 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Unsupervised Audio-Visual Segmentation with Modality Alignment
Mar 21, 2024

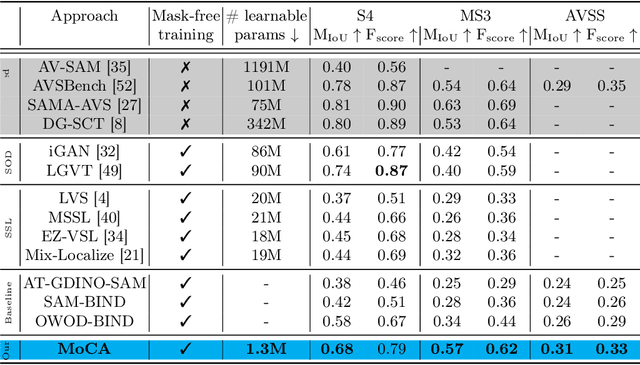
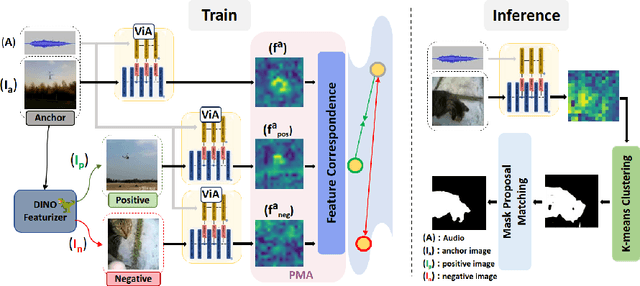

Audio-Visual Segmentation (AVS) aims to identify, at the pixel level, the object in a visual scene that produces a given sound. Current AVS methods rely on costly fine-grained annotations of mask-audio pairs, making them impractical for scalability. To address this, we introduce unsupervised AVS, eliminating the need for such expensive annotation. To tackle this more challenging problem, we propose an unsupervised learning method, named Modality Correspondence Alignment (MoCA), which seamlessly integrates off-the-shelf foundation models like DINO, SAM, and ImageBind. This approach leverages their knowledge complementarity and optimizes their joint usage for multi-modality association. Initially, we estimate positive and negative image pairs in the feature space. For pixel-level association, we introduce an audio-visual adapter and a novel pixel matching aggregation strategy within the image-level contrastive learning framework. This allows for a flexible connection between object appearance and audio signal at the pixel level, with tolerance to imaging variations such as translation and rotation. Extensive experiments on the AVSBench (single and multi-object splits) and AVSS datasets demonstrate that our MoCA outperforms strongly designed baseline methods and approaches supervised counterparts, particularly in complex scenarios with multiple auditory objects. Notably when comparing mIoU, MoCA achieves a substantial improvement over baselines in both the AVSBench (S4: +17.24%; MS3: +67.64%) and AVSS (+19.23%) audio-visual segmentation challenges.
EventDance: Unsupervised Source-free Cross-modal Adaptation for Event-based Object Recognition
Mar 21, 2024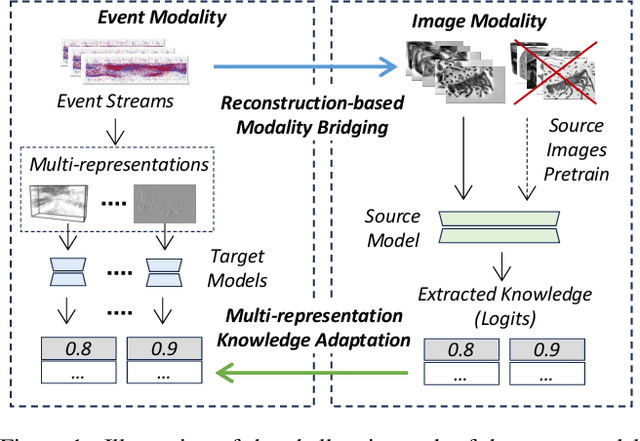
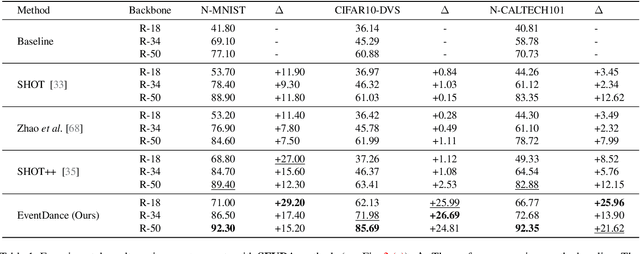

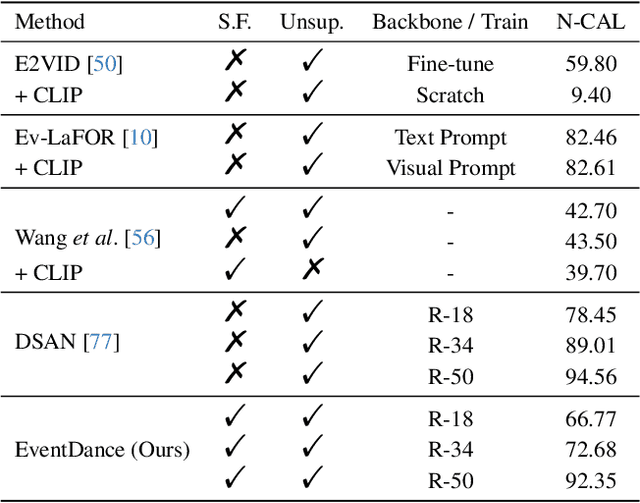
In this paper, we make the first attempt at achieving the cross-modal (i.e., image-to-events) adaptation for event-based object recognition without accessing any labeled source image data owning to privacy and commercial issues. Tackling this novel problem is non-trivial due to the novelty of event cameras and the distinct modality gap between images and events. In particular, as only the source model is available, a hurdle is how to extract the knowledge from the source model by only using the unlabeled target event data while achieving