 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Blowing in the Wind: CycleNet for Human Cinemagraphs from Still Images
Mar 15, 2023
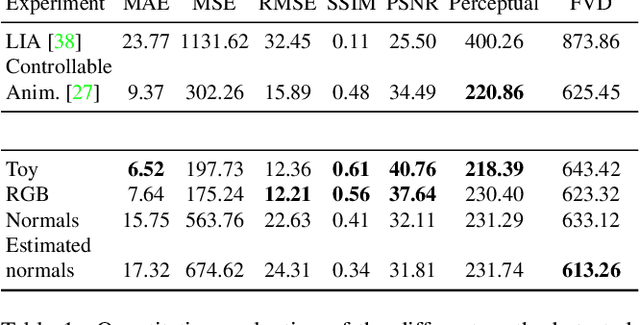
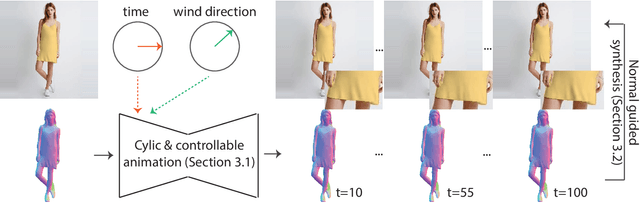
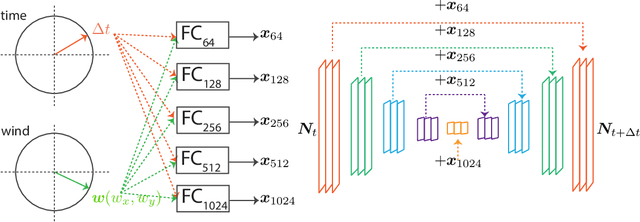

Cinemagraphs are short looping videos created by adding subtle motions to a static image. This kind of media is popular and engaging. However, automatic generation of cinemagraphs is an underexplored area and current solutions require tedious low-level manual authoring by artists. In this paper, we present an automatic method that allows generating human cinemagraphs from single RGB images. We investigate the problem in the context of dressed humans under the wind. At the core of our method is a novel cyclic neural network that produces looping cinemagraphs for the target loop duration. To circumvent the problem of collecting real data, we demonstrate that it is possible, by working in the image normal space, to learn garment motion dynamics on synthetic data and generalize to real data. We evaluate our method on both synthetic and real data and demonstrate that it is possible to create compelling and plausible cinemagraphs from single RGB images.
Diffusion Models Generate Images Like Painters: an Analytical Theory of Outline First, Details Later
Mar 04, 2023

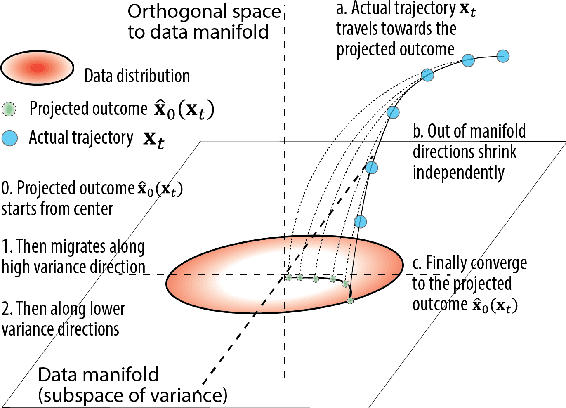
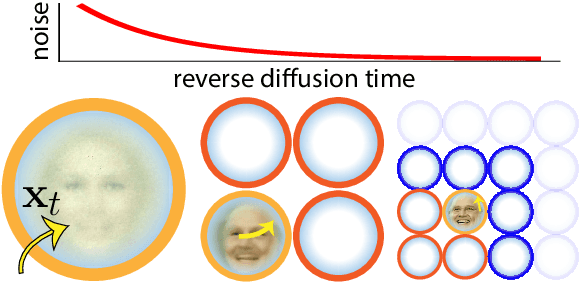
How do diffusion generative models convert pure noise into meaningful images? We argue that generation involves first committing to an outline, and then to finer and finer details. The corresponding reverse diffusion process can be modeled by dynamics on a (time-dependent) high-dimensional landscape full of Gaussian-like modes, which makes the following predictions: (i) individual trajectories tend to be very low-dimensional; (ii) scene elements that vary more within training data tend to emerge earlier; and (iii) early perturbations substantially change image content more often than late perturbations. We show that the behavior of a variety of trained unconditional and conditional diffusion models like Stable Diffusion is consistent with these predictions. Finally, we use our theory to search for the latent image manifold of diffusion models, and propose a new way to generate interpretable image variations. Our viewpoint suggests generation by GANs and diffusion models have unexpected similarities.
