 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Understanding and Improving the Role of Projection Head in Self-Supervised Learning
Dec 22, 2022
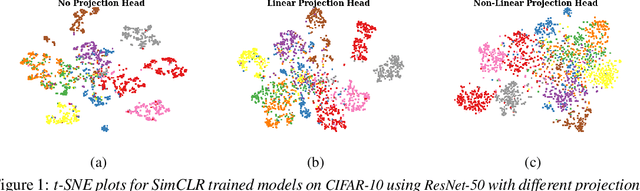
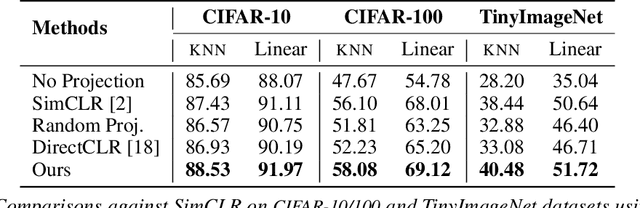
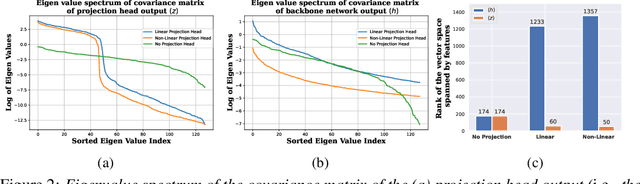
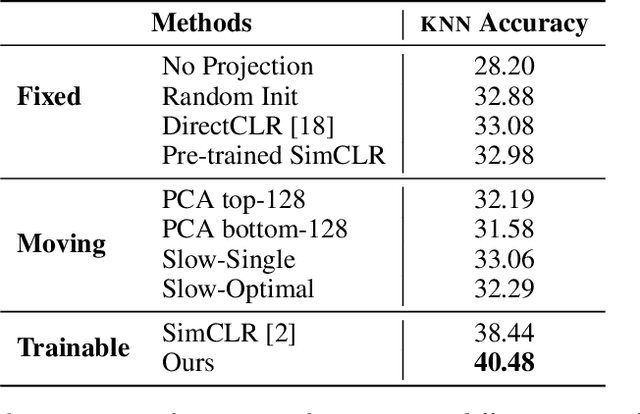
Self-supervised learning (SSL) aims to produce useful feature representations without access to any human-labeled data annotations. Due to the success of recent SSL methods based on contrastive learning, such as SimCLR, this problem has gained popularity. Most current contrastive learning approaches append a parametrized projection head to the end of some backbone network to optimize the InfoNCE objective and then discard the learned projection head after training. This raises a fundamental question: Why is a learnable projection head required if we are to discard it after training? In this work, we first perform a systematic study on the behavior of SSL training focusing on the role of the projection head layers. By formulating the projection head as a parametric component for the InfoNCE objective rather than a part of the network, we present an alternative optimization scheme for training contrastive learning based SSL frameworks. Our experimental study on multiple image classification datasets demonstrates the effectiveness of the proposed approach over alternatives in the SSL literature.
