 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Computational Pathology for Brain Disorders
Jan 13, 2023

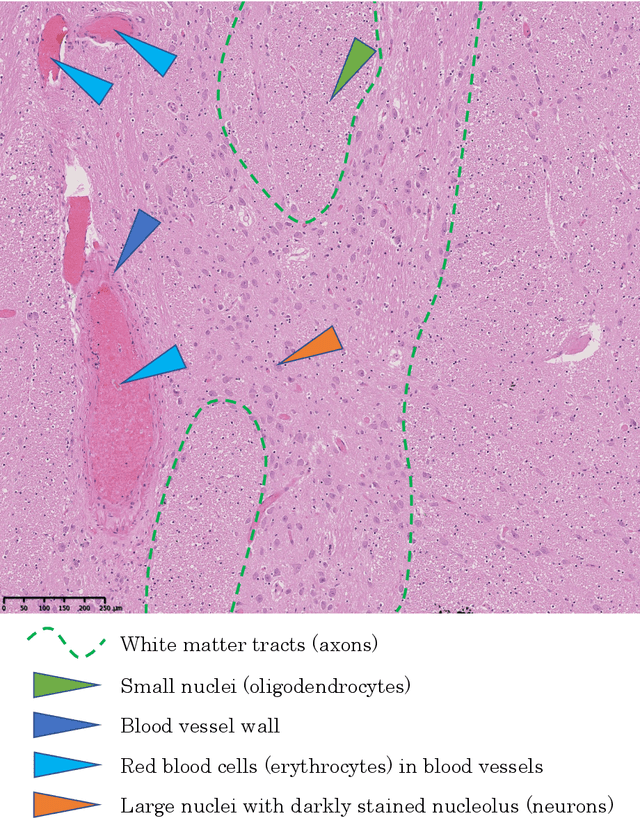
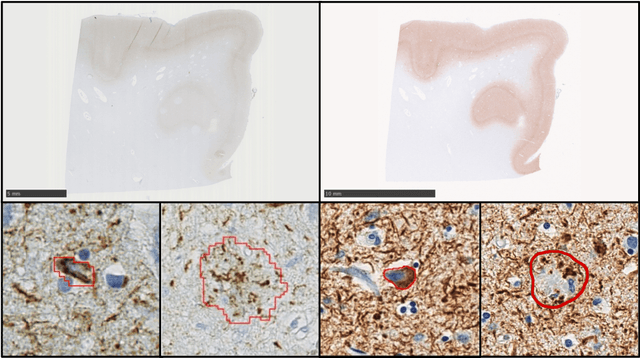
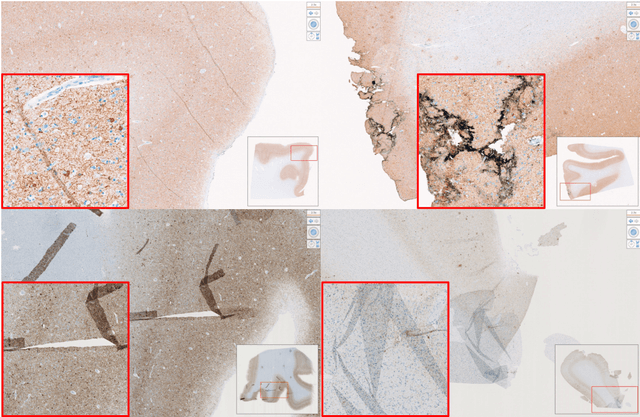
Non-invasive brain imaging techniques allow understanding the behavior and macro changes in the brain to determine the progress of a disease. However, computational pathology provides a deeper understanding of brain disorders at cellular level, able to consolidate a diagnosis and make the bridge between the medical image and the omics analysis. In traditional histopathology, histology slides are visually inspected, under the microscope, by trained pathologists. This process is time-consuming and labor-intensive; therefore, the emergence of Computational Pathology has triggered great hope to ease this tedious task and make it more robust. This chapter focuses on understanding the state-of-the-art machine learning techniques used to analyze whole slide images within the context of brain disorders. We present a selective set of remarkable machine learning algorithms providing discriminative approaches and quality results on brain disorders. These methodologies are applied to different tasks, such as monitoring mechanisms contributing to disease progression and patient survival rates, analyzing morphological phenotypes for classification and quantitative assessment of disease, improving clinical care, diagnosing tumor specimens, and intraoperative interpretation. Thanks to the recent progress in machine learning algorithms for high-content image processing, computational pathology marks the rise of a new generation of medical discoveries and clinical protocols, including in brain disorders.
