contrastive loss to precisely model the compactness discrepancy of the two layers for better discriminative decomposition. In addition, considering that the existing real rain datasets are of low quality, either small scale or downloaded from the internet, we collect a real large-scale dataset under various rainy kinds of weather that contains high-resolution rainy images.
MatrixVT: Efficient Multi-Camera to BEV Transformation for 3D Perception
Nov 19, 2022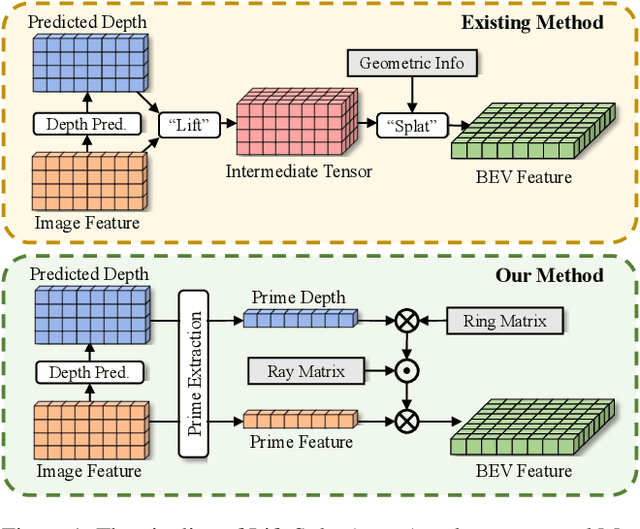
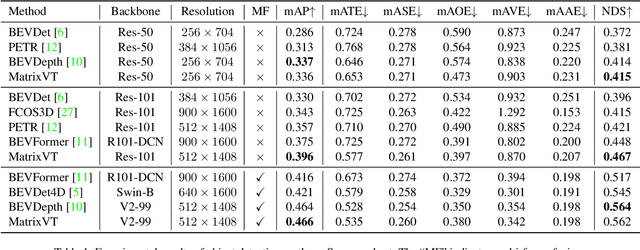
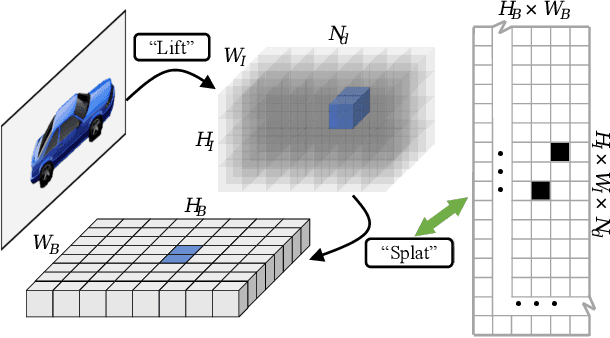
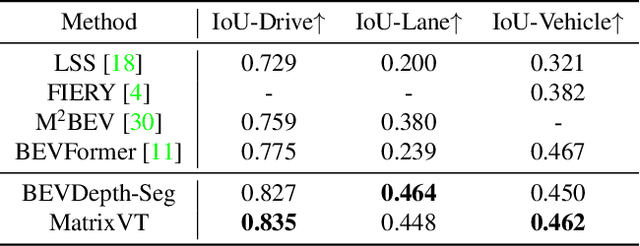
This paper proposes an efficient multi-camera to Bird's-Eye-View (BEV) view transformation method for 3D perception, dubbed MatrixVT. Existing view transformers either suffer from poor transformation efficiency or rely on device-specific operators, hindering the broad application of BEV models. In contrast, our method generates BEV features efficiently with only convolutions and matrix multiplications (MatMul). Specifically, we propose describing the BEV feature as the MatMul of image feature and a sparse Feature Transporting Matrix (FTM). A Prime Extraction module is then introduced to compress the dimension of image features and reduce FTM's sparsity. Moreover, we propose the Ring \& Ray Decomposition to replace the FTM with two matrices and reformulate our pipeline to reduce calculation further. Compared to existing methods, MatrixVT enjoys a faster speed and less memory footprint while remaining deploy-friendly. Extensive experiments on the nuScenes benchmark demonstrate that our method is highly efficient but obtains results on par with the SOTA method in object detection and map segmentation tasks