On Calibrating Semantic Segmentation Models: Analysis and An Algorithm
Dec 22, 2022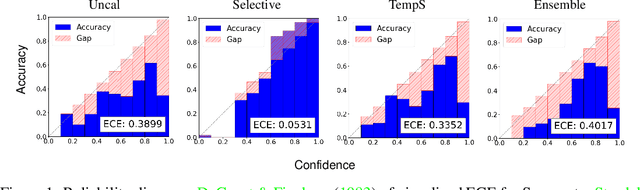
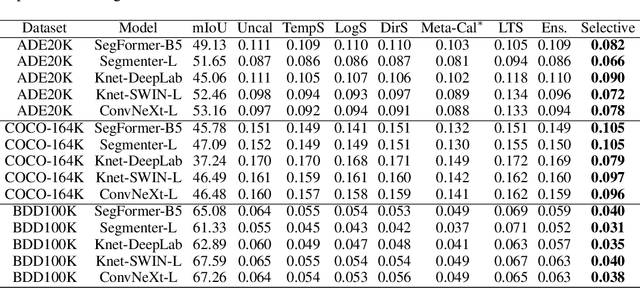
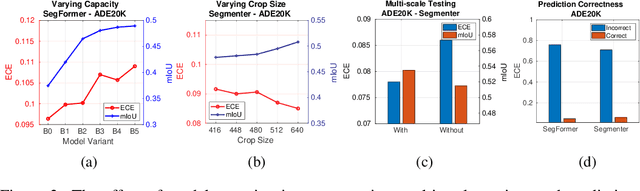
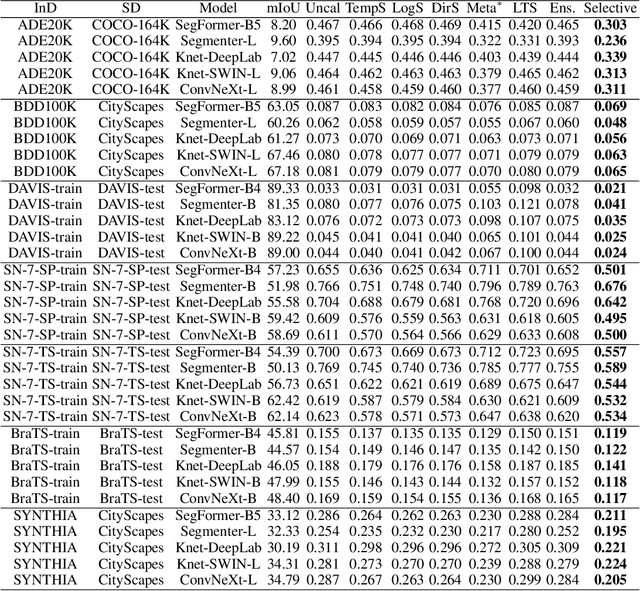
We study the problem of semantic segmentation calibration. For image classification, lots of existing solutions are proposed to alleviate model miscalibration of confidence. However, to date, confidence calibration research on semantic segmentation is still limited. We provide a systematic study on the calibration of semantic segmentation models and propose a simple yet effective approach. First, we find that model capacity, crop size, multi-scale testing, and prediction correctness have impact on calibration. Among them, prediction correctness, especially misprediction, is more important to miscalibration due to over-confidence. Next, we propose a simple, unifying, and effective approach, namely selective scaling, by separating correct/incorrect prediction for scaling and more focusing on misprediction logit smoothing. Then, we study popular existing calibration methods and compare them with selective scaling on semantic segmentation calibration. We conduct extensive experiments with a variety of benchmarks on both in-domain and domain-shift calibration, and show that selective scaling consistently outperforms other methods.