MetaNO: How to Transfer Your Knowledge on Learning Hidden Physics
Feb 03, 2023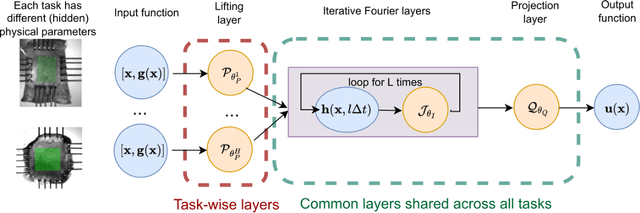
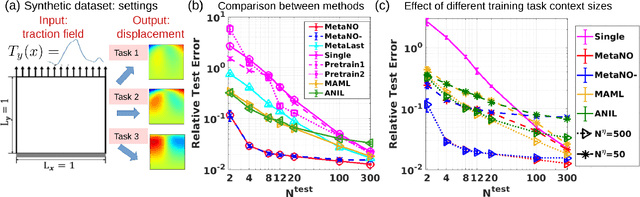
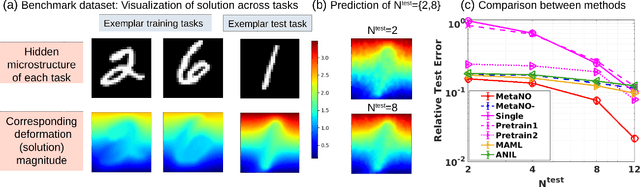
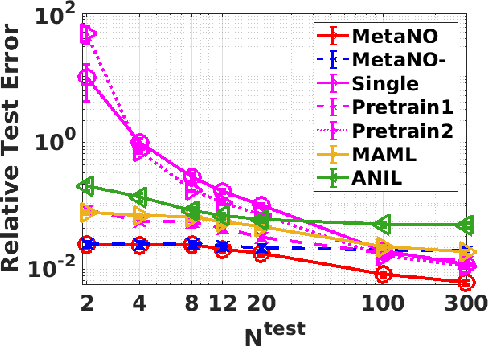
Gradient-based meta-learning methods have primarily been applied to classical machine learning tasks such as image classification. Recently, PDE-solving deep learning methods, such as neural operators, are starting to make an important impact on learning and predicting the response of a complex physical system directly from observational data. Since the data acquisition in this context is commonly challenging and costly, the call of utilization and transfer of existing knowledge to new and unseen physical systems is even more acute. Herein, we propose a novel meta-learning approach for neural operators, which can be seen as transferring the knowledge of solution operators between governing (unknown) PDEs with varying parameter fields. Our approach is a provably universal solution operator for multiple PDE solving tasks, with a key theoretical observation that underlying parameter fields can be captured in the first layer of neural operator models, in contrast to typical final-layer transfer in existing meta-learning methods. As applications, we demonstrate the efficacy of our proposed approach on PDE-based datasets and a real-world material modeling problem, illustrating that our method can handle complex and nonlinear physical response learning tasks while greatly improving the sampling efficiency in unseen tasks.