Tensor Factorization via Transformed Tensor-Tensor Product for Image Alignment
Dec 13, 2022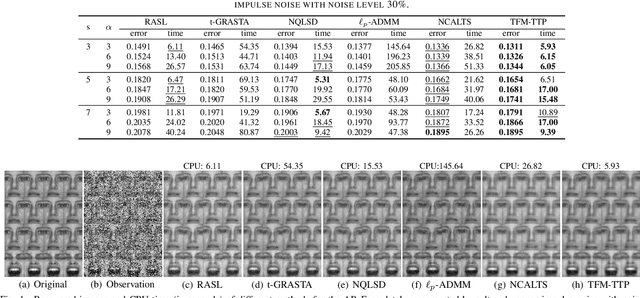
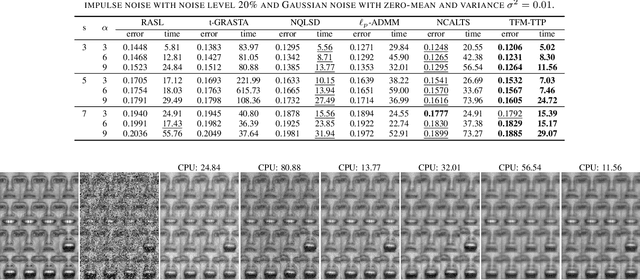
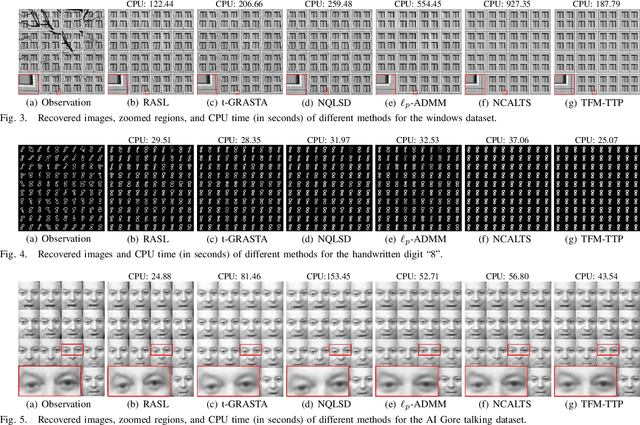

In this paper, we study the problem of a batch of linearly correlated image alignment, where the observed images are deformed by some unknown domain transformations, and corrupted by additive Gaussian noise and sparse noise simultaneously. By stacking these images as the frontal slices of a third-order tensor, we propose to utilize the tensor factorization method via transformed tensor-tensor product to explore the low-rankness of the underlying tensor, which is factorized into the product of two smaller tensors via transformed tensor-tensor product under any unitary transformation. The main advantage of transformed tensor-tensor product is that its computational complexity is lower compared with the existing literature based on transformed tensor nuclear norm. Moreover, the tensor $\ell_p$ $(0<p<1)$ norm is employed to characterize the sparsity of sparse noise and the tensor Frobenius norm is adopted to model additive Gaussian noise. A generalized Gauss-Newton algorithm is designed to solve the resulting model by linearizing the domain transformations and a proximal Gauss-Seidel algorithm is developed to solve the corresponding subproblem. Furthermore, the convergence of the proximal Gauss-Seidel algorithm is established, whose convergence rate is also analyzed based on the Kurdyka-$\L$ojasiewicz property. Extensive numerical experiments on real-world image datasets are carried out to demonstrate the superior performance of the proposed method as compared to several state-of-the-art methods in both accuracy and computational time.