knowledge transfer. To this end, we propose a novel framework, dubbed EventDance for this unsupervised source-free cross-modal adaptation problem. Importantly, inspired by event-to-video reconstruction methods, we propose a reconstruction-based modality bridging (RMB) module, which reconstructs intensity frames from events in a self-supervised manner. This makes it possible to build up the surrogate images to extract the knowledge (i.e., labels) from the source model. We then propose a multi-representation knowledge adaptation (MKA) module that transfers the knowledge to target models learning events with multiple representation types for fully exploring the spatiotemporal information of events. The two modules connecting the source and target models are mutually updated so as to achieve the best performance. Experiments on three benchmark datasets with two adaption settings show that EventDance is on par with prior methods utilizing the source data.
VidLA: Video-Language Alignment at Scale
Mar 21, 2024In this paper, we propose VidLA, an approach for video-language alignment at scale. There are two major limitations of previous video-language alignment approaches. First, they do not capture both short-range and long-range temporal dependencies and typically employ complex hierarchical deep network architectures that are hard to integrate with existing pretrained image-text foundation models. To effectively address this limitation, we instead keep the network architecture simple and use a set of data tokens that operate at different temporal resolutions in a hierarchical manner, accounting for the temporally hierarchical nature of videos. By employing a simple two-tower architecture, we are able to initialize our video-language model with pretrained image-text foundation models, thereby boosting the final performance. Second, existing video-language alignment works struggle due to the lack of semantically aligned large-scale training data. To overcome it, we leverage recent LLMs to curate the largest video-language dataset to date with better visual grounding. Furthermore, unlike existing video-text datasets which only contain short clips, our dataset is enriched with video clips of varying durations to aid our temporally hierarchical data tokens in extracting better representations at varying temporal scales. Overall, empirical results show that our proposed approach surpasses state-of-the-art methods on multiple retrieval benchmarks, especially on longer videos, and performs competitively on classification benchmarks.