Removing Objects From Neural Radiance Fields
Dec 22, 2022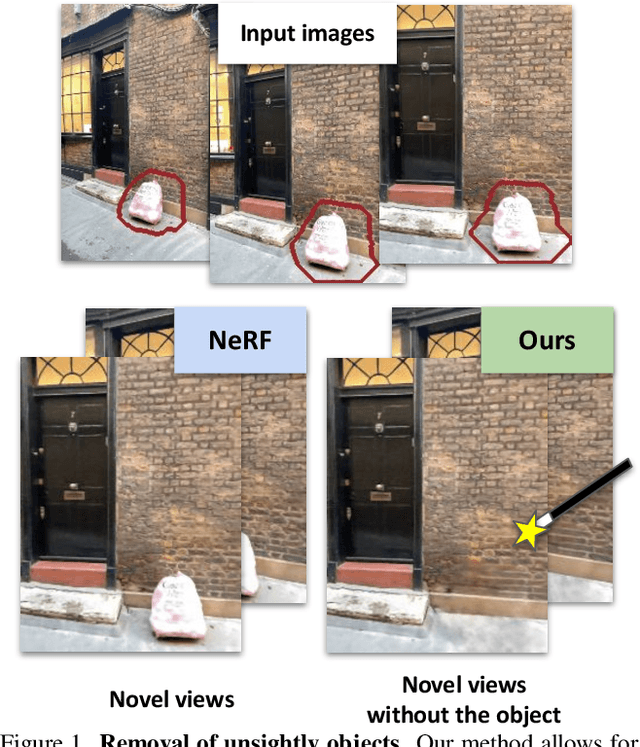
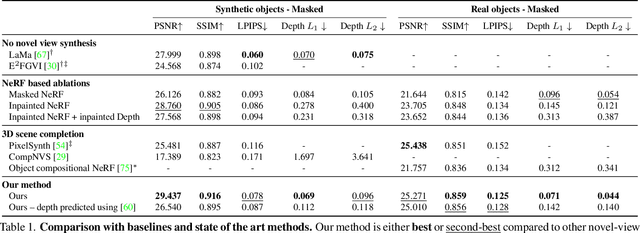

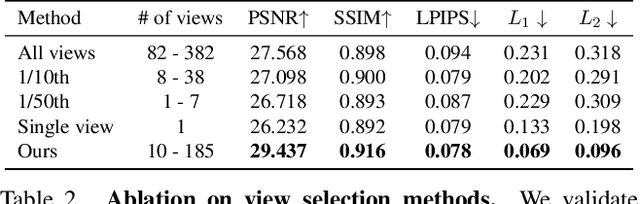
Neural Radiance Fields (NeRFs) are emerging as a ubiquitous scene representation that allows for novel view synthesis. Increasingly, NeRFs will be shareable with other people. Before sharing a NeRF, though, it might be desirable to remove personal information or unsightly objects. Such removal is not easily achieved with the current NeRF editing frameworks. We propose a framework to remove objects from a NeRF representation created from an RGB-D sequence. Our NeRF inpainting method leverages recent work in 2D image inpainting and is guided by a user-provided mask. Our algorithm is underpinned by a confidence based view selection procedure. It chooses which of the individual 2D inpainted images to use in the creation of the NeRF, so that the resulting inpainted NeRF is 3D consistent. We show that our method for NeRF editing is effective for synthesizing plausible inpaintings in a multi-view coherent manner. We validate our approach using a new and still-challenging dataset for the task of NeRF inpainting.
A Critical Appraisal of Data Augmentation Methods for Imaging-Based Medical Diagnosis Applications
Dec 14, 2022
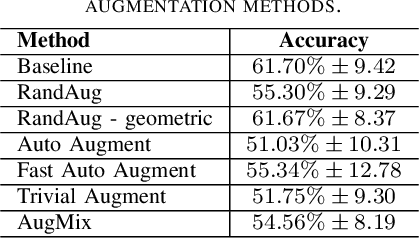
Current data augmentation techniques and transformations are well suited for improving the size and quality of natural image datasets but are not yet optimized for medical imaging. We hypothesize that sub-optimal data augmentations can easily distort or occlude medical images, leading to false positives or negatives during patient diagnosis, prediction, or therapy/surgery evaluation. In our experimental results, we found that utilizing commonly used intensity-based data augmentation distorts the MRI scans and leads to texture information loss, thus negatively affecting the overall performance of classification. Additionally, we observed that commonly used data augmentation methods cannot be used with a plug-and-play approach in medical imaging, and requires manual tuning and adjustment.