Zero-Shot Image Restoration Using Denoising Diffusion Null-Space Model
Dec 01, 2022
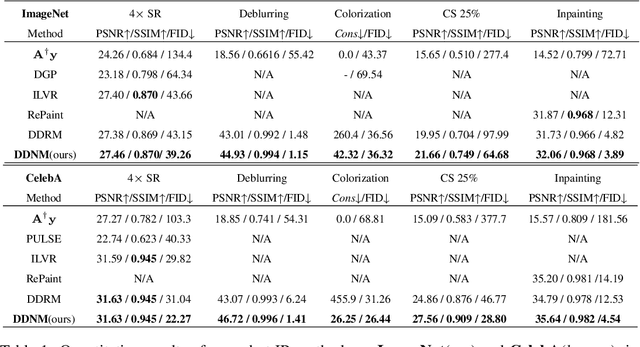
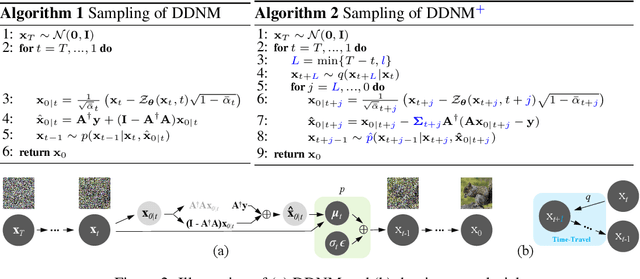

Most existing Image Restoration (IR) models are task-specific, which can not be generalized to different degradation operators. In this work, we propose the Denoising Diffusion Null-Space Model (DDNM), a novel zero-shot framework for arbitrary linear IR problems, including but not limited to image super-resolution, colorization, inpainting, compressed sensing, and deblurring. DDNM only needs a pre-trained off-the-shelf diffusion model as the generative prior, without any extra training or network modifications. By refining only the null-space contents during the reverse diffusion process, we can yield diverse results satisfying both data consistency and realness. We further propose an enhanced and robust version, dubbed DDNM+, to support noisy restoration and improve restoration quality for hard tasks. Our experiments on several IR tasks reveal that DDNM outperforms other state-of-the-art zero-shot IR methods. We also demonstrate that DDNM+ can solve complex real-world applications, e.g., old photo restoration.
BiCro: Noisy Correspondence Rectification for Multi-modality Data via Bi-directional Cross-modal Similarity Consistency
Mar 22, 2023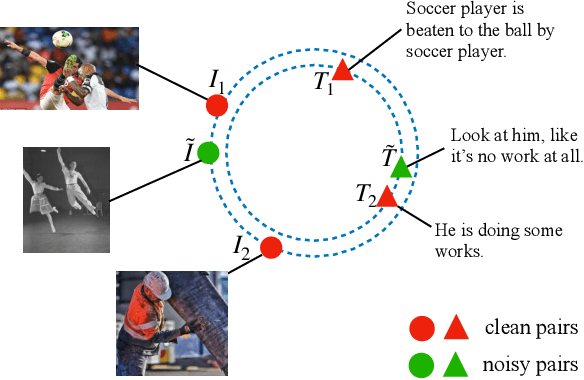
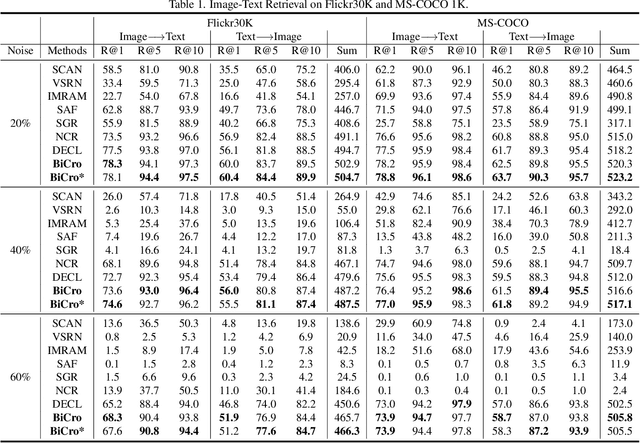

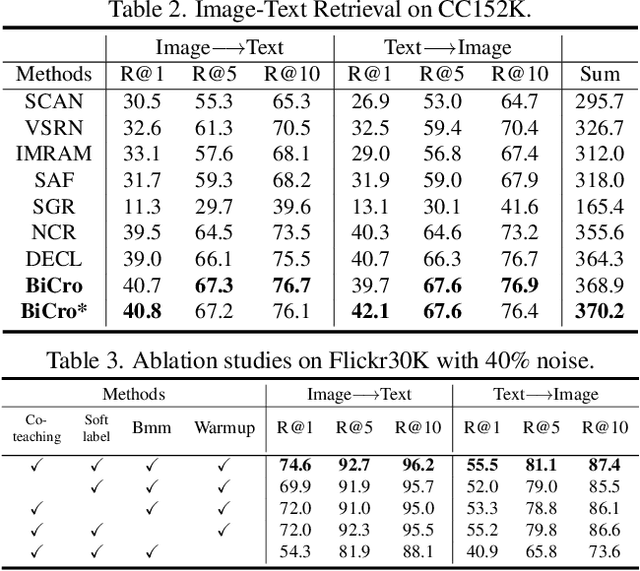
As one of the most fundamental techniques in multimodal learning, cross-modal matching aims to project various sensory modalities into a shared feature space. To achieve this, massive and correctly aligned data pairs are required for model training. However, unlike unimodal datasets, multimodal datasets are extremely harder to collect and annotate precisely. As an alternative, the co-occurred data pairs (e.g., image-text pairs) collected from the Internet have been widely exploited in the area. Unfortunately, the cheaply collected dataset unavoidably contains many mismatched data pairs, which have been proven to be harmful to the model's performance. To address this, we propose a general framework called BiCro (Bidirectional