Supervision Complexity and its Role in Knowledge Distillation
Jan 28, 2023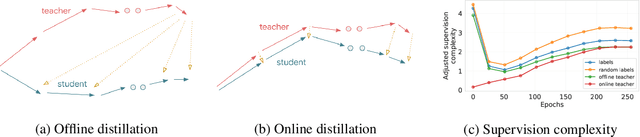


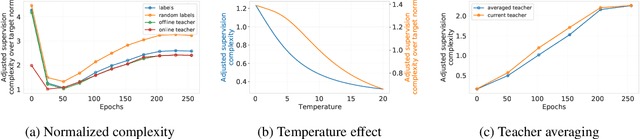
Despite the popularity and efficacy of knowledge distillation, there is limited understanding of why it helps. In order to study the generalization behavior of a distilled student, we propose a new theoretical framework that leverages supervision complexity: a measure of alignment between teacher-provided supervision and the student's neural tangent kernel. The framework highlights a delicate interplay among the teacher's accuracy, the student's margin with respect to the teacher predictions, and the complexity of the teacher predictions. Specifically, it provides a rigorous justification for the utility of various techniques that are prevalent in the context of distillation, such as early stopping and temperature scaling. Our analysis further suggests the use of online distillation, where a student receives increasingly more complex supervision from teachers in different stages of their training. We demonstrate efficacy of online distillation and validate the theoretical findings on a range of image classification benchmarks and model architectures.
RCRN: Real-world Character Image Restoration Network via Skeleton Extraction
Jul 19, 2022
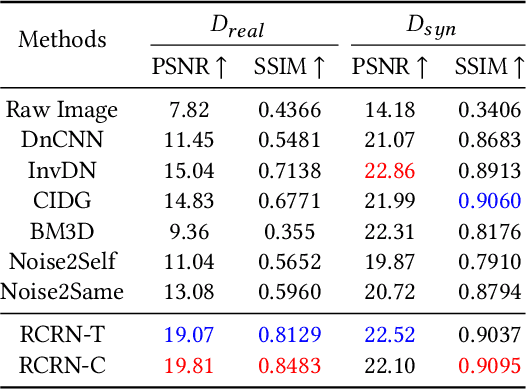

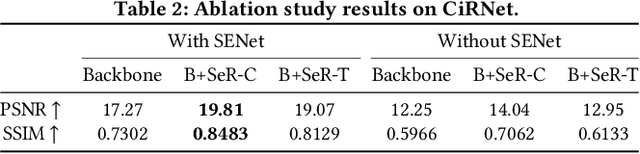
Constructing high-quality character image datasets is challenging because real-world images are often affected by image degradation. There are limitations when applying current image restoration methods to such real-world character images, since (i) the categories of noise in character images are different from those in general images; (ii) real-world character images usually contain more complex image degradation, e.g., mixed noise at different noise levels. To address these problems, we propose a real-world character restoration network (RCRN) to effectively restore degraded character images, where character skeleton information and scale-ensemble feature extraction are utilized to obtain better restoration performance. The proposed method consists of a skeleton extractor (SENet) and a character image restorer (CiRNet). SENet aims to preserve the structural consistency of the character and normalize complex noise. Then, CiRNet reconstructs clean images from degraded character images and their skeletons. Due to the lack of benchmarks for real-world character image restoration, we constructed a dataset containing 1,606 character images with real-world degradation to evaluate the validity of the proposed method. The experimental results demonstrate that RCRN outperforms state-of-the-art methods quantitatively and qualitatively.