TORE: Token Reduction for Efficient Human Mesh Recovery with Transformer
Nov 19, 2022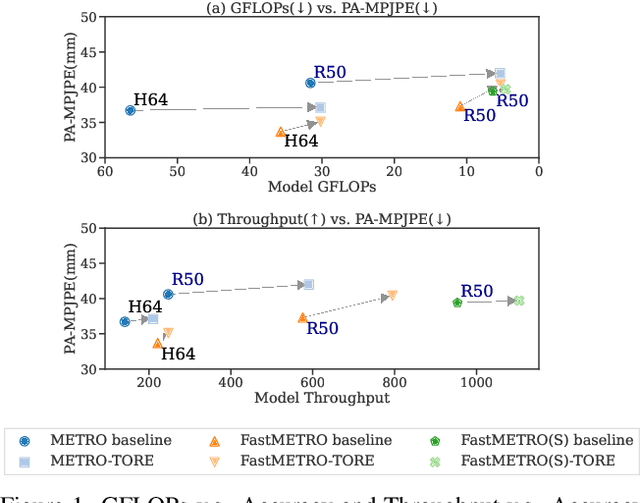
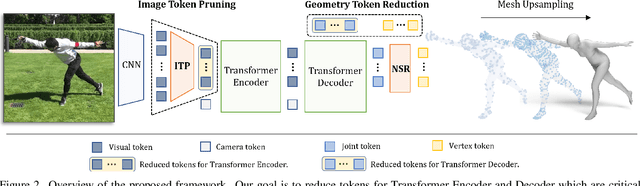
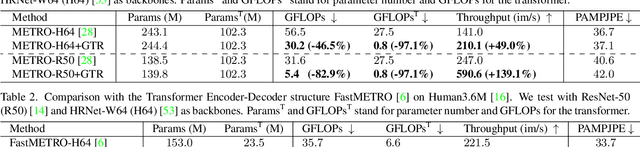
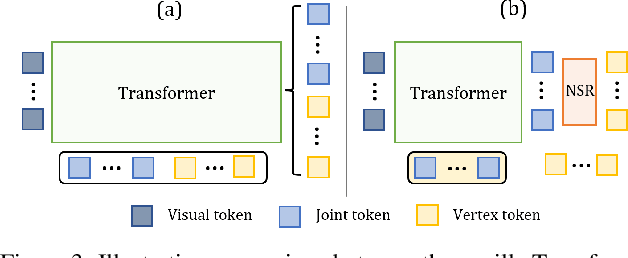
In this paper, we introduce a set of effective TOken REduction (TORE) strategies for Transformer-based Human Mesh Recovery from monocular images. Current SOTA performance is achieved by Transformer-based structures. However, they suffer from high model complexity and computation cost caused by redundant tokens. We propose token reduction strategies based on two important aspects, i.e., the 3D geometry structure and 2D image feature, where we hierarchically recover the mesh geometry with priors from body structure and conduct token clustering to pass fewer but more discriminative image feature tokens to the Transformer. As a result, our method vastly reduces the number of tokens involved in high-complexity interactions in the Transformer, achieving competitive accuracy of shape recovery at a significantly reduced computational cost. We conduct extensive experiments across a wide range of benchmarks to validate the proposed method and further demonstrate the generalizability of our method on hand mesh recovery. Our code will be publicly available once the paper is published.