Cross-modal similarity consistency), which can be easily integrated into existing cross-modal matching models and improve their robustness against noisy data. Specifically, BiCro aims to estimate soft labels for noisy data pairs to reflect their true correspondence degree. The basic idea of BiCro is motivated by that -- taking image-text matching as an example -- similar images should have similar textual descriptions and vice versa. Then the consistency of these two similarities can be recast as the estimated soft labels to train the matching model. The experiments on three popular cross-modal matching datasets demonstrate that our method significantly improves the noise-robustness of various matching models, and surpass the state-of-the-art by a clear margin.
Stain-invariant self supervised learning for histopathology image analysis
Nov 14, 2022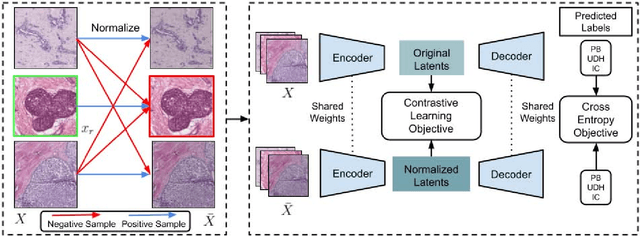
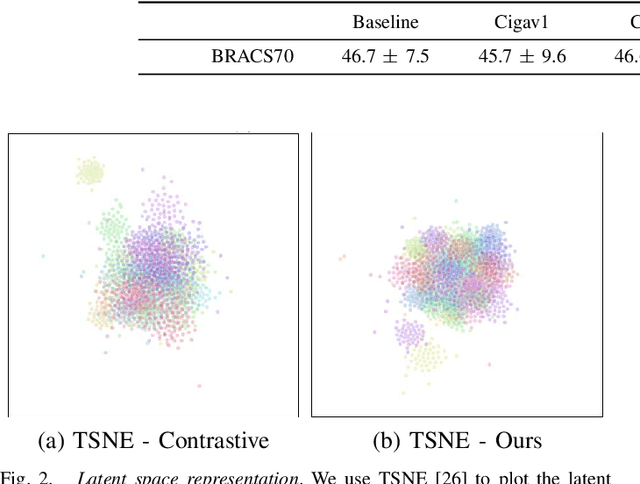

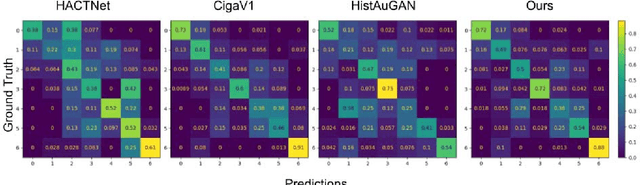
We present a self-supervised algorithm for several classification tasks within hematoxylin and eosin (H&E) stained images of breast cancer. Our method is robust to stain variations inherent to the histology images acquisition process, which has limited the applicability of automated analysis tools. We address this problem by imposing constraints a learnt latent space which leverages stain normalization techniques during training. At every iteration, we select an image as a normalization target and generate a version of every image in the batch normalized to that target. We minimize the distance between the embeddings that correspond to the same image under different staining variations while maximizing the distance between other samples. We show that our method not only improves robustness to stain variations across multi-center data, but also classification performance through extensive experiments on various normalization targets and methods. Our method achieves the state-of-the-art performance on several publicly available breast cancer datasets ranging from tumor classification (CAMELYON17) and subtyping (BRACS) to HER2 status classification and treatment response prediction.