Satellite Image Based Cross-view Localization for Autonomous Vehicle
Jul 27, 2022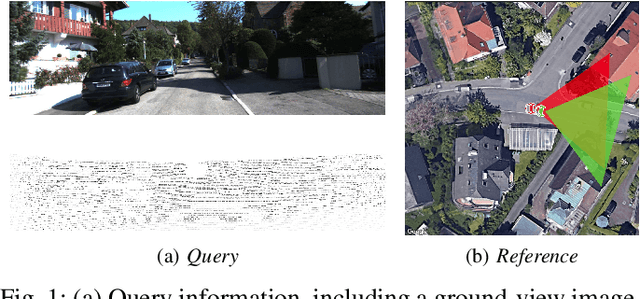
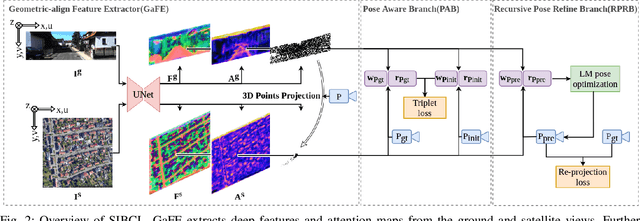


Existing spatial localization techniques for autonomous vehicles mostly use a pre-built 3D-HD map, often constructed using a survey-grade 3D mapping vehicle, which is not only expensive but also laborious. This paper shows that by using an off-the-shelf high-definition satellite image as a ready-to-use map, we are able to achieve cross-view vehicle localization up to a satisfactory accuracy, providing a cheaper and more practical way for localization. Although the idea of using satellite images for cross-view localization is not new, previous methods almost exclusively treat the task as image retrieval, namely matching a vehicle-captured ground-view image with the satellite image. This paper presents a novel cross-view localization method, which departs from the common wisdom of image retrieval. Specifically, our method develops (1) a Geometric-align Feature Extractor (GaFE) that leverages measured 3D points to bridge the geometric gap between ground view and overhead view, (2) a Pose Aware Branch (PAB) adopting a triplet loss to encourage pose-aware feature extracting, and (3) a Recursive Pose Refine Branch (RPRB) using the Levenberg-Marquardt (LM) algorithm to align the initial pose towards the true vehicle pose iteratively. Our method is validated on KITTI and Ford Multi-AV Seasonal datasets as ground view and Google Maps as the satellite view. The results demonstrate the superiority of our method in cross-view localization with spatial and angular errors within 1 meter and $2^\circ$, respectively. The code will be made publicly available.
Granularity-aware Adaptation for Image Retrieval over Multiple Tasks
Oct 05, 2022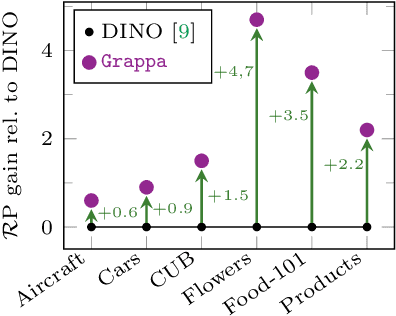
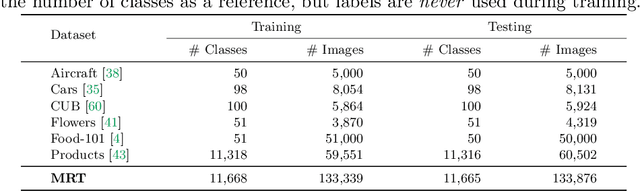
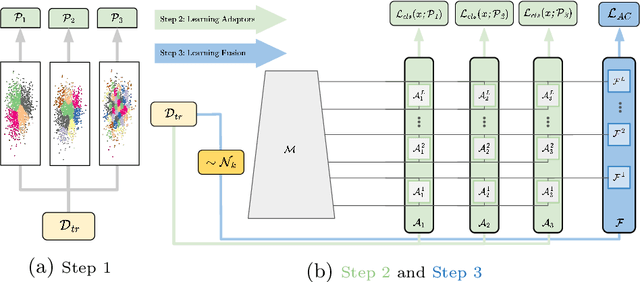
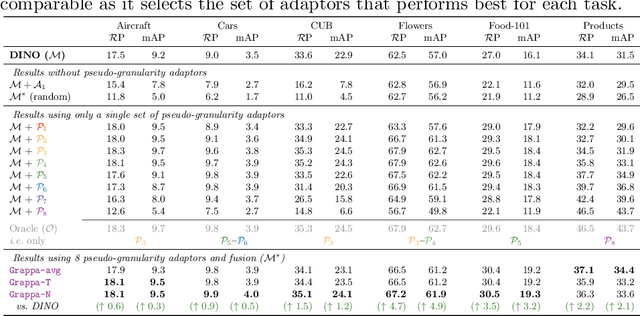
Strong image search models can be learned for a specific domain, ie. set of labels, provided that some labeled images of that domain are available. A practical visual search model, however, should be versatile enough to solve multiple retrieval tasks simultaneously, even if those cover very different specialized domains. Additionally, it should be able to benefit from even unlabeled images from these various retrieval tasks. This is the more practical scenario that we consider in this paper. We address it with the proposed Grappa, an approach that starts from a strong pretrained model, and adapts it to tackle multiple retrieval tasks concurrently, using only unlabeled images from the different task domains. We extend the pretrained model with multiple independently trained sets of adaptors that use pseudo-label sets of different sizes, effectively mimicking different pseudo-granularities. We reconcile all adaptor sets into a single unified model suited for all retrieval tasks by learning fusion layers that we guide by propagating pseudo-granularity attentions across neighbors in the feature space. Results on a benchmark composed of six heterogeneous retrieval tasks show that the unsupervised Grappa model improves the zero-shot performance of a state-of-the-art self-supervised learning model, and in some places reaches or improves over a task label-aware oracle that selects the most fitting pseudo-granularity per task.