ReGround: Improving Textual and Spatial Grounding at No Cost
Mar 20, 2024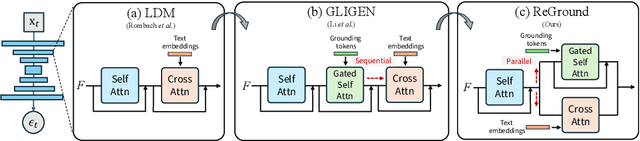


When an image generation process is guided by both a text prompt and spatial cues, such as a set of bounding boxes, do these elements work in harmony, or does one dominate the other? Our analysis of a pretrained image diffusion model that integrates gated self-attention into the U-Net reveals that spatial grounding often outweighs textual grounding due to the sequential flow from gated self-attention to cross-attention. We demonstrate that such bias can be significantly mitigated without sacrificing accuracy in either grounding by simply rewiring the network architecture, changing from sequential to parallel for gated self-attention and cross-attention. This surprisingly simple yet effective solution does not require any fine-tuning of the network but significantly reduces the trade-off between the two groundings. Our experiments demonstrate significant improvements from the original GLIGEN to the rewired version in the trade-off between textual grounding and spatial grounding.
D-YOLO a robust framework for object detection in adverse weather conditions
Mar 20, 2024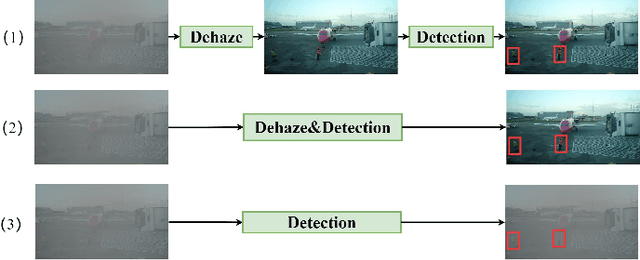
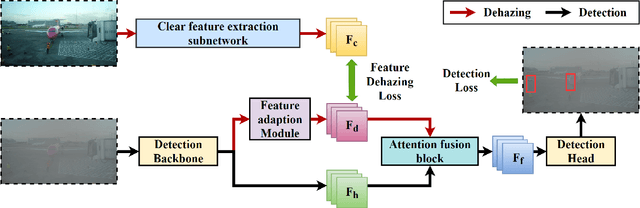
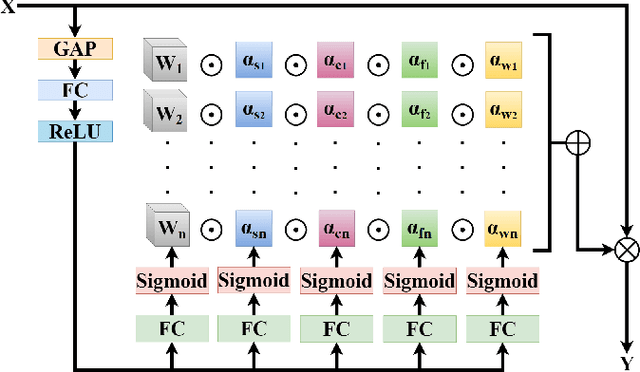
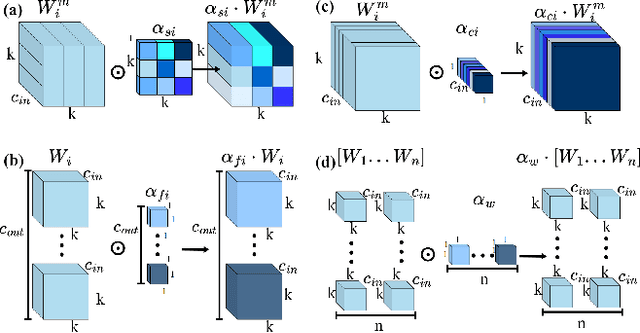
Adverse weather conditions including haze, snow and rain lead to decline in image qualities, which often causes a decline in performance for deep-learning based detection networks. Most existing approaches attempts to rectify hazy images before performing object detection, which increases the complexity of the network and may result in the loss in latent information. To better integrate image restoration and object detection tasks, we designed a double-route network with an attention feature fusion module, taking both hazy and dehazed features into consideration. We also proposed a subnetwork to provide haze-free features to the detection network. Specifically, our D-YOLO improves the performance of the detection network by minimizing the distance between the clear feature extraction subnetwork and detection network. Experiments on RTTS and FoggyCityscapes datasets show that D-YOLO demonstrates better performance compared to the state-of-the-art methods. It is a robust detection framework for bridging the gap between low-level dehazing and high-level detection.