Long Scale Error Control in Low Light Image and Video Enhancement Using Equivariance
Jun 02, 2022
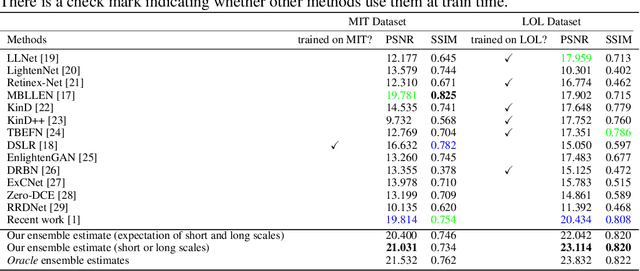


Image frames obtained in darkness are special. Just multiplying by a constant doesn't restore the image. Shot noise, quantization effects and camera non-linearities mean that colors and relative light levels are estimated poorly. Current methods learn a mapping using real dark-bright image pairs. These are very hard to capture. A recent paper has shown that simulated data pairs produce real improvements in restoration, likely because huge volumes of simulated data are easy to obtain. In this paper, we show that respecting equivariance -- the color of a restored pixel should be the same, however the image is cropped -- produces real improvements over the state of the art for restoration. We show that a scale selection mechanism can be used to improve reconstructions. Finally, we show that our approach produces improvements on video restoration as well. Our methods are evaluated both quantitatively and qualitatively.
Elastica Models for Color Image Regularization
Mar 18, 2022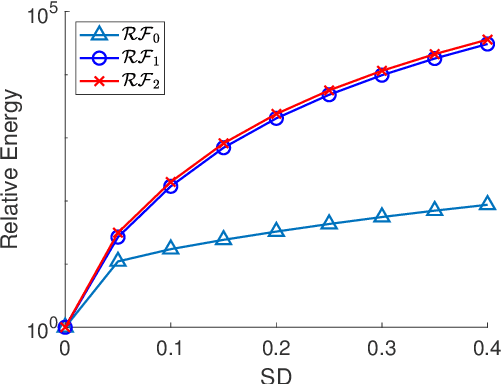
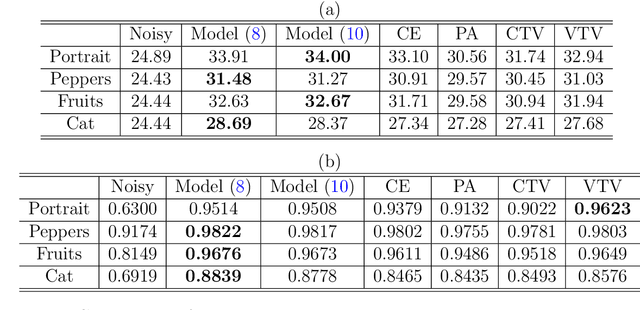

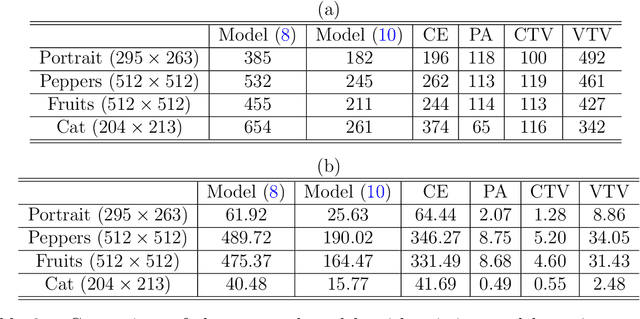
One classical approach to regularize color is to tream them as two dimensional surfaces embedded in a five dimensional spatial-chromatic space. In this case, a natural regularization term arises as the image surface area. Choosing the chromatic coordinates as dominating over the spatial ones, the image spatial coordinates could be thought of as a paramterization of the image surface manifold in a three dimensional color space. Minimizing the area of the image manifold leads to the Beltrami flow or mean curvature flow of the image surface in the 3D color space, while minimizing the elastica of the image surface yields an additional interesting regularization. Recently, the authors proposed a color elastica model, which minimizes both the surface area and elastica of the image manifold. In this paper, we propose to modify the color elastica and introduce two new models for color image regularization. The revised measures are motivated by the relations between the color elastica model, Euler's elastica model and the total variation model for gray level images. Compared to our previous color elastica model, the new models are direct extensions of Euler's elastica model to color images. The proposed models are nonlinear and challenging to minimize. To overcome this difficulty, two operator-splitting methods are suggested. Specifically, nonlinearities are decoupled by introducing new vector- and matrix-valued variables. Then, the minimization problems are converted to solving initial value problems which are time-discretized by operator splitting. Each subproblem, after splitting either, has a closed-form solution or can be solved efficiently. The effectiveness and advantages of the proposed models are demonstrated by comprehensive experiments. The benefits of incorporating the elastica of the image surface as regularization terms compared to common alternatives are empirically validated.