3DHumanGAN: Towards Photo-Realistic 3D-Aware Human Image Generation
Dec 14, 2022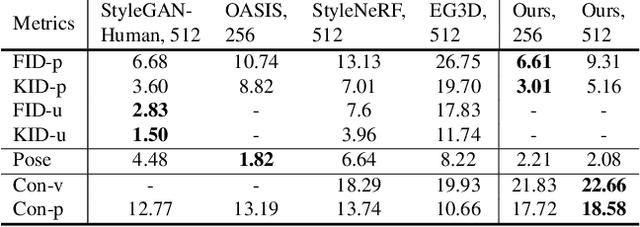
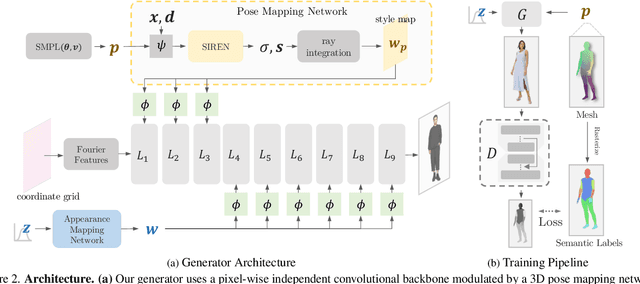
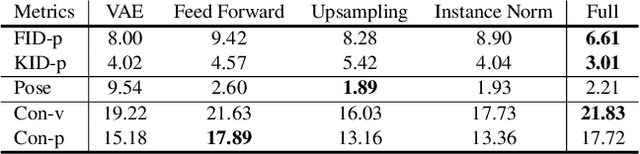

We present 3DHumanGAN, a 3D-aware generative adversarial network (GAN) that synthesizes images of full-body humans with consistent appearances under different view-angles and body-poses. To tackle the representational and computational challenges in synthesizing the articulated structure of human bodies, we propose a novel generator architecture in which a 2D convolutional backbone is modulated by a 3D pose mapping network. The 3D pose mapping network is formulated as a renderable implicit function conditioned on a posed 3D human mesh. This design has several merits: i) it allows us to harness the power of 2D GANs to generate photo-realistic images; ii) it generates consistent images under varying view-angles and specifiable poses; iii) the model can benefit from the 3D human prior. Our model is adversarially learned from a collection of web images needless of manual annotation.