Synthetic Image Generation in Cyber Influence Operations: An Emergent Threat?
Mar 18, 2024



The evolution of artificial intelligence (AI) has catalyzed a transformation in digital content generation, with profound implications for cyber influence operations. This report delves into the potential and limitations of generative deep learning models, such as diffusion models, in fabricating convincing synthetic images. We critically assess the accessibility, practicality, and output quality of these tools and their implications in threat scenarios of deception, influence, and subversion. Notably, the report generates content for several hypothetical cyber influence operations to demonstrate the current capabilities and limitations of these AI-driven methods for threat actors. While generative models excel at producing illustrations and non-realistic imagery, creating convincing photo-realistic content remains a significant challenge, limited by computational resources and the necessity for human-guided refinement. Our exploration underscores the delicate balance between technological advancement and its potential for misuse, prompting recommendations for ongoing research, defense mechanisms, multi-disciplinary collaboration, and policy development. These recommendations aim to leverage AI's potential for positive impact while safeguarding against its risks to the integrity of information, especially in the context of cyber influence.
Differentially Private Representation Learning via Image Captioning
Mar 04, 2024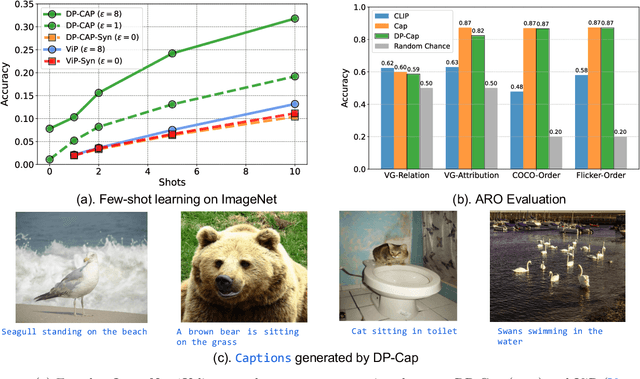
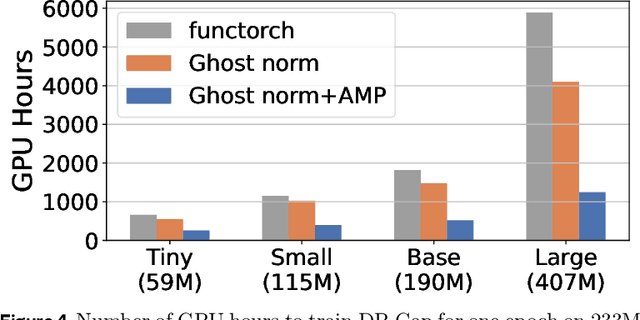
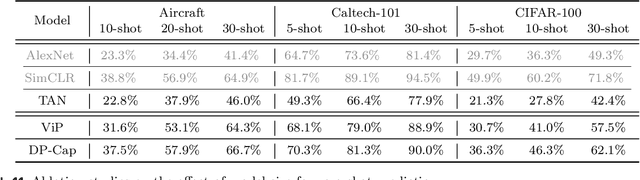
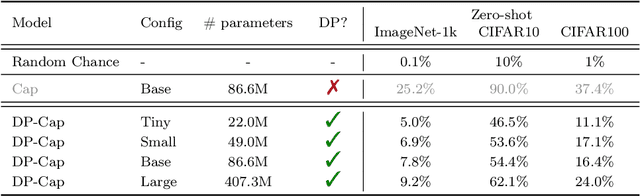
Differentially private (DP) machine learning is considered the gold-standard solution for training a model from sensitive data while still preserving privacy. However, a major barrier to achieving this ideal is its sub-optimal privacy-accuracy trade-off, which is particularly visible in DP representation learning. Specifically, it has been shown that under modest privacy budgets, most models learn representations that are not significantly better than hand-crafted features. In this work, we show that effective DP representation learning can be done via image captioning and scaling up to internet-scale multimodal datasets. Through a series of engineering tricks, we successfully train a DP image captioner (DP-Cap) on a 233M subset of LAION-2B from scratch using a reasonable amount of computation, and obtaining unprecedented high-quality image features that can be used in a variety of downstream vision and vision-language tasks. For example, under a privacy budget of $\varepsilon=8$, a linear classifier trained on top of learned DP-Cap features attains 65.8% accuracy on ImageNet-1K, considerably improving the previous SOTA of 56.5%. Our work challenges the prevailing sentiment that high-utility DP representation learning cannot be achieved by training from scratch.