Interactive Feature Embedding for Infrared and Visible Image Fusion
Nov 09, 2022
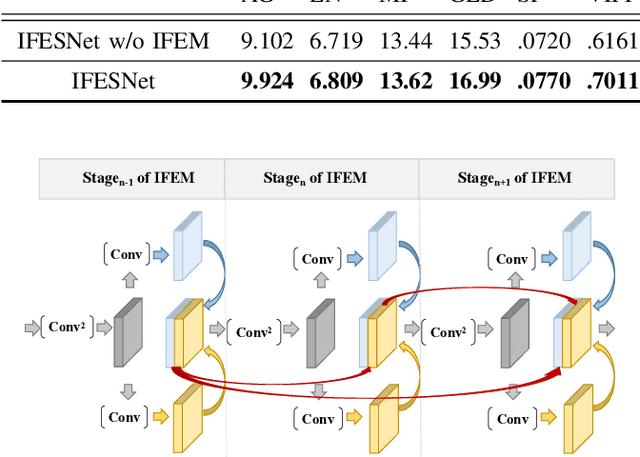
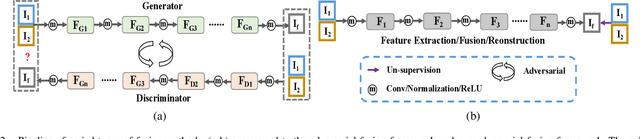
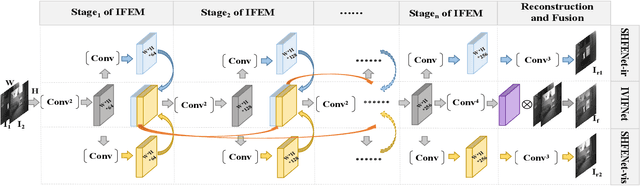
General deep learning-based methods for infrared and visible image fusion rely on the unsupervised mechanism for vital information retention by utilizing elaborately designed loss functions. However, the unsupervised mechanism depends on a well designed loss function, which cannot guarantee that all vital information of source images is sufficiently extracted. In this work, we propose a novel interactive feature embedding in self-supervised learning framework for infrared and visible image fusion, attempting to overcome the issue of vital information degradation. With the help of self-supervised learning framework, hierarchical representations of source images can be efficiently extracted. In particular, interactive feature embedding models are tactfully designed to build a bridge between the self-supervised learning and infrared and visible image fusion learning, achieving vital information retention. Qualitative and quantitative evaluations exhibit that the proposed method performs favorably against state-of-the-art methods.