Neural Relation Graph for Identifying Problematic Data
Jan 29, 2023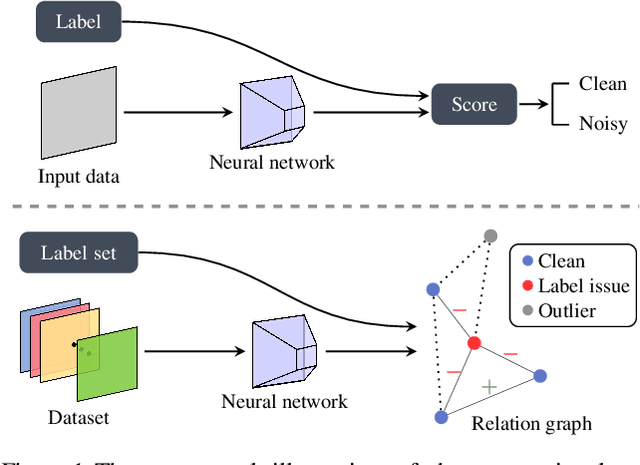

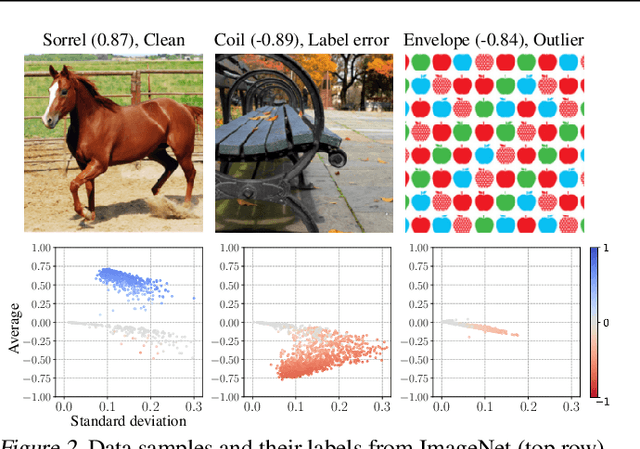
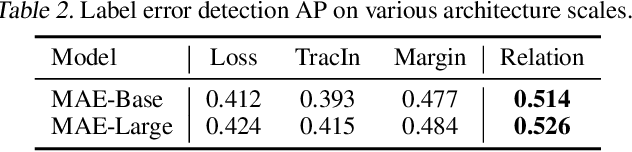
Diagnosing and cleaning datasets are crucial for building robust machine learning systems. However, identifying problems within large-scale datasets with real-world distributions is difficult due to the presence of complex issues, such as label errors or under-representation of certain types. In this paper, we propose a novel approach for identifying problematic data by utilizing a largely ignored source of information: a relational structure of data in the feature-embedded space. We develop an efficient algorithm for detecting label errors and outlier data points based on the relational graph structure of the dataset. We further introduce a visualization tool for contextualizing data points, which can serve as an effective tool for interactively diagnosing datasets. We evaluate label error and out-of-distribution detection performances on large-scale image and language domain tasks, including ImageNet and GLUE benchmarks, and demonstrate the effectiveness of our approach for debugging datasets and building robust machine learning systems.
Global-Local Stepwise Generative Network for Ultra High-Resolution Image Restoration
Jul 16, 2022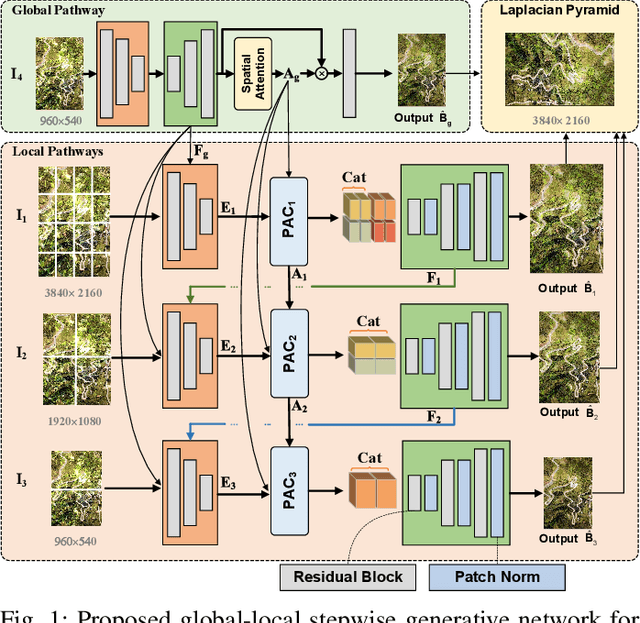



While the research on image background restoration from regular size of degraded images has achieved remarkable progress, restoring ultra high-resolution (e.g., 4K) images remains an extremely challenging task due to the explosion of computational complexity and