Image Harmonization by Matching Regional References
Apr 10, 2022
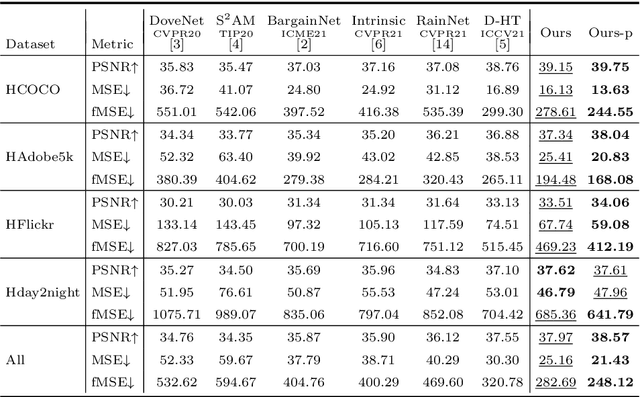
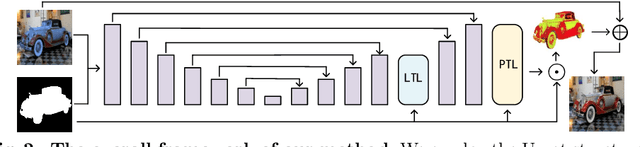
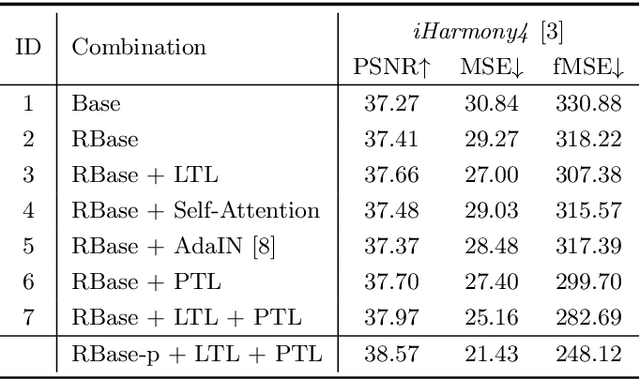
To achieve visual consistency in composite images, recent image harmonization methods typically summarize the appearance pattern of global background and apply it to the global foreground without location discrepancy. However, for a real image, the appearances (illumination, color temperature, saturation, hue, texture, etc) of different regions can vary significantly. So previous methods, which transfer the appearance globally, are not optimal. Trying to solve this issue, we firstly match the contents between the foreground and background and then adaptively adjust every foreground location according to the appearance of its content-related background regions. Further, we design a residual reconstruction strategy, that uses the predicted residual to adjust the appearance, and the composite foreground to reserve the image details. Extensive experiments demonstrate the effectiveness of our method. The source code will be available publicly.