Modality-Agnostic Structural Image Representation Learning for Deformable Multi-Modality Medical Image Registration
Feb 29, 2024Establishing dense anatomical correspondence across distinct imaging modalities is a foundational yet challenging procedure for numerous medical image analysis studies and image-guided radiotherapy. Existing multi-modality image registration algorithms rely on statistical-based similarity measures or local structural image representations. However, the former is sensitive to locally varying noise, while the latter is not discriminative enough to cope with complex anatomical structures in multimodal scans, causing ambiguity in determining the anatomical correspondence across scans with different modalities. In this paper, we propose a modality-agnostic structural representation learning method, which leverages Deep Neighbourhood Self-similarity (DNS) and anatomy-aware contrastive learning to learn discriminative and contrast-invariance deep structural image representations (DSIR) without the need for anatomical delineations or pre-aligned training images. We evaluate our method on multiphase CT, abdomen MR-CT, and brain MR T1w-T2w registration. Comprehensive results demonstrate that our method is superior to the conventional local structural representation and statistical-based similarity measures in terms of discriminability and accuracy.
Ultra Low-Cost Two-Stage Multimodal System for Non-Normative Behavior Detection
Mar 24, 2024The online community has increasingly been inundated by a toxic wave of harmful comments. In response to this growing challenge, we introduce a two-stage ultra-low-cost multimodal harmful behavior detection method designed to identify harmful comments and images with high precision and recall rates. We first utilize the CLIP-ViT model to transform tweets and images into embeddings, effectively capturing the intricate interplay of semantic meaning and subtle contextual clues within texts and images. Then in the second stage, the system feeds these embeddings into a conventional machine learning classifier like SVM or logistic regression, enabling the system to be trained rapidly and to perform inference at an ultra-low cost. By converting tweets into rich multimodal embeddings through the CLIP-ViT model and utilizing them to train conventional machine learning classifiers, our system is not only capable of detecting harmful textual information with near-perfect performance, achieving precision and recall rates above 99\% but also demonstrates the ability to zero-shot harmful images without additional training, thanks to its multimodal embedding input. This capability empowers our system to identify unseen harmful images without requiring extensive and costly image datasets. Additionally, our system quickly adapts to new harmful content; if a new harmful content pattern is identified, we can fine-tune the classifier with the corresponding tweets' embeddings to promptly update the system. This makes it well suited to addressing the ever-evolving nature of online harmfulness, providing online communities with a robust, generalizable, and cost-effective tool to safeguard their communities.
Towards Two-Stream Foveation-based Active Vision Learning
Mar 24, 2024Deep neural network (DNN) based machine perception frameworks process the entire input in a one-shot manner to provide answers to both "what object is being observed" and "where it is located". In contrast, the "two-stream hypothesis" from neuroscience explains the neural processing in the human visual cortex as an active vision system that utilizes two separate regions of the brain to answer the what and the where questions. In this work, we propose a machine learning framework inspired by the "two-stream hypothesis" and explore the potential benefits that it offers. Specifically, the proposed framework models the following mechanisms: 1) ventral (what) stream focusing on the input regions perceived by the fovea part of an eye (foveation), 2) dorsal (where) stream providing visual guidance, and 3) iterative processing of the two streams to calibrate visual focus and process the sequence of focused image patches. The training of the proposed framework is accomplished by label-based DNN training for the ventral stream model and reinforcement learning for the dorsal stream model. We show that the two-stream foveation-based learning is applicable to the challenging task of weakly-supervised object localization (WSOL), where the training data is limited to the object class or its attributes. The framework is capable of both predicting the properties of an object and successfully localizing it by predicting its bounding box. We also show that, due to the independent nature of the two streams, the dorsal model can be applied on its own to unseen images to localize objects from different datasets.