Be Careful with Rotation: A Uniform Backdoor Pattern for 3D Shape
Dec 01, 2022
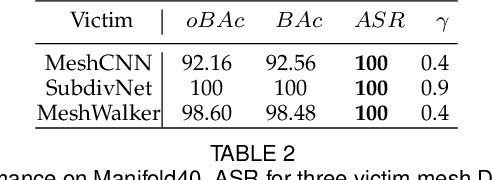
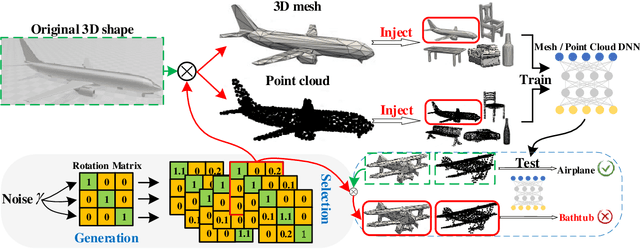
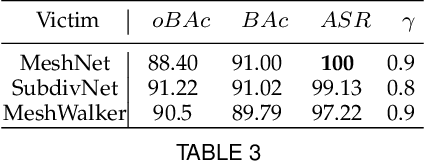
For saving cost, many deep neural networks (DNNs) are trained on third-party datasets downloaded from internet, which enables attacker to implant backdoor into DNNs. In 2D domain, inherent structures of different image formats are similar. Hence, backdoor attack designed for one image format will suite for others. However, when it comes to 3D world, there is a huge disparity among different 3D data structures. As a result, backdoor pattern designed for one certain 3D data structure will be disable for other data structures of the same 3D scene. Therefore, this paper designs a uniform backdoor pattern: NRBdoor (Noisy Rotation Backdoor) which is able to adapt for heterogeneous 3D data structures. Specifically, we start from the unit rotation and then search for the optimal pattern by noise generation and selection process. The proposed NRBdoor is natural and imperceptible, since rotation is a common operation which usually contains noise due to both the miss match between a pair of points and the sensor calibration error for real-world 3D scene. Extensive experiments on 3D mesh and point cloud show that the proposed NRBdoor achieves state-of-the-art performance, with negligible shape variation.
FedMix: Mixed Supervised Federated Learning for Medical Image Segmentation
May 04, 2022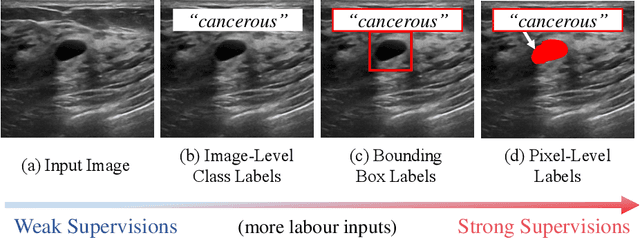
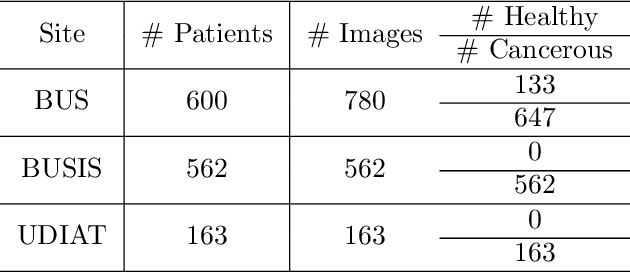
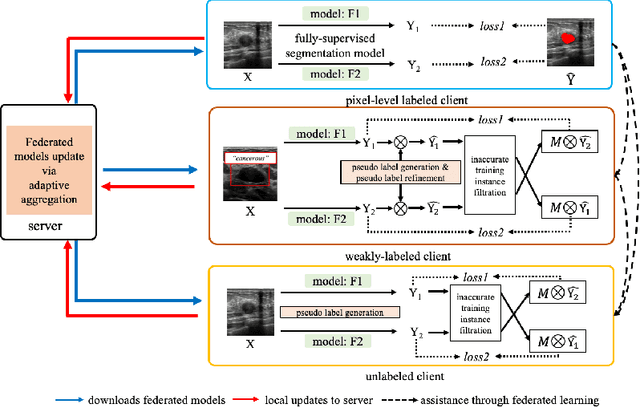
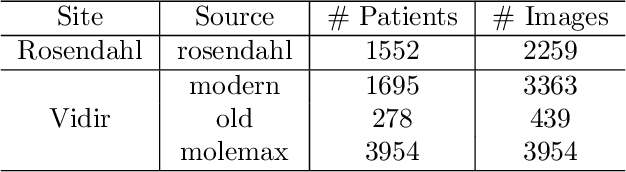