Deep learning applied to computational mechanics: A comprehensive review, state of the art, and the classics
Dec 31, 2022


Three recent breakthroughs due to AI in arts and science serve as motivation: An award winning digital image, protein folding, fast matrix multiplication. Many recent developments in artificial neural networks, particularly deep learning (DL), applied and relevant to computational mechanics (solid, fluids, finite-element technology) are reviewed in detail. Both hybrid and pure machine learning (ML) methods are discussed. Hybrid methods combine traditional PDE discretizations with ML methods either (1) to help model complex nonlinear constitutive relations, (2) to nonlinearly reduce the model order for efficient simulation (turbulence), or (3) to accelerate the simulation by predicting certain components in the traditional integration methods. Here, methods (1) and (2) relied on Long-Short-Term Memory (LSTM) architecture, with method (3) relying on convolutional neural networks.. Pure ML methods to solve (nonlinear) PDEs are represented by Physics-Informed Neural network (PINN) methods, which could be combined with attention mechanism to address discontinuous solutions. Both LSTM and attention architectures, together with modern and generalized classic optimizers to include stochasticity for DL networks, are extensively reviewed. Kernel machines, including Gaussian processes, are provided to sufficient depth for more advanced works such as shallow networks with infinite width. Not only addressing experts, readers are assumed familiar with computational mechanics, but not with DL, whose concepts and applications are built up from the basics, aiming at bringing first-time learners quickly to the forefront of research. History and limitations of AI are recounted and discussed, with particular attention at pointing out misstatements or misconceptions of the classics, even in well-known references. Positioning and pointing control of a large-deformable beam is given as an example.
Efficient Self-supervised Learning with Contextualized Target Representations for Vision, Speech and Language
Dec 14, 2022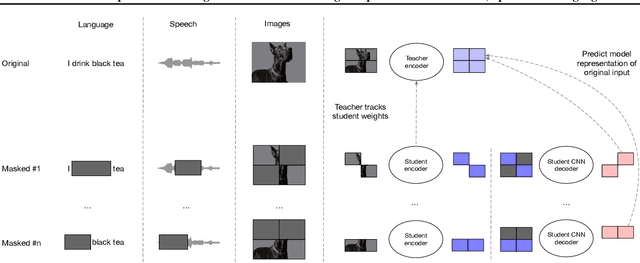
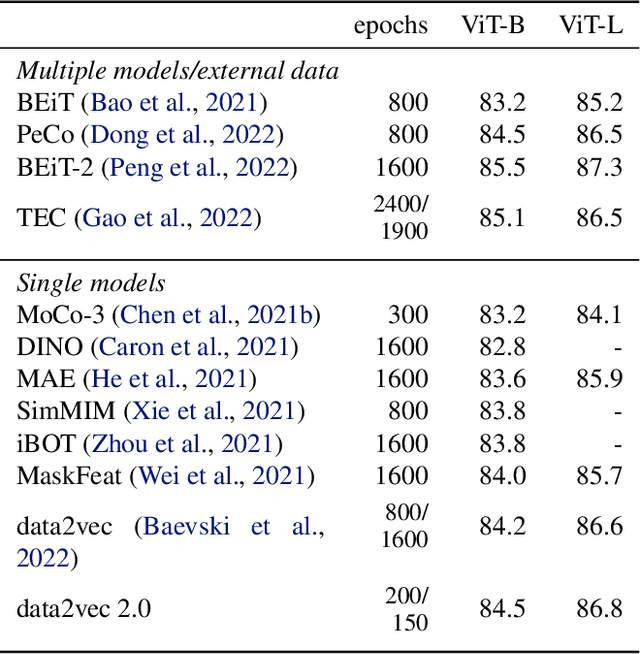
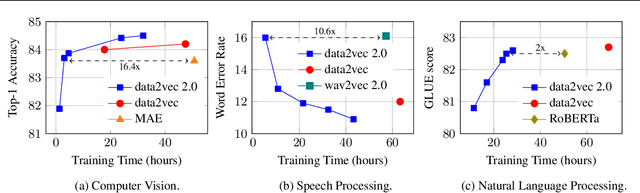

Current self-supervised learning algorithms are often modality-specific and require large amounts of computational resources. To address these issues, we increase the training efficiency of data2vec, a learning objective that generalizes across several modalities. We do not encode masked tokens, use a fast convolutional decoder and amortize the effort to build teacher representations. data2vec 2.0 benefits from the rich contextualized target representations introduced in data2vec which enable a fast self-supervised learner. Experiments on ImageNet-1K image classification show that data2vec 2.0 matches the accuracy of Masked Autoencoders in 16.4x lower pre-training time, on Librispeech speech recognition it performs as well as wav2vec 2.0 in 10.6x less time, and on GLUE natural language understanding it matches a retrained RoBERTa model in half the time. Trading some speed for accuracy results in ImageNet-1K top-1 accuracy of 86.8\% with a ViT-L model trained for 150 epochs.