memory usage, as well as the deficiency of annotated data. In this paper we present a novel model for ultra high-resolution image restoration, referred to as the Global-Local Stepwise Generative Network (GLSGN), which employs a stepwise restoring strategy involving four restoring pathways: three local pathways and one global pathway. The local pathways focus on conducting image restoration in a fine-grained manner over local but high-resolution image patches, while the global pathway performs image restoration coarsely on the scale-down but intact image to provide cues for the local pathways in a global view including semantics and noise patterns. To smooth the mutual collaboration between these four pathways, our GLSGN is designed to ensure the inter-pathway consistency in four aspects in terms of low-level content, perceptual attention, restoring intensity and high-level semantics, respectively. As another major contribution of this work, we also introduce the first ultra high-resolution dataset to date for both reflection removal and rain streak removal, comprising 4,670 real-world and synthetic images. Extensive experiments across three typical tasks for image background restoration, including image reflection removal, image rain streak removal and image dehazing, show that our GLSGN consistently outperforms state-of-the-art methods.
A CT-based deep learning system for automatic assessment of aortic root morphology for TAVI planning
Feb 10, 2023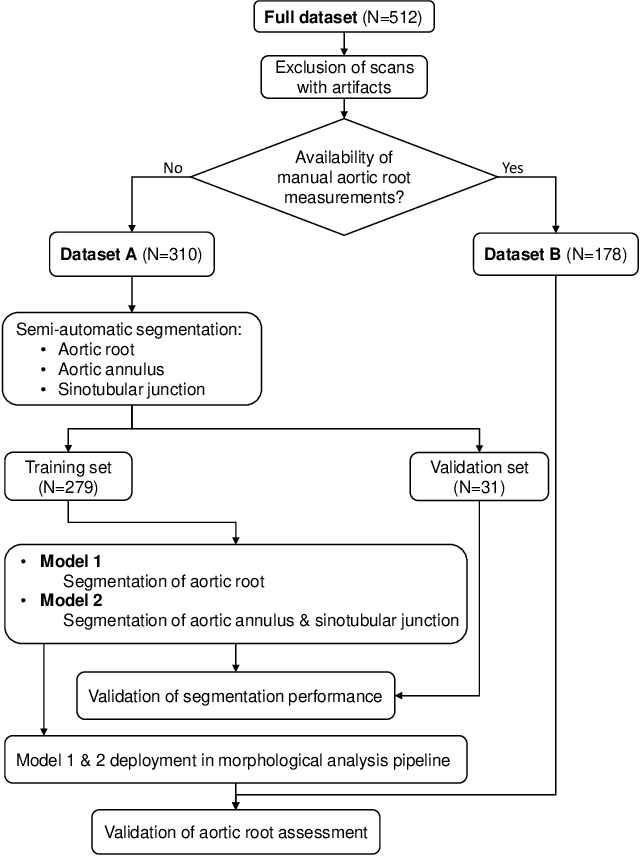
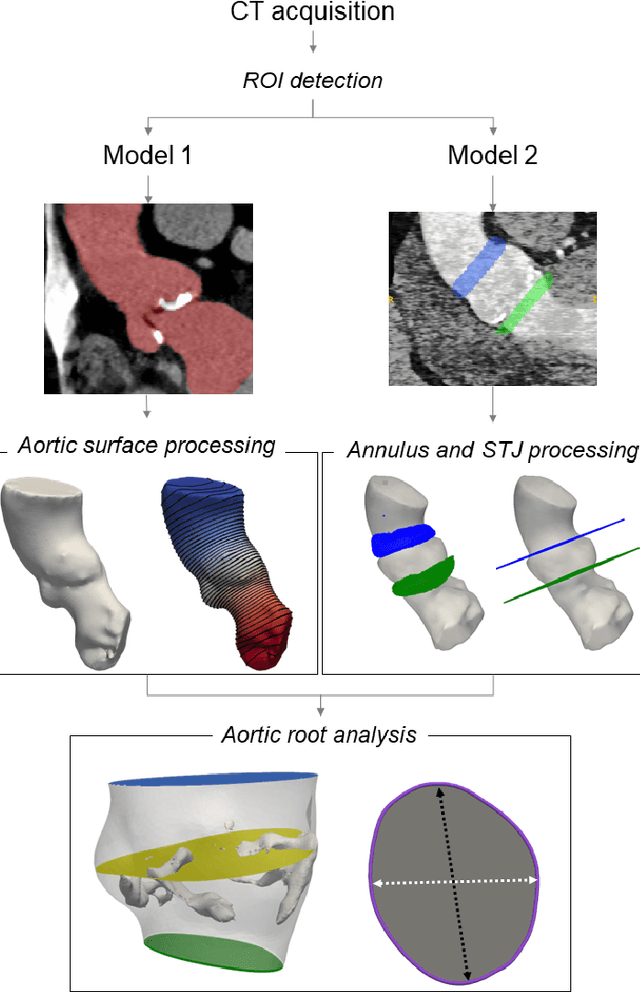
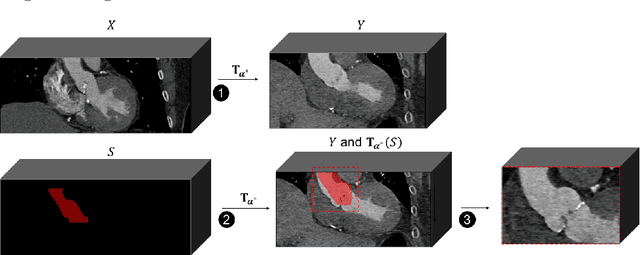
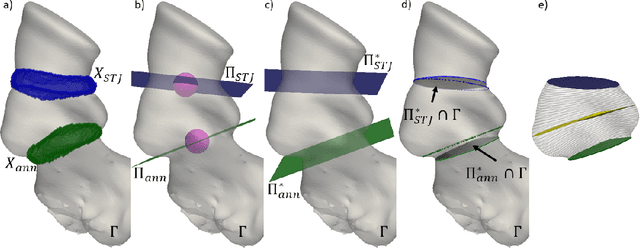