The purpose of federated learning is to enable multiple clients to jointly train a machine learning model without sharing data. However, the existing methods for training an image segmentation model have been based on an unrealistic assumption that the training set for each local client is annotated in a similar fashion and thus follows the same image supervision level. To relax this assumption, in this work, we propose a label-agnostic unified federated learning framework, named FedMix, for medical image segmentation based on mixed image labels. In FedMix, each client updates the federated model by integrating and effectively making use of all available labeled data ranging from strong pixel-level labels, weak bounding box labels, to weakest image-level class labels. Based on these local models, we further propose an adaptive weight assignment procedure across local clients, where each client learns an aggregation weight during the global model update. Compared to the existing methods, FedMix not only breaks through the constraint of a single level of image supervision, but also can dynamically adjust the aggregation weight of each local client, achieving rich yet discriminative feature representations. To evaluate its effectiveness, experiments have been carried out on two challenging medical image segmentation tasks, i.e., breast tumor segmentation and skin lesion segmentation. The results validate that our proposed FedMix outperforms the state-of-the-art method by a large margin.
Curvilinear Aperture Monopulse
Nov 30, 2022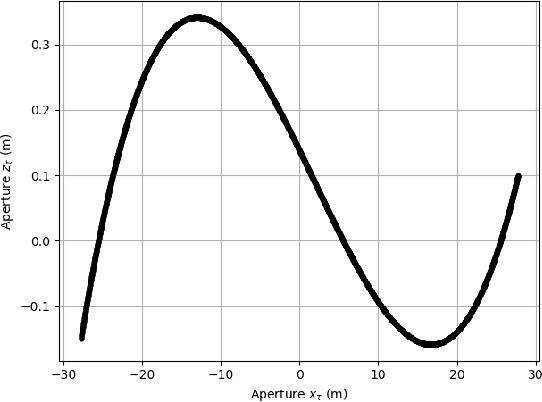
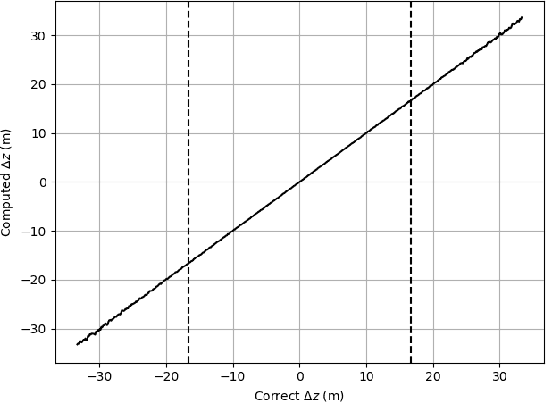
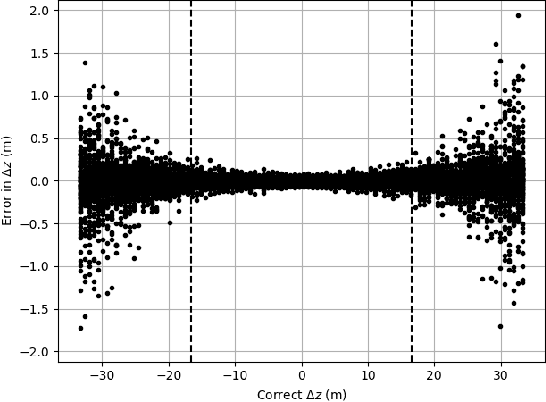
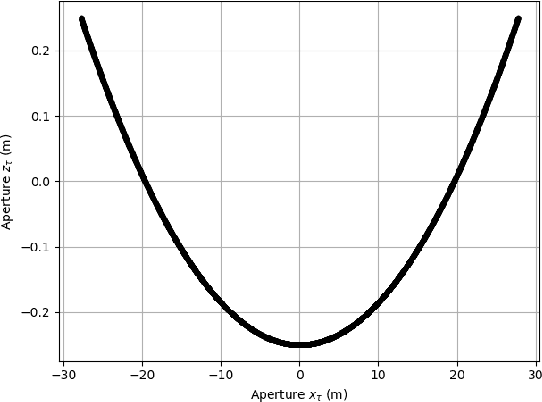
By a symmetry argument, a synethic aperture radar collection along a linear path does not collect three-dimensional information about the scene. However, it is known that vertical curvature can be used to derive some vertical position information. This paper approaches the problem from a monopulse perspective, resulting in a non-iterative computation that commutes with efficient image formation algorithms.