Disentangled Uncertainty and Out of Distribution Detection in Medical Generative Models
Nov 11, 2022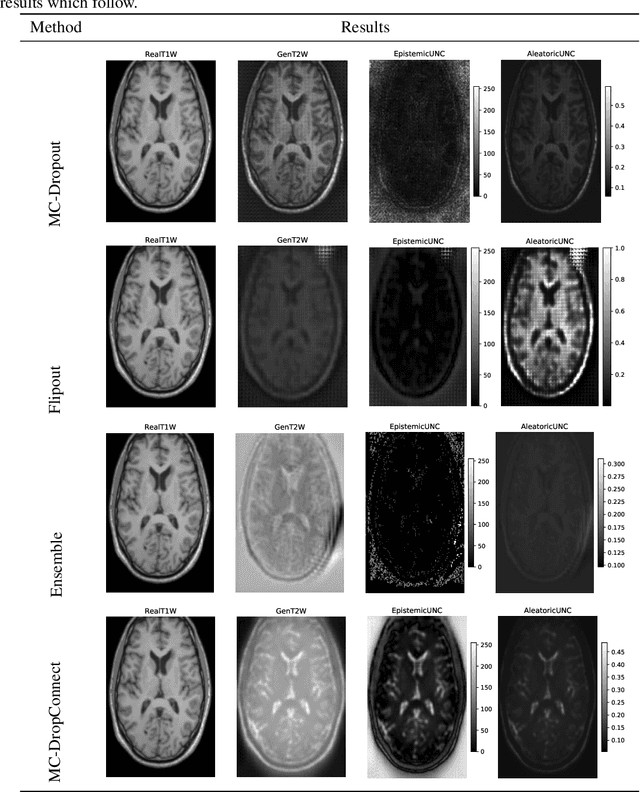
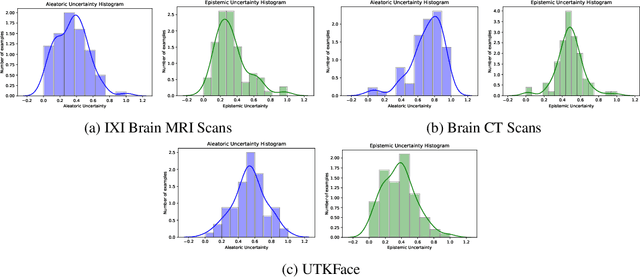
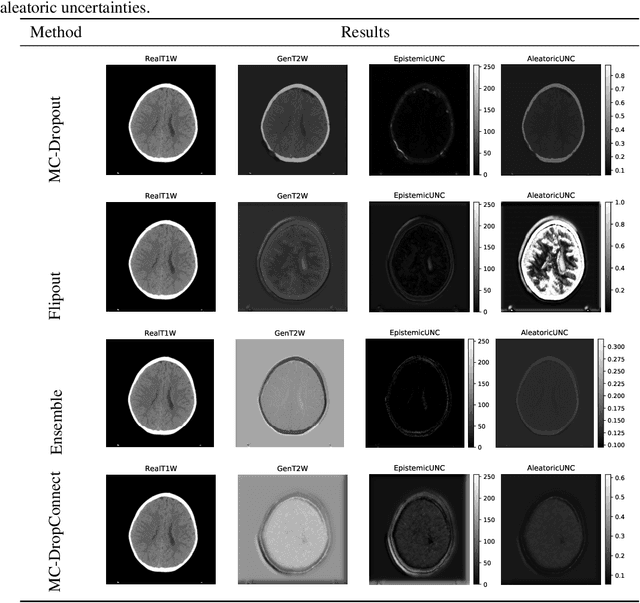
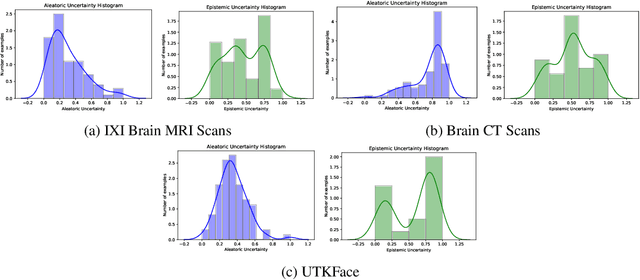
Trusting the predictions of deep learning models in safety critical settings such as the medical domain is still not a viable option. Distentangled uncertainty quantification in the field of medical imaging has received little attention. In this paper, we study disentangled uncertainties in image to image translation tasks in the medical domain. We compare multiple uncertainty quantification methods, namely Ensembles, Flipout, Dropout, and DropConnect, while using CycleGAN to convert T1-weighted brain MRI scans to T2-weighted brain MRI scans. We further evaluate uncertainty behavior in the presence of out of distribution data (Brain CT and RGB Face Images), showing that epistemic uncertainty can be used to detect out of distribution inputs, which should increase reliability of model outputs.