Accurate planning of transcatheter aortic implantation (TAVI) is important to minimize complications, and it requires anatomic evaluation of the aortic root (AR), commonly done through 3D computed tomography (CT) image analysis. Currently, there is no standard automated solution for this process. Two convolutional neural networks (CNNs) with 3D U-Net architectures (model 1 and model 2) were trained on 310 CT scans for AR analysis. Model 1 performed AR segmentation and model 2 identified the aortic annulus and sinotubular junction (STJ) contours. Results were validated against manual measurements of 178 TAVI candidates. After training, the two models were integrated into a fully automated pipeline for geometric analysis of the AR. The trained CNNs effectively segmented the AR, annulus and STJ, resulting in mean Dice scores of 0.93 for the AR, and mean surface distances of 1.16 mm and 1.30 mm for the annulus and STJ, respectively. Automatic measurements were in good agreement with manual annotations, yielding annulus diameters that differed by 0.52 [-2.96, 4.00] mm (bias and 95% limits of agreement for manual minus algorithm). Evaluating the area-derived diameter, bias and limits of agreement were 0.07 [-0.25, 0.39] mm. STJ and sinuses diameters computed by the automatic method yielded differences of 0.16 [-2.03, 2.34] and 0.1 [-2.93, 3.13] mm, respectively. The proposed tool is a fully automatic solution to quantify morphological biomarkers for pre-TAVI planning. The method was validated against manual annotation from clinical experts and showed to be quick and effective in assessing AR anatomy, with potential for time and cost savings.