Knowledge-Guided Data-Centric AI in Healthcare: Progress, Shortcomings, and Future Directions
Dec 27, 2022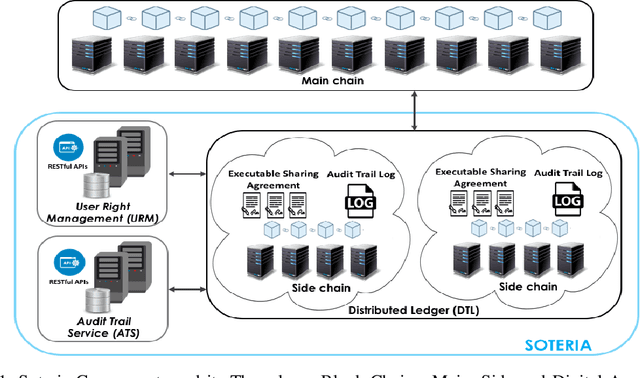



The success of deep learning is largely due to the availability of large amounts of training data that cover a wide range of examples of a particular concept or meaning. In the field of medicine, having a diverse set of training data on a particular disease can lead to the development of a model that is able to accurately predict the disease. However, despite the potential benefits, there have not been significant advances in image-based diagnosis due to a lack of high-quality annotated data. This article highlights the importance of using a data-centric approach to improve the quality of data representations, particularly in cases where the available data is limited. To address this "small-data" issue, we discuss four methods for generating and aggregating training data: data augmentation, transfer learning, federated learning, and GANs (generative adversarial networks). We also propose the use of knowledge-guided GANs to incorporate domain knowledge in the training data generation process. With the recent progress in large pre-trained language models, we believe it is possible to acquire high-quality knowledge that can be used to improve the effectiveness of knowledge-guided generative methods.
Cascade Luminance and Chrominance for Image Retouching: More Like Artist
May 31, 2022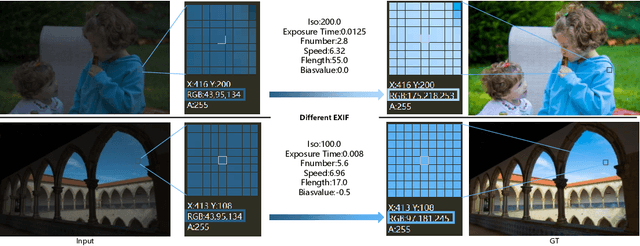

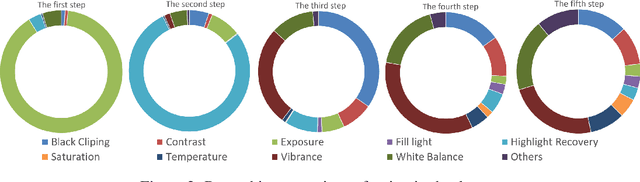
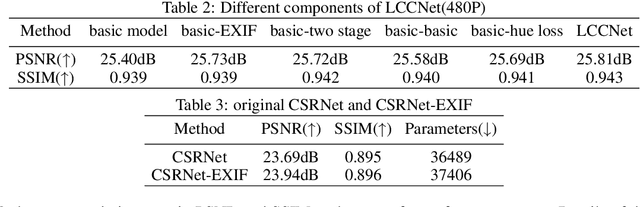
Photo retouching aims to adjust the luminance, contrast, and saturation of the image to make it more human aesthetically desirable. However, artists' actions in photo retouching are difficult to quantitatively analyze. By investigating their retouching behaviors, we propose a two-stage network that brightens images first and then enriches them in the chrominance plane. Six pieces of useful information from image EXIF are picked as the network's condition input. Additionally, hue palette loss is added to make the image more vibrant. Based on the above three aspects, Luminance-Chrominance Cascading Net(LCCNet) makes the machine learning problem of mimicking artists in photo retouching more reasonable. Experiments show that our method is effective on the benchmark MIT-Adobe FiveK dataset, and achieves state-of-the-art performance for both quantitative and qualitative evaluation.