Unsupervised Domain Adaptation Using Feature Disentanglement And GCNs For Medical Image Classification
Jun 27, 2022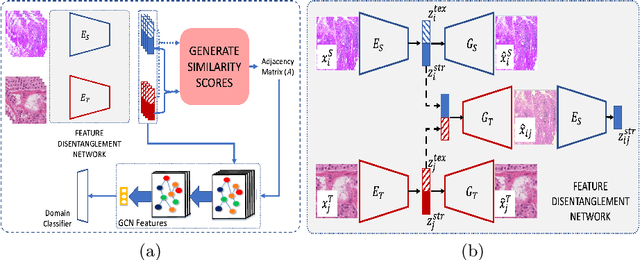
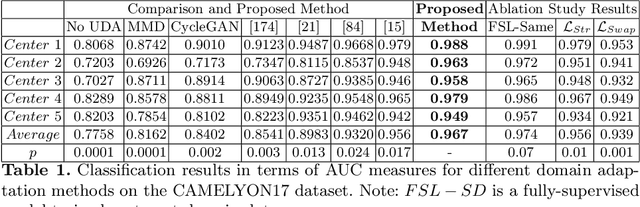
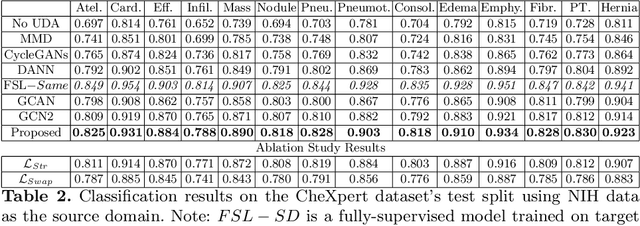
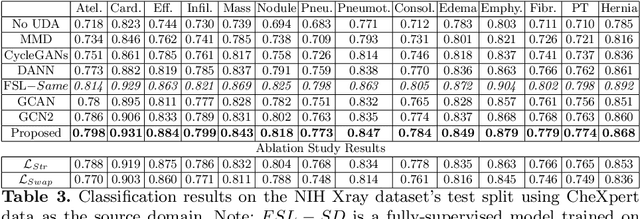
The success of deep learning has set new benchmarks for many medical image analysis tasks. However, deep models often fail to generalize in the presence of distribution shifts between training (source) data and test (target) data. One method commonly employed to counter distribution shifts is domain adaptation: using samples from the target domain to learn to account for shifted distributions. In this work we propose an unsupervised domain adaptation approach that uses graph neural networks and, disentangled semantic and domain invariant structural features, allowing for better performance across distribution shifts. We propose an extension to swapped autoencoders to obtain more discriminative features. We test the proposed method for classification on two challenging medical image datasets with distribution shifts - multi center chest Xray images and histopathology images. Experiments show our method achieves state-of-the-art results compared to other domain adaptation methods.