Near-filed SAR Image Restoration with Deep Learning Inverse Technique: A Preliminary Study
Nov 28, 2022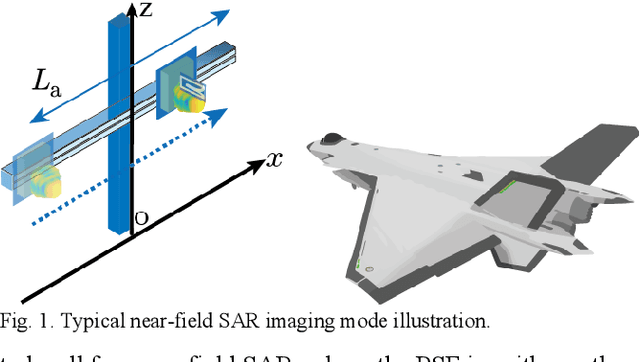
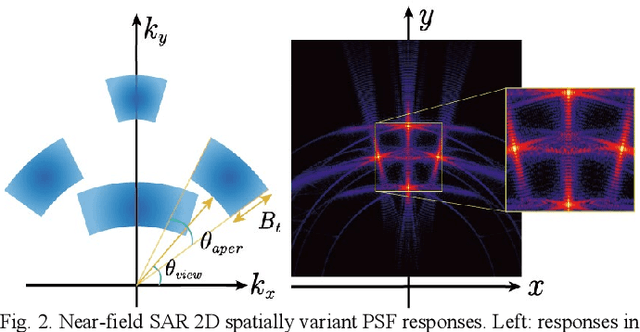

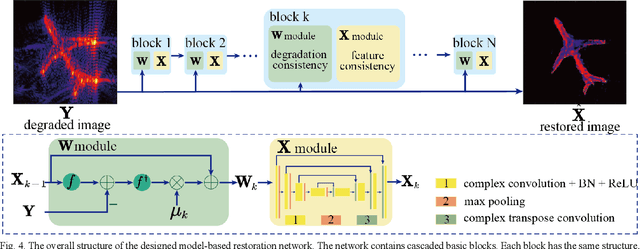
Benefiting from a relatively larger aperture's angle, and in combination with a wide transmitting bandwidth, near-field synthetic aperture radar (SAR) provides a high-resolution image of a target's scattering distribution-hot spots. Meanwhile, imaging result suffers inevitable degradation from sidelobes, clutters, and noises, hindering the information retrieval of the target. To restore the image, current methods make simplified assumptions; for example, the point spread function (PSF) is spatially consistent, the target consists of sparse point scatters, etc. Thus, they achieve limited restoration performance in terms of the target's shape, especially for complex targets. To address these issues, a preliminary study is conducted on restoration with the recent promising deep learning inverse technique in this work. We reformulate the degradation model into a spatially variable complex-convolution model, where the near-field SAR's system response is considered. Adhering to it, a model-based deep learning network is designed to restore the image. A simulated degraded image dataset from multiple complex target models is constructed to validate the network. All the images are formulated using the electromagnetic simulation tool. Experiments on the dataset reveal their effectiveness. Compared with current methods, superior performance is achieved regarding the target's shape and energy estimation.
Last-Layer Fairness Fine-tuning is Simple and Effective for Neural Networks
Apr 08, 2023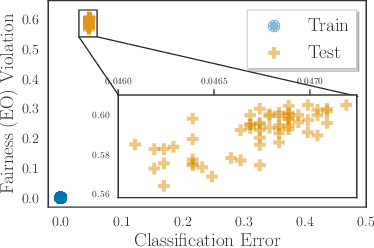
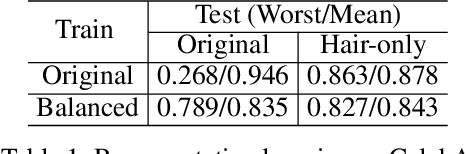
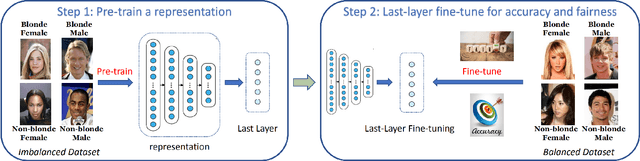
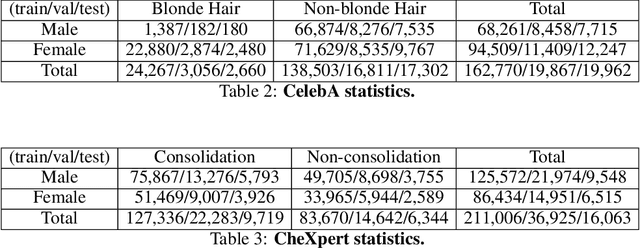
As machine learning has been deployed ubiquitously across applications in modern data science, algorithmic fairness has become a great concern and varieties of fairness criteria have been proposed. Among them, imposing fairness constraints during learning, i.e. in-processing fair training, has been a popular type of training method because they don't require accessing sensitive attributes during test time in contrast to post-processing methods. Although imposing fairness constraints have been studied extensively for classical machine learning models, the effect these techniques have on deep neural networks is still unclear. Recent research has shown that adding fairness constraints to the objective function leads to severe over-fitting to fairness criteria in large models, and how to solve this challenge is an important open question. To address this challenge, we leverage the wisdom and power of pre-training and fine-tuning and develop a simple but novel framework to train fair neural networks in an efficient and inexpensive way. We conduct comprehensive experiments on two popular image datasets with state-of-art architectures under different fairness notions to show that last-layer fine-tuning is sufficient for promoting fairness of the deep neural network. Our framework brings new insights into representation learning in training fair neural networks.