Fast Key Points Detection and Matching for Tree-Structured Images
Nov 07, 2022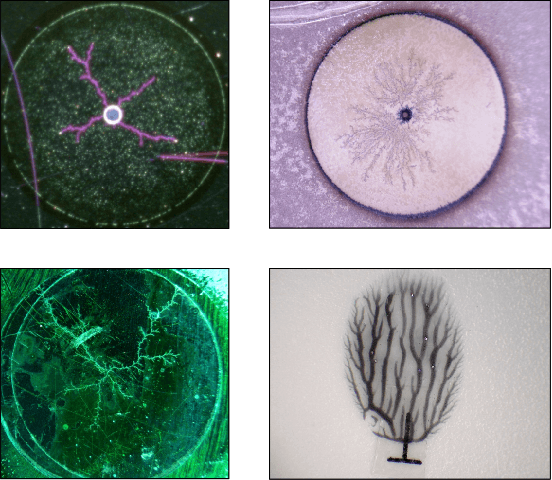
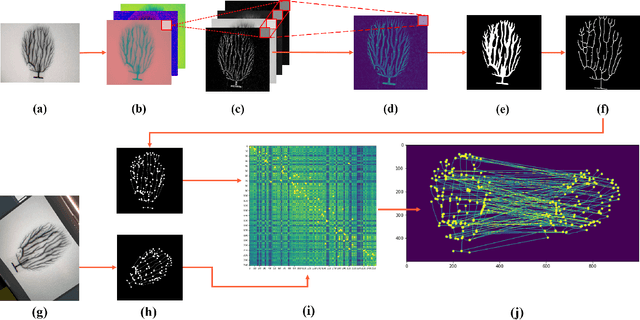

This paper offers a new authentication algorithm based on image matching of nano-resolution visual identifiers with tree-shaped patterns. The algorithm includes image-to-tree conversion by greedy extraction of the fractal pattern skeleton along with a custom-built graph matching algorithm that is robust against imaging artifacts such as scaling, rotation, scratch, and illumination change. The proposed algorithm is applicable to a variety of tree-structured image matching, but our focus is on dendrites, recently-developed visual identifiers. Dendrites are entropy rich and unclonable with existing 2D and 3D printers due to their natural randomness, nano-resolution granularity, and 3D facets, making them an appropriate choice for security applications such as supply chain trace and tracking. The proposed algorithm improves upon graph matching with standard image descriptors. For instance, image inconsistency due to the camera sensor noise may cause unexpected feature extraction leading to inaccurate tree conversion and authentication failure. Also, previous tree extraction algorithms are prohibitively slow hindering their scalability to large systems. In this paper, we fix the current issues of [1] and accelerate the key points extraction up to 10-times faster by implementing a new skeleton extraction method, a new key points searching algorithm, as well as an optimized key point matching algorithm. Using minimum enclosing circle and center points, make the algorithm robust to the choice of pattern shape. In contrast to [1] our algorithm handles general graphs with loop connections, therefore is applicable to a wider range of applications such as transportation map analysis, fingerprints, and retina vessel imaging.