High Speed Neuromorphic Vision-Based Inspection of Countersinks in Automated Manufacturing Processes
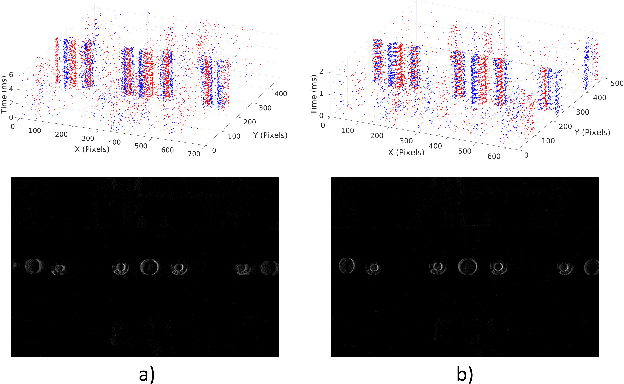
Apr 08, 2023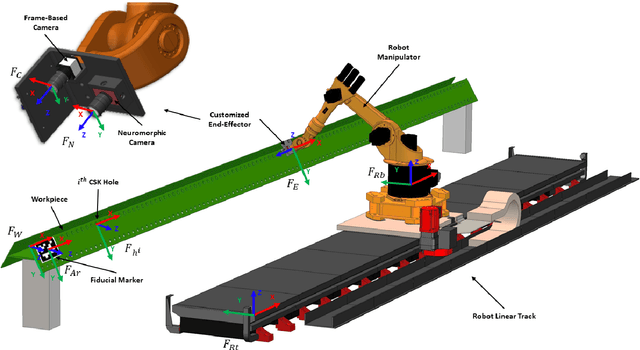

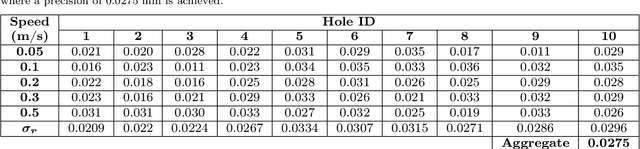
Countersink inspection is crucial in various automated assembly lines, especially in the aerospace and automotive sectors. Advancements in machine vision introduced automated robotic inspection of countersinks using laser scanners and monocular cameras. Nevertheless, the aforementioned sensing pipelines require the robot to pause on each hole for inspection due to high latency and measurement uncertainties with motion, leading to prolonged execution times of the inspection task. The neuromorphic vision sensor, on the other hand, has the potential to expedite the countersink inspection process, but the unorthodox output of the neuromorphic technology prohibits utilizing traditional image processing techniques. Therefore, novel event-based perception algorithms need to be introduced. We propose a countersink detection approach on the basis of event-based motion compensation and the mean-shift clustering principle. In addition, our framework presents a robust event-based circle detection algorithm to precisely estimate the depth of the countersink specimens. The proposed approach expedites the inspection process by a factor of 10$\times$ compared to conventional countersink inspection methods. The work in this paper was validated for over 50 trials on three countersink workpiece variants. The experimental results show that our method provides a precision of 0.025 mm for countersink depth inspection despite the low resolution of commercially available neuromorphic cameras.